はじめに
文法誤り訂正のシステムは,誤り文を入れると修正文が出てきます.これは,一般的に,ニューラル機械翻訳の手法を使うことにより,誤り文から修正文への翻訳として実現されます.この学習データとして,学習者コーパスの誤り文と修正文のペアがよく用いられます.ここで,誤り文は図の「おかしい文」の集合全体,修正文は「ただしい文」の集合全体の部分集合になっています.(ただしさ・おかしさをgrammaticalである・ないってそのまま言っていいのかよくわからないので,あえてこういう言い方をしています)
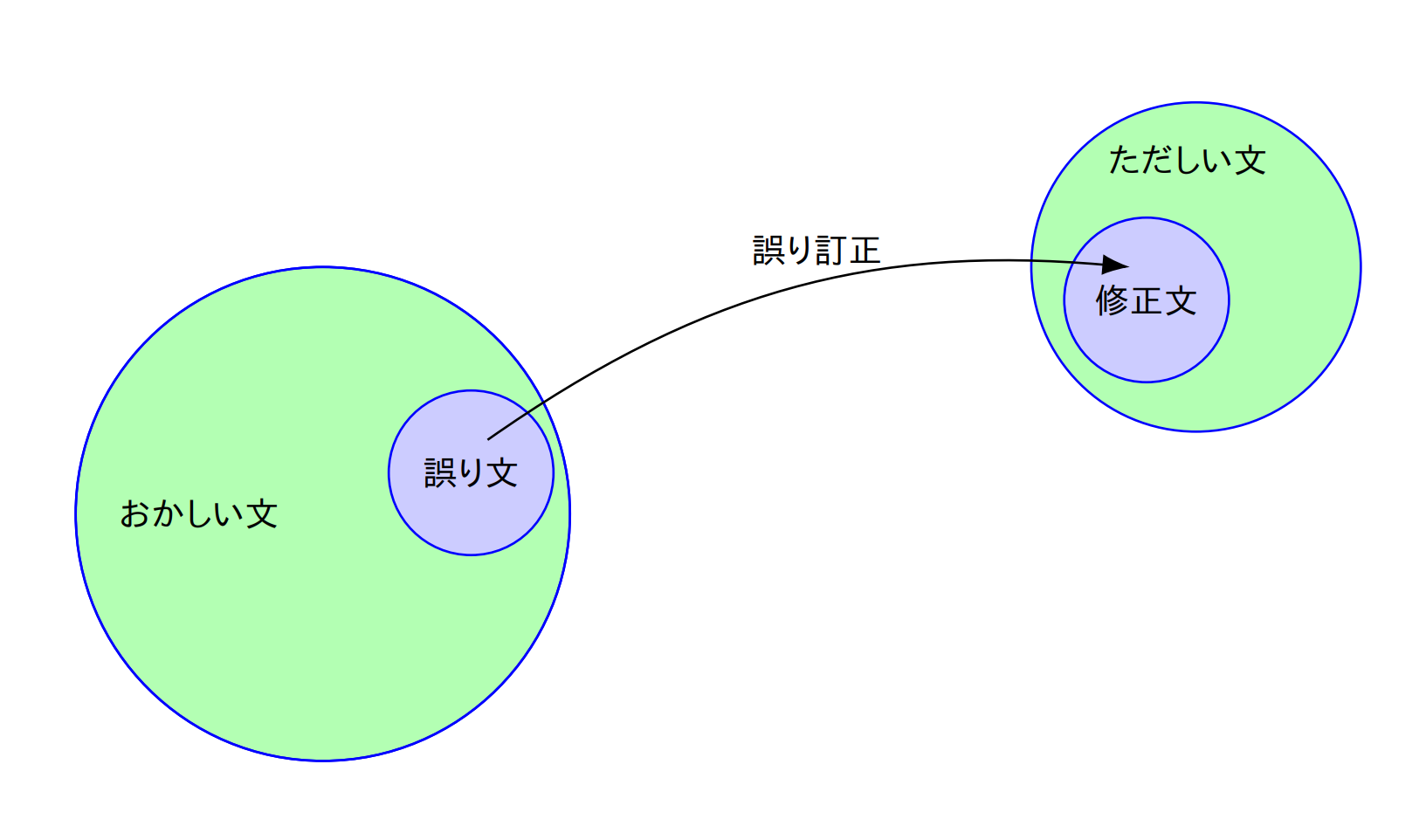
この学習者コーパスの規模が小さいく,質の良い機械翻訳モデルを学習するには不十分だということがよく言われています.そのため,「ただしい文」に人工的な誤りを加えて,データ拡張を行う研究が活発に行われています.流行りというやつです.
