本記事は「AWS Amplify Advent Calendar 2020」の17日目です。
(16日目担当の Dyson さん、お誕生日おめでとうございました![]() )
)
経緯
今回は AWS Amplify の GraphQL API についての記事を書きます。
Amplify では GraphQL API を利用できますが、そのバックエンドのデータソースとしては DynamoDB を使われている方が多いかと思います。
実はこの GraphQL API のデータソースには、 DynamoDB だけでなく RDB として Aurora Serverless を指定できることを皆さんご存知だったでしょうか。
Amplify Docs > CLI > API(Graph QL) > Relational Databases
RDB で育ってきた私にとっては興味をそそられたのですが、上記リンクの記載例には1テーブルに対する Mutation の例しか記載がないようでした。(2020/12/16時点)
そこで、SQL 制約や複数テーブルの JOIN など、RDB でよく使うような基本的な機能が実現できるかを確認してみた、というのが本記事の内容です。
調査したこと
まずは環境構築
上記のリンクを見ながら、まずは環境を構築しました。
手順としては、まず事前に Aurora Serverless の DB クラスター、およびアクセス対象のテーブルを作成する必要があります。
DynamoDB を使う場合は、GraphQL のスキーマを作成して Amplify CLI で amplify push を実行すればよしなにテーブルが作られますが、RDB (Aurora Serverless) を利用する場合は Amplify CLI でのテーブル作成は行われない (2020/12/16時点) ため、手動で作成する必要があります。
今回はリンク先のガイドと同じ名前のDBクラスター、テーブル群を作成しました。
- テーブル作成時に実行したSQL文
CREATE DATABASE MarketPlace;
USE MarketPlace;
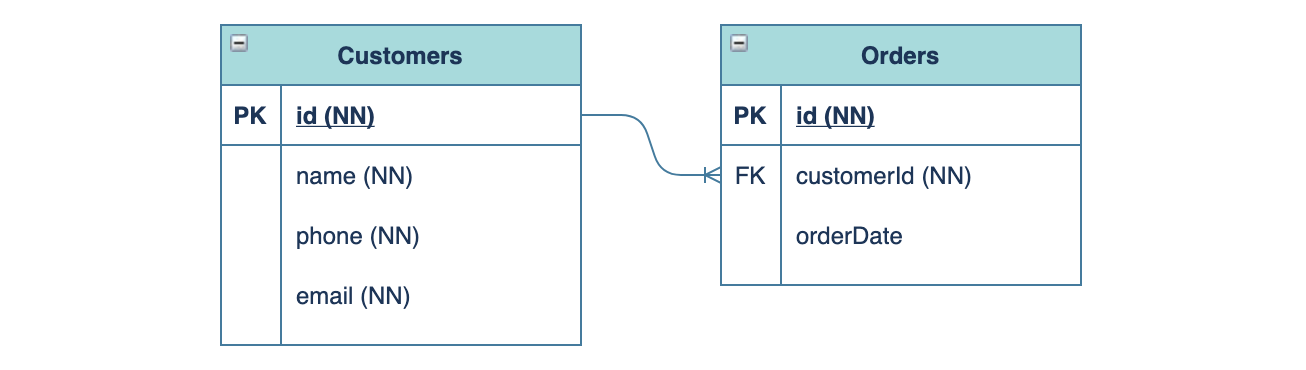
CREATE TABLE Customers (
id int(11) NOT NULL PRIMARY KEY,
name varchar(50) NOT NULL,
phone varchar(50) NOT NULL,
email varchar(50) NOT NULL
);
CREATE TABLE Orders (
id int(11) NOT NULL PRIMARY KEY,
customerId int(11) NOT NULL,
