※は筆者の追記、私見です
講演内容
講演名:
製品開発担当が語るドキュメント処理の未来と生成AIとの統合
発表者:
Andras Palfi(UiPath Senior Product Manager)
山崎 麟太郎(UiPath株式会社 プロダクトマーケティングマネージャー)
IDPとは?AI-OCRとIDPの違いとは?
IDP…インテリジェントドキュメント処理(Intelligent Document Processing)の略
※大量のデータから意味のある情報をスキャン、読み取り、抽出、分類、整理して、利用可能な形式にするワークフローの自動化テクノロジ
Microsoft:インテリジェントなドキュメント処理 (IDP) とはより
図や表をスキャンし、情報を読み取るという点ではAI-OCRと似ているが、下記のような違いがある
-
IDP
世界で開発・活用が進められている -
AI-OCR
日本独自の呼び方
それぞれ非構造データと呼ばれる、定型のフォーマットがないデータを認識・整理し、ロボットが利用可能な構造化データへの加工を行う
※非構造データ⇒構造化データのイメージ

UiPathが提供しているIDPソリューションと強み
提供ソリューション
-
Communications Mining
メールやチャットといったテキストベースのやり取りの中から、処理に必要なデータを認識・取得し構造化データへ加工する -
Document Understanding
スキャンした図表をフォーマットに関わらずデータを解釈・加工する
(いずれもUiPath Automation Cloudの導入が必須)
強み
-
上記ソリューションの性能・精度は世界的にも上位のリーダークラス
※今までのAI-OCRのようにIDPは別の製品を使う…といったほかのベンダーを介す必要がないので、導入時のハードルが低い・実装時のノウハウがUiPath社から得られるのが強みか? -
IDPの日本語対応アップデート
・Extended Language OCRにより日本語読み取り精度UP
・対応言語数アップ(292言語に対応)
・日本語請求書モデルの精度向上
・日本リージョンへの対応、UX向上
IDP×生成AI
※発表者の方が英語話者だったこともあり同時翻訳で聞いていたのですが、理解があいまいです…すいません