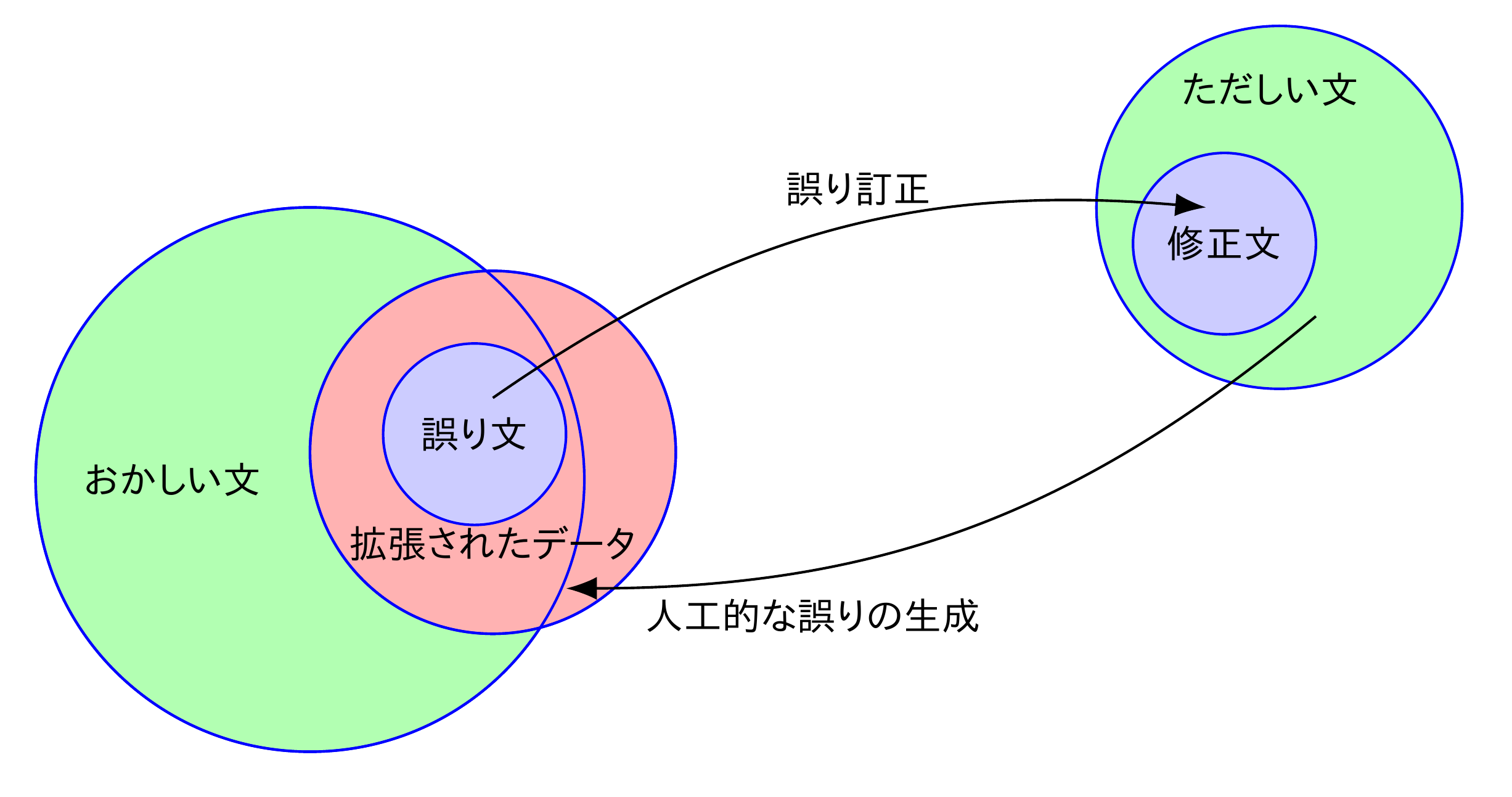
ただ,ここで言うところの人工的な誤りが必ずしも「おかしい文」である保証はあまりありません.さらに,「ただしい文」を元に誤りの生成を行ったとしても,「おかしい文」の多くを再現することができるのかどうかもよくわかりません.
