はじめに
MENSA (https://mensa.jp/)は、人工上位2%の知能指数(IQ)を有する者の交流を主たる目的とした非営利団体である。高IQ団体としては、最も長い歴史を持つ。会員数は全世界で約12万人。支部は世界40か国。イギリス・リンカンシャーにあるケイソープ(英語版)に、本部(メンサ・インターナショナル)を持つ。
Wikipediaより抜粋
テレビのクイズ番組などでもたまーに目にするこのMENSA、独自のテストを通過すると入会資格が得られ、入会するとMENSA会員のみの交流会などに参加できるそうです。
ネットのIQテストや海外のMENSA支部が提供している模擬テスト(?)を解いてみるとギリギリ入会できそうだったのでテストを受けてみることにしました。
最大の障壁
入会テスト受験を決意してから現在まで半年以上経過しました。何故かというと・・・

ご覧のように満席満席満席・・・
定期的にテストは開催されるのですが、どうも一回あたりの定員が多くないらしく、募集が開始されるとすぐに枠が埋まってしまいテストが受けられませんでした。
このままでは埒が明かないのでPython3とAWSのCloud9でこの入会テスト情報のページを一定間隔でスクレイピングし、任意の箇所が更新されたらLineに通知がいくようにしてみました。ターゲットは7/5受付開始予定のテスト!ただし受付開始時間は不明です
自動でスクレイピングを行うために
いつページの更新が行われても対応できるように24時間コードが動いている状態を維持しなければなりません。
ですので今回はAWSのCloud9という総合開発環境(IDE)使用しました。この開発環境にEC2インスタンス(仮想サーバー)を用いることで、自分が使っているPCが起動していない時にも健気に稼働し続けてくれます。
AWSは登録すると1年間の無料体験枠が付いてきます。1つのEC2インスタンスだけであれば、24時間稼働させても無料範囲内で収まるので安心です。
それでは始めてみましょう。
AWSの登録~Cloud9で開発環境の構築
AWS アカウント作成の流れ(公式)を参照して登録を行ってください。登録が終わりましたら
