Google Code Jam2020のQualification Roundに参戦しました。
結果は75点で約4万4千人中806位でした。
予選ラウンドより先に進むためには30点取ればよく、得点状況はリアルタイムで分かるので大半の人は30点を超えた時点で諦めていたと思います。
ですが、ぼくはおよそ20時間ほど粘りました(最終Submitこそ16時間でしたが)
正直AtCoder緑でここまで問題を解くことが出来て自分でも信じられないのですが、結果は嘘をつかないので参戦記としてまとめてみようと思います。
解説
A. Vestigium
N列N行からなる正方行列がT個与えられます。それらのトレースkと、同じ数字が含まれる行数r, 同じ数字が含まれる列数cを出力してください。
まぁ最初に「トレースってなんぞや?」となるのですが、2行目に「対角線の合計値(左上から右下に走るもの)とあることに気が付きましょう。
行列Mの各要素をM[r][c](0 <= r,c < N)と表してあげると、トレースはリスト内包表記を用いて
k = sum([m[j][j] for j in range(n)])
のように表せます。リスト内包表記に慣れない人はfor文を用いて
k = 0
for j in range(n):
k += m[j][j]
のようにしても良いでしょう。
また、「同じ数字の含まれる列(行)の数」は、それぞれの列または行に対して同じ数字が含まれるかどうかを判定し、もしそうなら値をインクリメントさせてゆく、という方法が簡単に実装出来ると思います。同じ値が含まれているかどうかは、それらのリストの要素数と、それらを集合(重複を許さないリスト)にしたときの要素数を比較すると得られます。
以下実装例です。
t = int(input())
for i in range(1,t+1):
n = int(input())
m = [[0] for j in range(n)]
r = 0
c = 0
for j in range(n):
m[j] = list(map(int,input().split()))
if len(m[j]) != len(set(m[j])):
r += 1
for j in range(n):
tmp = [m[k][j] for k in range(n)]
if len(tmp) != len(set(tmp)):
c += 1
k = sum([m[j][j] for j in range(n)])
print("Case #"+str(i)+": ",end="")
print(k,r,c)
20行程度に収まるのでそこまで難しくはないと思います。
B. Nesting Depth
数列Sが与えられるので、それらをネストさせ、各数字の左右を囲う括弧の数が各数字と等しくなるように出力してください。
各数字はSmall解が0と1から成る数列であり、Large解には0~9の数字が含まれます。
数列Sはint型で受け取ってしまうと先頭の0が受け取れない場合があるので、String型で受け取らなければなりません。
そのあとに最初の数字の数だけ"("と最初の数字を出力します。
あとはそれ以降の各文字に対して
- もし前の文字より大きければ、差の数だけ"("を出力
- もし前の数字より小さければ、差の数だけ")"を出力
- もし前の数字と同じなら何もしない
- 数字を出力
という作業を繰り返し、最後に最後の数字の数だけ")"を出力してあげればいいです。難しいことは何もありません。Largeも通ります。
というかむしろSmallだけを通す解法をコーディングするのが逆に難しそう、という印象を受けました。0 1を条件分岐するのでしょうが、その分岐を実装するくらいなら最初からこの実装をした方が楽なように思えてしまいます・・・
以下実装例です。
t = int(input())
for i in range(1,t+1):
t = list(str(input()))
print("Case #"+str(i)+": ",end="")
for j in range(len(t)):
if j == 0:
for k in range(int(t[0])):
print("(",end="")
elif int(t[j]) > int(t[j-1]):
for k in range(int(t[j])-int(t[j-1])):
print("(", end="")
elif int(t[j]) < int(t[j-1]):
for k in range(int(t[j-1])-int(t[j])):
print(")", end="")
