
初めに
社内でシステムの管理をしていると、各システムの連携を図や表で表す必要が出てくることがよくあります。しかし、人間は細かい管理には向いておらず、定期的なメンテナンスや最新化、そして統一された粒度(レベル)の管理を続けるのは非常に困難です。

そんな中で、最近「Neo4j」というグラフ描画ツールの存在を知りました。「LangChain」と「Neo4j」を使って効率的にグラフを作成する記事を目にし、これが私が求めていた「システム連携図の自動生成ツール」になるのではないかと考えました。そこで今回は、「LangChain」と「Neo4j」を実際に試してみました。
「Neo4j」と「LangChain」の関係
「Neo4j」は、複数のノード(例えばデータの項目)とリレーション(それらを結ぶ関係)を視覚的に描画するためのツールです。クエリ言語を使って、条件に応じたグラフを描くことができる点が非常に優れています。一方、「LangChain」は主に生成AIを活用するためのライブラリで、テキストや図から自動的にクエリ言語を生成します。この2つを組み合わせて、システム連携図の作成を試みます。
流れ
以下の手順で進めていきます。

1.「システム構成図」を準備する。
2. 「LangChain」でその構成図を基に、Neo4jが理解できるクエリを生成する。
3. 生成されたクエリを基に、Neo4jでグラフを描画する。
今回は、これらの流れに沿って「Neo4j」と「LangChain」を実際に利用する方法を紹介します。
「neo4j」のセットアップ
「Neo4j」はローカルにインストールする方法と、クラウドサービス「Neo4j Aura」を利用する方法があります。今回は後者を利用します。登録方法について、詳しく説明します。このサービスは「Neo4j aura」と言います。
つまずいたところもありましたので、それを含めて可能な限りわかりやすく手順を説明したいと思います。
以下のURLのサイトに「Start Free」というボタンがあるので押下します。
そうしますと、以下のようなアカウント作成画面が表示されるので、「メールアドレス」と「パスワード」を入力し、「Continue」ボタンを押下します。
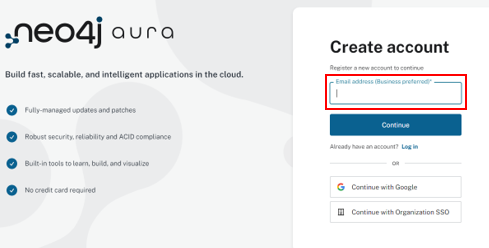
登録が完了すると、以下のようなダイアログが表示され、設定した「メールアドレス」に自動送信メールが届きます。
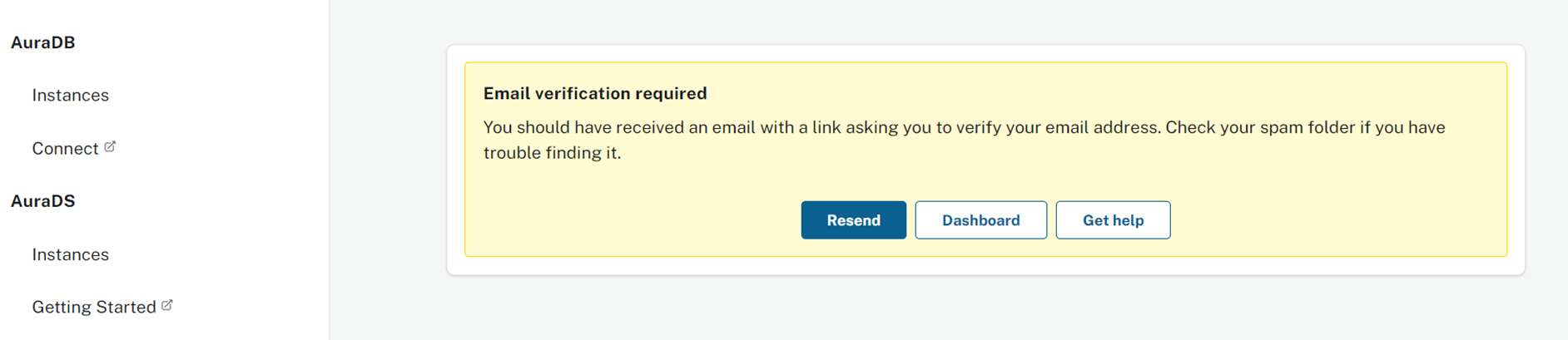
Neo4jからの自動メールを確認すると、以下のような内容になっていますので、「verify my e-mail address」ボタンを押下しますと、「Neo4j」の利用が許可されます。