AWSアカウントを取得したら速攻でやっておくべき初期設定まとめ を一通り済ませてください。セキュリティの観点からIAMユーザーの作成は必須と言ってもいいと思います。
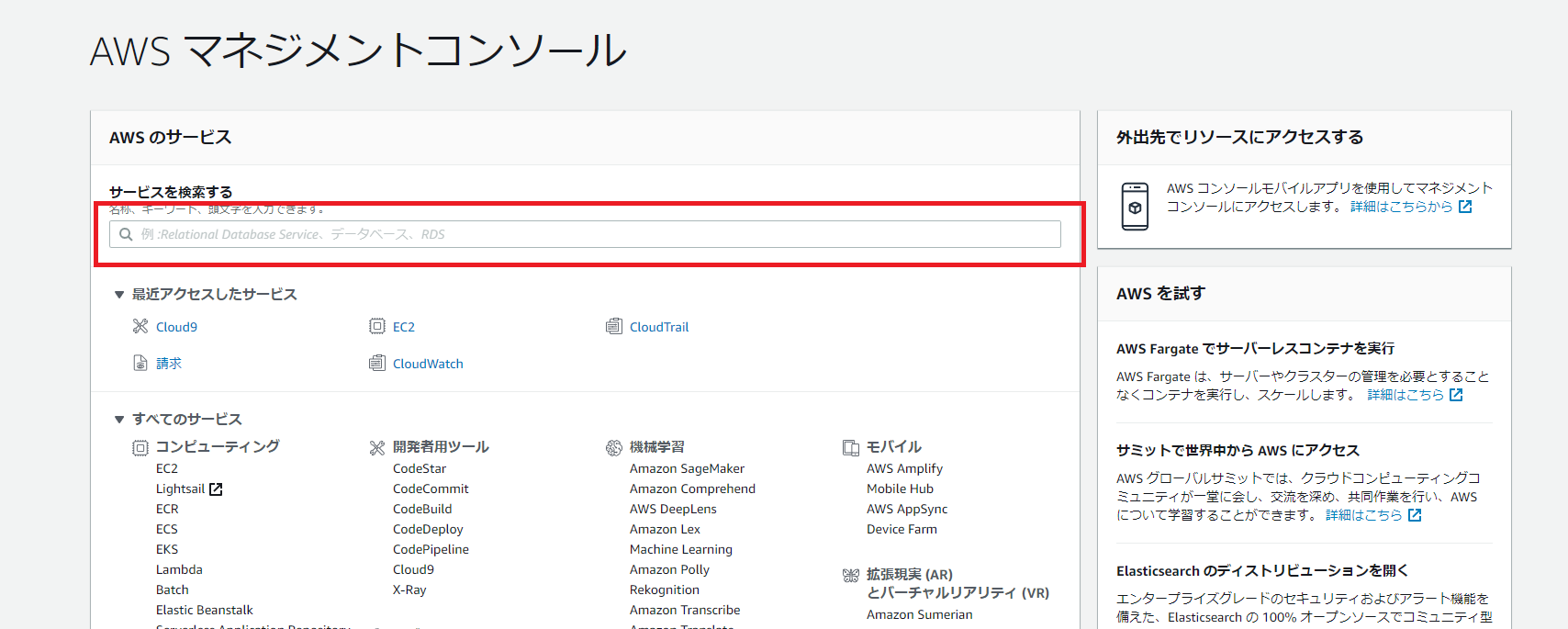
一通りの作業が済みましたら、AWSマネジメントコンソールの検索欄(画像赤枠内)にCloud9と入力し、表示されるCloud9をクリックして移動してください。
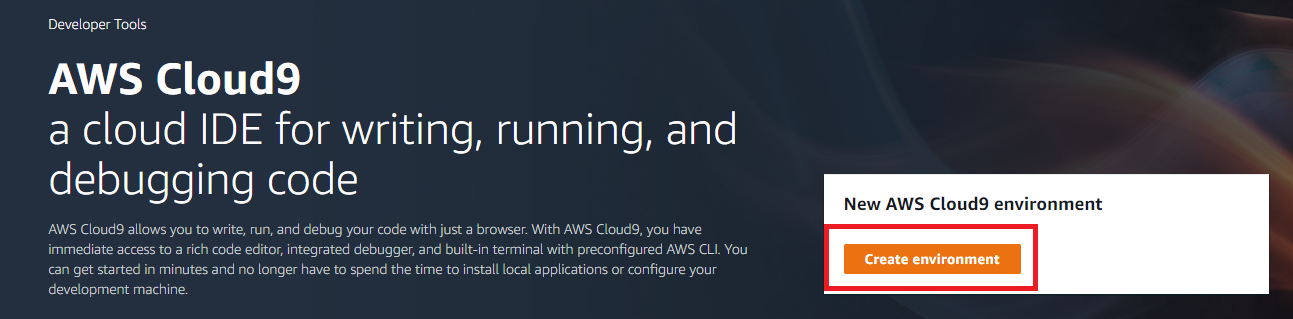
Cloud9のページに移動したらCreate environmentをクリックしてください。
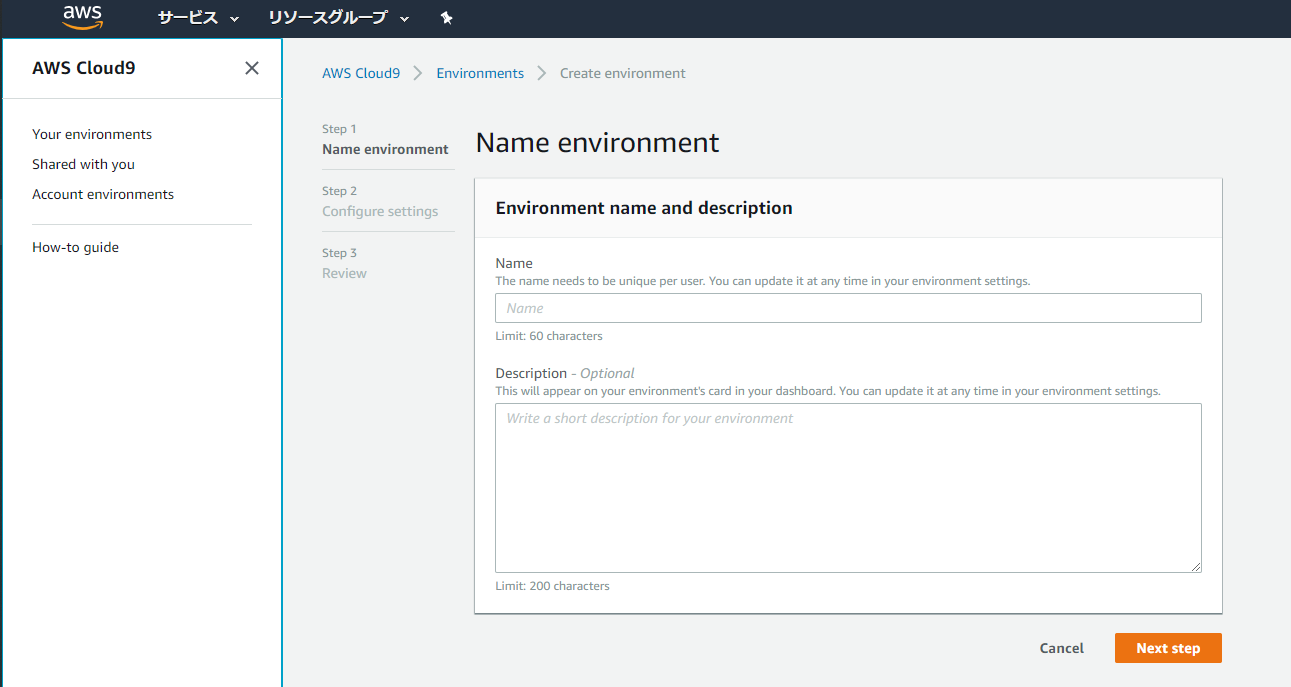
ここでは開発環境の名前と説明を入力します。Name欄に適当な名前を入力してください。説明を入力するDescription欄は必須ではないので入力しなくてもOKです。入力が完了したらNext stepをクリックして次に進みます。
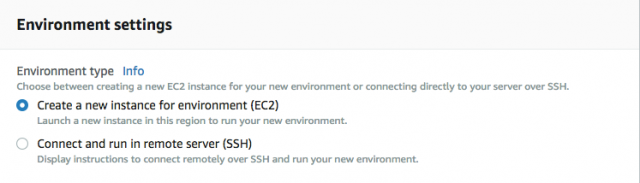
次に環境の設定を行います。
まずは開発環境をどこに置くかを設定します。上の Create a new instance for environment(EC2)を選択しましょう。自前のサーバーを持っている人は下を選択しても良いですがここでは割愛します。
次にインスタンスの性能を選択します。ただ選択肢はなく、一番上以外は無料範囲外なので一番上のt2macro(i GiB RAM + 1vCPU)を選択しましょう。今回行う内容ではこれで十分です。
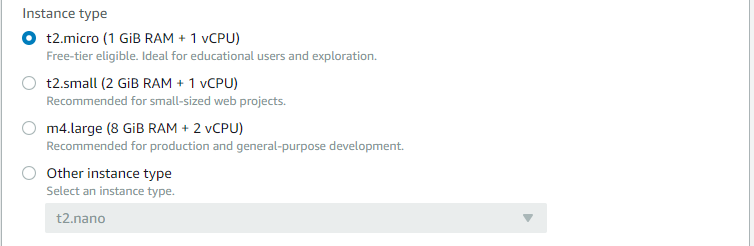
インスタンスのOSを選択します。ここではAmazon Linuxを選択します。

次にインスタンスの自動停止に関する設定(Cost-saving setting)です。これはブラウザを閉じてからどれぐらいの時間でインスタンスを自動停止するかを設定します。上から30分、1時間、4時間、1日、1週間、最後は停止しない です。後から設定する事も可能ですがここで選択してしましましょう。今回は一番下のNeverつまり自動停止を行わない設定にします。