print(t[j],end="")
if j == len(t)-1:
for k in range(int(t[-1])):
print(")",end="")
print()
C. Qarenting Partnering Returns
時間Sに始まり、時間Eに終わるN個のアクティビティが与えられます。人間CameronとJamieが与えられるので、N個のアクティビティを2人に割り当てて下さい。ただし、それぞれの人間は複数のアクティビティを同時に行うことは出来ないものとし、時間Eに終わるアクティビティを終了したと同時に時間Sに始まるアクティビティに取り組むことが出来るとします。また、アクティビティを上手く割り当て出来ない場合は"IMPOSSIBLE"を出力してください。
まず、アクティビティを前から順に処理するとWorong Answerになるのはなんとなく分かると思います。
手書きで申し訳ないのですが、例えば入力として
1
4
1 3
2 5
5 6
4 6
という例が与えられた場合、貪欲にCにアクティビティを割り当て、割り当てられない場合にJに割り当てる、という処理を行うと下の図のようになり、最後のアクティビティを割り当てることが出来なくなってしまいます。
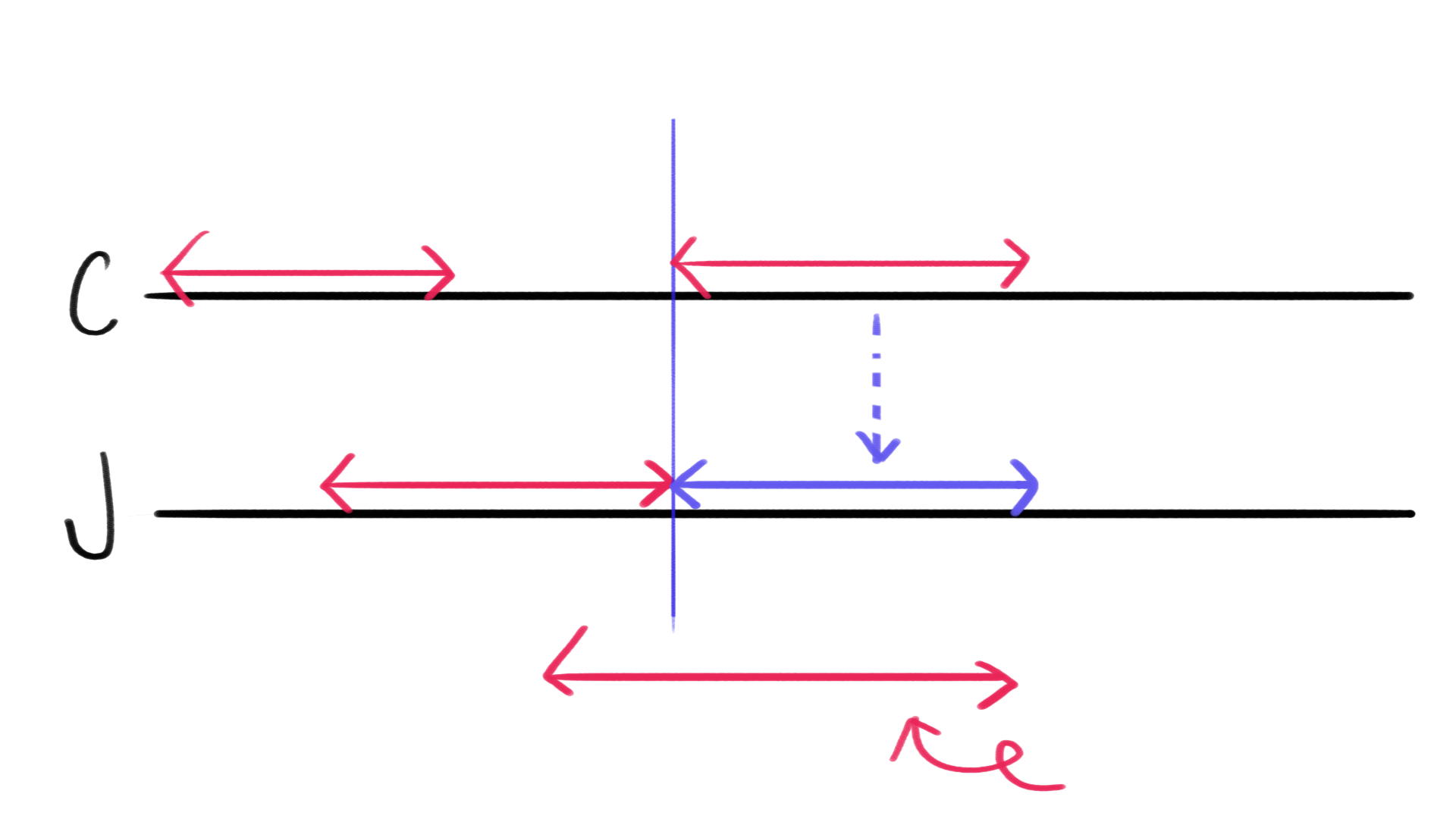
このような悲劇を避けるためには、アクティビティをSの昇順でソートしてあげてから貪欲に割り振っていけば良いです。
ただし、出力は与えられた順番に行わなければならないので、ソートする前に与えられた順番を何らかの形でメモしなければなりません。実装の注意点はそのくらいです。
以下実装例です。
t = int(input())
for i in range(1,t+1):
n = int(input())
tasks = [0] * n
for j in range(n):
tasks[j] = list(map(int,input().split()))
tasks[j].append(j) #アクティビティの追加された順番を保持
tasks.sort(key=lambda x: x[0]) #Sの昇順でソート
ans = [str()] * n
C = 0
J = 0
for j in range(n):
if tasks[j][0] >= C:
C = tasks[j][1]
ans[tasks[j][2]] = "C"
elif tasks[j][0] >= J:
J = tasks[j][1]
ans[tasks[j][2]] = "J"
else:
ans = "IMPOSSIBLE"
break
print("Case #"+str(i)+": ",end="")
print(*ans,sep="")
もしあなたが本番中にこのようなアルゴリズムを思いつかなかった場合、Bit全探索というアルゴリズムを用いることも出来ます。このアルゴリズムでは、アクティビティの割り当てのパターンを全て試すことで解答を得ます。Small解ではN<=10なので、これは十分間に合います。予選を抜けることだけを考えるならば、非常に有効な考え方です。
D. ESAb ATAd
この問題はインタラクティブ問題です
各テストケースでは、システム内部に長さBのバイト列(0と1からなる配列)を保持します。
数値Nを出力することにより、ジャッジはN番目のバイト列が何であるかを返します。
ただし、1番目、11番目、21番目・・・の出力(出力回数の下一桁が"1"となる場合)の場合は、システム内部のバイト列に対して以下の事象がそれぞれ25%の確率で発生します。
- 0と1が反転する
- 配列が逆になる
- 0と1が反転し、配列が逆になる(上2つの事象が同時に発生する)
- 何も起こらない
プログラムは上記の事象のうち、何が発生したかを直接得ることは出来ません。
最終的には、現在システム内部に保持しているバイト列を出力してください。
この問題では、そもそもインタラクティブ問題とは何か、それをテストする環境を構築できるか、というところでつまずきます。そもそもテストをGoogleのサーバーのジャッジシステムで行うことが出来ないので。
インタラクティブ問題は、システムジャッジと提出するコードが対話をすることによって解答を導き出す形式です。対話の方法ですが、自分のプログラムが出力した数字に対してシステムジャッジが数値を出力するので、それを入力として受け取ることで可能になります。
環境構築は思ったより面倒ではない(Pythonの導入と、プログラムを2つダウンロードするだけ)なので、やっておいて損はないと思います。
詳しくはこちらを参照してください。
