
はじめに
前回は、chainlitをstreamlitに置き換えて、「XMLファイルの名称(10桁の数字)を入力するためのテキストボックス」と「プロンプト入力ボックス」の両方を表示させて入力できるようにしました。
今回で10回目の記事投稿なのですが、少しずつ進化しているような気がしています。
今まで、XMLファイルの中で必要なデータのみをデータベースに登録したり、metadataの属性情報をデータベースに追加登録したりしてきました。少しずつ精度は上がっているのですが、これではまだまだ商用としては通用しません。
第10回目の今回は、生成AI(ChatGPT)が推論したキーワードをVectorDB(Chroma)に登録する機能(自動タグ付け機能)を追加していきます。
こうすることで、もう少し検索精度が上がるのではないかと考えております。
では、これから始めてまいります。
VectorDB作成プログラム
まずは、ChromaのVectorDBを生成するプログラムを以下に示します。
import glob
import os
import xml.etree.ElementTree as ET
from dotenv import load_dotenv
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from pydantic import BaseModel, Field
from langchain.chat_models import ChatOpenAI
from langchain.chains import create_tagging_chain_pydantic
load_dotenv()
docs = []
# 取り出したい名前空間-タグ名
name_spaces_tag_names = [
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PublicationNumber",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PublicationDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}RegistrationDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}ApplicationNumberText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PartyIdentifier",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}EntityName",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PostalAddressText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PersonFullName",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}P",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}FigureReference",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}PlainLanguageDesignationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}FilingDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}MainClassification",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}FurtherClassification",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}PatentClassificationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}SearchFieldText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}ClaimText",
]
llm = ChatOpenAI(model="gpt-3.5-turbo")
class TagAttribute(BaseModel):
tags: list[str] = Field(description="文章の中でキーワードを取得")
def set_element(level, trees, el):
trees.append({"tag" : el.tag, "attrib" : el.attrib, "content_page" :el.text})
def set_child(level, trees, el):
set_element(level, trees, el)
for child in el:
set_child(level+1, trees, child)
def parse_and_get_element(input_file):
tmp_elements = []
new_elements = []
tree = ET.parse(input_file)
root = tree.getroot()
set_child(1, tmp_elements, root)
for name_space_tag_name in name_spaces_tag_names:
for tmp_element in tmp_elements:
if tmp_element["tag"] == name_space_tag_name:
new_elements.append(tmp_element)
return new_elements
title = ""
entryName = ""
patentCitationText = ""
files = glob.glob(os.path.join("C:\\Users\\ogiki\\JPB_2023185", "**/*.*"), recursive=True)
for file in files:
base, ext = os.path.splitext(file)
if ext == '.xml':
# --- topic名称 ---
topic_name = os.path.splitext(os.path.basename(file))[0]
# --- file名称 ---
print(file)
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
new_elements = parse_and_get_element(file)
for new_element in new_elements:
text = new_element["content_page"]
tag = new_element["tag"]
title = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle" else ""
