Cloud Composerを使用して簡単なワークフローを定義・実行したので、その際の処理の概要やCloud Composerについて学習したことをアウトプットしたいと思います。firebase-public-datasetを利用して、Cloud Storage上のデータをBigQueryの作業テーブルに取り込み、テーブルの結合などを行い、最後にBigQueyの作業用テーブルを削除する、という3つのタスクを定義・実行しました。GCP初学者なので、内容に誤りがあるかもしれません。その際はご指摘していただけると幸いです。
本記事の対象読者
・GCPを扱い初めて間もない方
・Cloud Composerを初めて利用する方
本記事で扱わないこと
・Cloud SDKのセットアップ:記事内でターミナル上でコマンドを実行しGCPを操作することがありますが、Cloud SDKのセットアップは下記の記事を参考にしてください。
Cloud SDK
・課金される料金の説明:課金される料金についての責任を負いかねますので、ご自身で公式サイトを確認しながら、ストレージやテーブル、プロジェクトの管理をお願いします。
Google Cloudの料金
実行環境
・macOS BigSur v11.6.4
・Cloud Composer v1.18.10
・Apache Airflow v1.10.15
Cloud Composerの概要
Google Cloudには効率的なデータ分析基盤のワークフロー管理を可能にするCloud Composerがあります。OSSのApache Airflowが活用されており、Pythonで各タスクや有向非巡回グラフ(以降DAG)、ワークフローを定義できます。また、BigQueryやDataflow、 Dataprocなどの他のサービスと連携させることで、これらのサービスを使用するワークフローを効率的に作成・運用できます。
主なコンポーネント
・GKEクラスタ:Airflowスケジューラ、ワーカー、Redisキューは、単一のクラスタでGKEワークロードとして実行され、DAGの処理と実行を行う
・Cloud Storageバケット:Cloud Composer環境のAirflowはこのファイルを関連付け、DAG、ログ、カスタムプラグイン、データが保存される
・Cloud logging:Airflow環境のログが自動で連携される
・Cloud Monitoring:AirflowやCloud Composer環境の指標が自動で連携される
Airflow DAG
Airflow DAGはワークフローであり、追加のタスク依存関係を持つタスクの集まりです。また、各タスクの処理内容を定義するのにPythonを使用し、個々のタスクの依存関係をDAGとして表現、定義します。作成したPythonファイルをCloud Storageのバケットに配布することで、そのファイルに定義されているDAGが自動的にCloud Composerの環境へデプロイされます。下図の例だと、load_events -> insert_dat -> delete_work_table の順に実行するという依存関係および処理フローを定義しています。
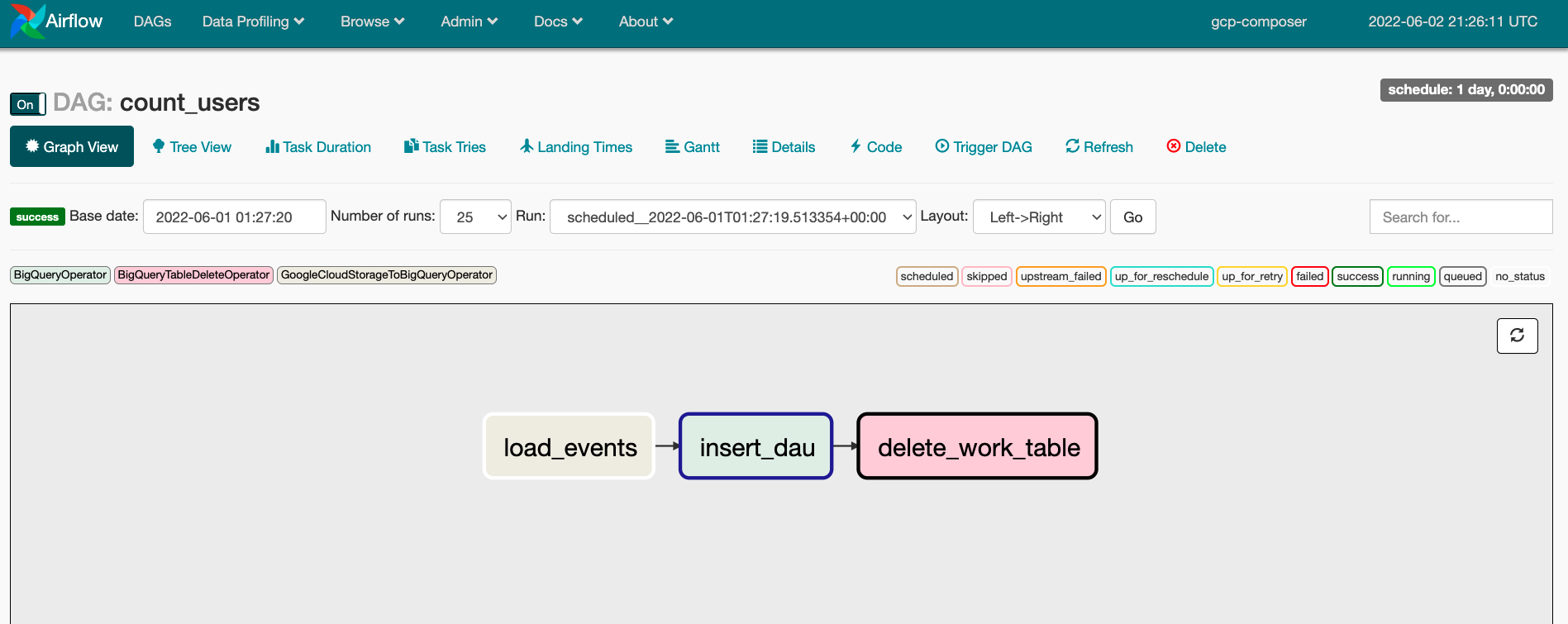
DAGの作成
・bigquery_operator:BigQueryでクエリを実行するライブラリ。
・bigquery_table_delete_operator:BigQueryのテーブルを削除するためのライブラリ。
・gcs_to_bq:Cloud StorageからBigQueryにデータをロードするためのライブラリ。
・pendulumはタイムゾーンやdatetime, durationを簡単に計算・設定できるライブラリです。
# pythonモジュールのインポート
import datetime
import airflow
from airflow.contrib.operators import bigquery_operator, \
bigquery_table_delete_operator, gcs_to_bq
# タイムゾーンの設定やdatetimeを簡単に行えるライブラリ
import pendulum
defalut_argsへはDAGないの全オペレータに共通して設定するパラメータを定義します。
・retries:各タスクの処理が正常に実行完了しなかった場合、n回そのタスクが再実行されます。(1が設定されているので、1回再実行する)
・retry_delay:タスクが失敗してからn時間後にリトライ処理が実行されます。(minutes=5が設定されているので、5分後に再実行する)