補足として、サンプルを試す場合にツールを実行する場合、
$ python interactive_runner.py python testing_tool.py 0 -- python solve.py
としますが、この問題では
$ python interactive_runner.py python testing_tool.py 1 -- python solve.py
$ python interactive_runner.py python testing_tool.py 2 -- python solve.py
のようにすると、Largeなど他のサンプルを試すことが出来ます。
マジで英語読めない人用にダウンロードリンクを張り付けておきます。
interactive_runner.py
testing_tool.py
実装上必要になるデバッグですが、標準エラー出力を使わないとジャッジがエラーを吐いてしまいます。めちゃくちゃ使うので、関数化したほうが良いと思います。
次に、問題が意味不明でつまずきます。ぼくも問題の解読にかなりの時間を要しました。
それに関しては、ぼくがめちゃくちゃ丁寧に解読した文章を先ほど皆さんがご覧になられましたので、パスしたことにします。
次に制約ですが、
- B = 10 (1pt)
- B = 20 (9pt)
- B = 100 (16pt)
となっています。つまり、途中に説明されている部分のうち、確率的にバイト列が反転したり逆になったりする現象はSmall解では無視して良いことになります。
Medium解ではそれを意識して解答する必要があり、Large解ではジャッジの数字を返す回数の上限、150回以内に収めることが出来るかどうかを考慮して解答する必要があります。
Small解では1~10の数字を順に出力した上で、ジャッジが返した数値を順に配列に保持してそれを出力すればよいので、全く難しいことはありません。このポイントを獲得できるかどうかは、問題文を理解できるかどうかです。
以下実装例です。
t,b = map(int,input().split())
for i in range(1,t+1):
ans = [0] * b
for j in range(b):
print(j+1)
ans[j] = int(input())
print(*ans,sep="",flush=True)
exit()
Medium解、Large解では25%で起こる4つの事象(問題文では「ランダムな量子的揺らぎ」と表現されている)のうち、何が起こっているかを判断する必要があります。
この4つの事象は、それぞれ2つの事象(バイト列の01反転と、バイト列の逆転現象)が独立して起こっていると考えることが出来ます。よって、4つのうちどれが起こっているか?という問題ではなく、それぞれ2つの事象が起こったか / 起こっていないかを判定すれば良いです。
ここでは説明のために、N番目のバイト列をB[N]と定義します。Nの範囲は1 <= N <= Bです。(この問題ではそう定義付けられている)また、NにおいてB == -1, B-1 == -2とします。(後ろから見たときの順序を負数で表す)
まず配列を取得する順番ですが、1 -> -1 -> 2 -> -2 -> 3 ...のようにすると良い感じになります。理由をこれから説明します。
この時、N[a]とN[-a]を考えます。
N[a] == N[-a]である場合において、ランダムな量子的揺らぎによる数値の変化が生じたときは、100%バイト列の0と1が反転する事象が起こったことが分かります。なぜならば、バイト列が逆になったとしてもその2つの値は変化しないからです。
次に、N[a] != N[-a]である場合においては、ランダムな量子的揺らぎによる数値の変化が生じたときは、バイト列の0と1の反転する事象、もしくはバイト列が逆転する現象のどちらかが起こったと考えられます。もし、どちらも起こっていた場合には元に戻るので、判定できません。
以上の2つの性質を利用すると、以下の手順でランダムな量子的揺らぎの事象のうちどれが起きたかを判定することが出来ます。
- N[a] == N[-a]であるaと、N[b] != N[-b]であるbを保持する。
- ランダムな量子的揺らぎが発生するタイミングにおいて、以下の手順を行う。
- N[a]を調べる。事前に取得している数値と異なった場合は、数値の01反転が起こっているため、現在取得している値のすべてを反転させる。
- N[b]を調べる。ここでは、数値の01反転の可能性が直前のステップで取り除かれているため、事前に取得している数値と異なった場合は全て、バイト列の逆転現象によるものだとすることが出来る。つまり、そのような場合には現在所持しているバイト列を逆転させる。