そもそも,「おかしい文」は,なぜ,どのように生み出されるのでしょうか.母語話者が書き間違い・タイプミスをすることによって,綴りや表記の誤りが生み出されるということもあるでしょうし,なんかいろいろむずかしいことを考えながら書いていたら意味のわからない文ができてしまうということもあると思います.人生いろいろ.誤りもいろいろ.
ただ,やはりもっとも問題になるのは,言語学習者の誤りだと思います.「おかしい文」が言語学習者によってどのように生み出されるのかについて考えるには,学習者がどのように言語を習得するのかということについて,くわしく知っている必要があるだろうと思われます.普遍文法とか用法基盤モデルみたいな言語獲得に関する話は知っていたのですが,思えば第二言語習得に関しては何もしらないなということに気づいたので,とりあえず,関連する本をがんばっていくつか読んでみました.
いくつか紹介します.白井『外国語学習の科学』は新書ということもあり,読みやすかったです.馬場・新多『はじめての第二言語習得論講義』や,鈴木・白畑『ことばの習得』は,もうすこし詳しいことが書かれています.『外国語学習の科学』を読んだあとに読むとわかりやすいかもしれません.他にも,教室指導などのフィードバック研究の入門書もいろいろあるようです.こちらの方が文法誤り訂正と近いような気はしますが,自分はあんまりよくわかってないです.
それで,いろいろ読んだところ,どうも,誤りが生み出される仕組みとして中間言語という考えを用いるとよいのではないかと思いました.
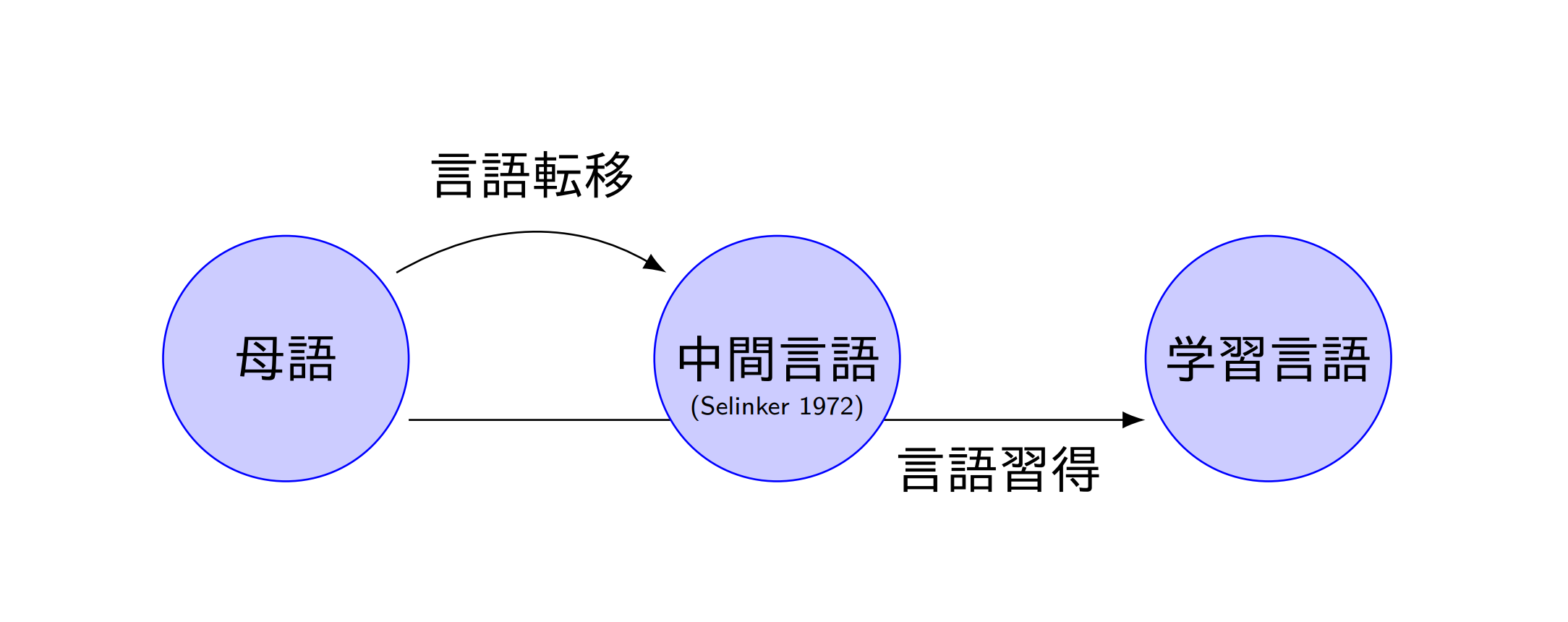
中間言語は,母語でも学習言語でもなく,その中間の位置にある,言語学習者の発達途上の言語体系のことです.言語転移は,学習者の母語の知識が言語習得に影響を及ぼすことを言います.例えば,日本語母語話者が,「濃いコーヒー」と英語で言いたいときに,"strong coffee"ではなく,"thick coffee"と言ってしまうことがあるかもしれないという具合です."thick coffee"が中間言語での表現で,"strong coffee"が学習言語での表現であると言えます.