orderDate datetime DEFAULT CURRENT_TIMESTAMP,
KEY `customerId` (`customerId`),
CONSTRAINT `customer_orders_ibfk_1` FOREIGN KEY (`customerId`) REFERENCES `Customers` (`id`)
);
- ER図 (型やindexの記載は割愛)
上記のテーブル群までが作成された状態で、ローカル環境のPCで以下の手順を実行します。
- ワークディレクトリに移動
-
amplify initで Amplify CLI の初期化(必要に応じて AWS CLI プロファイルを作成) -
amplify add apiで Amplify の GraphQL API 機能を追加 -
amplify api add-graphql-datasourceで先ほど作成した Aurora Serverless DB クラスターをデータソースとして登録 -
amplify pushで AWS 上に GraphQL API をデプロイ
注:詳細手順はリンク先のガイドを参照ください。
デプロイが完了するまで待ちます。
作られたもの
amplify push が完了すると AWS 上に GraphQL API がデプロイされ、ローカルPC上で以下のようなものが作成された状態になります。
-
GraphQL スキーマ
テーブルごと、リクエスト / レスポンスごとに Mutation や Query のメソッドが自動生成された状態の GraphQL スキーマが作成されます。
※ ただし、後述しますが1つのテーブルに対する CRUD に関わる処理が記載され、複数テーブルの JOIN に対応するようなメソッドは見つかりませんでした。
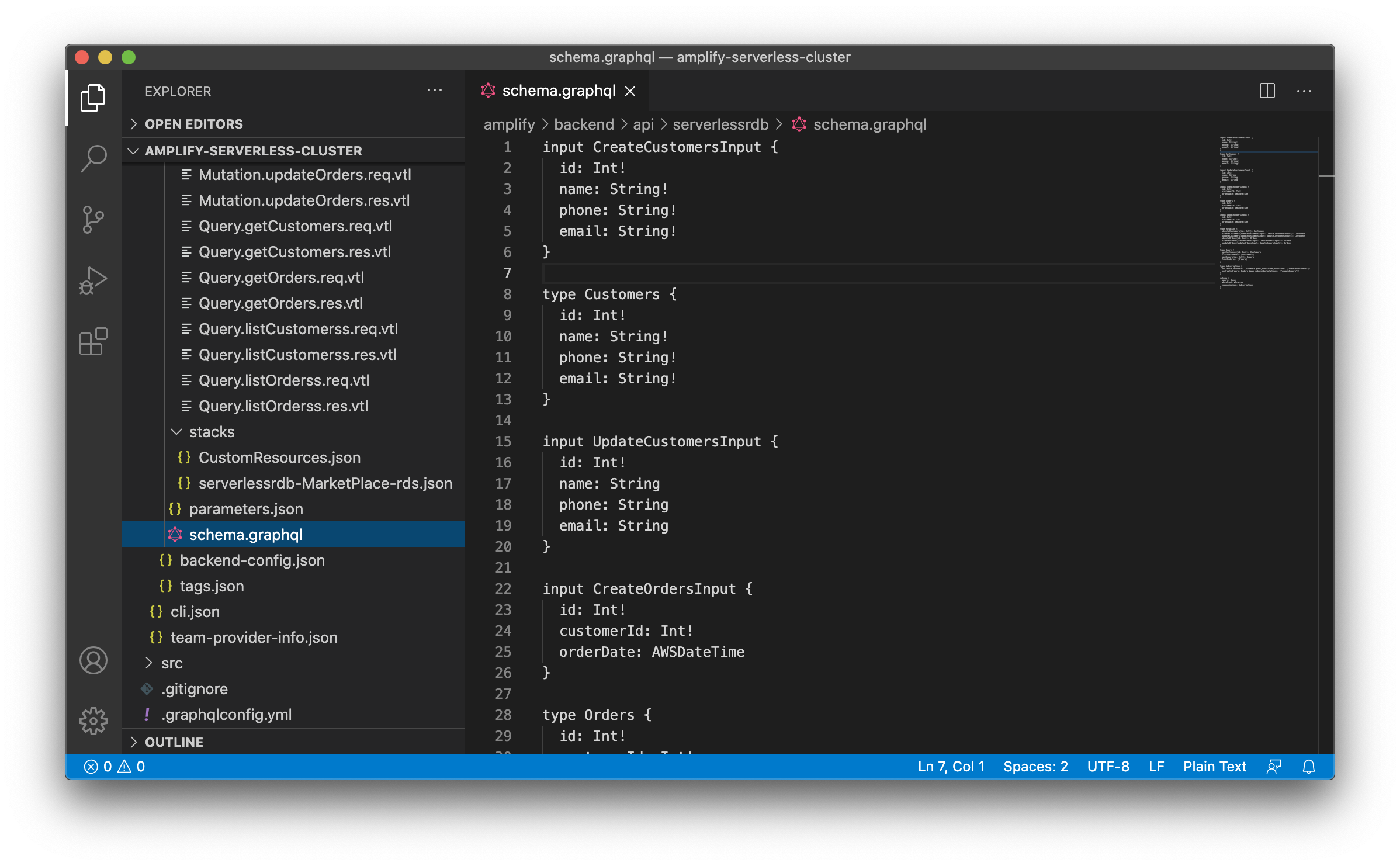
-
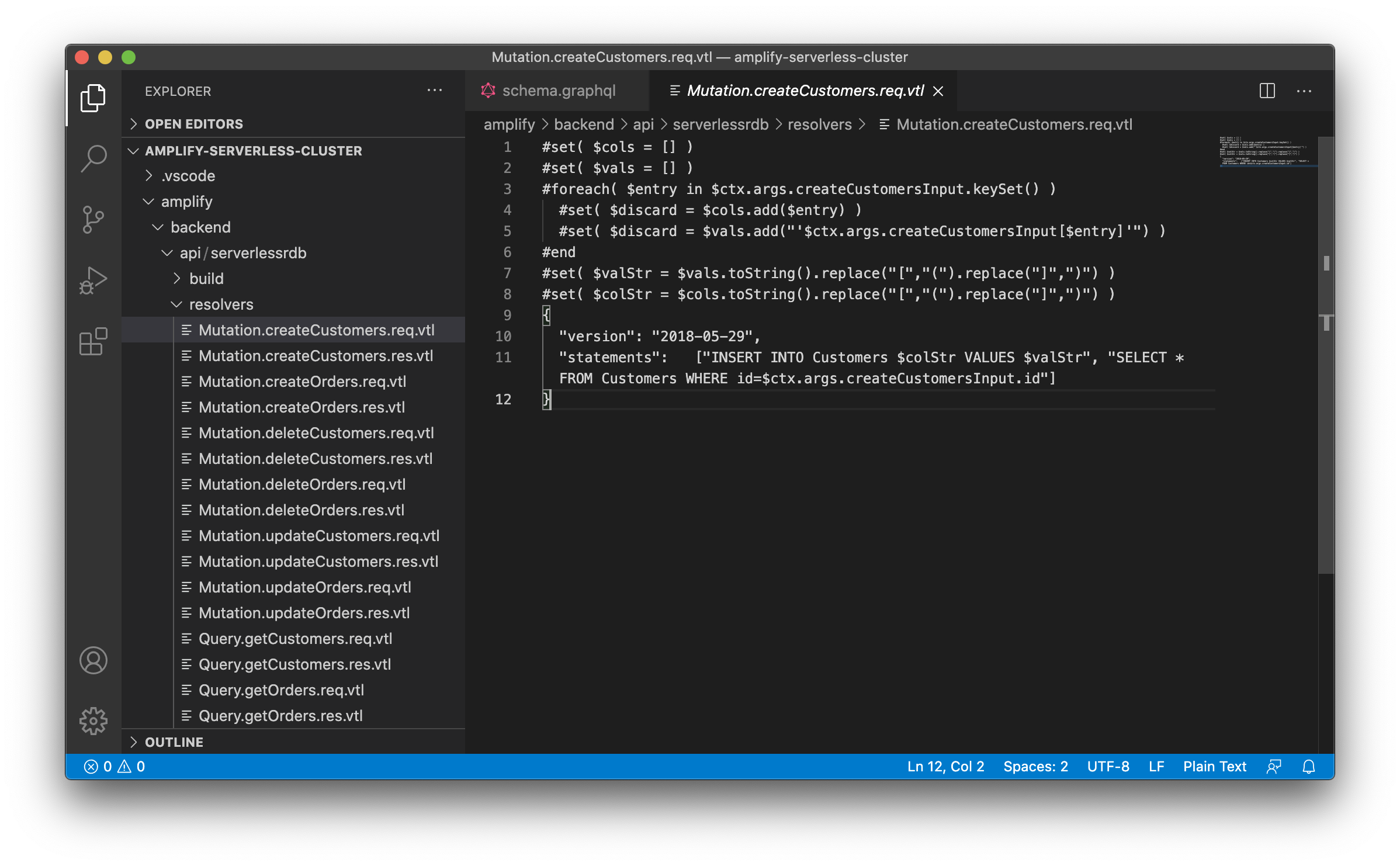
GraphQL リゾルバー
スキーマに書かれた Mutation や Query ごとに、VTL (Apache Velocity Template Language) で書かれたリゾルバーが配置されます。
リゾルバーには、バリデーション処理や呼び出される SQL ステートメントが記載されています。ここまでやってくれるとは驚きです。
※ ただし(同上)
他にもデプロイ時に実行された CloudFormation のスタック定義や、DynamoDB を使った場合にもできるような、フロントエンドで GraphQL を利用するためのソースコードの雛形を作成してくれます。(ここでは割愛)
GraphQL API を使った Aurora Serverless へのデータ登録