entryName = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Common}EntityName" else ""
patentCitationText = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText" else ""
# --- キー情報取得 ---
keys_str = ""
chain = create_tagging_chain_pydantic(TagAttribute, llm)
keys = chain.run(text)
i = 0
for key in keys:
i += 1
if i == 1:
keys_str = str(key[1][0])
else:
keys_str = keys_str + ", " + str(key[1][0])
documents = text_splitter.create_documents(texts=[text], metadatas=[{
"name": topic_name,
"source": file,
"tag": tag,
"keys": keys_str,
"title": title,
"entry_name": entryName,
"patent_citation_text" : patentCitationText}]
)
docs.extend(documents)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
db = Chroma(persist_directory="C:\\Users\\ogiki\\vectorDB\\local_chroma", embedding_function=embeddings)
# トークン数制限のため、500 documentずつ処理をする
intv = 500
ln = len(docs)
max_loop = int(ln / intv) + 1
for i in range(max_loop):
splitted_documents = text_splitter.split_documents(docs[intv * i : intv * (i+1)])
db.add_documents(splitted_documents)
以下では、特筆する内容を説明していきます。
属性クラス定義
create_tagging_chain_pydanticという関数は90行目付近に出てくるのですが、キーワード情報を取得するには、予めBaseModelというクラスを継承した「具象クラス」を定義する必要があります。今回はTagAttributeという具象クラスを定義しました。
class TagAttribute(BaseModel):
tags: list[str] = Field(description="文章の中でキーワードを取得")
フィールド(Field)の返り値が複数になることを想定し、listで返却してもらうようにしました。
また、生成AIに推測してもらうためにdiscriptionで何を取得するのかを記述しました。
これだけで、わかってくれるのはとっても賢いですね~。
キー情報生成
次に、create_tagging_chain_pydanticという関数を利用して、先ほどのTaggAttributeとllmを設定します。
それからそのインスタンスであるchainのrun関数にテキスト情報を入れてあげれば、キー情報のリストが出てくるという仕組みになっています。本当に便利ですね。
# --- キー情報取得 ---
keys_str = ""
chain = create_tagging_chain_pydantic(TagAttribute, llm)
keys = chain.run(text)
i = 0
for key in keys:
i += 1
if i == 1:
keys_str = str(key[1][0])
else:
keys_str = keys_str + ", " + str(key[1][0])
データベースにどうやって複数のキー情報を登録しようか考えたのですが、SQL文でLIKE検索に引っかかるように、複数のキー情報をカンマ区切りで1つのフィールドに収めることとしました。こうすると取得したカンマ区切りの文字列を簡単にsplitでリストに戻せますし。
metadata追加
最後はtext_splitter.create_documentsの引数としてkeysを追加しました。
これにより、VectorDBのmetadataとしてkeysが追加されるはずです。
documents = text_splitter.create_documents(texts=[text], metadatas=[{
"name": topic_name,
"source": file,
"tag": tag,
"keys": keys_str,
"title": title,
"entry_name": entryName,
"patent_citation_text" : patentCitationText}]
)
プログラム実行
ではプログラムを実行してみます。
python chroma_retriever_tagging.py
めっちゃ処理時間が長い・・・1ファイルを処理するのに30秒くらいかかっています。
おそらくXMLの1つのタグ情報毎に更にキー情報を取得するためにChatGPTのAPIをコールしているのでしょう。お金も気になります・・・
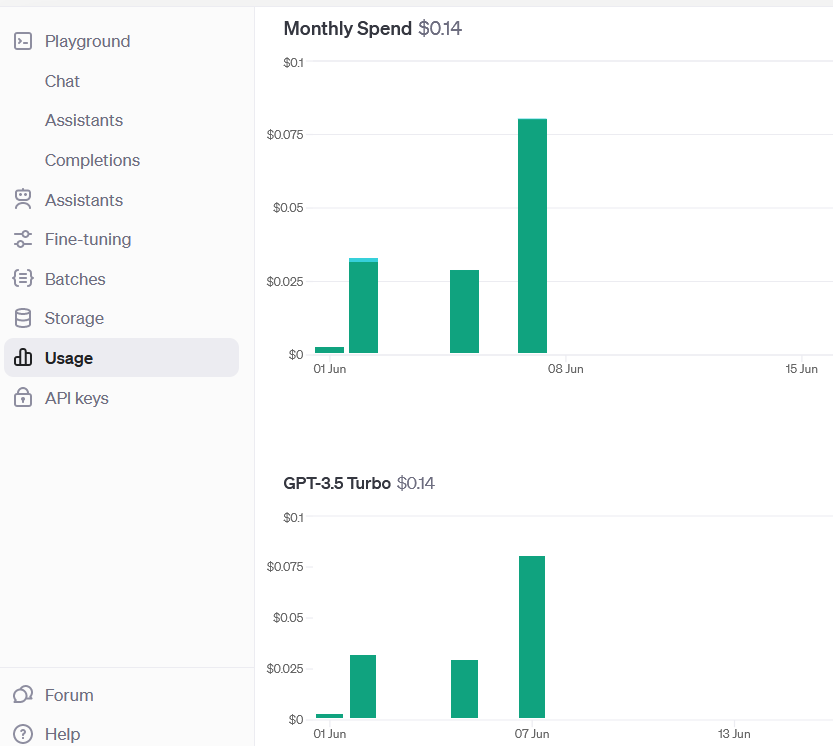
OpenAIの「Usage」を見ると6月8日(記事を書いた日)は「0.075$」で12~15円くらいでしょか。![]()
また、以前はembeddingでtext-embedding-ada-002を採用していたために、ものごっつ金額がかかっていたのですが、embeddingについてのコストを確認することができませんでした。text-embedding-3-smallは本当に安いかもしれませんね。
VectorDBの確認
次にVectorDBを確認することにします。

いつものごとく「DB Browser forSQLite」で確認することにします。
「embedding_metadata」の「key」カラムに「keys」を含むレコードが追加されています。
「keys」だけを抽出してみましょう。
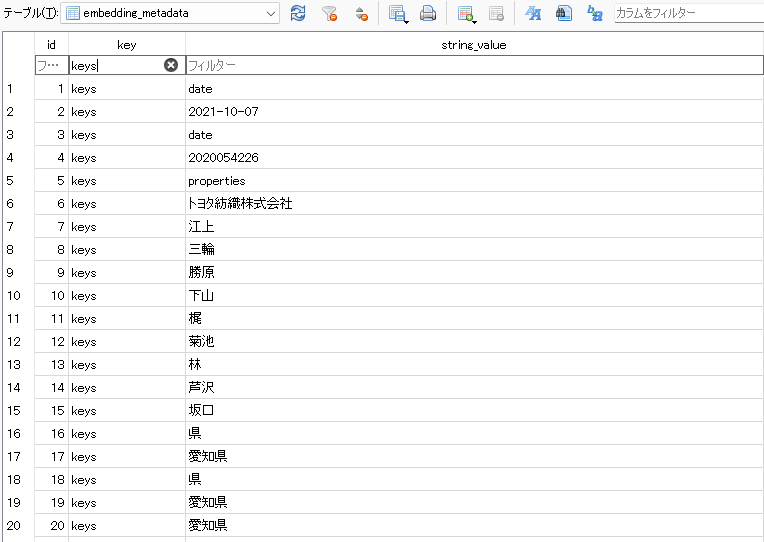

XMLファイルの最小の方は日付や会社名・人物名が続くので、それらがキー情報になっているのが分かります。また、40行目以降は文章の中からキーワードを抽出していることが分かります。
これはうまくいった感じがします。キー情報に引っかかったレコードに含まれるXMLファイル全体を対象にして、そこからいろいろな内容を抽出すれば、前回みたいにファイル名称を撃ち込まずともキー情報だけで精度の高い検索ができるかもしれません。
おわりに
今回は、taggingを適用してVectorDBのデータを作成することを実施しました。
生成AIが自動的にタグ付け(キー情報付与)をしてもらえるのであれば、とても便利ですね。
ただ、VectorDBの生成にかかる時間が多くなっているのも心配です。
追々解決していきたいと覆います。
次回は、streamlitで、キーワード検索をして、思った通りの情報が取り出せるかを確認したいと思います。