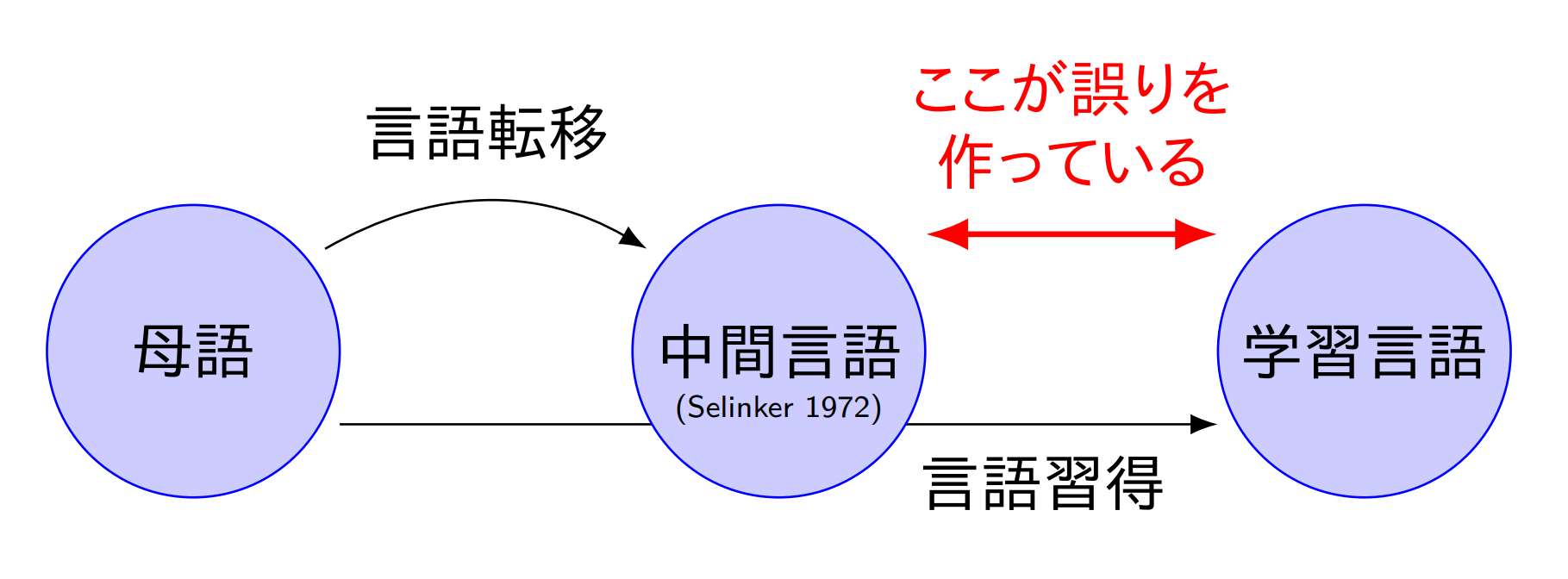
そのように考えると,中間言語の背景にある,学習者自身の知識やルールが「おかしい文」を生み出していると言えるかもしれません.さらに,そのような誤りは,中間言語と学習言語の間の差異によるものとも言えるかもしれません.