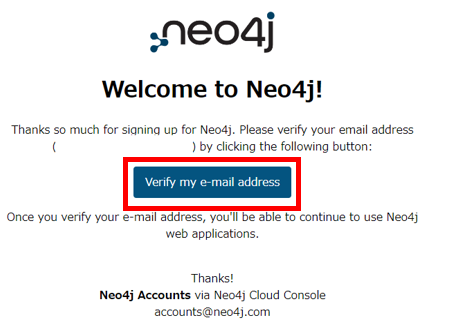
ボタン押下後、許可された後の画面です。
「Back to Neo4j Cloud Console」ボタンを押下すると、「Neo4j Cloud Console」に戻ります。
「Neo4j Cloud Console」に戻りますと、今度はポリシーの同意を求められます。
とりあえず「I agree」ボタンを押下してみましょう。

そうすると、裏に隠れていた「neo4j Cloud Console」の画面が表示されます。
インスタンスを新規作成するため、上部の「New Instance」ボタンを押下してください。
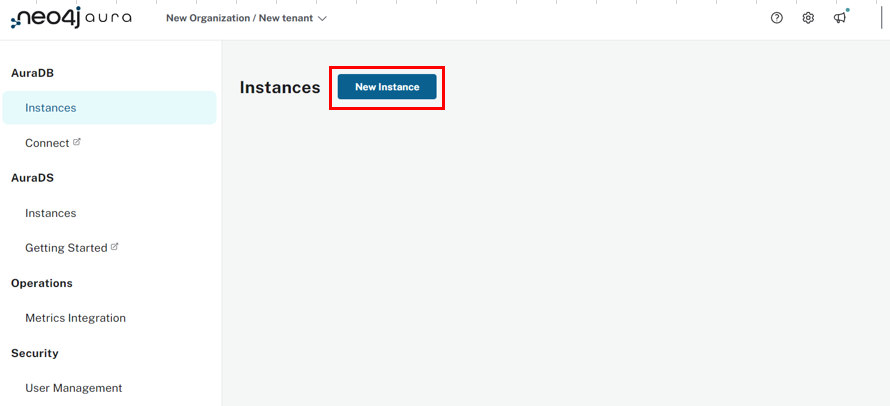
3種類の選択肢が出てきますので、今回は左側の「$0」の中にある「select」ボタンを押下してください。
ボタンを押下すると以下のようなダイアログが表示されます。
上部の赤枠に目立たない小さな字で「Username:neo4j」と書かれています。これ(neo4j)が「ユーザ名」になります。変更は出来なさそうです。また、その下のグレーの網掛けをしている部分が「パスワード」です。パスワードのボックスの右側の「コピーマーク」を押して別のテキストファイルなどに張り付けて保存しても良いでしょう。この画面を閉じてしまうと、二度と「パスワード」を確認することができなくなります。
「Download and continue」ボタンを押下しますと、「パスワード」を記載したテキストファイルをダウンロードすることができ、同時に次画面に遷移します。

そして3~5分程度でインスタンス作成が完成します。下図はインスタンス作成中のところです。

下画面が、インスタンス生成が完了した時の画面です。インスタンスの上部に「Open」ボタンがあるので、押下してください。
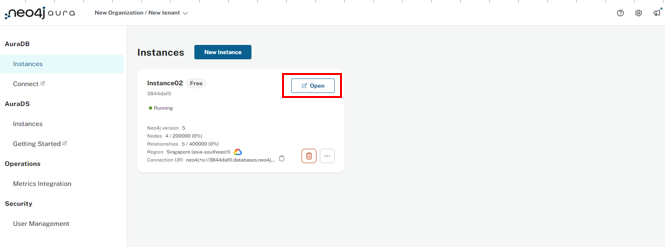
真ん中にダイアログが表示されます。これからインスタンスに接続することを表しています。
左側の「Protocol」と右側の「ConnectionURL」を合わせたものがインスタンスのURLとなります。Pythonなどのソースコードではneo4j+s://********.neofj.io:7687という形でURLを設定することになります。「Connect」ボタンを押下するとインスタンスに接します。
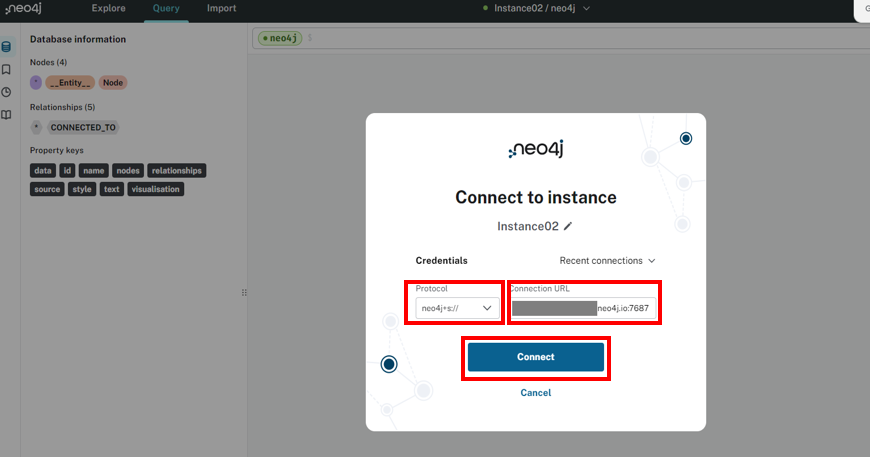