・start_date:開始日時の設定(下記の例だとDAG作成日の午前2時(JST)が開始日時)
default_args = {
'owner': '<your project>',
'depends_on_past': False,
'email': [''],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
# DAG作成日の午前2時(JST)を開始日時とする。
'start_date': pendulum.today('Asia/Tokyo').add(hours=2)
}
with airflow.DAG() as dag:のコンストラクタでDAGが定義されます。
・ID: コードの例だとcount_usersというIDが設定されます。
・schedule_interval: DAGが起動・実行される日時を設定できます。(例の場合だとDAGが日時で起動・実行される)
・catchup: DAGの作成時より過去の日付の処理を実行するかどうかを設定できます。
# DAGを定義する。
with airflow.DAG(
'count_users',
default_args=default_args,
# 日次でDAGを実行する。
schedule_interval=datetime.timedelta(days=1),
catchup=False) as dag:
load_eventsでCloud Storage上のユーザー行動ログをBigQueryの作業用テーブルに取り込みます。
・ds_nodash:Airflowでデフォルトで使用できる変数として提供されており、YYYYMMDD形式のDAG実行日が格納されています。
・destination_project_dataset_table:データがロードされるテーブルが設定されています。このテーブルは予め用意しておく必要はなく、タスクの実行によりテーブルが作成されます。
・source_format:ロード対象のデータファイルの形式が設定されています。NEWLINE_DELIMITED_JSONは改行区切りのJSON。
load_events = gcs_to_bq.GoogleCloudStorageToBigQueryOperator(
task_id='load_events',
bucket='<your bucket name>',
source_objects=['data/events/{{ ds_nodash }}/000000000000.json.gz'],
destination_project_dataset_table='gcp_tutorial.work_events',
source_format='NEWLINE_DELIMITED_JSON'
)
BigQueryのクエリを実行し、テーブルにデータを挿入するタスクが定義されています。
・use_legacy_sql:FalseにすることでBigQueryの標準SQLを使用できます。
・sql:タスク実行時にBigQueryで実行されるSQL。
・ds:Airflowでデフォルトで使用できる変数であり、YYYY-MM-DD形式のDAG実行日が格納されます。
insert_dau = bigquery_operator.BigQueryOperator(
task_id='insert_dau',
use_legacy_sql=False,
sql="""
insert gcp_tutorial.dau
select
date('{{ ds }}') as dt
, countif(u.is_paid_user) as paid_users
, countif(not u.is_paid_user) as free_to_play_users
from
(
select distinct
user_pseudo_id
from
gcp_tutorial.work_events
) e
inner join
gcp_tutorial.users u
on
u.user_pseudo_id = e.user_pseudo_id
"""
)
BigQueryのテーブルを削除するタスクを定義し、deletion_dataset_tableに削除対象のテーブルを指定します。
最後にタスクの依存関係を定義します。この例ではload_events -> insert_dau -> delete_work_tableの順にタスクが実行されるように設定しています。
delete_work_table = \
bigquery_table_delete_operator.BigQueryTableDeleteOperator(
task_id='delete_work_table',
