概要
1年以上前に作ったベイジアンABテストPyMC3版がCoLab上で上手く動作しなくなっていました..
旧PyMC3版に関する記事
ごりごり実装版に関する記事
ベイジアンABテストとは?な記事
以下によると,PyMC4.0のリリースと共にPyMCに名称変更された模様,,,
そこで今回は,PyMC3をPyMCに置き換えた上で,入力フォームのUIにGradioを導入しました.より使いやすくなるように,機能やビジュアルにも手を加えています.主な変更点は以下.
- 使用ライブラリを
PyMC3からPyMCに変更 - 入力フォームのUIを
Gradioに変更 - 対応テストパターンを
2つから4つに増加 - 各テストパターンの良し悪しを定量的に見える化
- テストパターンの比較方法を
B - AからB / Aに変更
PyMCの以下のドキュメントを参考に実装していますが,グラフなどの見える化はPyMCを使わずMatplotlib,Seabornなどを使っています.
使い方
ベイジアンABテストとは?などは↑の記事を参照ください.
準備
↑にてOpen in Colabボタンを押します.

表示されたCoLabにて右上の接続ボタンを押して起動.
上から順番に▶ボタン(再生ボタンみたいなやつ)を押していきます.PyMCはCoLabに既に入っているため,gradioとjapanize_matplotlibをpip install.

私の環境では以下のように出力され,何故か403に..
Colab notebook detected. To show errors in colab notebook, set debug=True in launch()
Note: opening Chrome Inspector may crash demo inside Colab notebooks.
To create a public link, set `share=True` in `launch()`.
Running on https://localhost:7860/

https://localhost:7860/にアクセスしたらちゃんとUIが表示されました!
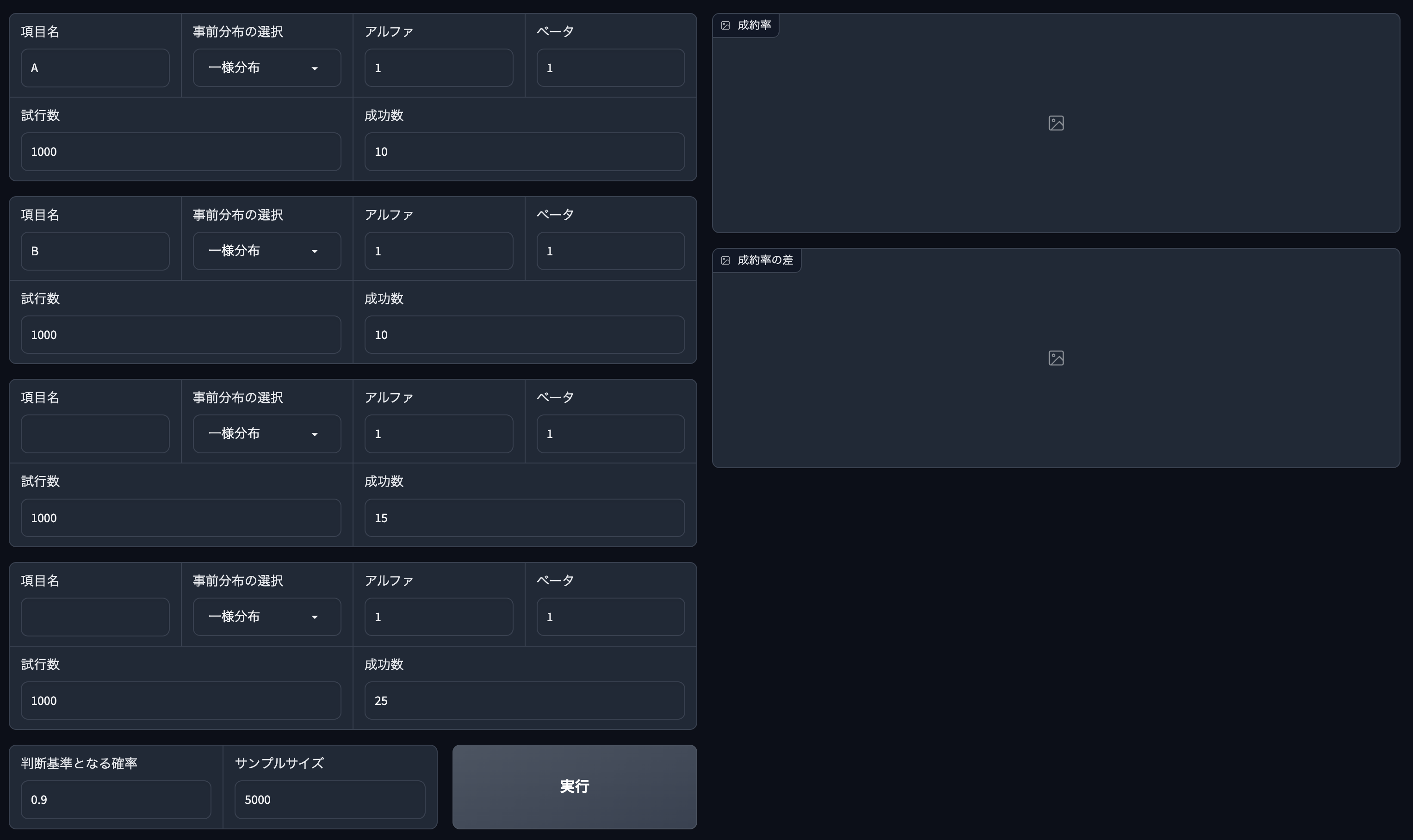
データを入力
各入力項目の説明は以下です.
