はじめに
これは「imtakalab Advent Calendar 2023」の22日目の記事です。
こんにちは!現在、私立理系大学4年生の者です。
最近、趣味の一環?として「音楽の自動生成」について勉強をする機会がありました。本記事では自分の復習の意図も込めて、音楽の自動生成についてざっくり紹介していきます。
対象読者
- 研究室の方々
- 音楽の自動生成の初学者の方
音楽の自動生成とは
音楽の自動生成とは、人工知能(AI)やアルゴリズムを使用して音楽を自動的に作成することです。
特徴として、
- AIが音楽の構造、リズム、メロディー、ハーモニーなどを学習し、それらの要素を組み合わせて新しい曲を生成できる
- クラシック、ジャズ、ポップ、電子音楽など、多様なジャンルの音楽を生成できる
- 特定のジャンル、テンポ、調などのパラメータを指定して、希望に応じた音楽を生成できる
などが挙げられます。
まずは音楽を手動生成してみよう
まず先に、音楽データを扱うために用いる MIDI について説明します。
MIDI とは、電子楽器間で演奏情報をリアルタイムにやり取りするための規格です。大半の音は MIDI データで扱うことができます。
MidoでMIDIファイルを生成する
Midoとは、MIDIデータを読み書きするためのPythonライブラリーです。
以下のコードを参考にしてみましょう。
Google Colaboratory で実行可能です。
!pip install mido
!apt install -y fluidsynth
!pip install midi2audio
from mido import Message, MidiFile, MidiTrack
from google.colab import files
from midi2audio import FluidSynth
from IPython.display import Audio
fs = FluidSynth()
mid = MidiFile()
mid.ticks_per_beat = 480
track1 = MidiTrack()
track1.append(Message("program_change", channel=0, program=0, time=0))
track1.append(Message("note_on", channel=0, note=60, velocity=100, time=0))
track1.append(Message("note_off", channel=0, note=60, velocity=100, time=480))
track1.append(Message("note_on", channel=0, note=62, velocity=100, time=0))
track1.append(Message("note_off", channel=0, note=62, velocity=100, time=480))
track1.append(Message("note_on", channel=0, note=64, velocity=100, time=0))
track1.append(Message("note_off", channel=0, note=64, velocity=100, time=480))
track1.append(Message("note_on", channel=0, note=65, velocity=100, time=0))
track1.append(Message("note_off", channel=0, note=65, velocity=100, time=480))
track1.append(Message("note_on", channel=0, note=67, velocity=100, time=0))
track1.append(Message("note_off", channel=0, note=67, velocity=100, time=480))
mid.tracks.append(track1)
mid.save("song.mid")
audio_file = 'output_audio.wav'
fs.midi_to_audio('song.mid', audio_file)
Audio(filename=audio_file)
ピアノの音で「ドレミファソ」が生成できたはずです。
少しプログラムについて解説します。
mid.ticks_per_beat = 480
- MIDIファイルの1拍(ビート)あたりのティック数を定義
track1.append(Message("program_change", channel=0, program=0, time=0))
-
program_change
- MIDI チャンネル上の楽器を変更
-
channel=0
- 送信する MIDI チャンネルを指定
- MIDI では通常、0から15までの16チャンネルがある
-
program=0
- 使用する楽器を指定
- 0はピアノを意味している
-
time=0
- 始まるタイミングを指定
- 曲の開始時点(0)で楽器を変更
track1.append(Message("note_on", channel=0, note=60, velocity=100, time=0))
track1.append(Message("note_off", channel=0, note=60, velocity=100, time=480))
-
note_on
- その音を開始する
-
note_off
- 特定の高さの音を止める
- note_onメッセージと同様の設定で、同じ音を止める
- 特定の高さの音を止める
-
channel=0
- この音が鳴るチャンネルを指定
-
note=60
- 音の高さを指定
- 60は中央のC(C4)を意味
- ピアノでの真ん中ぐらいの高さの「ド」
-
velocity=100
- 音の強さを指定
- MIDI 通常、0(無音)から 127(最大音量)までの範囲で指定
-
time=0
- 音を鳴らすタイミングを指定
-
time=480
- 音を止めるタイミングを指定
- 480 を指定することで 4 分音符分の長さで音を止める
このように、プログラムを用いて音楽を手動で生成することができます。
トラック数を増やして音を重ねてみたり、さまざま楽器で試したり、なんてこともできます。
音楽を自動生成してみよう