このようにすると、2回でランダムな量子的揺らぎを判定することが出来ます。
ランダムな量子的揺らぎは10回周期で発生するため、10回数値の取得 -> 2回を判定に用いる -> 8回数値の取得 -> 2回を判定に用いる...と繰り返すと、バイト列の長さ100であるLarge解でも十分に間に合うことが分かります。(124回の操作でバイト列を全て取得することが出来ます。)
ここで一応、ランダムな量子的揺らぎを判定する時点で
- 全ての文字列が異なった場合
- 全ての文字列が同じだった場合
について考えてみます。全ての文字列が異なった場合、文字列の01反転と逆転現象は、どちらが起こっても同値になります。よってどちらかが起こったか、起こっていないかを考えれば良いです。
全ての文字列が同じだった場合、01反転のみ判定すればよいです。逆転が起こっても数値は変化しないからです。
考察上ではこのように場合分けしなければならないですが、実装上ではこのような条件分岐を深く考える必要ありません。
簡単に言えば、aとbのどちらかしか存在しなかった場合は、01判定のみ判定すれば良いです。しかし、そのようなことをすると判定回数がズレてしまい面倒なことになるので、1回虚無を判定することによって回数を調整します。
ぼくは考察が煮え切らないまま実装を始めてしまったので汚いコードになってしまいましたが、一応自分の提出したコードを置いておきます。
t,b = map(int,input().split())
for i in range(1,t+1):
ans = [False] * b
head = 0
foot = b-1
cnt = 0
change = False
same = False
while True:
print(head+1)
ans[head] = int(input())
print(foot+1)
ans[foot] = int(input())
if ans[head] != ans[foot] and change is False:
change = head
elif ans[head] == ans[foot] and same is False:
same = head
cnt +=2
head += 1
foot -= 1
if not cnt%10 and not b==10:
cnt += 2
if not same is False:
print(same+1)
tmp = int(input())
if ans[same] != tmp:
for j in range(head):
ans[j] ^= 1
for j in range(foot,b):
ans[j] ^= 1
else:
print(1)
_ = input()
if not change is False:
print(change+1)
tmp = int(input())
if ans[change] != tmp:
for j in range(head):
ans[j], ans[b-j-1] = ans[b-j-1], ans[j]
else:
print(1)
_ = input()
if head -1 == foot:
break
print(*ans,sep="",flush=True)
_ = input()
exit()
E問題 - Indiciumに関しては、Large解が思いつきませんでした。よって、詳しい解説はしません。(どうしてもして欲しいという場合はリクエストしてください。)
ちなみにSmall解の考察を軽く話しますと、正方行列のトレースとして考えうる数値かどうかを最初に判定し、考えうる数値だった場合にはそれでありうるトレースを持つ正方行列を作成し、残りの開いたマスを深さ優先探索で全通り試す、という方法でSmallを通すことが出来ます。Large解は少しTwitterで調べても意味不明だったのでこれから精進したいと思います。
感想
初めての海外コンでしたが、翻訳サイトの力をフル活用することによって全ての問題文を理解することが出来ました。この点が一番心配だったので、少し安心しました。
Code Jam予選ラウンドの傾向としては、「このアルゴリズムを知らないと解けない」という問題が少ないように思えました。E問題以外はそうだと思います。ABCはやるだけでしたが、Dの深い考察を終わった後にACしたときのドーパミンはヤバかったです。(語彙力)
Round1を突破出来るのは全世界で4500人と狭き壁ですが、最後まで諦めずに全力疾走したいと思います。対戦よろしくお願いいたします。