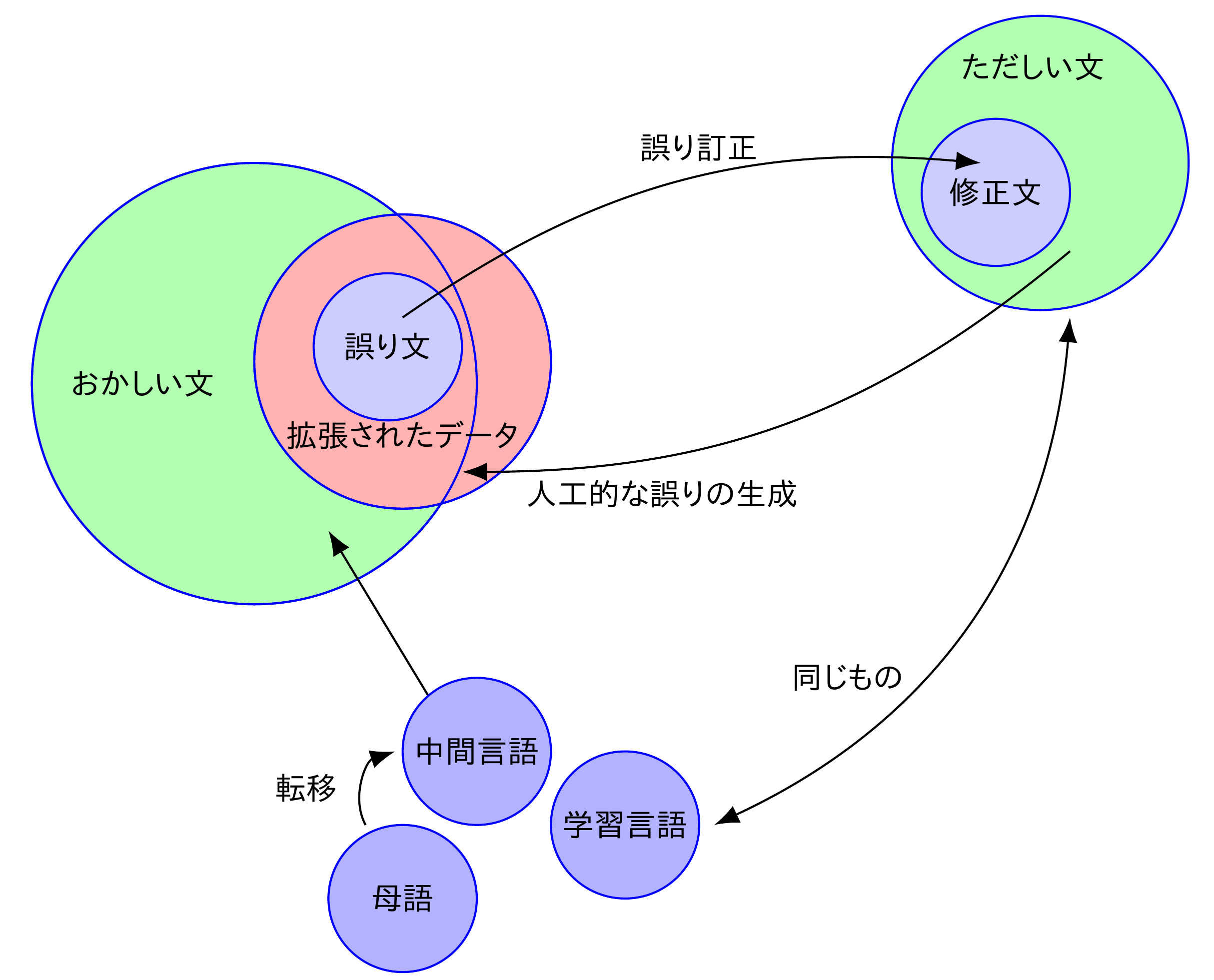
そこで,この中間言語の考えを先ほどのデータ拡張の図に追加してみます.「おかしい文」を用意するためには,中間言語が使えるかもしれないという気持ちになります.しかし,中間言語は各学習者の体系であり,統計的な手法を適用しようと思っても,例えばニュース記事のような母語話者によって書かれたデータが豊富にあるものとは異なり,データが十分にはありません.データをたくさん集めたいなと思っても,中間言語は学習者の数だけあるわけで,均質な構成員のみからなる集団(例えば,日本人の10代後半から20代前半の首都圏の理工系大学の学生など)だけから集めても,「おかしい文」のごく一部分だけの偏ったデータしか集めることができないかもしれません.「おかしい文」をなるべく多様な集団から収集したいわけですが,それはとても大変そうです.どうにかならないかという感じですが,中間言語は,母語と学習言語からできる(厳密には学習者個別の要因もあるはずですが)わけなので,これらを用いて様々な母語に対する中間言語のようなものを再現すれば,多様な中間言語から,多様な「おかしい文」を再現できるかもしれません.