下画像は、接続完了後の画面イメージです。ただ私の場合は以前データベースにデータを登録していますので、左側に「_Entity_」や「Node」という文字が表示されています。初めて作成した方は、何も表示されません。
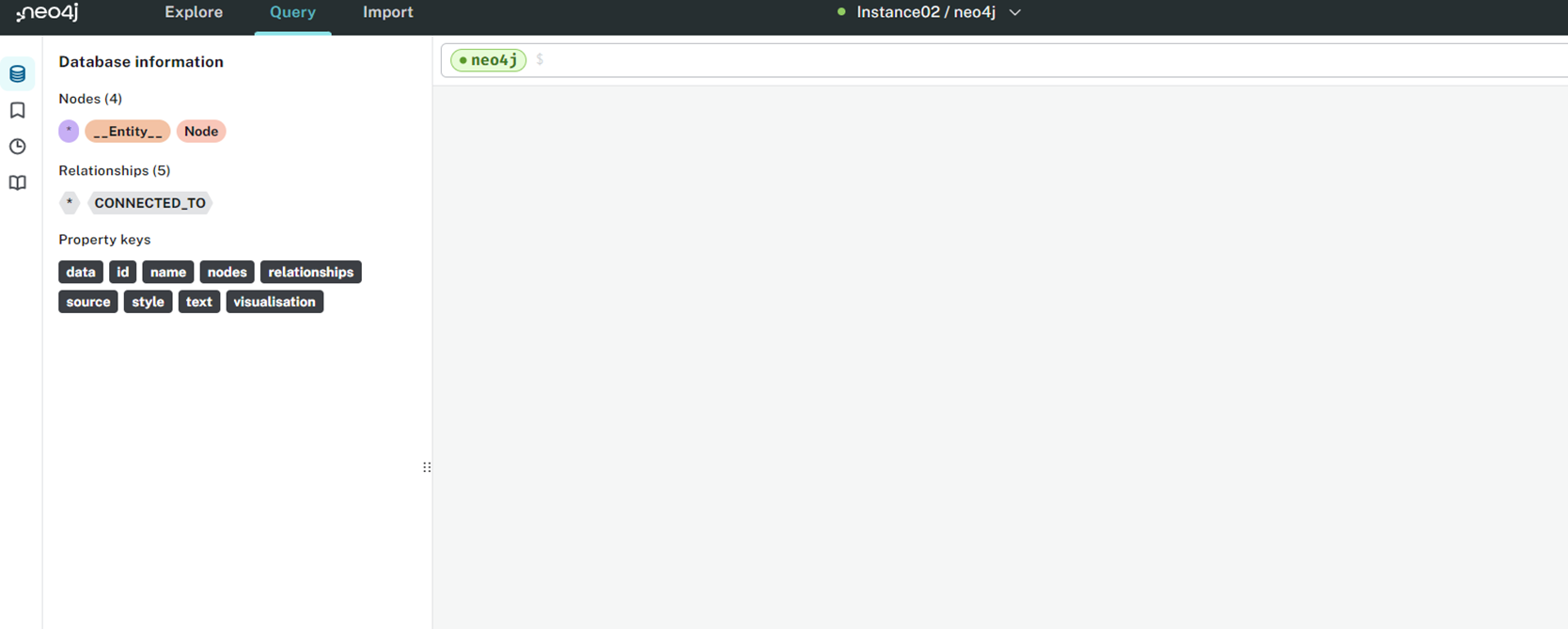
ここまで出来ましたら、「Neo4j aura」インスタンスの完成です。
実際に試したプログラム
次に、実際に動かしたプログラムのコードを紹介します。
from langchain_community.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
#from langchain_openai import ChatOpenAI
from langchain.chat_models import ChatOpenAI
from langchain_experimental.graph_transformers import LLMGraphTransformer
from node4j_1 import load_pdf, split_text
llm = ChatOpenAI(
model= "gpt-4o-mini"
)
import os
os.environ["NEO4J_URI"] = "neo4j+s://**********.databases.neo4j.io:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "********************************"
graph = Neo4jGraph()
docs = load_pdf()
tgt_chunks = split_text(docs)
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(tgt_chunks)
graph.add_graph_documents(graph_documents)
モデルについて
今回は一番安いgpt-4o-miniを使ってみることにしました。
llm = ChatOpenAI(
model= "gpt-4o-mini"
)
「Neo4j」へのアクセス権限
前章で説明した通り、「URL」「USERNAME」「PASSWORD」を設定します。
「URL」については具体的に記述している記事を見つけることができませんでしたが、Try&Errorで、neo4j+s://から始まるようにすればよいことが分かりました。また「USERNAME」はフリー版を利用する限りneo4jのようです。