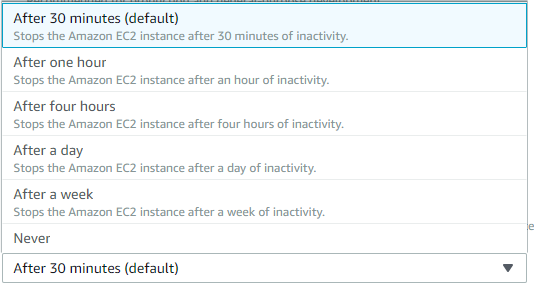
すべての項目が設定できましたらNext stepをクリックして確認画面に移ります。表示されている内容に問題がなければCreate environmentで環境構築を実行しましょう。構築には数分間掛かります。
この画面が表示されれば開発環境の構築が完了です。それでは早速コードを書いていきましょう。
今回は3つのモジュールを作成します。それぞれ
・line_notify.py (Lineに通知する)
・mensa_scrape.py (スクレイピングを実行する)
・main.py (上記2つを一定間隔で実行する)となります。
それでは画面左のディレクトリ欄を右クリックして New Fileをクリックして新規ファイルを作成してください。
Lineに通知する
Lineに通知を行うためにはアクセストークンの発行が必要です。
たったの2ステップでLINEにメッセージを通知する方法【python】
に記載されている手順に従ってアクセストークンを発行してください。トークン名は自由に設定してOKです(私は「Mensaアラート」にしました)
また、発行されたアクセストークンは必ずコピーしてください。これが無いと通知を送れません。
アクセストークンの発行が完了したらCloud9に戻ります。先程作成した新規ファイルを右クリックしRenameを選択してファイル名をline_notice.pyに変更しましょう。内容は以下のようになります
import requests
token = "発行したアクセストークン"
def line_notify(message):
line_notify_token = token
line_notify_api = 'https://notify-api.line.me/api/notify'
payload = {'message': message}