deletion_dataset_table='gcp_tutorial.work_events'
)
# 各タスクの依存関係を定義する。
load_events >> insert_dau >> delete_work_table
以上でDAGの定義は終了です。コード全文は以下のGitHubにアップロードされています。
コード全文
Cloud Storageへファイルをアップロード
以下のコマンドでローカル環境で作成したファイルをCloud Storage上にアップロードできます。ブラウザ上でStorageを確認してみましょう。
gcloud composer environments storage dags import --environment <your composer name> --location us-central1 --source <your python script name>
DAGの実行
以下のコマンドでDAGの実行ができます。DAGのTreeViewページでタスクの実行が終了しているかを確認できます。各タスクがsuccessになっていれば問題なく実行できています。
・backfill:特定の日付の範囲で特定のDAGを実行できます。(今回は実行日として2018-10-01を指定し、-sは開始日、-eは終了日)
gcloud composer environments run <your composer name> --location us-central1 backfill -- -s 2018-10-01 -e 2018-10-01 <your DAG ID>
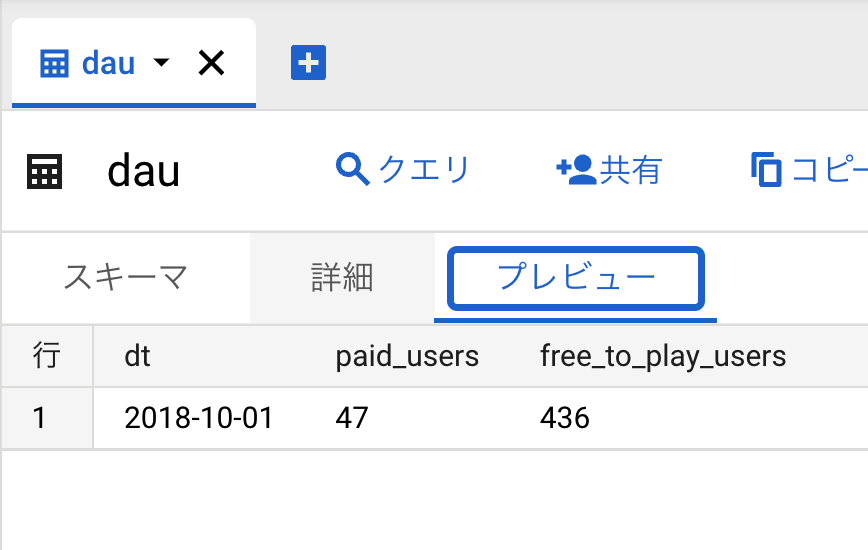
最終的に指定したテーブルのdt,paid_users,free_to_play_usersに値が格納されていればOKです。dtは指定した2018-10-01になっていてこの日の課金ユーザー数は47人、無課金ユーザーは436人という集計結果になりました。
躓いた点
Airflowのバージョンの不一致
ローカルでインストールしたAirflowのバージョンが最新の2.3.1で、Google Cloud上のバージョンが1.10.15であったため、ローカルでは2.3.1のコードをドキュメントを参考にしながら、実装しそのままCloud Storageバケットにアップロードするというミスをしてしまいました。Airflowは1.xと2.x系でライブラリの仕様に大きな変更があり、インポートするライブラリや実装方法も大きく変わったようです。
Google Cloud上のAirflowのバージョンは下図に記載されています。

またコマンドの引数として--veborsity=debugを加えることでターミナルにDEBUG結果が表示されエラーの特定に役立ちました。
gcloud composer environments run <your composer> --location us-central1 --verbosity=debug backfill -- -s 2018-10-01 -e 2018-10-01 <your DAG>
これでCloud Coomposer上のAirflowバージョンが1.10.15であることに気づけました。僕のように初歩的なミスで時間を失う方が減ると幸いです。
DEBUG: Executing command: ['/usr/local/bin/kubectl', '--namespace', 'composer-1-18-10-airflow-1-10-15-7c6f98d0',,,
ファイルパスのワイルドカードでエラーが発生
書籍ではバケットのファイルパスとしてワイルドカードが使用されていましたが、ファイルが読み込めずエラーになりました。これは明示的にファイル名を記載することで解決できました。
所感
Google Cloudのキャッチアップとして書籍をベースにCloud Composerでワークフローの定義・実行を行いました。Pythonで実装できることもあり、DAGによって複雑なタスクもワークフローとして実行できるので、データエンジニアリングする際は重宝されるサービスだと感じました。処理内容によってBigQueryでのELT処理、Dataproc、Dataflowを使った処理または今回のようにCloud Composerでタスク管理をするケース等様々考えられるので、ユースケースによって最適なサービスの選択やデータ基盤構築をできるように学習を進めていきたいと思いました。
参考文献
Google Cloudではじめる実践データエンジニアリング入門
書籍GitHub
Google Cloud Composer
Airflow