IDPの継続的なデプロイは様々な要因が絡み困難になりやすい
・コスト:専門的な知識・人材が必要
・複雑さ:パフォーマンスの監視・モデルの保守
それらの処理を生成AIを用いたラーニングによってより素早く、より高精度に行う
UiPath LLMs
UiPathのIDPをより使いやすくするためのテクノロジーを活用し、
精度の向上・より複雑な非構造化データの解析・時間短縮を行う
※LLM(大規模言語モデル)とは
大規模言語モデル(Large Language Models、LLM)とは、非常に巨大なデータセットとディープラーニング技術を用いて構築された言語モデルです。ここでいう「大規模」とは、従来の自然言語モデルと比べ、後述する3つの要素「計算量」「データ量」「パラメータ数」を大幅に増やして構築されていることに由来します。大規模言語モデルは、人間に近い流暢な会話が可能であり、自然言語を用いたさまざまな処理を高精度で行えることから、世界中で注目を集めています。
NRI:用語解説 大規模言語モデルとはより
-
Communications Mining
UiPath CommPath
複数のリクエストや追加のコンテキストを含む様々な種類の複雑なコミュニケーションを処理
(Ver 24.6よりリリース) -
Document Understanding
UiPath DocPath
長い非構造化データや表を含む、あらゆる文書を殆どトレーニング不要で即座に処理
(日本語版は'24/8月ごろのリリースを予定)
※ユーザーが意識して使うサービスというよりは、UiPath側で実装しているから今後もIDPの精度が上がっていくよという宣伝?
※参考ページ
製品紹介(日本語):Automation Cloud
製品紹介(日本語):Communications Mining
製品紹介(日本語):Document Understanding
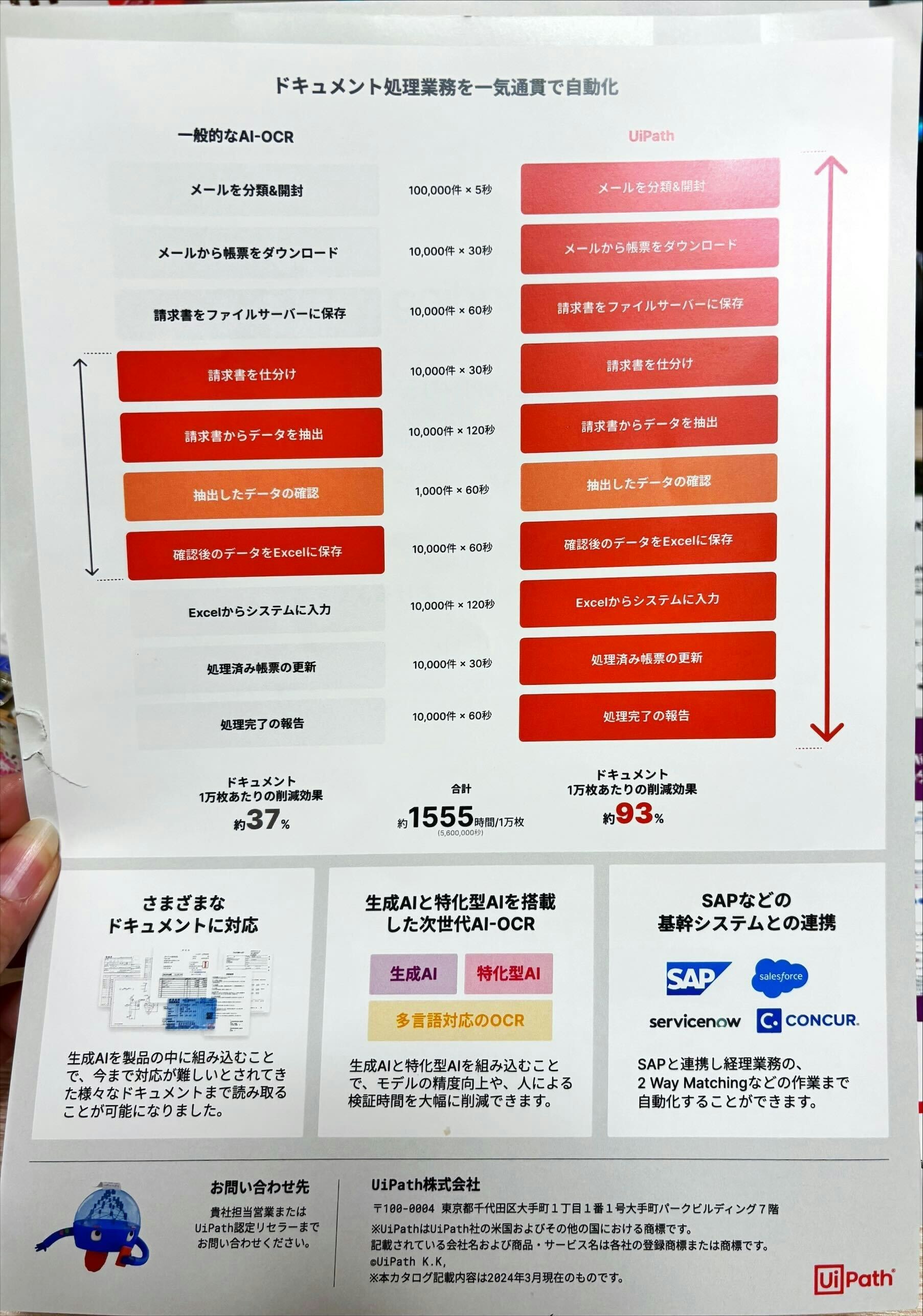
※参考資料(会場展示ボード)

※参考資料(会場配布リーフレット)
Automation Cloud


Communications Mining


Document Understanding