はじめに
落語心中
ここ最近、「昭和元禄落語心中」というアニメ(漫画)にハマっているわけですが、
調べてみると"古典落語"のテキストデータが公開されているようなので、これを元にChainerのLSTMで落語を生成したら面白い結果にならないかなと思い、試してみました。
Chainerのインストールについては、過去記事で書いたのでそちらを参照ください。
http://qiita.com/oggata/items/22e4512821a3ce2590d0
古典落語テキストデータ
http://www.asahi-net.or.jp/~ee4y-nsn/rakugo/00menu.htm
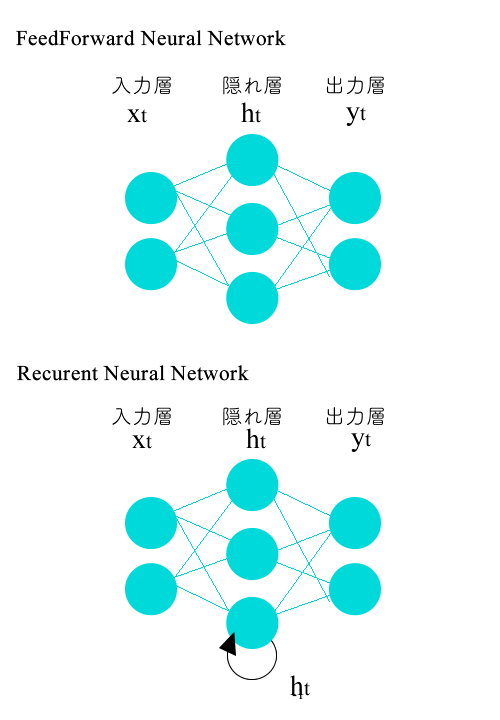
FeedForward Neural Network と Recurent Neural Network の違い
通常のNeuralNetworkでは、特定の入力に対して出力が導かれますが、RNNではニュートラルネットワークを再帰的に扱えるようにし、時系列のモデルの解析が可能になっています。
例えば、"湯を"から連想される動詞は"飲む"などが推測されそうですが、
"風呂で、湯を..."という前の文脈があった場合には"沸かす"の方がより良い推測であると言えます。
このように過去の情報を記憶して、結果を出力できることからLSTMは文章の生成などに用いられることが多いようです。
辞書作成は、文字単位?単語単位?
LSTMに文章を学習させるときに、基本的に入力に対する正解は(次の文字or単語)になります。
文字単位で辞書を作成する場合は、正解は次の文字になり、
単語単位で辞書を作成する場合は、正解は次の単語となります。
例
(文字単位)
我/輩/は/猫/で/あ/る
(単語単位)
我輩/は/猫/で/ある
手順
コード
chainerでLSTMを使う方法をいろいろ調べていたらこちらのコードを使っている方が多かったので、
自分も参考にさせていただきました。
$ git clone https://github.com/yusuketomoto/chainer-char-rnn.git rakugo
$ cd rakugo
$ python train.py
input.txtにデータを書く
vim data/rakugo/input.txt
訓練する
$ python train.py --data_dir data/rakugo --checkpoint_dir cv/rakugo --gpu -1
train_lossが収束していく
1/8038, train_loss = 7.84989990234, time = 0.61
2/8038, train_loss = 7.71635498047, time = 0.99
3/8038, train_loss = 6.4572869873, time = 1.03
..
8037/8038, train_loss = 2.20953674316, time = 1.33
8038/8038, train_loss = 2.19822174072, time = 1.22
vocabとmodel
訓練を行うと辞書データとmodelデータというものが出来上がります。
(辞書データ)
一部pirntしてみるとわかりますが、
text <--> id
になっています。
文章学習のときに、入力ベクトルと正解ベクトルのミニバッチを作成するときに、
正解ベクトルは、入力文字の1文字後(単語区切りの場合は、1単語後)になります。
このときに、ベクトル化されたデータと、実際の文字(単語)のリレーションのためにvocab(辞書)が必要になります。
(modelデータ)
訓練したデータのことです。
(イメージ)
文章 -> (vocab) vector && word -> x_batch,y_batch(<-vector) -> 結果(vector) -> 辞書で vector -> wordに戻す
ジェネレートして見る
$ python sample.py --vocabulary data/rakugo/vocab.bin --model cv/rakugo/latest.chainermodel --primetext "落語心中" --gpu -1 --length 100
modelデータはepochごとにversion番号が付けられてインクリメントされていきます。
学習を重ねた方がより良いデータになっていることを信じて、ここはlatest.chainermodelを指定していますが、徐々に賢くなっていく様子は途中のmodelを使うことによって確認できるかもしれません。
ざっくりと中身を理解
ネットワークの設計
入力次元に辞書(vocab)の長さ(例:10個の文字の辞書であれば10ユニットが入力次元になる)と、
(中間層のユニット数(ニューロン数)、中間層の層数についてどのように設計して良いのか、
まだよく理解できていないが、ネットワーク設計者が試行錯誤しながら、ニューロン数を変化させていくのが普通であるらしい。)
model = CharRNN(len(vocab), n_units
↓
ここでは3段のLSTMを使っている
super(CharRNN, self).__init__(
embed = F.EmbedID(n_vocab, n_units),
l1_x = L.Linear(n_units, 4*n_units),
l1_h = L.Linear(n_units, 4*n_units),