headers = {'Authorization': 'Bearer ' + line_notify_token}
requests.post(line_notify_api, data=payload, headers=headers)
def main():
# 上の通知を実行する関数を呼び出します。引数は通知の際に送られるメッセージです。
line_notify("TEST")
if __name__=="__main__":
main()
これに関しては殆ど定型文みたいなところがあるので説明は割愛します。def main()とif __name=="main__"はこのモジュール単体でのテストを行うために追加しているコードなので厳密には不要です。
それでは保存が完了したら画面上部にあるRunをクリックしてモジュールを実行してみてください。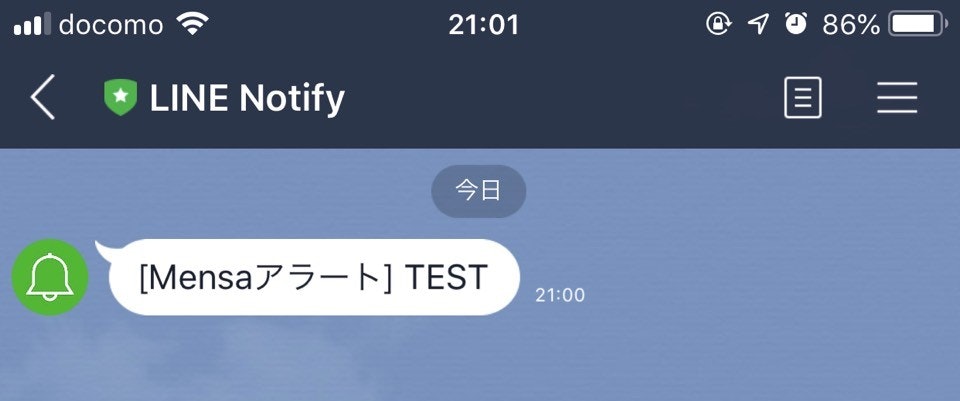
Line Notifyさんから[トークン名]+メッセージ で通知が送られていると思います。これでLineの通知モジュールの完成です。かなり簡単に出来たので私も最初驚きました。
スクレイピングを実行する
次にスクレイピングを実行するモジュールを作成します。先程と同じ手順で新規ファイルを作成し、名前をmensa_scrape.pyで保存してください。コード全文は以下になります。コメントを各所に入れているので参考にしてください
大まかな流れとしては
スクレイピングを実行してHTMLを取得
↓
取得したHTMLをcurrent.csvに保存
↓
前回取得したHTMLが保存されているprevious.csvと比較
↓
内容が同じ場合は特になし、内容が異なる(=更新された)場合はLineに通知する。その後今回取得したHTMLをprevious.csvに保存、次回取得時の比較対象にする。
です。
import requests
import csv
import os.path
import time
import line_notice as ln # 先程作成したモジュールをインポートします
import datetime as dt
