自然言語処理とニューラルネット
ここ数年で、自然言語処理の分野でもニューラルネットが非常に頻繁に使われるようになってきました。
自然言語処理で主に解析対象となるのは単語の配列や構文木などで、これらの内包する情報を表現するためにrecurrent neural network1やrecursive neural network1などに基づくモデルが頻繁に使われます。これらの最大の特徴はニューラルネットがある種のデータ構造を持っているという点で、1レイヤあたりのノードはそれほど多くない代わりにネットワークの接続が複雑で、しかも入力されるデータごとにネットワークそのものの形状が変化するという特徴があります。このため、伝統的なfeedforward neural networkを前提としたツールキットでは構築が難しいという問題がありました。
Chainerは、そのような問題を概ね解決してしまう強力なニューラルネットのフレームワークです。Pythonの文法とほんの少しだけNumPyを知っていれば使えるのと、ソースコード上の計算式がそのままニューラルネットの接続情報として自動的に記憶されるので、入力データをパースすれば自動的にニューラルネットで解析できてしまうというチートのような特徴があります。
最近書き溜めていたChainerサンプル集でも言語モデルや単語分割器、翻訳モデルなどを実装していますが、いずれも基本的な部分(コード中のforward関数)は半日、短いものだと1時間くらいあれば実装できてしまいます。サンプルを見てもらえば分かりますが、むしろデータを整理する周辺コードに労力の大半を割いているような状況です。
本稿では主にrecurrent neural networkについて、そのChainerでの実装方法と、自然言語処理での一応用であるencoder-decoder翻訳モデルの解説を行います。
記事の内容はChainer1.4以前を前提としています。1.5系には様子を見て対応します。
Recurrent Neural Network
最も基本的なrecurrent neural network(以降RNN)は、次の図のような、オーソドックスな3層ニューラルネットに隠れ層のフィードバックが追加されたものです。
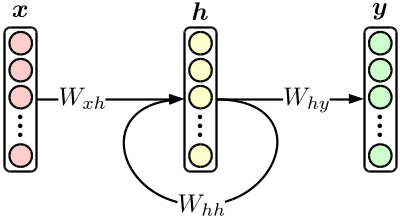
簡単なモデルですが、後で紹介する翻訳モデルはRNNを組み合わせて作られています。またRNN単体でも、言語モデルに使用すると従来のN-gramモデルを簡単に凌駕する精度を叩き出してくれる優れ物です。2
上図を式に書き下すと、
\begin{align}
{\bf h}_n & = \tanh \bigl( W_{xh} \cdot {\bf x}_n + W_{hh} \cdot {\bf h}_{n-1} \bigr), \\
{\bf y}_n & = {\rm softmax} \bigl( W_{hy} \cdot {\bf h}_n \bigr)
\end{align}
となり、これをそのままChainer上の計算式として使います。
とりあえずここでは「単語IDを入力して、次の単語IDを予測する」RNN言語モデルを考えましょう。3
まずモデルを定義します。モデルとは学習可能なパラメータの集合のことで、上図の$W_{**}$がこれに相当します。この場合$W_{**}$は全て線形作用素(行列)なので、chainer.functions内のLinearかEmbedIDを使用します。EmbedIDは入力側がone-hotベクトルの場合のLinearで、ベクトルの代わりに発火している要素のIDを渡すことができます。
from chainer import FunctionSet
from chainer.functions import *
model = FunctionSet(
w_xh = EmbedID(VOCAB_SIZE, HIDDEN_SIZE), # 入力層(one-hot) -> 隠れ層
w_hh = Linear(HIDDEN_SIZE, HIDDEN_SIZE), # 隠れ層 -> 隠れ層
w_hy = Linear(HIDDEN_SIZE, VOCAB_SIZE), # 隠れ層 -> 出力層
)
VOCAB_SIZEは単語の種類数、HIDDEN_SIZEは隠れ層の次元を表します。
次に実際の解析を行うforward関数を定義します。ここでは基本的にはモデルの定義と実際の入力データに従って上図のネットワーク構造を再現し、最終的に求めたい値を計算することになります。言語モデルの場合は次の式に表す文の結合確率を求めることになります。
\begin{align}
\log {\rm Pr} \bigl( {\bf w} \bigr) & = \sum_{n=1}^{|{\bf w}|} \log {\rm Pr} \bigl( w_n \ \big| \ w_1, w_2, \cdots, w_{n-1} \bigr) \\
