こんにちは。普段は産婦人科医をしつつAIの医学応用に関する研究をしています。
以前ED法がにわかに話題になった時、以下のような記事をQiitaで書かせていただきました。
その際に、大脳の機能局在についても言及しました。
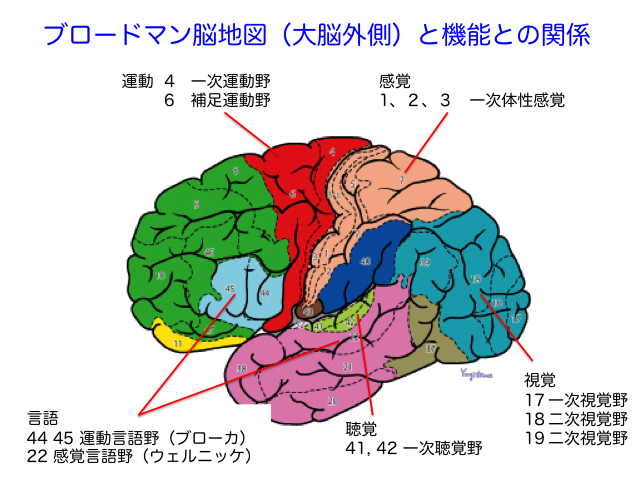
大脳皮質には機能局在があり、役割ごとに運動野、言語野、視覚野などの野(Area)があります(確かブロードマンの分類では全部で46野だったと思います)。それらを機能単位でまとめたものが前頭葉や側頭葉、後頭葉などの葉(Lobe)です。この構造はなにも学習が始まっていない、胎内の赤ちゃんの頃からある程度構造として作られており、3歳くらいまで発達はしますが機能局在として大きくは変わりません。ニューラルネットの論理で考えれば、バックプロパゲーションにせよ誤差拡散にせよ、学習をしてから野や葉を分化していくほうが合理的であるような気がします。人間の学習なんて小規模なデータセットで都度学習を行うようなものですから、学習前のモデルにすでにこのブロックは画像用、このブロックは言語用、このブロックは体を動かす用と決めておくのは非効率な気がします。複数のLLMのマージのようなものなのかもしれませんが、46個のLLMをマージするよりもう少しうまい方法があるような気がしてなりません。それにもかかわらずこのように予め機能局在が分かれていることを考えると、仮にED法が生物の学習の主な学習方法であったとした場合、学習前のモデルにすでに特定のブロックを特定の用途のために使うと決めておく方がいいシステムがあるのかもしれません。
そして先日、以下のような記事を目にし、ものすごくびっくりしました。
スパース・オートエンコーダー(SAE)という技術を用いて大規模言語モデル(LLM)の内部構造を調べたところ、LLMの内部構造は「概念」を表現する特徴点が「原子(atom)」「脳(brain)」「銀河(galaxy)」の3つのスケールで組織化されており、生物の脳構造と類似しているという主張です。
この報告が真だとすると、人間の脳はニューロンの集合からなるLLMで、ブロードマンの分類は自然発生的に生じた可能性があるためです。
元素がシリコンか炭素かの違いであって、ニューラルネットが高度化するとどのようなニューラルネットであっても似たような機能を持つ部分同士が集まってクラスター化され、効率的な機能局在が自然発生するということが再現されたことになります。
そうすると遺伝子というものはAI用語でいうところの知識蒸留のような機能を持ち、子を成すということが教師-生徒間の転移学習というモデル化ができることになります。
そうであれば赤ちゃんの頭に最初からある程度の機能局在があることも自然なように思います。
この仮説が正しい場合、おそらく機能局在は各入力に近い位置に集まると考えられます。
人間の脳をものすごく単純化すると、耳から得た音声信号は側頭葉で、視覚情報は後頭葉で処理され、嗅覚と味覚は脳神経(Ⅰ、Ⅸ、Ⅻ)で、触覚や深部感覚は脊椎を通して頭頂葉に集められ、前頭葉で判断を下すことで意思決定を行うといわれています。
https://pathologycenter.jp/als/neuroanatomy/neuroanatomy6.html
これをLLMで再現すると、おそらく音声入力をつかさどる領域は音声入力に近い位置に、ビジョンをつかさどる領域は画像入力に近い位置に、文字情報をつかさどる領域は文字入力に近い位置にあるのが合理的なはずです。
人間が言語をしゃべる場合①話の意味を理解して②舌や喉を動かし発語するという2ステップがあり、①は感覚言語野(Welnicke野)、②は運動言語野(Broka野)と呼ばれます。①が聴覚領域と視覚領域にまたがるように配されていることもこの証左となるでしょう。
まだ読み込めていないですが、先のLLMの機能局在もたぶんそのように近い機能は近い位置に来ているんじゃないでしょうか。
余談ですが、脳梗塞などで脳にダメージを受け言語がしゃべれなくなることを「失語」といいますが、この失語にもパターンがあり、「言葉として発語できるが支離滅裂で意味を成さない」失語を「Welnicke失語」、「意味は通るが言葉として発語できない」失語を「Broka失語」といいます。由来は上記の機能局在です。
何が言いたいのかというと、おそらく今後のマルチモーダル化においては、LLMへの入力系統を完全に分離してしまうほうが人間の脳に照らして考えると正しい設計になる可能性があるということです。
人工知能とはよく言ったもので、生理学や解剖学から学ぶことはまだおおいのかもしれません。