はじめに
- 不審なIPアドレスを調査する際に、サーチ時間がかかることが少し悩ましい。少しの工夫で早く出来ないものか
- データモデルアクセラレーションとか使う以前にキーワード検索の延長で早くする方法がないか探していた
- そこでTERM()に出会って検証してみました。TERMは、ざっくりいうと、余計なデータまで無駄に検索せずピンポイントで指定した値を検索する方法の1つです
TERMとは
- TERMコマンドは以下のように検索することでindex=activedirectoryを対象に、172.20.220.12に一致する値のみを高速に結果を返してくれます
index="activedirectory" TERM(172.20.220.12)
- 一致する値のみというところがポイントなのですが、以下の例のようにsrc="172.20.220.12"と検索していても、実はSplunkは「.(ドット)」をMinor breakers(マイナーブレーカー)という区切り文字として認識し分割してindexingしています。
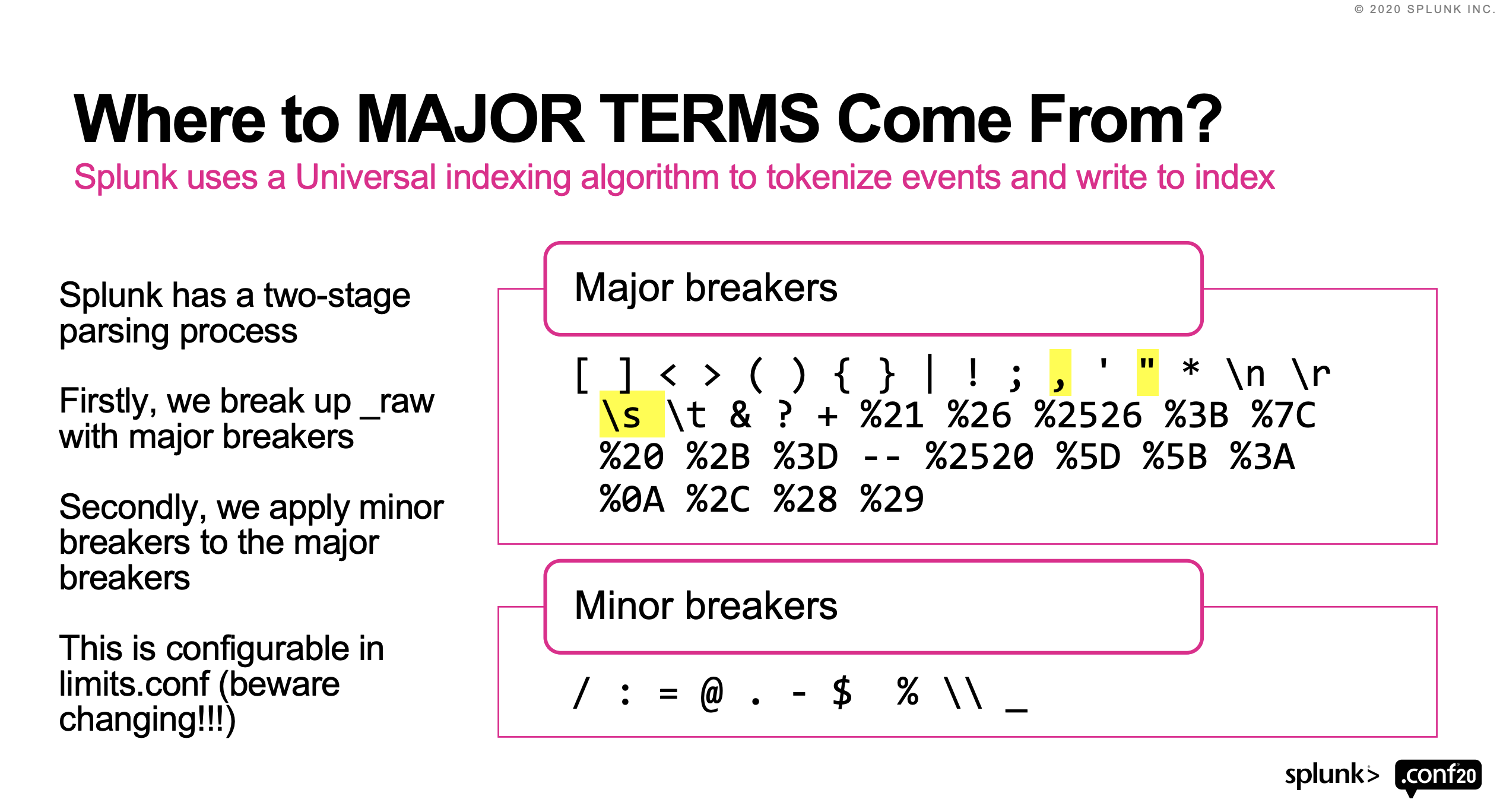
- 例えば、IPアドレスで127.0.0.1の場合、.のマイナーブレーカーで区切られるためindexされるとこんな形でTSIDXファイルに書き込まれます。赤枠の「127」と「0」と「1」と青枠の「127.0.0.1」でそれぞれindexingされることになります。
参考:Fields, Indexed Tokens,And You