& = \sum_{n=1}^{|{\bf w}|} \log {\bf y}_n\big[ {\rm index} \bigl( w_n \bigr) \big]
\end{align}
以下がコード例ですが、Chainerはミニバッチ処理が前提になっているので、データの次元がひとつ多くなっています(コード中でバッチ処理は行っていません)。
import math
import numpy as np
from chainer import Variable
from chainer.functions import *
def forward(sentence, model): # sentenceはstrの配列。MeCabなどの出力を想定。
sentence = [convert_to_your_word_id(word) for word in sentence] # 単語をIDに変換。自分で適当に実装する。
h = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32)) # 隠れ層の初期値
log_joint_prob = float(0) # 文の結合確率
for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) # 次回の入力層
y = softmax(model.w_hy(h)) # 次の単語の確率分布
log_joint_prob += math.log(y.data[0][word]) # 結合確率の更新
h = tanh(model.w_xh(x) + model.w_hh(h)) # 隠れ層の更新
return log_joint_prob # 結合確率の計算結果を返す
これで文の確率を求めることができるようになりました。が、上記にはモデルを学習するための損失関数の計算が含まれていません。今回はsoftmax関数を最終段に使用しているので、chainer.functions.softmax_cross_entropyで正解とのクロスエントロピーを求めて損失関数とします。
def forward(sentence, model):
...
accum_loss = Variable(np.zeros((), dtype=np.float32)) # 累積損失の初期値
...
for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) # 次回の入力層 (=今回の正解)
u = model.w_hy(h)
accum_loss += softmax_cross_entropy(u, x) # 損失の蓄積
y = softmax(u)
...
return log_joint_prob, accum_loss # 累積損失も一緒に返す
これで学習ができるようになりました。
from chainer.optimizers import *
...
def train(sentence_set, model):
opt = SGD() # 確率的勾配法を使用
opt.setup(model) # 学習器の初期化
for sentence in sentence_set:
opt.zero_grad(); # 勾配の初期化
log_joint_prob, accum_loss = forward(sentence, model) # 損失の計算
accum_loss.backward() # 誤差逆伝播
opt.clip_grads(10) # 大きすぎる勾配を抑制
opt.update() # パラメータの更新
基本的にChainerの処理はこれだけです。従来はこのようなニューラルネットのためにウンザリするような行数のプログラムを記述していたわけですが、Chainerは面倒な計算がほぼ全てPythonの構文に隠蔽されているので、このように短い記述が可能となります。Chainerの使い方さえ覚えていれば、最近提案されたモデルや今思いついた独自モデルをサッと書いて試す、というような実験も可能となるわけです。4
Encoder-decoder翻訳モデル
RNNを応用した少し複雑な例として、ニューラルネットを使った機械翻訳の手法であるencoder-decoder翻訳モデルを実装してみます。
これは入力から出力までの全ての過程がニューラルネットで記述された翻訳モデルであり、そのシンプルさに反して従来の翻訳モデルに匹敵する精度を実現するため、発表時には研究者に驚きを以って迎えられました。
Encoder-decoder翻訳モデルには色々な亜種がありますが、ここでは私のサンプル集でも実装している下図のモデルを書いてみます。