各言語の単言語コーパスや機械翻訳のデータセットはたくさんあるので,原理的には,中間言語のようなものを再現することは可能なように思えます.これは,まさに,みずみずしいパラダイムの萌芽です.しかし,そこでどのような制約や機構を用いれば,さまざまなコーパスから中間言語のようなものを生成できるのかというのは,よくわかりません.
そこで,そもそも,もっと根本的に,文法誤り訂正と機械翻訳を同時学習したらどうなるんだろうという疑問が生じました.文法誤り訂正と機械翻訳のデータセットがどちらもあって,かつ,ある程度近いがそれなりに異なっている言語対でやれば,母語・学習言語間の翻訳と,おかしい文・ただしい文間の翻訳が互いに良い影響を与えて,なんかいいことがあるかもしれないという感じです.もし,これである程度うまく行ったら,それがベースラインとなって,中間言語の再現や,多様な中間言語の利用の有効性が検証できるかもしれません.それで,いろいろ考えたところ,英語とドイツ語なら近いし,やってみようという気持ちになりました.今年の夏ぐらいに思いついてやるだけやったのですが,やったっきりでもったいない気もするし,どこかに発表できるような内容でもないため,こういう形で書くことにしました.
実験設定
使用するコーパス
| コーパス | サイズ | |
|---|---|---|
| Falko Merlin | De GEC | 18,754 |
| WI&LOCNESS | En GEC | 34,308 |
| FCE | En GEC | 28,350 |
| IWSLT De-En | MT | 174,443 |
| Tatoeba De-En | MT | 378,868 |
| 合計 | 634,723 |
英独の文法誤り訂正・機械翻訳のデータセットを用います.
ドイツ語の文法誤り訂正データセット Falko Merlin は,github:adrianeboyd/boyd-wnut2018からダウンロードできます.英語の文法誤り訂正データセットは,BEA 2019 Shared Taskのものです.Lang-8コーパスやNUCLEも使えますが,あんまりデータがたくさんあると学習が大変なので今回は用いませんでした.
英独翻訳は,IWSLT 2014の英独翻訳データセットと,Tatoeba.orgのデータを用いました.今思うと,あまり素性のはっきりしないTatoebaのデータじゃなくて,WMT newsタスクのNews Commentaryデータセットあたりを使ったほうがよかったかもしれません.機械翻訳なにもわからない.
前処理
SpaCyを用いてトークナイズしたあと,BPE-Dropoutでサブワード正則化をします.Dropout確率は,訓練時のsource側で0.1,その他で0です.個人的な経験上,この値が一番良くて,綴り誤りの訂正性能が特に良くなります.Falko Merlinコーパスだけを使う場合は,語彙サイズは4,000ですが,それ以外では16,000です.Falko Merlinだけの場合は,データが少なすぎるため,語彙サイズが小さくないと厳しいようです.
複数のコーパスを同時学習するときは,どのデータなのかを区別するため,source側の先頭にタグを付けます.ドイツ語文法誤り訂正では,<de>,英語文法誤り訂正では,<en>,英->独翻訳では<e2d>,独->英翻訳では<d2e>としました.
モデル
Left-to-rightの生成をするモデルと,Right-to-leftの生成をするTransformer baseを,それぞれ5つ,異なるシードで学習します.実装には,fairseq v0.10.2を用いました.Left-to-rightのモデルで誤り訂正を行います.ビーム幅は12です.Right-to-leftのモデルは,ビームの12個の候補に対するリランキングに用いました.Left-to-rightとRight-to-leftの尤度を足して並べ替えます.
マスク言語モデルを用いてさらにリランキングを行う実験もしてみました.その際には,Salazar+ 20の手法を採用し,ドイツ語で,bert-base-german-dbmdz-cased,英語でroberta-largeを用いました.validationデータで適切なハイパーパラメータλを決めて,(Left-to-rightの尤度) + (Right-to-leftの尤度) + λ × (マスク言語モデルの疑似尤度)として並び替えます.