os.environ["NEO4J_URI"] = "neo4j+s://**********.databases.neo4j.io:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "********************************"
また、split_text(docs)という関数を別ファイルで定義して、ドキュメントをちっちゃく切り刻んでいきます。
tgt_chunks = split_text(docs)
最後にconvert_to_graph_documentsという便利なメソッドを呼び出し、インプットを基にクエリを作成しているようです。また、その結果をクラウド上のNeo4j auraにクエリを登録しているようです。
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(tgt_chunks)
graph.add_graph_documents(graph_documents)
このプログラムは、以下の投稿記事を参考にさせて頂きました。記事を書いた釣部 勇人さん、ありがとうございました。
非常にわかりやすい説明で、それほど障壁もなくインストールとプログラム実行ができました。
それから、pdfファイルをチャンクする処理も以下に載せます。
import glob
#from langchain.document_loaders import PyPDFLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document
# demodata/ *.txt の読み込み
def load_pdf(path: str= "demodata/*.txt") -> list:
pdf_resources = []
for file in glob.glob(path):
print(file)
loader = PyMuPDFLoader(file)
pages = loader.load_and_split()
file_text = ''.join([x.page_content for x in pages])
doc = Document(page_content=file_text, metadata={'source': file})
pdf_resources.append(doc)
return pdf_resources
# テキストのチャンク分割
def split_text(docs: list) -> list:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=700,
chunk_overlap=100,