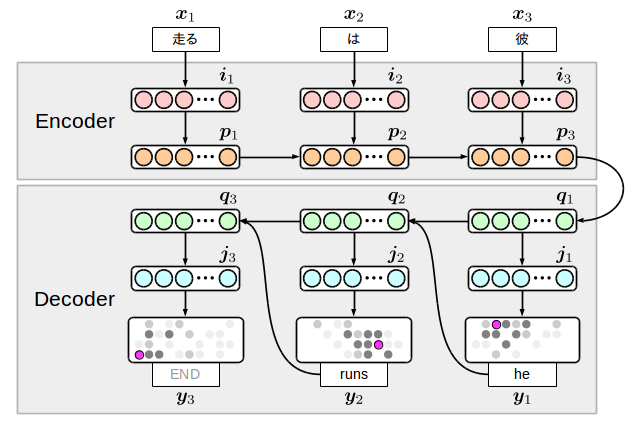
考え方としては簡単で、入力言語側(encoder)と出力言語側(decoder)の2個のRNNを用意して、それを中間ノードで繋ぎ合わせたものです。このモデルの面白い点は、出力側で単語と一緒に終端記号を生成するため、翻訳の終了をモデル自身が決めているという点です。しかし逆に言うと、この終端記号の学習に失敗していると無限に単語を生成するようになってしまうため、実際には適当な単語数を生成しても終わらない場合は処理を打ち切る必要があります。
${\bf i}$と${\bf j}$は埋め込み(embedding)層と呼ばれるもので、次元の圧縮された単語情報を表します。また入力の単語列が反転していますが、このようにすると実験的に良い翻訳結果が出ることが分かっています。なぜなのかはあまりはっきりと分かっていませんが、encoderとdecoderが変換・逆変換の関係にあるから、という風に解釈されていたりします。
早速コードを書き進めて行きますが、まずは計算式に落とし込みましょう。これは次のようになります。
\begin{align}
{\bf i}_n & = \tanh \bigl( W_{xi} \cdot {\bf x}_n \bigr), \\
{\bf p}_n & = {\rm LSTM} \bigl( W_{ip} \cdot {\bf i}_n + W_{pp} \cdot {\bf p}_{n-1} \bigr), \\
{\bf q}_1 & = {\rm LSTM} \bigl( W_{pq} \cdot {\bf p}_{|{\bf w}|} \bigr), \\
{\bf q}_m & = {\rm LSTM} \bigl( W_{yq} \cdot {\bf y}_{m-1} + W_{qq} \cdot {\bf q}_{m-1} \bigr), \\
{\bf j}_m & = \tanh \bigl( W_{qj} \cdot {\bf q}_m \bigr), \\
{\bf y}_m & = {\rm softmax} \bigl( W_{jy} \cdot {\bf j}_m \bigr).
\end{align}
ここで隠れ層${\bf p}$と${\bf q}$の遷移にちゃっかりLSTMを使っています。5というのも図を見て貰えば分かるのですが、encoder側は実際に損失が計算される位置${\bf y}$からかなり遠い場所にあるので、普通の活性化関数ではうまく学習できないという問題があるためです。このようなモデルでは重みの事前学習か、LSTMのような長距離の依存関係を記憶できる素子が必要となります。
さて、上図や式を見てみると、遷移$W_{**}$が8種類あることが分かります。これらが今回学習するパラメータで、モデルの定義にはこれを列挙します。
model = FunctionSet(
w_xi = EmbedID(SRC_VOCAB_SIZE, SRC_EMBED_SIZE), # 入力層(one-hot) -> 入力埋め込み層
w_ip = Linear(SRC_EMBED_SIZE, 4 * HIDDEN_SIZE), # 入力埋め込み層 -> 入力隠れ層
w_pp = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), # 入力隠れ層 -> 入力隠れ層
w_pq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), # 入力隠れ層 -> 出力隠れ層
w_yq = EmbedID(TRG_VOCAB_SIZE, 4 * HIDDEN_SIZE), # 出力層(one-hot) -> 出力隠れ層
w_qq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), # 出力隠れ層 -> 出力隠れ層
w_qj = Linear(HIDDEN_SIZE, TRG_EMBED_SIZE), # 出力隠れ層 -> 出力埋め込み層
w_jy = Linear(TRG_EMBED_SIZE, TRG_VOCAB_SIZE), # 出力隠れ層 -> 出力隠れ層
)
注意する必要があるのはLSTMの入力になる$W_{ip}, W_{pp}, W_{pq}, W_{yq}, W_{qq}$の各パラメータで、LSTMに入力される側の次元を4倍に増やす必要があります。Chainerの実装しているLSTMは通常の入力の他にinput gate, output gate, forget gateの3種類の入力があり、これを1個のベクトルとしてまとめているためにこのような実装が必要となっています。6