l2_h = L.Linear(n_units, 4*n_units),
l2_x = L.Linear(n_units, 4*n_units),
l3 = L.Linear(n_units, n_vocab),
)
optimizerの決定
RMSProp, AdaDelta, Adamなどいくつか有名なものがあるので選択して使う。
optimizer = optimizers.RMSprop(lr=args.learning_rate, alpha=args.decay_rate, eps=1e-8)
入力と正解のデータを作成
ミニバッチの生成。ここでは+1文字のデータをy_batch(正解)として学習させている
x_batch = np.array([train_data[(jump * j + i) % whole_len]
for j in xrange(batchsize)])
y_batch = np.array([train_data[(jump * j + i + 1) % whole_len]
for j in xrange(batchsize)])
入力値と正解を学習させる
state, loss_i = model.forward_one_step(x_batch, y_batch, state, dropout_ratio=args.dropout)
過学習を防ぐためにdropout率を設定
h1_in = self.l1_x(F.dropout(h0, ratio=dropout_ratio, train=train)) + self.l1_h(state['h1'])
c1, h1 = F.lstm(state['c1'], h1_in)
逆伝搬
accum_loss.backward()
truncated backprop
truncated backpropと呼ばれる手法で
入力と状態のシーケンスがメモリに収まらないほど長い時
短い間隔でバックプロパゲーションを打ち切る
accum_loss.unchain_backward()
optimizer.update()
ジェネーレートの方法
state, prob = model.forward_one_step(prev_char, prev_char, state, train=False)
probability = cuda.to_cpu(prob.data)[0].astype(np.float64)
probability /= np.sum(probability)
index = np.random.choice(range(len(probability)), p=probability)
出力結果
落語心中が計って開け聞けるというものは」
ね「年見合われると何か先者の町内でございます。酒は」
辰「左らかありません。それが急う者が参ろうに申しますよ」
客「ウム、この通りじゃァ皆な御前《めふ》がノシンといってるんだすね」
権「そんなどでも方のんや/\と言う訳もあるものか。女房は起ころこれな事を申す事にする 馬鹿な小《めき》でもゝう、モウ一遍留めて、女房どんに人間の面《から》をして逃げなければ、私は病気になりますそうに着きます。そないにお気が出て火の玉へ寝ていて
甚「そうね、お“先方に平伏は好《い》いね。じゃァいねえだ、我々は瓦ァと何よくなるから遊びにそういうんだ、いう御暇分な事を申すな」
泥「オイ/\此は運かジズ/\と着けてッたらねえ事をしなさった。アヽ御更に替え方が礼に有りと言われるもんだが」
伝「じゃァお前の所で彼《あ》れき先《かち》だって只今」
富「アハヽヽ」
八「モさ、お忙しいなはお前途中に買ってしまったんで、買うなら知って来たんだ」
熊「ちょっと御酒《おとら》をお出しをした」
清「そんな事を吐《くれ》えたから……」
まっけたらば、稲上をくれなかったら、寝ておるのだ」
甚の泥「魚を言
おしまい
考察
元のデータは会話形式になっていることや、読み仮名が書かれていることなどから、
今回出力した結果は同じように会話形式で、また読み仮名(らしき)ワードが含まれていて、それっぽい結果にはなったかなとは思いますが、意味などは全く理解できません。
それにしても、やたら登場人物が多すぎるな...。
ちなみに、学習データを増やせばどうにかなるものだろうかと思っていたのですが、
「シンプルなRNN/LSTMだけでまともな文章はできない」
http://studylog.hateblo.jp/entry/2015/08/31/225124
に書かれているのは、やみくもに増やせば良いというわけではなく、
「前の文字列のみを素性とするのではなく文法素性や言語資源をふんだんにぶち込む」
とかこの辺りがキーになってきそうな気がします。
日本語のコーパス
さて、今回は落語のデータをコーパスに使いましたが、
そもそも、LSTMを使って、何か実験的に覚えさせてみようと思っても、使える日本語のコーパス自体が少ないようです。他のLSTMの文献を調べると下記のようなコーパスを使っている例が多く見られました。
wikipedia
LiveDoorコーパス
青空文庫
ニコニコデータセット
ちゃんとした日本語を作るにはまだまだ工夫が必要そうですが、とりあえず、LSTMをざっと学ぶことができました。
おまけ
JavaScriptでLSTMを使うことができるライブラリがあるようなので、次回はこの辺りを使って何か作ってみたいと思います。
https://github.com/karpathy/recurrentjs