def mensa_scrape():
# urlに、スクレイピングを行いたいwebページのURLを定義します。
url = "https://mensa.jp/exam/"
# 次にLineに通知を行う際に入れるメッセージをmessageに定義します。私は通知を受け取った際にすぐに移動できるように
# urlを追加しています。ここは個人の好みなので何でもいいです。
message = "Mensa 検知" + url
# request.get(url)で指定したURLのリクエストを取得します。
r = requests.get(url)
# この行でエンコードを指定します。この行がないと取得したが文字化けする可能性があります。
r.encoding = r.apparent_encoding
# 取得したリクエストのHTML部分を文字列型でhtml_textに格納します。
html_text = r.text
# 更新の判定を行う箇所を絞るために、HTMLの部分を切り出しています。私は関東在住なので関東地方の部分のみ抽出しています。
extract_st = html_text.find('<h3 class="area_title">関東地方</h3>')
extract_ed = html_text.find('<h3 class="area_title">中部地方</h3>')
extracted_text = html_text[extract_st:extract_ed]
# 今のままではテキスト内にスペースが大量に入っているので、スペースを削除してカンマ区切りに変えます
html_list = extracted_text.split()
# このif文はスクレイピングが成功した場合True、失敗した場合Falseです。
if str(r) == "<Response [200]>":
# current.csvに今回取得したHTMLを保存します(current.csvが存在しない場合は作成して保存します)
with open ("current.csv", mode="w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(html_list)