ここから、音楽の自動生成になります。
自動生成と言ってもアプローチはさまざまです。
例えば、確率最大化があります。これは、確率が最も高いメロディ(音符列)を求めるというものです。条件(入力)が一緒なら得られるメロディは常に同じようであり、「与えられた条件に最も合う唯一のメロディがあるはず」という考えが元です。
また、サンプリングがあります。これは、与えられた(または学習した)確率分布に基づいた乱数を得てメロディを決めます。条件(入力)が一緒でも、得られるメロディは毎回変わり、「与えられた条件に合うメロディは複数ある」という考えが元です。
どちらを使うかは、曲や研究次第です。
今回は、サンプリングを扱います。
データから音高の出現割合を求める
ここからは、細かい解説は省略し音楽の自動生成に焦点を当てていきます。
今回は、「Infinite Bach」というデータセットを用います。
Bachのコラールを中心にMIDIファイルとMusicXMLが収録されたデータセットです。MIDI ファイルの中には、さまざまな調(音楽の型のようなもの)が混在しており、全て学習させても上手くいきません。なので、学習させるデータを絞ります。
今回は、長調の曲だけで学習し、得た確率分布から音楽を生成してみましょう。
Google Colaboratory で実行可能です。
まずは、確率分布を求めます。
!pip install pretty_midi
import glob
import pretty_midi
import numpy as np
import matplotlib.pyplot as plt
# PrettyMIDIオブジェクトと調情報に基づいて、ハ長調 or ハ短調に移調する関数
def transpose_to_c(midi, key_number):
for instr in midi.instruments: # MIDIデータ内のすべての楽器に対してループ
if not instr.is_drum: # ドラムトラックでない場合
for note in instr.notes: # その楽器の全てのノートに対して、ピッチを指定されたキー番号分だけ減少
note.pitch -= key_number % 12
dir = "drive/MyDrive/chorales/midi/"
# 各MIDIノート番号の出現回数をカウントのため
counts = np.zeros(128)
# フォルダ内の全てのmidファイルを参照
for f in glob.glob(dir + "/*.mid"):
print(f)
midi = pretty_midi.PrettyMIDI(f) #ファイル読み込み、midi変数に格納
# key_signature_changesの要素数が1じゃなかったらスキップする(曲の中の調の個数)。(0:情報なし、1より大きい:転調ありの曲、1:転調なしの曲)
if len(midi.key_signature_changes) != 1:
print("skip")
continue
# key_signature_changes の要素(番号)を取り出す
key_number = midi.key_signature_changes[0].key_number
# 要素数が一個とわかったので、長調か短調の判定
# 長調の範囲外ならスキップ
if not (0 <= key_number <= 11):
print("Not in major key.")
continue
# transpose_to_c関数を呼び出す(PrettyMIDIオブジェクトと調情報に基づいて、ハ長調 or ハ短調に移調する関数)
if len(midi.instruments) > 0:
for note in midi.instruments[0].notes:
counts[note.pitch] += 1
unigram = counts / np.sum(counts)
print(unigram)
得た確率分布を、グラフにして出力してみます。
plt.bar(np.arange(0, 128), unigram)
plt.show()
以下のようなグラフが得られたかと思います。
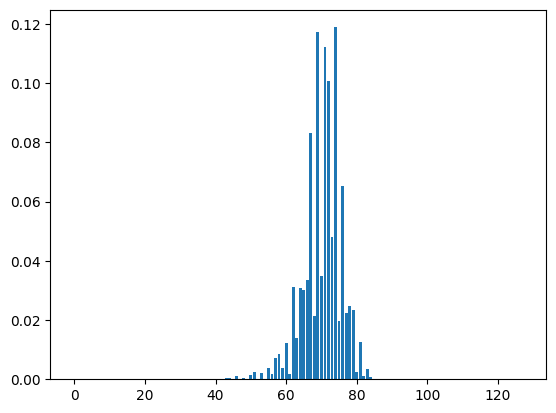
横軸は音の高さ、縦軸は確率を表しています。
では、得られた確率分布から、音楽を自動生成してみましょう。
import pretty_midi
import numpy as np
from scipy.stats import rv_discrete
unigram = np.load("drive/MyDrive/chorales/unigram.npy")
notenums = np.arange(128)
distr = rv_discrete(values=(notenums, unigram))
div = 480
midi = pretty_midi.PrettyMIDI(resolution=div, initial_tempo=120)
instr1 = pretty_midi.Instrument(0)
for i in range(4 * 4):
pitch = distr.rvs()
instr1.notes.append(pretty_midi.Note(100, pitch, i*0.5, (i+1)*0.5))
midi.instruments.append(instr1)
midi.write("melody.mid")
# MIDIファイルからオーディオファイルを生成
audio_file = 'output_audio.wav'
fs.midi_to_audio('melody.mid', audio_file)
# 生成されたオーディオファイルを再生
Audio(filename=audio_file)
音楽は生成できましたか?
生成された音楽に違和感を感じるはずです。
それは、データから音の出現確率のみを学習させて曲を生成しているからです。
これらに、音楽的ルールをプログラムに加え上げる(音の遷移確率を調整したり、2音以上なら不協和音にならないようにするなど)ことによって、自分や大衆にとって、尤もらしいと言える音楽を自動で生成できるようになります。
おわりに
本記事では、音楽の自動生成についてざっくり紹介しました。
ここで説明したものは、音楽生成分野のほんの一部であり、私なりの解釈なので、あくまで参考程度として考えていただければ幸いです。