まず最大4つのテストパターンの情報を入力.2パターン以上の入力が必須.
-
項目名
- ABテストのパターン名
-
4つのパターンの中で項目名が入っているデータが使用される - 上
2つの項目名にはデフォルトでAとBが入っており,残り2つは空白
-
事前分布の選択
-
一様分布とベータ分布が選択できる - 通常は
一様分布を選択
-
-
アルファ/ベータ
-
一様分布選択時は自動的に1.0/1.0となる -
ベータ分布選択時は必要に応じて数値を入力
-
-
試行数
- ページビューやインプレッションなど,テストを試行した数を入力
- デフォルトでは適当な数が入っている
-
成功数
- コンバージョンや購入など,試行に対して成功したか否かの数を入力
- デフォルトでは適当な数が入っている
次にベイジアンABテストに必要な設定を入力.指定が無ければそのままでOK.
-
判断基準となる確率
- ABテストで優劣を判断する際に基準となる確率を設定
-
90%であれば0.9,95%であれば0.95と入力
-
サンプルサイズ
- 確率分布を生成する際のサンプル数を設定
- 数が大きいほど正確な分布が出るが処理に時間がかかる
- 目安は
5000で1分ちょっと
実行
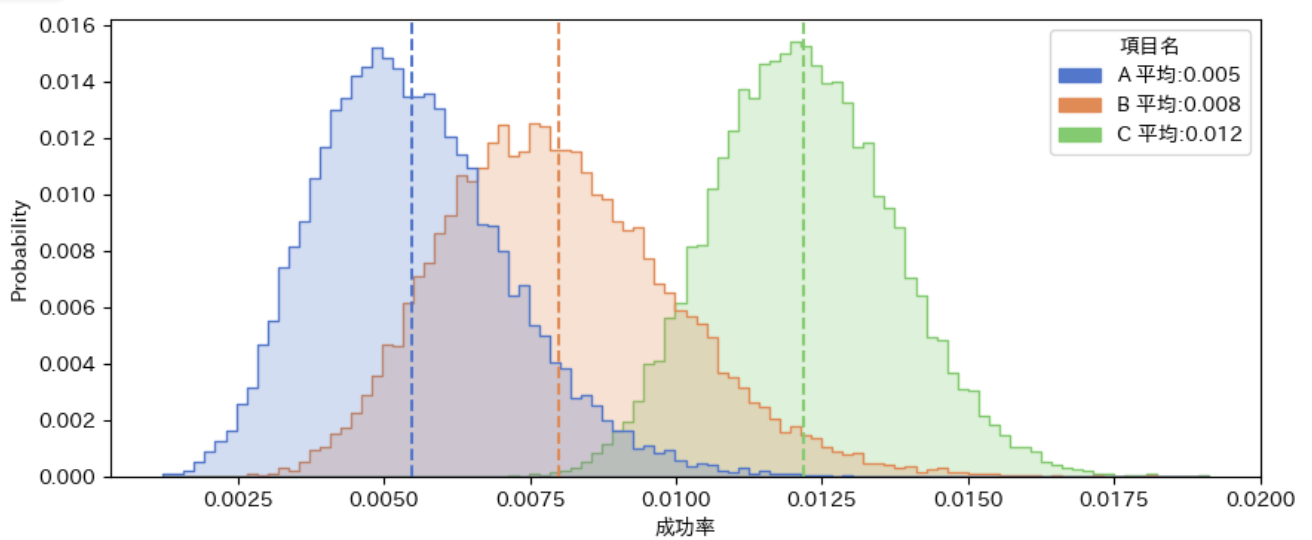
実行ボタンを押してしばらく待てば結果が表示されます!以下はA,B,Cの3パターンを評価した結果です.