# previous.csvが存在する場合、current.csvとprevious.csvの内容をそれぞれ読み込みます
if os.path.exists("previous.csv"):
with open("previous.csv") as f:
previous_csv = f.read()
with open("current.csv") as g:
current_csv = g.read()
# current.csvとprevious.csvが同じ(更新がない)場合、Sameの文字と実行時の時間をコンソールに表示します
if current_csv == previous_csv:
print("Same: " + str(dt.datetime.now()))
# current.csvとprevious.csvが異なる(更新がある)場合、Lineに通知した後previous.csvに今回のHTMLを保存します
else:
ln.line_notify(message)
with open("previous.csv", mode="w") as f:
writer = csv.writer(f)
writer.writerow(html_list)
# previous.csvがない場合(=今回が1回目の実行の場合)今回の内容をprevious.csvに保存して終了します。
else:
with open("previous.csv", mode="w") as f:
writer = csv.writer(f)
writer.writerow(html_list)
if __name__=="__main__":
mensa_scrape()
抽出するHTMLの箇所は実際にスクレイピングを行いたいページに移動し、右クリック→ページのソースを表示(Chromeの場合)を行うことでHTMLを見ることが出来るので、そこからコピペで引っ張ってきましょう。
これで必要なモジュールは揃いました。あとこれらを実行するmainモジュールを作成します。
一定間隔でスクレイピングを実行する
これまでに作成したモジュールを一定間隔で実行させるmainモジ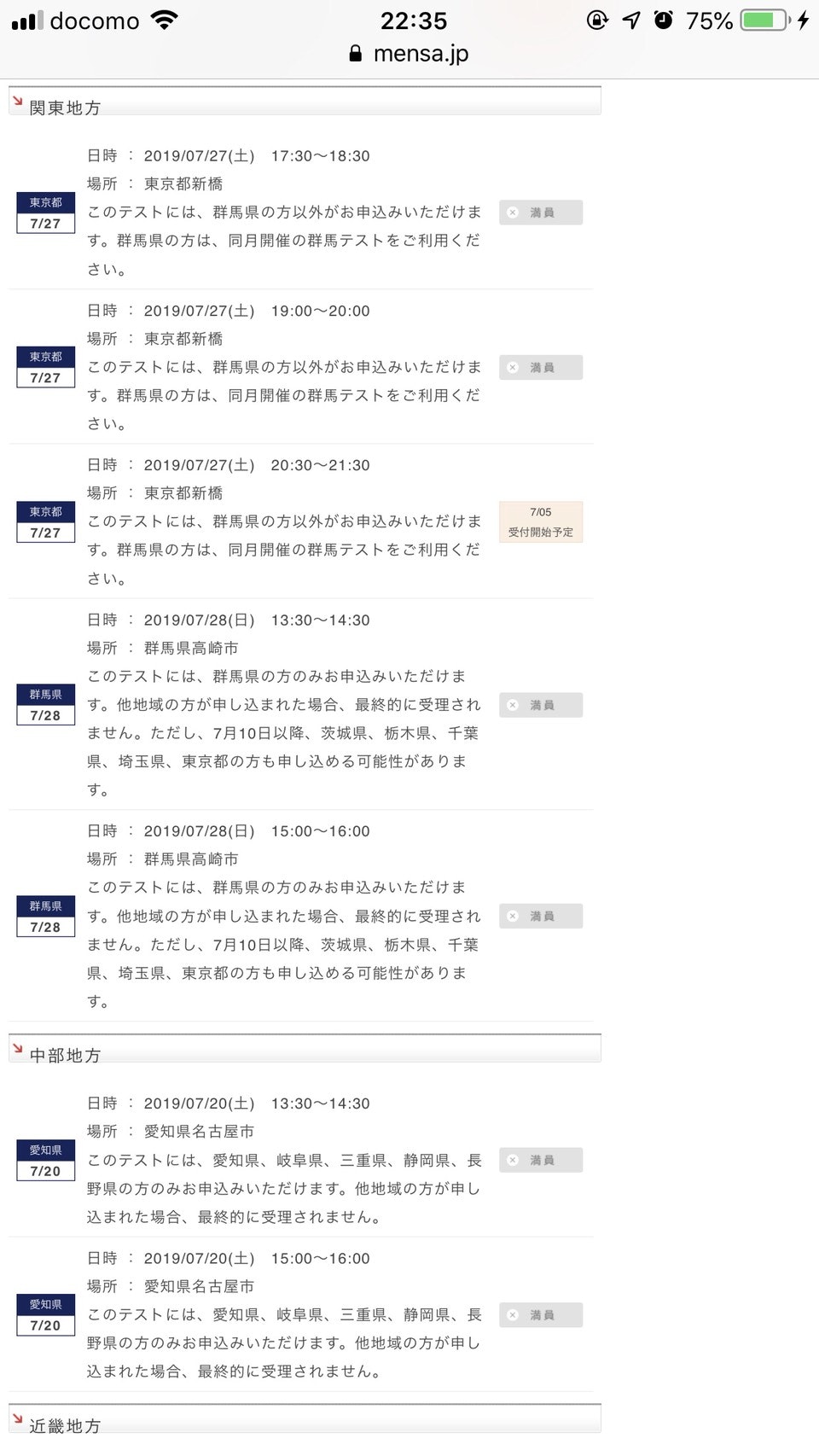
ュールを作成します。これまでと同じ手順でmain.pyを作成してください。
内容はかなりシンプルです。While Trueで無限ループを作り、その中に先程のスクレイピングのモジュールと、間隔を開けるためのtime.sleep(120)を入れるだけです。この状態だとスクレイピングが終了すると2分待機して再度スクレイピング~ をひたすら続ける内容となっています。
※間隔の調整は自由ですが、あまり間隔を短くしすぎるとアクセス先のサーバーに負担が掛かるためある程度は開けたほうがいいです。
import mensa_scrape as ms
import time
def main():
while True:
ms.mensa_scrape()
time.sleep(120)
if __name__=="__main__":
main()
これで自動スクレイピングのシステムが出来上がりました。main.pyを開いた状態でRunをクリックしましょう。初回のループではスクレイピングを実行してprevious.csvとcurrent.csvを作成するだけで終了すると思います。画面左側のディレクトリ欄に2つのCSVが生成されていれば成功です。
本当に更新を検知できているかどうかは、適当なニュースサイトなど更新頻度の高いサイトをスクレイピングしてみれば確認できるかと思います。
運命の日・・・
というわけで本番です。各種テストを済ませ、受付開始予定の7/5を迎えました。何時に開始されるか分からないため、普段は切っている通知音も最大に設定し準備は万全です。
そしてそのときは唐突に訪れました。
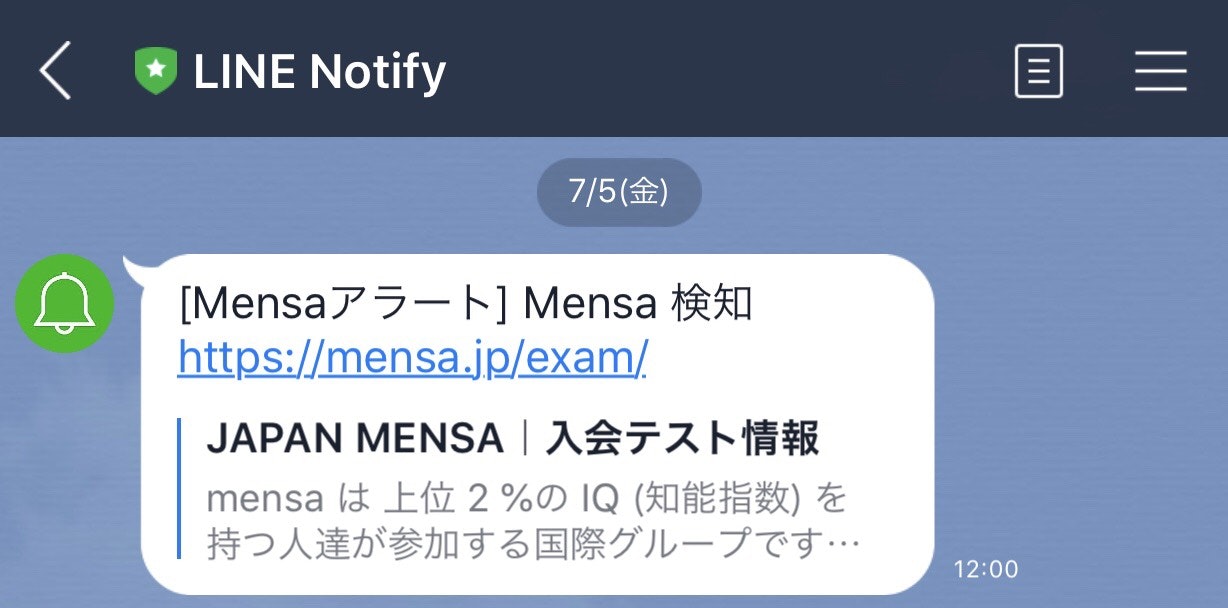
来た!!!!
メッセージに添えられているURLからアクセスしてみると・・・
ありました!!