作成された GraphQL API を利用して Customers テーブルにデータを INSERT してみます。
ここでは、AWS AppSync のマネジメントコンソール上からクエリを実行してみます。
createCustomers を実行しましたが、右に結果が出ている通り、エラーなく実行されたようです。
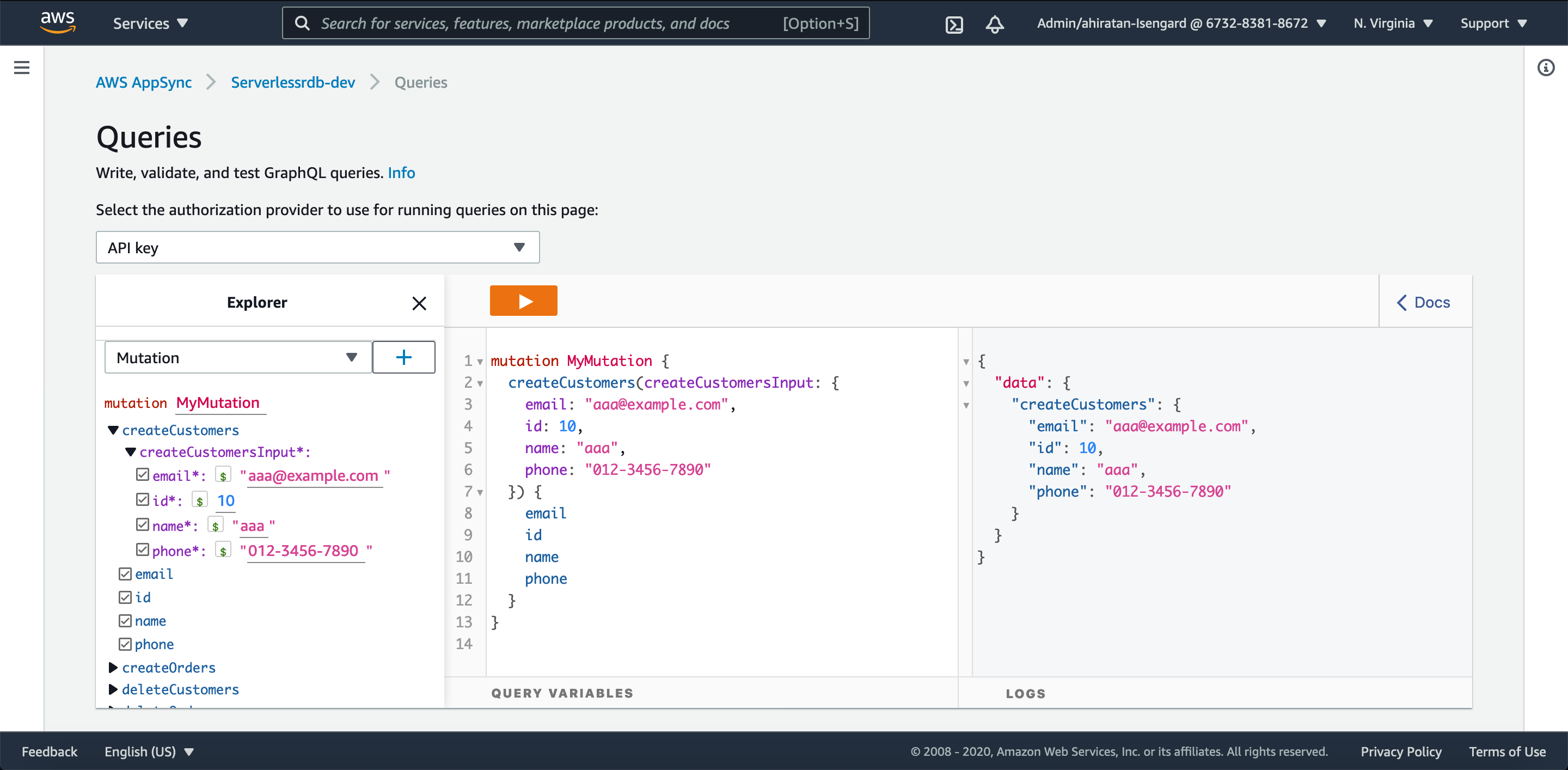
Aurora Serverless の方を見てみると、以下のように確かにレコードが追加されました。
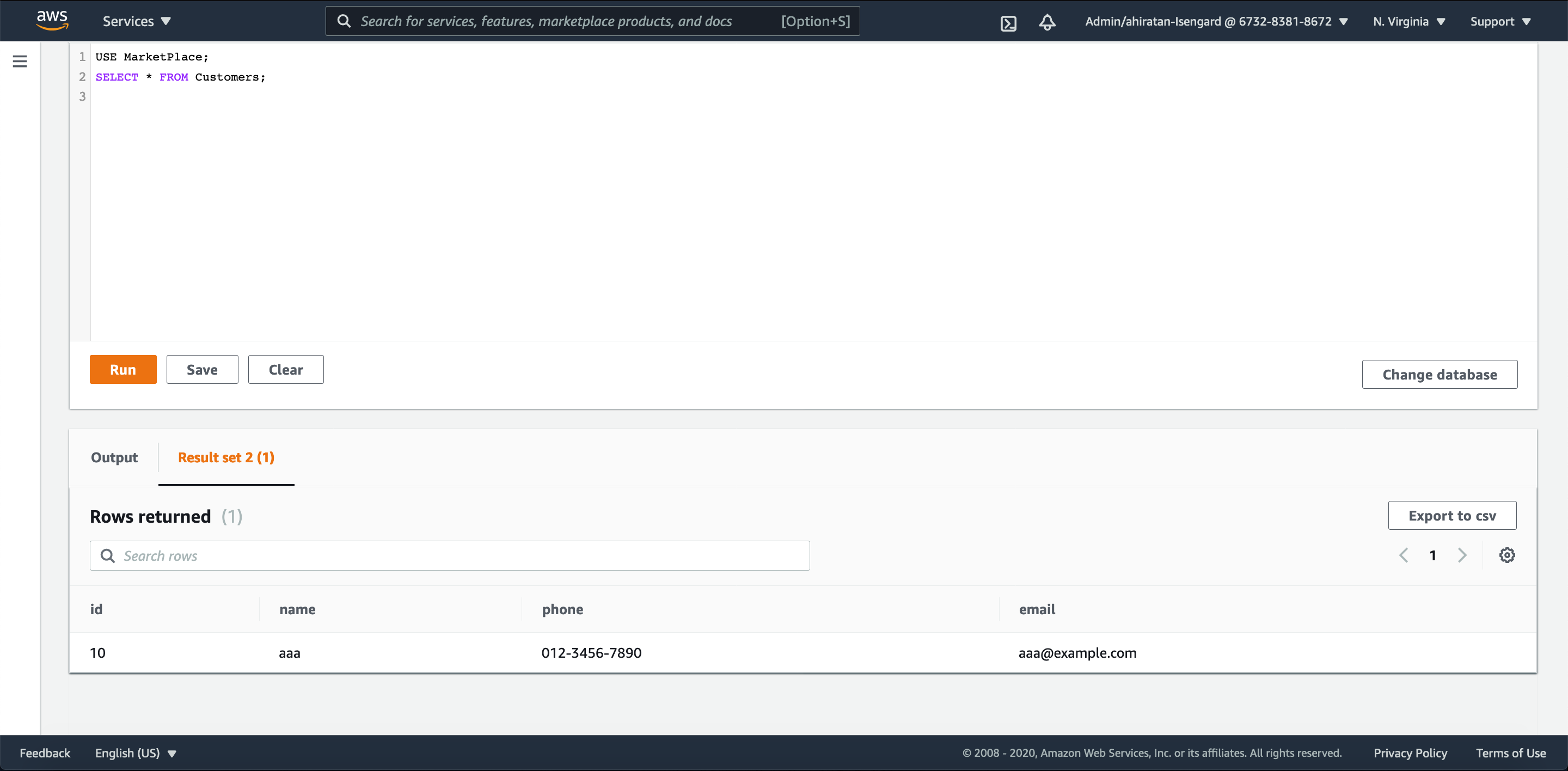
SQL 制約やデフォルト値の挙動
SQL 制約 - PK 制約
今度は PK 制約の挙動を確認するため同じ id でデータを登録するクエリを実行してみます。
エラーは出ませんでしたが、データが null で返ってきています。
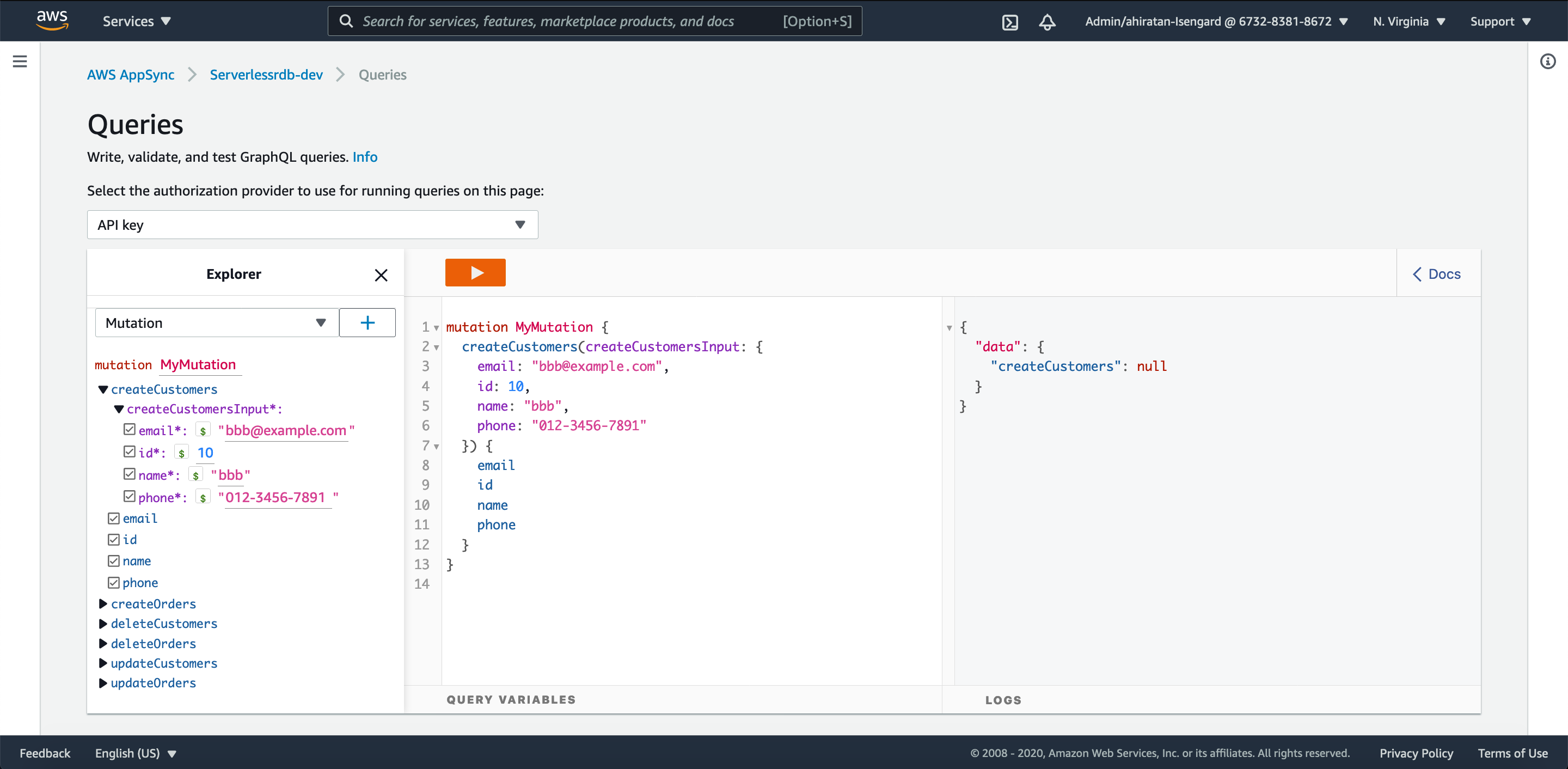
Aurora Serverless の方を見てみると、新たなレコードは追加されていません。
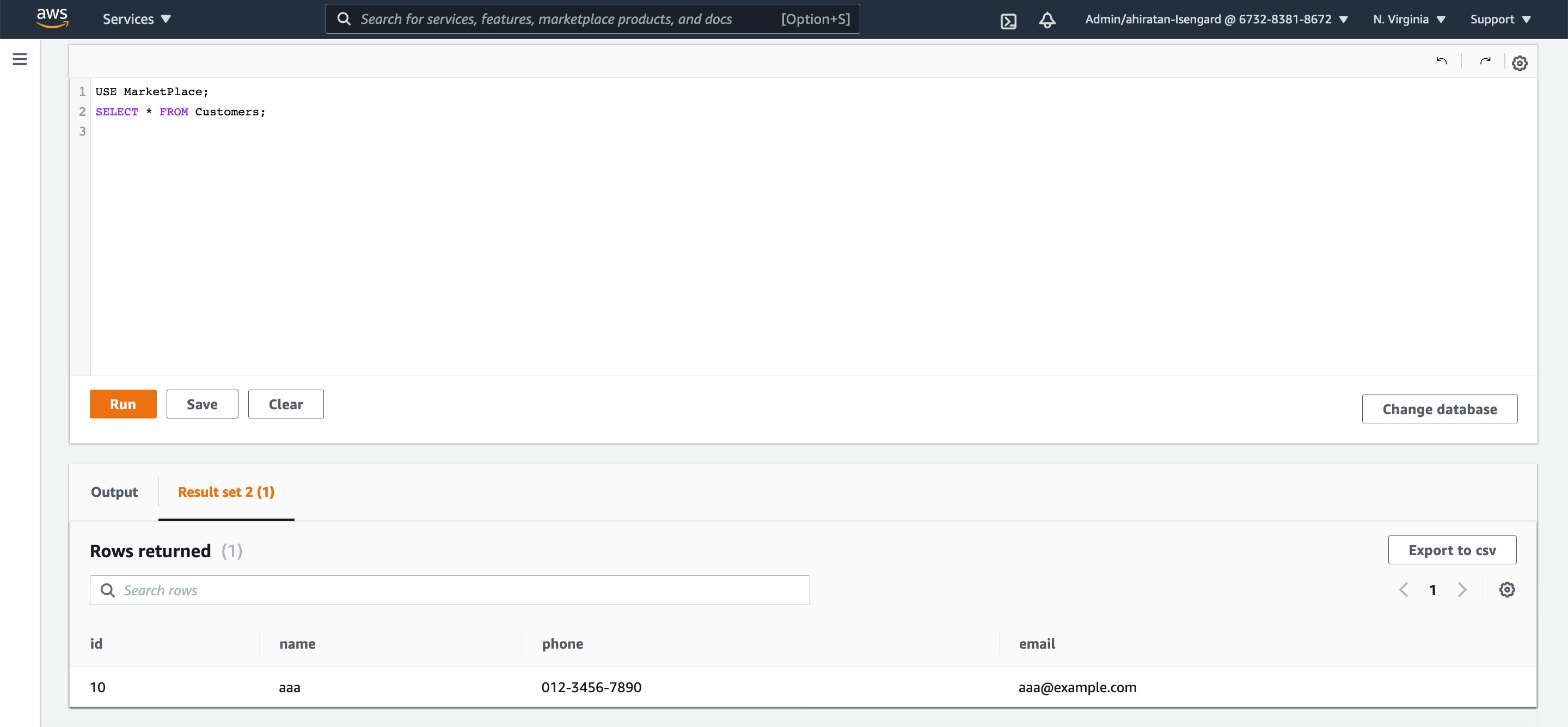
PK 制約に引っかかった場合はレコードが作成されず、data の部分が null となって返ってくる挙動のようです。
SQL 制約 - Not Null 制約