成功率のグラフでは,テストパターンそれぞれの成功率の確率分布を表示しています.点線がそれぞれの平均を示しています.
成功率の差のグラフでは,ABCをそれぞれ比較したとき,成功率が何倍優れているか,の確率分布を表示しています.塗りつぶされたところが判断基準となる90%のエリアなので,赤い線である1倍が塗られたエリアの外にあるとき,2つのテストパターンには差がある,と判断できます.
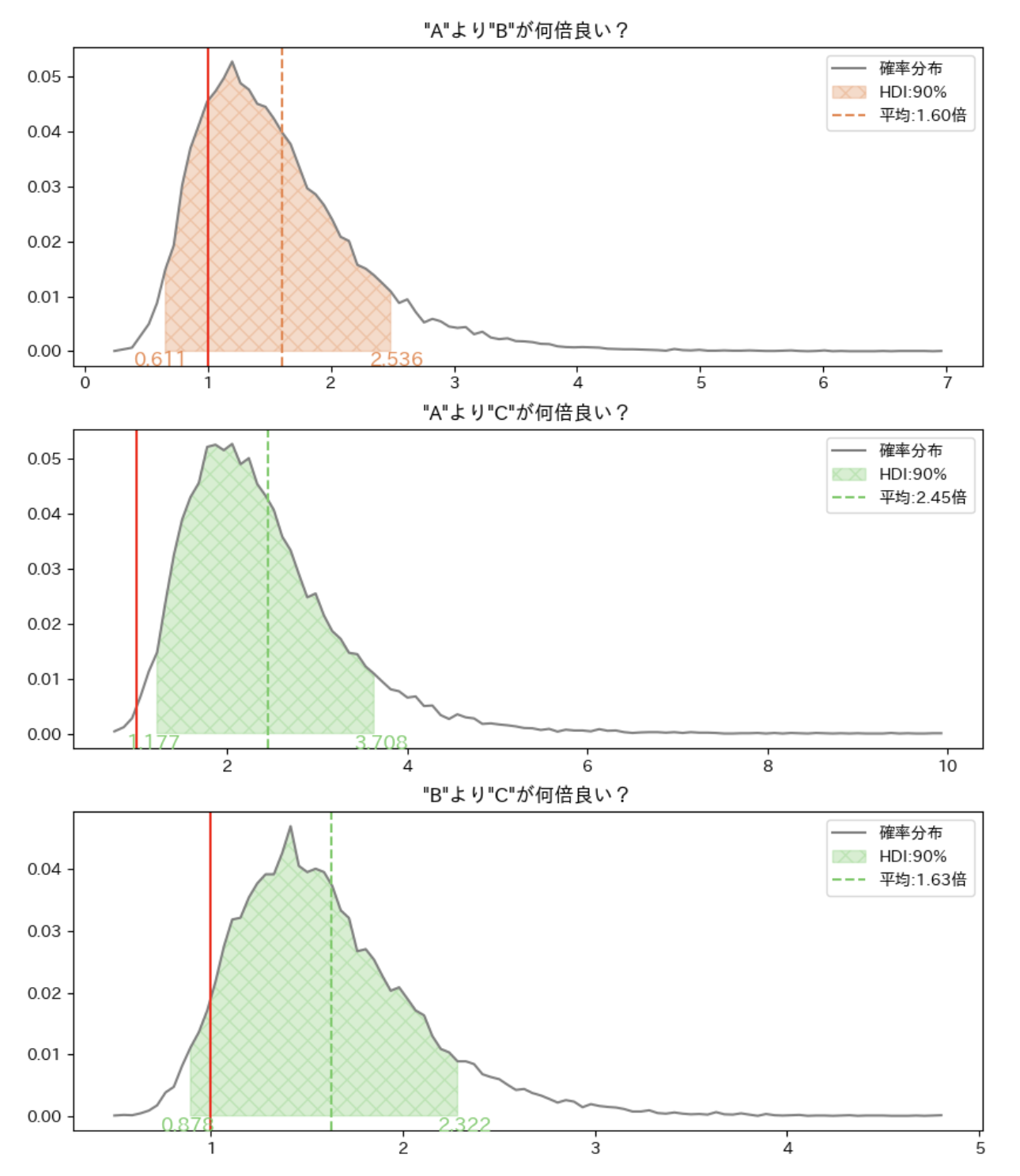
今回はテストパターンがABCの3つなので,
-
AよりBが何倍良い?- 平均
1.6倍だが有意差無し
- 平均
-
AよりCが何倍良い?- 平均
2.45倍で有意差有り
- 平均
-
BよりCが何倍良い?- 平均
1.63倍で有意差無し
- 平均
の3パターンを示せば網羅できます.BよりAが何倍良い?はAよりBの逆なので評価していません.ちなみにABCDの4パターンのときは,全部で6通りの組み合わせが評価されます.
