初めまして。普段は産婦人科医をしつつAIの医学応用に関する研究をしています。
Qiitaは見る専でしたが、以下のバズっている記事を拝見した時、生理学の神経構造の話をふと思い出したのでメモ代わりに記載しようと思います。
読みにくい部分があれば申し訳ありません。
とくに@pocokhc(ちぃがぅ)さんの記事のコード詳細と実験内容を見ていた時、実際の神経系の構造とあまりに似ていたことにびっくりしました。
まず、興奮性ニューロンと抑制性ニューロンの2種類から構成されるED法の構成ですが、これは実際の神経系でも同様の構造になっています。実際の神経はシナプスのつながりをニューロンと言います。信号を伝える側の興奮性シナプスに電気が走ると、電位依存性のカルシウムチャネルが開き、Caが放出されます。このCaの影響でシナプスの末端にある小さな袋から神経伝達物質(中枢神経系では主にグルタミン酸)が放出されます。神経伝達物質はシナプス同士の隙間を伝播し信号を伝えられる側のシナプスの受容体に結合することでナトリウムイオンの通り道(Naチャネル)が開きます。Naチャネルからプラスに荷電したNaが流入することで、信号が伝えられる側の神経の電位が上がります。
一方、抑制性ニューロンの場合はγアミノ酪酸(GABA)の放出によってマイナスに荷電した塩素イオンの通り道(Clチャネル)が開き、信号が伝えられる側の神経の電位は下がります。
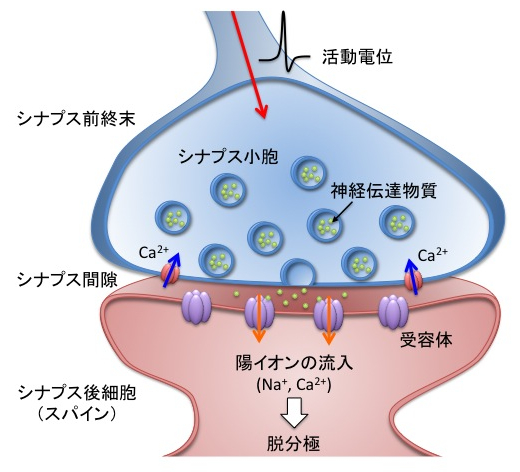
(https://bsd.neuroinf.jp/wiki/%E8%88%88%E5%A5%AE%E6%80%A7%E3%82%B7%E3%83%8A%E3%83%97%E3%82%B9 より引用)
aro kanekoさんの記事にあった
仮説2 - 二値は、(0, 1)ではなく(-1, 1)である
は、Na+イオンとCl-イオンに相当すると考えられます。
実際の神経系は複数のシナプスから電気信号を受け取るため、この興奮性ニューロンからの情報と抑制性ニューロンからの情報の総和がある閾値に達すると、大きな電位(活動電位)が急速に発生し(脱分極)、閾値に達しなければ発火しないという仕組みです。つまり微分ではなく積分のような仕組みです。末梢神経も伝達物質は異なるものの大まかな仕組みは同じです。
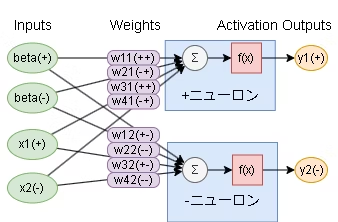
(https://qiita.com/pocokhc/items/f7ab56051bb936740b8f より引用)
この説明は医学生が必ずぶち当たる壁の一つで、(少なくとも当時の自分は)そういうものとして飲み下していましたが、+/ーの伝播だけでなぜ複雑な思考ができるのかは腑に落ちていませんでした。記事でもふれられていますが、金子さんの主張通り実際の生理学にかなり近い印象があり、このような単純な仕組みでニューラルネットの学習が可能であることにまず感動しました。
また、もう一つドキッしたのは以下の部分です。
また、10層だとTensorflowは学習できていません。(約54%程の精度)
これは勾配消失が起きて学習できていないからだと思われます。(5層に減らすとTensorflowでも学習できる)
何がびっくりしたかというと、大脳新皮質って6層構造なんです。4層部分までで入力を受け取りつつニューラルネットを構築し、第5層、第6層で大脳のほかの部分や脳幹・脊髄などに投射する構造になっています。医学生時代、この構造を学んだ時なんでもっと層を増やす方向に進化しなかったのか謎だったんですが、おそらく増やし過ぎると勾配消失が起きるんでしょうか。
もちろん、ちぃがぅさんの言っていることはこの中の特定の層のニューロンが5の場合の方が10の時より勾配消失が起きにくいというようなことだと思うのですが、各層を大きなブロックとしてみたとき、やはり5‐6ブロックくらいが一番ちょうどよいのかもしれません。