次に、Not Null 制約の挙動を調べるために、必須項目の email 属性を空(null)にしてクエリを実行してみます。
すると今度は errors の部分にエラーが表示されました。
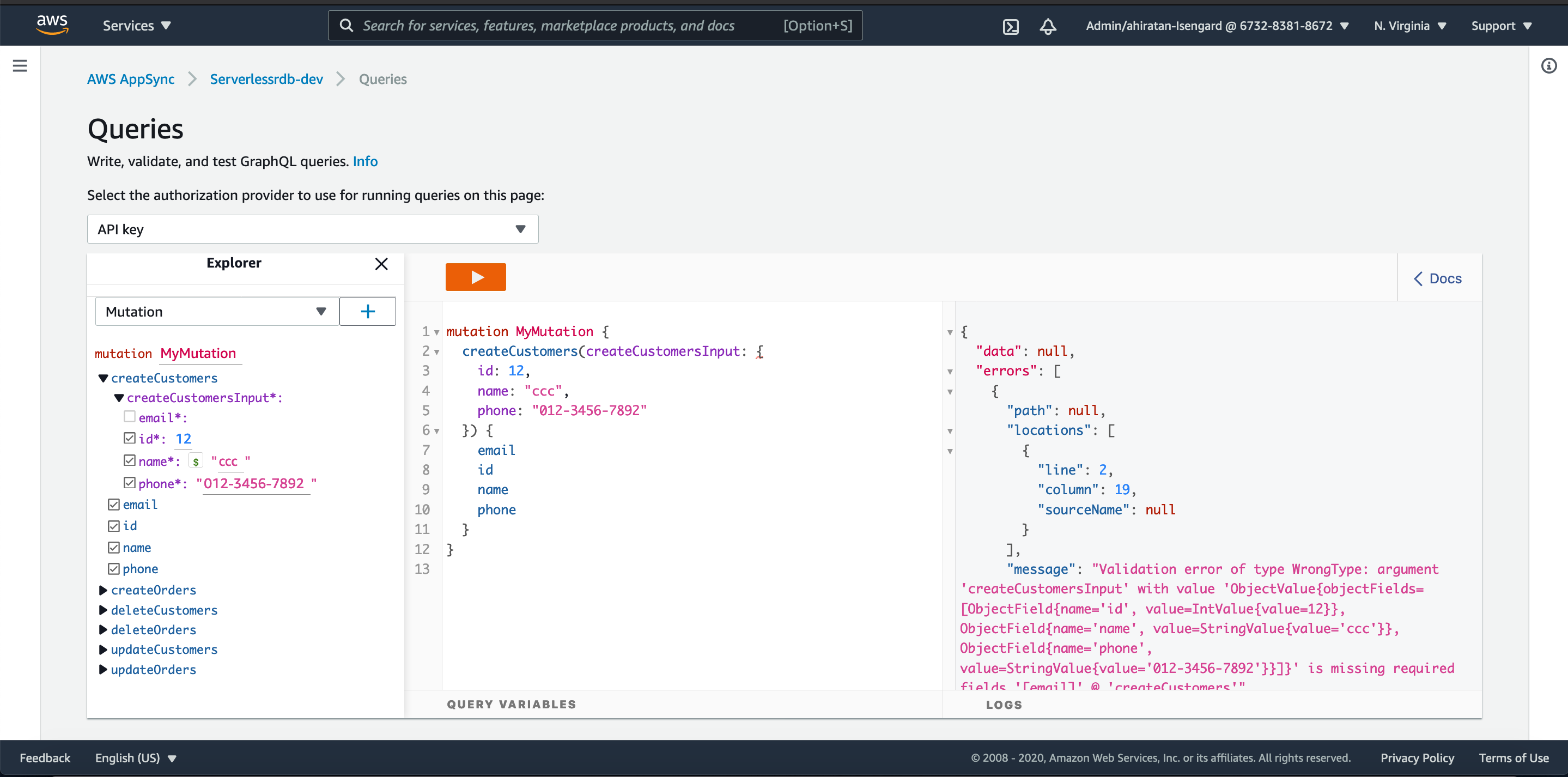
GraphQL の中で行われているバリデーション処理でのエラーが表示された模様です。
PK 制約と同様に data 部分が null となって返却され、Mutation 処理が完了していないことが分かります。一方で、エラー表示の有無について挙動が異なる点は注意が必要と思われます。
SQL 制約 - FK 制約
次に、Orders テーブルにデータを登録してみます。
FK 制約を確認するため、これまでの処理で未登録の customerId (=Customersテーブルのid属性)を入力してクエリを実行します。
すると、PK 制約に引っかかった場合と同様の挙動となりました。
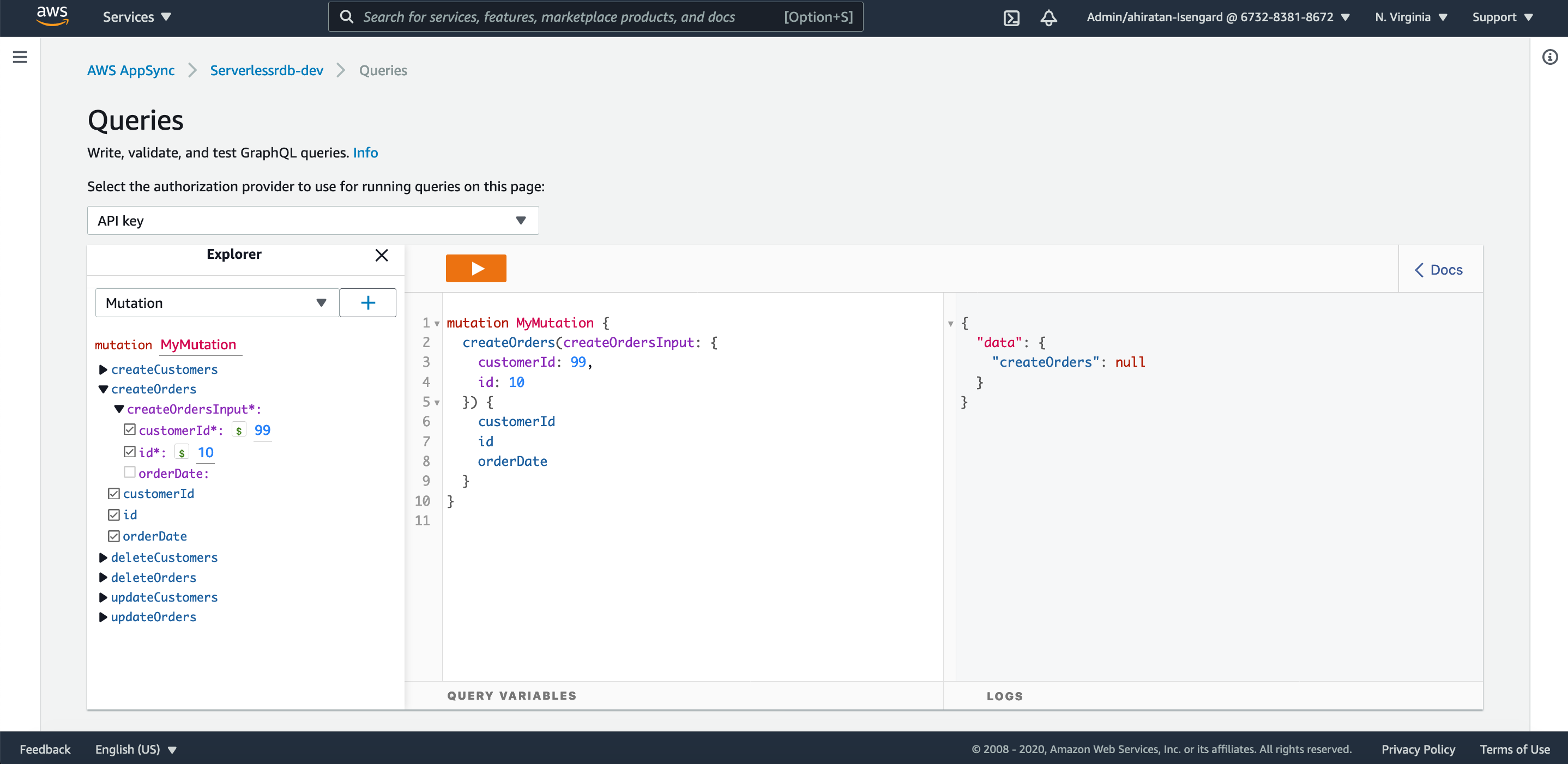
Aurora Serverless を確認すると Orders テーブルにはデータは登録されていませんでした。
PK 制約と同様、FK 制約に引っかかった場合はレコードが作成されず、data の部分が null となって返ってくる挙動のようです。
デフォルト値