実装
コードだけ貼っておきます.コメント無くてすみません..あとあと整理するかも..
from pydantic.dataclasses import dataclass
import io
import gradio as gr
import pymc as pm
import arviz as az
import traceback
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from PIL import Image
from matplotlib.patches import Patch
import numpy as np
import pandas as pd
@dataclass
class Pattern:
name: str
alpha: float
beta: float
trials: int
successes: int
@dataclass
class Comb:
key: str
challenger: int
champion: int
def convert_params(params):
param_size = 5
all_size = len(params)
pattern_size = all_size // param_size
pattern_param_size = pattern_size * param_size
patterns = []
for i in range(0, pattern_param_size, param_size):
if params[i] == '':
break
p = params[i:i + param_size]
patterns.append(Pattern(*p))
threshold = params[pattern_param_size]
sample_size = int(params[pattern_param_size + 1])
return patterns, threshold, sample_size
def make_trace(patterns, threshold, sample_size):
pattern_size = len(patterns)
combs = {
2: [Comb('1_0', 1, 0)],
3: [Comb('1_0', 1, 0), Comb('2_0', 2, 0), Comb('2_1', 2, 1)],
4: [
Comb('1_0', 1, 0), Comb('2_0', 2, 0), Comb('3_0', 3, 0),
Comb('2_1', 2, 1), Comb('3_1', 3, 1), Comb('3_2', 3, 2),
],
}[pattern_size]
with pm.Model() as model:
# 事前分布
p = pm.Beta(
'p',
alpha=[p.alpha for p in patterns],
beta=[p.beta for p in patterns],
shape=pattern_size,
)
# 事後分布
obs = pm.Binomial(
'y',
n=[p.trials for p in patterns],
observed=[p.successes for p in patterns],
p=p,
shape=pattern_size,
)
for c in combs:
pm.Deterministic(c.key, p[c.challenger] / p[c.champion])
return pm.sample(draws=sample_size), combs
def make_plot_image():
buf = io.BytesIO()
plt.savefig(buf, format='png')
buf.seek(0)
img = Image.open(buf)
img = np.array(img)
plt.close()
return img
def plot_probs(patterns, trace, threshold, sample_size):
pattern_size = len(patterns)
v = trace.posterior['p'].values
names = [p.name for p in patterns]
samples = pd.DataFrame(
v.reshape((v.shape[0] * v.shape[1], v.shape[2])),
columns=names,
)
samples = samples.stack().to_frame()
samples.reset_index(level=1, inplace=True)
samples.columns = ['項目名', '成功率']
colors = sns.color_palette('muted')
plt.figure(figsize=(10, 4))
sns.histplot(
data=samples, x='成功率', hue='項目名',
bins=100, hue_order=names,
stat='probability', element='step',
palette=colors[:pattern_size],
)
labels = []
for i, name in enumerate(names):
g = samples[samples['項目名'] == name]
mean = g['成功率'].mean()
plt.axvline(x=mean, color=colors[i], linestyle='dashed')
labels.append(Patch(facecolor=colors[i], edgecolor=colors[i], label=f'{name} 平均:{mean:.3f}'))
plt.legend(title='項目名', handles=labels)
plt.grid(False)
return make_plot_image()
def plot_combs(patterns, trace, combs, threshold, sample_size):
comb_size = len(combs)
colors = sns.color_palette('muted')
if comb_size > 1:
fig, axes = plt.subplots(comb_size, 1, figsize=(10, comb_size * 4))
else:
fig, ax = plt.subplots(comb_size, 1, figsize=(10, comb_size * 4))
axes = [ax]
for i, c in enumerate(combs):
name = f'"{patterns[c.champion].name}"より"{patterns[c.challenger].name}"が何倍良い?'