でもこれはバックプロパゲーションでも同じ話ですね。
ここまで書いたとき、自分の中に2つの仮説が沸きました。
大脳皮質には機能局在があり、役割ごとに運動野、言語野、視覚野などの野(Area)があります(確かブロードマンの分類では全部で46野だったと思います)。それらを機能単位でまとめたものが前頭葉や側頭葉、後頭葉などの葉(Lobe)です。この構造はなにも学習が始まっていない、胎内の赤ちゃんの頃からある程度構造として作られており、3歳くらいまで発達はしますが機能局在として大きくは変わりません。ニューラルネットの論理で考えれば、バックプロパゲーションにせよ誤差拡散にせよ、学習をしてから野や葉を分化していくほうが合理的であるような気がします。人間の学習なんて小規模なデータセットで都度学習を行うようなものですから、学習前のモデルにすでにこのブロックは画像用、このブロックは言語用、このブロックは体を動かす用と決めておくのは非効率な気がします。複数のLLMのマージのようなものなのかもしれませんが、46個のLLMをマージするよりもう少しうまい方法があるような気がしてなりません。それにもかかわらずこのように予め機能局在が分かれていることを考えると、仮にED法が生物の学習の主な学習方法であったとした場合、学習前のモデルにすでに特定のブロックを特定の用途のために使うと決めておく方がいいシステムがあるのかもしれません。
遺伝子の情報が事前学習に相当し、予め合理的な分布になるように進化していった可能性もありますが、それはそれで生物の学習が子や孫の遺伝子発現に影響している可能性を表すことを示しており、すごい発見なのかもしれません。あるいは、学習結果の伝搬を行うための遺伝子のようなものが別にあると、遺伝的アルゴリズムのような手法でニューラルネットそのものを進化させることが可能なのかもしれません。Sakana AIの基盤モデルに進化的アルゴリズムが使われている(https://gigazine.net/news/20240322-sakana-ai-evolutionary-model-merge/ )というニュースを最近見ましたが、この辺りと関連が深いような気がしています。
また、中枢神経の一部が事故や手術のため欠損した場合、リハビリすることで本来その失われた機能部分には影響していないはずの部分が、その機能を大きく損なうことなく失われた機能を補うことがあります。脳神経は一般的には殆ど再生しないといわれていますので、このような可塑性はニューラルネットワークシステムのダメージを回復させる手法に応用できるのではないでしょうか。
最後は取り留めのない話になってしまい、全体的にも何が言いたいのかよくわからなくなってしまいましたが、ここまでお読みくださりありがとうございました。
情報工学や脳神経外科を専攻していたわけではないので、間違いなどありましたら教えていただければ幸いです。
2024/04/24追記
また、最初の入力値は"+"と"-"に同じ値を分けて使います。(なので必ず入力は2n)
この部分を読んでふと思いましたが、人間の感覚器って大体2対ですね(目とか耳とか鼻の孔とか。舌も左右対称に各味覚の受容器が並んでいますし)。運動器も二対ですが、深部覚とか温痛覚とかも担っていると思えば感覚器の一種です。対して内臓は必ずしも2対ではなく、非対称です。
この理由として、受信対象からの左右の感覚器の距離の差によって方向を推定するという説明がよくされますが、なぜ上下方向の方向推定を行う仕組みがないのか疑問でした。重力の影響が一見もっともらしい説明かと思いましたが、その仕組みを作らなくていい理由が思いつきませんでした。外界からの入力情報が2n必要だからかもしれない、と思った次第です。