最後に、デフォルト値について確かめてみます。
(他のSQL制約については今回の調査対象からは割愛)
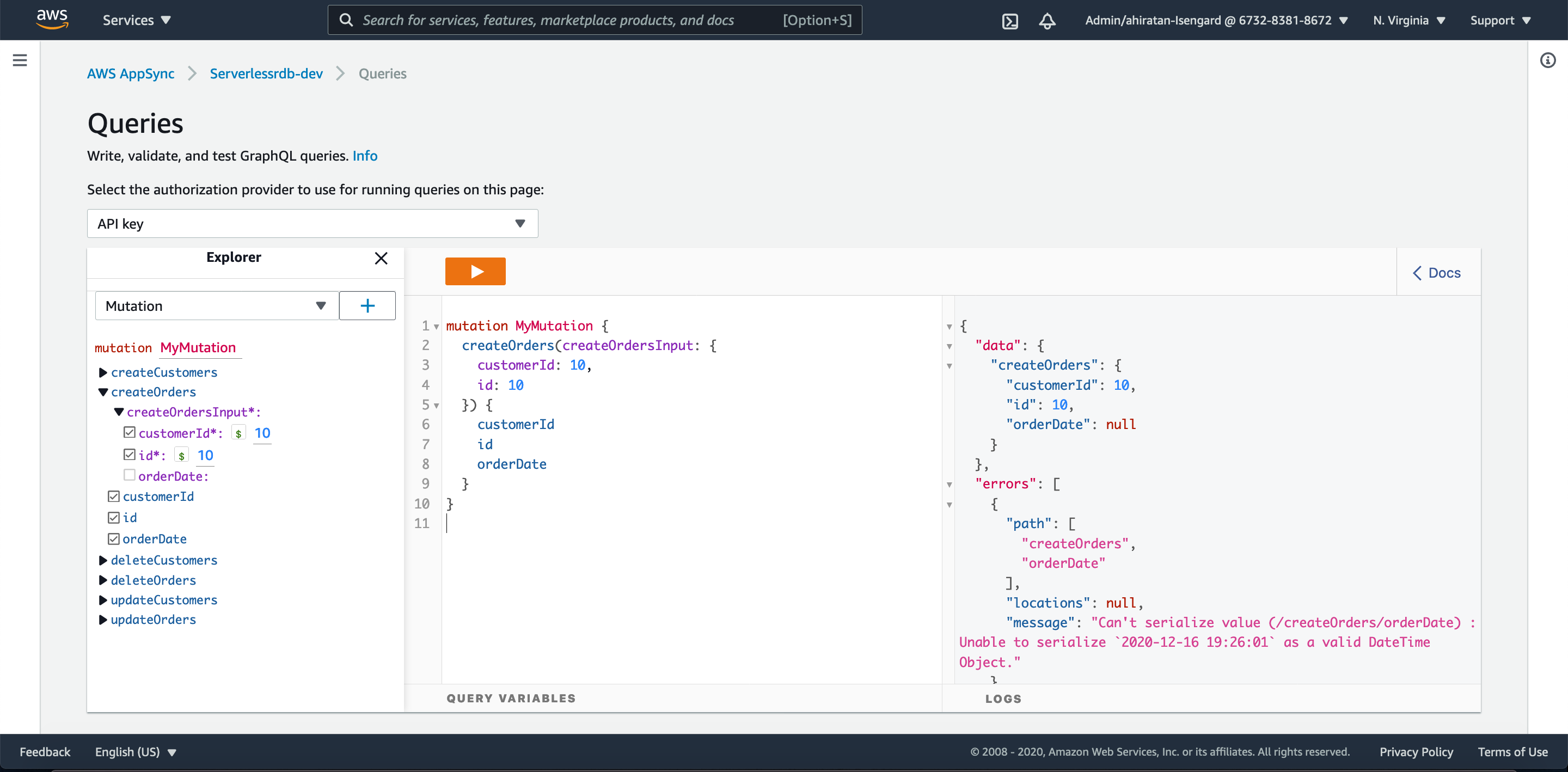
以下のように、orderDateを未指定で登録処理を行うクエリを実行します。
エラーが含まれていますが、data 部分は null でなく返り値があり、データが登録されたようです。
注:エラーはデフォルト値の現在時刻が設定されて返ってきたタイムスタンプ値を、GraphQL の型に変換し表示する際に生じている模様です(不具合か確認中)
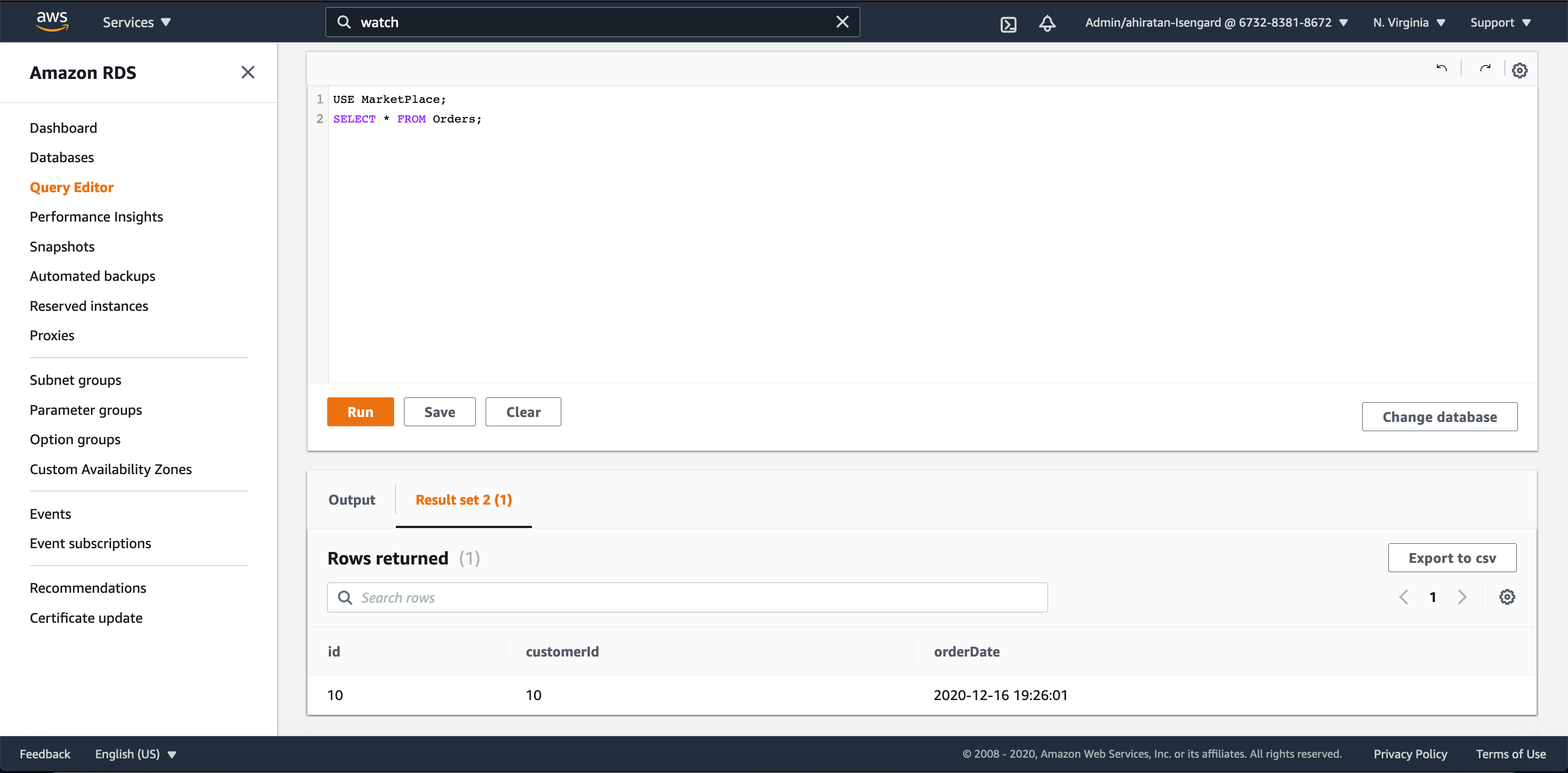
Aurora Serverless には、データ定義通りorderDateにはデフォルト値に現在時刻が入ったレコードが登録されていました。
ここで実行した、SQL 制約やデフォルト値の確認作業は異常となります。
2つのテーブルの JOIN 結果の取得
2つのテーブルの JOIN 結果の表示について考えてみます。
前述した通り、Amplify CLI によって作成された GraphQL のスキーマやリゾルバーを見る限り、1つのテーブルに対する CRUD に関わる処理は存在するものの、複数テーブルの JOIN に対応するものは見つかりませんでした。
したがって、GraphQL API の取得結果を自前で JOIN する場合は別ですが、GraphQL API を介して JOIN した結果を取得するためには追加の対応が必要のようです。
調べたところ、スキーマやリゾルバーを追加で作成する必要がある模様です。
今回は調査割愛しますが、VTL の書き方を含めて、ぜひ次回はここを掘ってみたいと思います。
まとめ
-
ドキュメントの記載通り、確かに Amplify CLI によって、RDB (Aurora Serverless) をデータソースにした GraphQL API を作成することができた

- RDB の機能である SQL 制約やデフォルト値を満たすクエリ結果が確認できたが、種類によってはエラーメッセージの有無など挙動が異なる部分があった

- 1つのテーブルへの CRUD 処理に対応する GraphQL スキーマやリゾルバーは自動作成されたものの、複数テーブルの JOIN 結果など複雑なクエリについては現状自動作成されないため(2020/12/16時点)、その部分は自作する必要がありそう

参考
知見をまとめてくださっている先人がいらっしゃいました。まとめの3.で記載した部分は Lambda を使って解決されているようです。
https://fixel.co.jp/blog/amplify-appsync-auroraserverless/
今回調べて分かったことは以上です。それではまた!