作ったもの
DLsiteの新作音声作品をクローリング -> 好みかどうか推論 -> 好みならSlack通知をするシステムを完全サーバーレス(AWS SAM)で構築しました。さらなる精度向上のため、Slackメッセージのボタンをもとに教師データを蓄積する処理も作りました。
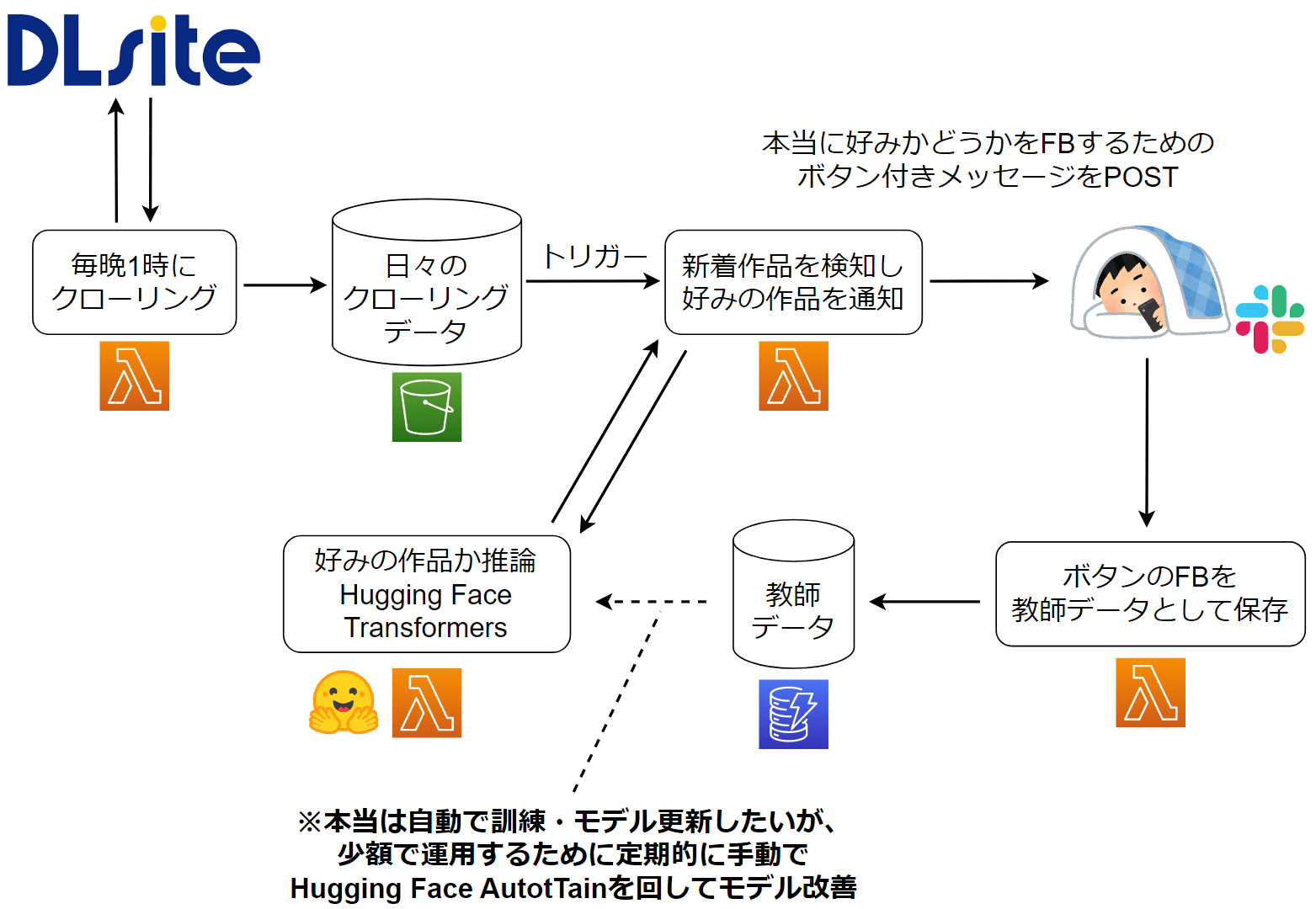
デモ(ぼかしMAX)
とてもわかりにくいですが、好みであろう作品がPOSTされているSlackの画面です。各メッセージについている「興味あり!」「別に…」ボタンを押すとLambdaが起動し、DynamoDBに新たな教師データとして保存されます。
なぜ作ったのか
- DLsiteが好き、以上。
・・・
- もう少し真面目に書くと、
- 会社でテキストデータに触れることが多いので、うまく扱えるようになりたい
- 音声作品はシチュエーションや台詞の一部が説明文に書かれていることが多く、自然言語処理との相性が良さそう
- AWSや機械学習の勉強はしてるけど、Hello Worldやタイタニックではなくダイレクトに自分の生活に役立つものを作りたい(そのほうが身につくものも多そう)
という背景です。
ちなみに、とある作品(全年齢対象)の説明文には下のようなテキストが書かれています。個人的には主にこういう情報をもとに買うかどうかを判断しているので、今回のモデルの教師データにはこのあたりのテキストを使いました。

やったこと
- DLsiteの音声作品のうち、比較的新しい約1600作品に対して、自分の好み or NOTをアノテーションした
- それをHugging Face AutoTrainで学習させ、Accuracy: 0.90, F-score: 0.82の精度で好みの作品を当ててくれる機械学習モデルを作った
- 数日運用してみた感想:「ふーん、お前わかってんじゃん」という作品を出してくることが多くて優秀
- 4つのLambda関数を実装し、新作をクローリング -> 推論 -> 好みの作品をSlack通知 -> 新たな教師データ蓄積をするシステムを完全サーバーレスで構築した
- ほぼAWS無料枠の範囲内なので、コストは約50円/月(Lambdaコンテナ用のイメージを保存するECRのストレージ代+ほんの少しだけS3)
それぞれ順に書いていきます。
アノテーション、教師データ作成
アノテーション
好みの要素がまったくない作品が大量に含まれるのは訓練データとして良くない気がしたので、特定のキーワードで検索して出てきた作品+過去に自分が買ったor閲覧した作品を対象にしました。
また効率的にアノテーションするために、Seleniumとinput()を使って、ある作品をアノテーションしたら自動的に次の作品ページに遷移するようなスクリプトを書きました。
実際にアノテーションしてる様子がこちらで、ターミナルに0(好みじゃない) or 1(好み)を入力すると自動的に次のページにいくようになっています。
およそ1週間アノテーションした結果、約1600作品(うち約25%が好み)のデータが集まりました。
教師データ作成
Dlsiteの音声作品には、説明文だけでなく作品タイトルや声優など、様々なテキスト項目があります。そのうち今回は、以下の項目を単純に結合したものを入力テキストとしました。
- タイトル
- サークル名(販売している団体名)
- シリーズ名
- 声優
- 作者
- シナリオライター
- イラストレーター
- ジャンル
- 説明文(の一部)
- HTML上ではいくつかの
div要素に分かれているが、そのうち特定のキーワード群(いろんなえっちワード)が最も多く含まれている要素だけを抽出して教師データに入れた - 全文を入れたときと比べて、Accuracyがざっくり0.8 -> 0.9に上がった
- HTML上ではいくつかの
この入力テキストに対して、好みかどうかの0 or 1を付けたものを教師データとしました。
Hugging Face AutoTrainで学習
これに関してはGUIにデータをドラッグ&ドロップするだけなのと、別で記事を書いているので省略します。