すかさず入って各種情報を入力し・・・
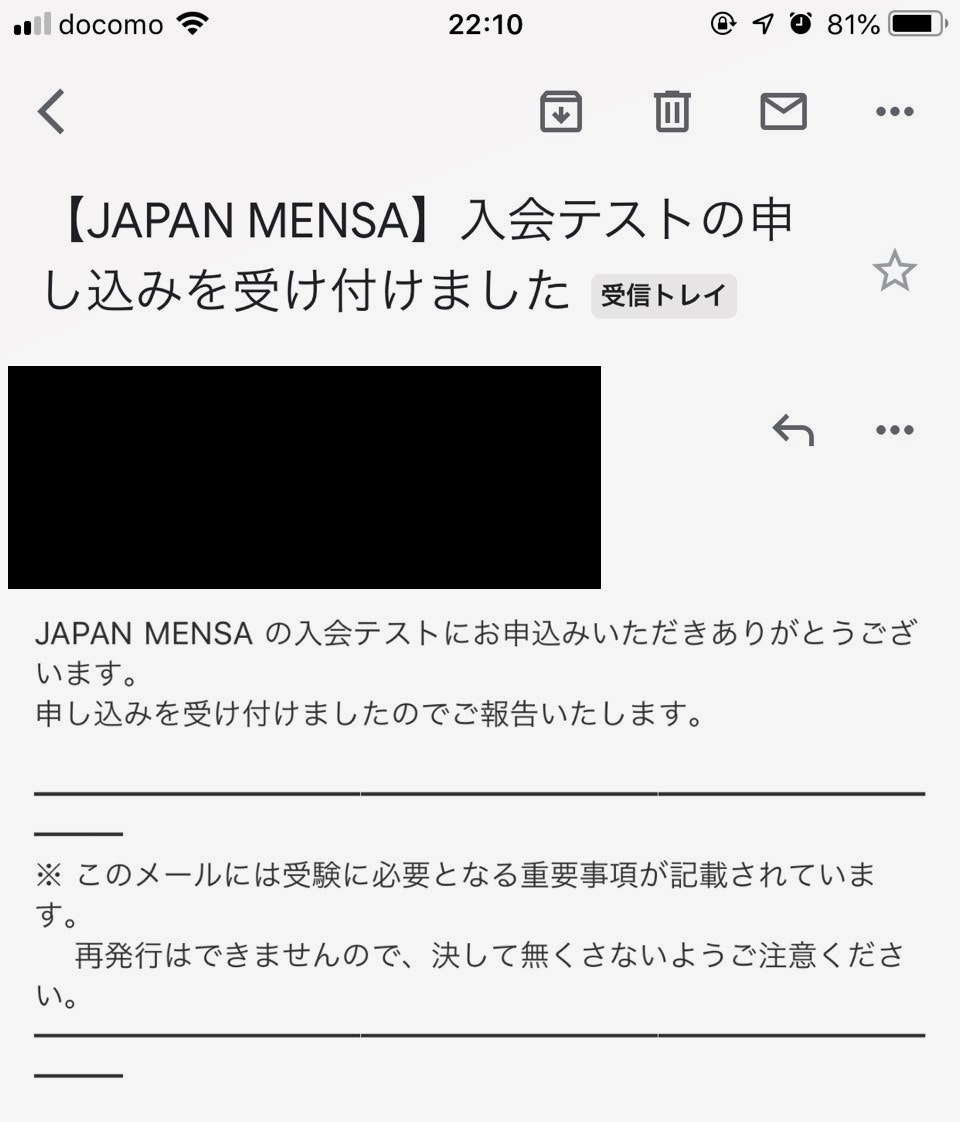
成功です。ありがとうございました
おわりに
投稿時点で既にテストは終了していますが、結果は当分先にならないと分からないみたいです。
合格したときにはもしかしたらここで報告するかもしれません。
以上です。最後までお付き合いいただきありがとうございました。
追加(9/20)
報告が遅れましたが無事に入会テストに合格しました。よかったです