次にforward関数を書きます。LSTMは内部状態を持っているので、${\bf p}$と${\bf q}$の計算時にもう一つVariableが必要となることに注意します。
# src_sentence: 翻訳したい単語列 e.g. ['彼', 'は', '走る']
# trg_sentence: 正解の翻訳を表す単語列 e.g. ['he', 'runs']
# training: 学習か予測か。デコーダの挙動に影響する。
def forward(src_sentence, trg_sentence, model, training):
# 単語IDへの変換(自分で適当に実装する)
# 正解の翻訳には終端記号を追加しておく。
src_sentence = [convert_to_your_src_id(word) for word in src_sentence]
trg_sentence = [convert_to_your_trg_id(word) for wprd in trg_sentence] + [END_OF_SENTENCE]
# LSTM内部状態の初期値
c = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32))
# エンコーダ
for word in reversed(src_sentence):
x = Variable(np.array([[word]], dtype=np.int32))
i = tanh(model.w_xi(x))
c, p = lstm(c, model.w_ip(i) + model.w_pp(p))
# エンコーダ -> デコーダ
c, q = lstm(c, model.w_pq(p))
# デコーダ
if training:
# 学習時はyとして正解の翻訳を使い、forwardの結果として累積損失を返す。
accum_loss = np.zeros((), dtype=np.float32)
for word in trg_sentence:
j = tanh(model.w_qj(q))
y = model.w_jy(j)
t = Variable(np.array([[word]], dtype=np.int32))
accum_loss += softmax_cross_entropy(y, t)
c, q = lstm(c, model.w_yq(t), model.w_qq(q))
return accum_loss
else:
# 予測時には翻訳器が生成したyを次回の入力に使い、forwardの結果として生成された単語列を返す。
# yの中で最大の確率を持つ単語を選択していくが、softmaxを取る必要はない。
hyp_sentence = []
while len(hyp_sentence) < 100: # 100単語以上は生成しないようにする
j = tanh(model.w_qj(q))
y = model.w_jy(j)
word = y.data.argmax(1)[0]
if word == END_OF_SENTENCE:
break # 終端記号が生成されたので終了
hyp_sentence.append(convert_to_your_trg_str(word))
c, q = lstm(c, model.w_yq(y), model.w_qq(q))
return hyp_sentence
少々長いですが、注意深く読むと上図の矢印とコードの各部分が対応していることが分かると思います。
あとはこのコードの外側にRNNと同じような学習器を追加すれば、晴れて自前の翻訳データを学習できるようになるわけです。
さて、果たしてこのモデルがどのように学習するかですが、ここに置いている日英翻訳のサンプルデータを用いて学習してみます。語彙数2000、埋め込み層100、隠れ層100として1万文程度を学習すると、概ね世代ごとに次のような翻訳結果が得られます(学習にはサンプル集の方のプログラムを使いました)。
2017/7/21: サンプルデータのリンクを張り直しました。
入力: 休暇 は いかが で し た か 。
出力:
1: the is is a of of <unk> .
2: the 't is a <unk> of <unk> .
3: it is a good of the <unk> .
4: how is the <unk> to be ?
5: how do you have a <unk> ?
6: how do you have a <unk> ?
7: how did you like the <unk> ?
8: how did you like the weather ?
9: how did you like the weather ?
10: how did you like your work ?