)
chunked_resources = text_splitter.split_documents(docs)
return chunked_resources
読み込みファイルについて
pdfファイルをインプットにしようと思ったのですが、最初なのでtextファイルで試すことにしました。
またPDFLoaderではencodeエラーが出てきたので、このモジュールよりも優秀(?)なPyMuPDFLoaderを利用することにしました。
loader = PyMuPDFLoader(file)
インプットデータ
Wikiの「走れメロス」の「あらすじ」の文章をtxtファイルにしてみました。

これがテキストファイルイメージ

実行
では実行してみます。
2kfra8p0\LocalCache\local-packages\Python311\site-packages\langchain_experimental\graph_transformers\llm.py", line 753, in process_response
nodes_set.add((rel["head"], rel["head_type"]))
~~~^^^^^^^^
KeyError: 'head'
お、なんかエラーが出ましたね・・・
これを解決するのに半日かかりました💦
結論はgpt-4o-miniではエラーになります。gpt-4oもしくはgpt-3.5-turboであれば動くようです。
再度モデルをgpt-3.5-turboに変更して実行します。
今度はうまくいきました。
「Neo4j」の描画
グラフ描画の結果は以下です。
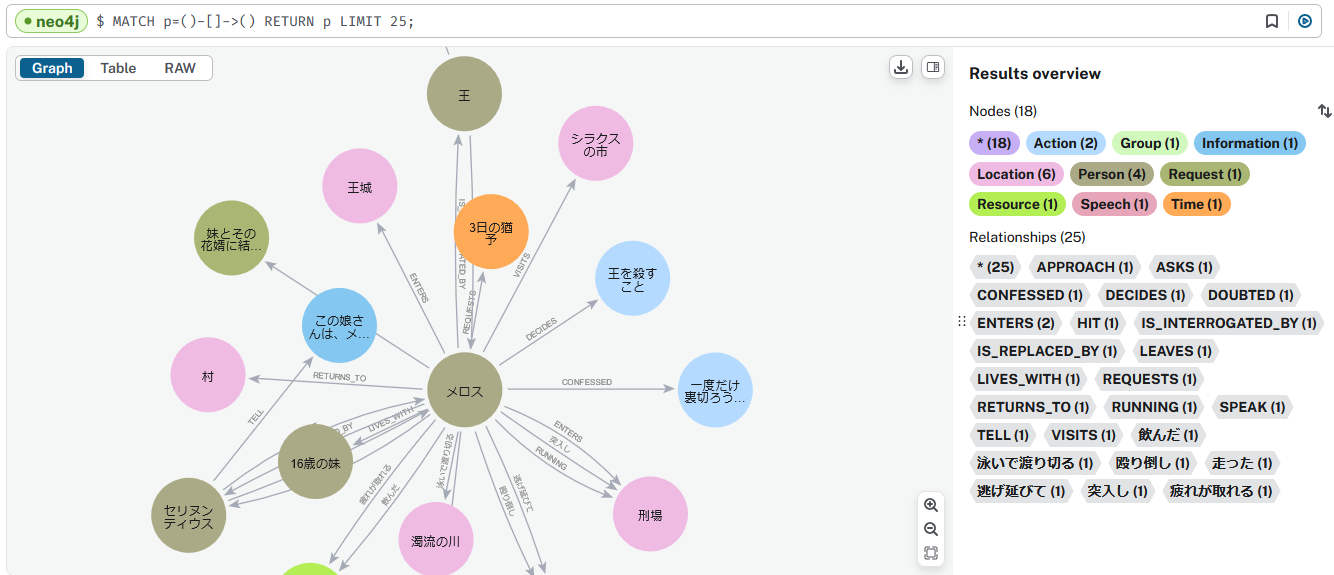
合っているかどうかは分からないのですが、まずまずではないかと思います。
ただ、「システム連携図」を作成するには、更なる精度向上が必要となります。
ちなみに、何度かやると前回の実行結果と足し合わされるため、以下のコードを追記して、「ノード」や「リレーション」を削除してから実施しました。
graph = Neo4jGraph()
graph.query("MATCH (n) DETACH DELETE n;") # <===これ追加
docs = load_pdf()
まとめ
今回の試行では、システム連携図の作成がある程度自動化できることが確認できました。ただし、まだ改善の余地がありますので、今後はさらに精度を高めるための工夫を検討していきます。
次回は「システム連携図」の画像認識を基に、どのくらいの精度がでるかを確認していきたいと思います。
最後までご覧いただき、ありがとうございました。