v = trace.posterior[c.key].values
samples = pd.DataFrame(
v.reshape((v.shape[0] * v.shape[1])),
columns=[name],
)
counts = samples[name].value_counts(bins=100, sort=False)
counts.index = counts.index.left
rates = counts.to_frame()
rates[name] = rates[name] / rates[name].sum()
ax = axes[i]
ax.plot(rates, color='gray', label='確率分布')
ax.set_facecolor((1, 1, 1, 1))
hdi = az.hdi(samples[name].values, hdi_prob=threshold)
index = rates[name].index
region = (hdi[0] < index) & (index < hdi[1])
color = colors[c.challenger]
ax.fill_between(
index[region], rates[name][region], 0, alpha=0.3,
color=color, hatch='xx', label=f'HDI:{threshold * 100:.0f}%',
)
ax.axvline(
x=samples[name].mean(), color=color,
label=f'平均:{samples[name].mean():.2f}倍', linestyle='dashed',
)
ax.axvline(x=1.0, color='red')
ax.text(hdi[0], 0, f'{hdi[0]:.3f}', ha='center', va='top', color=color, size='large')
ax.text(hdi[1], 0, f'{hdi[1]:.3f}', ha='center', va='top', color=color, size='large')
ax.grid(False)
ax.legend()
ax.set_title(name)
return make_plot_image()
def beyesian_ab(*params):
try:
# 各種パラメータ取得
patterns, threshold, sample_size = convert_params(params)
# ベイジアンモデル
trace, combs = make_trace(patterns, threshold, sample_size)
# 成約率一覧
s_probs = plot_probs(patterns, trace, threshold, sample_size)
# 有意差一覧
s_combs = plot_combs(patterns, trace, combs, threshold, sample_size)
return s_probs, s_combs, ''
except Exception as e:
return None, None, str(traceback.format_exc())
def change_prior(prior_index):
if prior_index == 0:
return gr.update(value=1, interactive=False)
else:
return gr.update(interactive=True)
def add_pattern(name, default_value=10):
with gr.Row():
name = gr.Textbox(label='項目名', value=name, interactive=True)
prior = gr.Dropdown(
['一様分布', 'ベータ分布'], label='事前分布の選択', type='index', value='一様分布',
interactive=True, scale=1)
prior_alpha = gr.Number(label='アルファ', value=1, minimum=0, interactive=False)
prior_beta = gr.Number(label='ベータ', value=1, minimum=0, interactive=False)
prior.change(change_prior, inputs=prior, outputs=prior_alpha)
prior.change(change_prior, inputs=prior, outputs=prior_beta)
posterior_trials = gr.Number(label='試行数', value=1000, minimum=1, interactive=True)
posterior_successes = gr.Number(label='成功数', value=default_value, minimum=0, interactive=True)
return name, prior_alpha, prior_beta, posterior_trials, posterior_successes
with gr.Blocks() as app:
with gr.Row():
with gr.Column():
params_a = add_pattern('A')
params_b = add_pattern('B')
params_c = add_pattern('', default_value=15)
params_d = add_pattern('', default_value=25)
params = list(params_a)
params.extend(params_b)
params.extend(params_c)
params.extend(params_d)
with gr.Row():
threshold = gr.Number(
label='判断基準となる確率', value=0.9, minimum=0, maximum=1,
step=None, interactive=True,
)
sample_size = gr.Number(label='サンプルサイズ', value=5000, minimum=0, interactive=True)
run = gr.Button('実行')
params.append(threshold)
params.append(sample_size)
with gr.Column():
s_probs = gr.Image(label='成約率')
s_combs = gr.Image(label='成約率の差')
run.click(fn=beyesian_ab, inputs=params, outputs=[s_probs, s_combs], api_name='beyesian_ab')
app.launch(height=1280)