11: how did you like your vacation ?
12: how did you like your vacation ?
13: how did you the weather to drink ?
14: how did you like your vacation ?
15: how did you like your vacation ?
16: how did you like your vacation ?
17: how did you like your vacation ?
18: how did you like your vacation ?
19: how did you enjoy your vacation ?
20: how did you enjoy your vacation now ?
21: how did you enjoy your vacation for you ?
22: how did you enjoy your vacation ?
入力: 彼女 は 幸福 そう に 見え る 。
出力:
1: she is a of of of .
2: she is a good of of .
3: she is a good of <unk> .
4: she is a good of <unk> .
5: she is a good of <unk> .
6: she is a good of his morning .
7: she is a good of his morning .
8: she is a good of his morning .
9: she is a good of his morning .
11: she is a good of his morning .
12: she is a good of his morning .
13: she is a good of his morning .
14: she is a good of his morning .
15: she is a good at tennis .
16: she is a good at tennis .
17: she is a good at tennis .
18: she is a good of the time .
19: she seems to be very very happy .
20: she is going to be a student .
21: she seems to be very very happy .
22: she seems to be very very happy .
23: she seems to be very happy .
入力: 今朝 は 寒 く 感じ る 。
出力:
1: i 'm a of of of .
2: i 'm a <unk> of the <unk> .
3: it is a good of <unk> .
4: it is a good of <unk> .
5: it is a good of <unk> .
6: it is a good of the day .
7: it 's a good of <unk> .
8: it 's a good of <unk> .
9: it 's a good of <unk> .
10: it 's a good of <unk> today .
11: i 'm a good <unk> of time .
12: i 'm a good <unk> of time .
13: i 'm a good <unk> of time .
14: i 'm very busy this <unk> today .
15: i 'm very busy this morning time .
16: i 'm very busy this morning time .
17: i 'm very busy this time .
18: i 'm very busy this time .
19: i have a lot of cold here .
20: i have a lot of <unk> here .
21: i have a lot of <unk> time .
22: i 'm very busy this morning time .
23: i have a lot of cold here .
24: i have a lot of cold here .
25: i have a lot of that morning .
26: i have a lot of cold here .
27: i have a lot of cold here .
28: i have a cold , will do .
29: i feel cold this morning this morning .
結果を見て分かるのは、まず大まかな文法や意味の広い単語を生成するよう学習し、次第に具体的な単語を当てに行くよう調整されてゆく点です。これは、ニューラルネットの収束が進むにつれて単語同士の意味の違いをはっきりと捉えることができるようになってゆくためである、と考えることもできます。最後の例などは面白くて、「今朝は寒い(feel cold this morning)」と「風邪を引いた(have a cold)」を学習の最後まで間違えていたようです。このような意味的な間違いはニューラルネットに独特の現象で、従来の機械翻訳の手法ではまず起こることがありません。このような異なる特徴を持つ点も、ニューラルネットが自然言語処理で注目されている理由の一つと考えられます。
-
両方ともRNNと略されるので紛らわしい。紛らわしさを逆手に取ったのかR2NN (recursive recurrent neural network)などというモデルもあったりする。 ↩ ↩2
-
ただし、N-gramモデルのように文の一部だけを取り出してスコアを求めたりすることはできないので、少しずつスコアを求めながら解析を進める機械翻訳のような分野では使い方が限られるという問題もある。 ↩
-
単語を単語IDに変換する方法は色々あり、採用する方法によってモデルの精度に直接影響が出る。ここまで説明すると記事の趣旨から逸脱するので、ここでは解説しない。 ↩
-
学習時間がボトルネックとして効いてくるので、本当にtry-and-error的な開発がしたい場合はGPUを1枚持っていた方が良い。 ↩
-
簡単のため、式上ではLSTMの内部状態を無視している。 ↩
-
最近の実装である
chainer.linksにはこの辺りの実装を隠蔽したバージョンのLSTMが実装されている。 ↩