もともとの想定では、AutoTrainでベースラインモデルを作ったうえで、それを超えるように自分でもモデルを組むつもりでしたが、ベースラインの時点でAccuracy: 0.90, F-score: 0.82と想像以上の精度が出たので、ありがたくAutoTrainでできたモデルを使うことにしました。
現状だと訓練はWEBの画面からしかできないので、「自動で新しいデータを食わせてモデルを更新する」のようなことはできないのですが、もしAPIが提供されたら簡易的なMLOpsが組めそうです。
Lambdaの実装
4つの処理を実装したので、順に説明します。一部は別で記事を書いてるので、興味があれば読んでみてください。
- 定期的にDLsiteをクローリングする
- 作品情報を入力すると、機械学習モデルをもとに好みかどうかを返す
- 新着作品を検知し、好みと推論された作品をSlackに通知する
- Slackメッセージ上のボタンをもとに教師データをDBに保存する
クローリング
これはこちらに書きました。
今回は「音声作品を発売日順に100作品クローリングする」という処理にしていて、十分なアクセス間隔を空けても5分くらいで処理が終わります。
処理が終わってクローリングデータがS3にアップされると、それをトリガーとして2つ先の「新着作品を検知し、好みの作品をSlack通知する」Lambdaが動きます。
推論
これもこちらに書いています。
20行くらいの推論処理を書いて、sam init && sam build && sam deployするだけで推論APIができてしまうのは、本当にHuggingFaceとAWS様々だなと思いました。
新着作品を検知し、好みの作品をSlack通知
ここは単純に、下のように実装しました。
- S3から当日と前日のクローリングデータ(json)を取得
- 前日になくて当日にある作品を抽出
- それらすべて(多くても30作品くらい?)を推論Lambdaに投げ、
好みとみなされた作品はSlackに通知する- その際、本当に好みかどうかをフィードバックするためのボタンを付ける(やり方は次の記事を参照)
一番苦戦したのはFB用のボタンを付けるところで、詳しくは下の記事に書きました。
ボタンのFBをもとに教師データをDBに保存
Slackの実装部分はこちらに書きました。
DynamoDBに保存する部分は、簡単ですがこのように書いています。
from datetime import datetime
from zoneinfo import ZoneInfo
import boto3
JST = ZoneInfo("Asia/Tokyo")
ddb = boto3.resource("dynamodb")
table = ddb.Table("テーブル名")
table.put_item(
Item={
"item_id": item_id,
"created_at": f"{datetime.now(JST):%Y-%m-%d %H:%M:%S}",
"is_interested": is_interested, # 好みかどうかの0 or 1
}
)
なお細かい部分だと、間違えて違うボタンを押してしまったときのために、再びボタンを押すとその作品の教師データが上書きされるようにしました(パーティションキーをitem_id(作品ID)にしているので、何もしなくても同じキーに対するput_item()は上書きされますが)。
以上の4つを組み合わせると、毎日自動で作品がおすすめされる世界になります。
まとめ
AWSとHugging Faceはすごい!
1ヶ月くらい前にパッと思いついたものを、モチベーションを失わずそのままの勢いで作ることができました。数年前だったらこんなに速く・低コストで作れるものではなかったと思うので、AWSとHugging Face(とPytorch)のエコシステムに感謝です。
前にこういうものも作ったんですが、それと根っこの思想は変わらず、技術的には順当に進歩したものが作れた気がするので個人的にはとても満足しています。