- Index時だけでなく、またサーチをする際にもマイナーブレーカーごとに分割してデータを探しにいってしまうため余計なデータを探索しにいくことになります。つまり127.0.0.1のIPを検索すると[ AND 0 1 127]という形で分解してデータをサーチしにいきます。
参考:Fields, Indexed Tokens,And You

-
これの何が問題かというと、ずばりIPアドレスそのもの(127.0.0.1)を探したいのに、127と0と1のデータを探しにいく形をとってしまうことで無駄なサーチコストが発生します。
-
無駄とは、一致したデータ数(eventCount) / スキャン対象データ数(scanCount)のLispy効率*が悪いことをいいます。空振りサーチが多いことになります。
Lispyとは
Splunkの"Lispy"は、Splunkの検索クエリ言語であるSplunk Processing Language(SPL)の一部です。Lispyは、SPLのクエリ記述スタイルの1つであり、SPLをより簡潔かつ効率的に記述するための手法です。サーチバーに入力したSPLを内部でlipy形式に置き換えて、TSIDXにクエリをかける際に使われています
参考:Fields, Indexed Tokens,And You

- なお、以下のように""(ダブルクオーテーション)で囲って検索すれば、さも完全一致のIPアドレスだけ探してくれるのでは?と思いますが、実は.ドットのマイナーブレーカーに引っ張られて分割して検索しています。
index="activedirectory" src="172.20.220.12"
- そこでTERMの出番です。TERM(127.0.0.1)と明示して検索すると、ずばり127.0.0.1を探してきてくれます。127や0や1を探しに行かないため空振りサーチを抑えることが出来ます。

検証した事
- 以下2つのサーチを実行した際の検索スピードを比較してみました
①TERMなし
index="activedirectory" src="172.20.220.12"
VS
②TERMあり*
index="activedirectory" TERM(172.20.220.12) src="172.20.220.12"
※TERM(172.20.220.12)で検索しただけだとdestなどの他のフィールドにも合致してしまうため最後にsrc=で明示的に指定
-
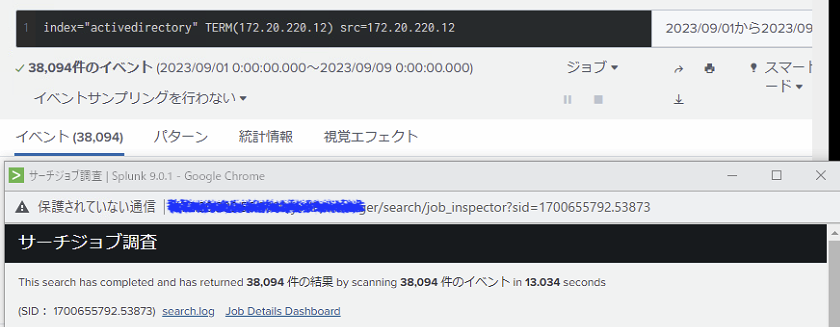
結果、TERMなしが134秒近くかかった検索が、TERMありだと13秒で終わる結果となりました。
-
TERMなし

-
TERMあり
-
ここでLispy効率に注目してみると、 TERMありのほうが無駄がないことがわかります。
| TERMなし | TERMあり | |
|---|---|---|
| eventCount | 38,094 | 38,094 |
| scanCount | 774,915 | 38,094 |
| Lispy効率 | 約0.05 | 1 |
| seconds | 144,492 sec | 13.034 sec |
結論
IPアドレスのようにマイナーブレーカーが含まれるデータを検索する際には、Lispy効率の高いTERM()を使うべし