評価
M2 Scorerを用いました.F${}_{0.5}$値で評価します.よく使われてるやつです.
実験
2080tiでやりました.
Falko Merlinコーパスのみ
| Falko Merlin (test) | P | R | F 0.5 |
|---|---|---|---|
| シングル | 63.38 | 45.11 | 58.63 |
| アンサンブル | 67.21 | 45.88 | 61.49 |
| + R2L | 69.81 | 46.27 | 63.36 |
| + MLM | 72.33 | 51.55 | 66.93 |
Falko Merlinコーパスがかんたんなデータセット(多分)だったり,train/valid/testのドメインが同じだったりということもあり,2万文程度の学習データでも,なんかそれなりにうまく行ってしまっている感じがあります.アンサンブルでPrecisionが上がるというのは,どこでも大体そうなんだろうという気がしますが,Right-to-leftのモデル,マスク言語モデルを用いたリランキングがかなり効いてていいですね.あと,実際に生成結果を見てみるとそれなりに同一トークンの反復が起きているのが確認できます.データサイズが小さすぎるのでしょうがないのかもしれません.
IWSLT De-Enデータとの同時学習
| Falko Merlin (test) | P | R | F 0.5 |
|---|---|---|---|
| シングル | 71.30 | 57.49 | 68.03 |
| アンサンブル | 73.76 | 58.63 | 70.14 |
| + R2L | 75.29 | 59.33 | 71.45 |
| + MLM | 75.64 | 61.38 | 72.28 |
とりあえず,IWSLT De-Enといっしょに学習させてみました.De-Enの向きとEn-Deの向きの両方を加えています.なんかめちゃくちゃスコア上がりました.びっくりですね.思うに,同時学習の効果がどうとかよりも,単純にデータが増えたことが強く影響してそうです.
WI&LOCNESS, FCE, Tatoeba De-Enを追加
| Falko Merlin (test) | P | R | F 0.5 |
|---|---|---|---|
| シングル | 72.09 | 59.08 | 69.05 |
| アンサンブル | 74.20 | 59.90 | 70.82 |
| + R2L | 75.96 | 60.74 | 72.34 |
| + MLM | 76.35 | 63.19 | 73.30 |
全部入れてみました.ちょっとスコアが上がりました.英語文法誤り訂正のデータセットも入れてみたわけですが,すごく効果があるわけでもなさそうです.やっぱり,データが増えただけという感じがしますね.翻訳データを有効に使おうと思ったら,いろいろと制約をつけたり工夫が必要そうです.
Falko Merlinでfine-tuning
| Falko Merlin (test) | P | R | F 0.5 |
|---|---|---|---|
| シングル | 72.72 | 60.48 | 69.89 |
| アンサンブル | 74.57 | 61.28 | 71.47 |
| + R2L | 76.30 | 61.92 | 72.91 |
| + MLM | 76.75 | 64.88 | 74.04 |
最後に,全部入れてみたやつのモデルに対して,Falko Merlinコーパスだけを用いてfine-tuningをしてみました.ちょっとスコアが上がりました.
比較
| Falko Merlin (test) | P | R | F 0.5 |
|---|---|---|---|
| Grundkiewicz+ 19 | 73.0 | 61.0 | 70.24 |
| Náplava+ 19 | 78.21 | 59.94 | 73.71 |
| Rothe+ 21 | 75.96 |
Grundkiewicz+ 19は,1億文に誤り生成をし,事前学習+fine-tuningをしました.Náplava+ 19は,1千万文に誤り生成をし,事前学習+fine-tuningをしました.Rothe+ 21は,T5を用いて,また,cleaned Lang-8コーパスを作って文法誤り訂正を行いました.Googleはすごいですね.ちなみに,Grundkiewicz+ 19では,trainデータのうち,target側がvalid/testにも現れるものを取り除いています.自分もこれにならいました.他の論文では,取り除かずに用いています.性能にはほとんど影響がないようではあるのですが,こういうのはどうするのがいいのかよくわかりません.
さて,最終的にFalko-Merlinコーパスでfine-tuningした結果と比べると,アンサンブルした時点で,Grundkiewicz+ 19より高いスコアとなっており,リランキングもすると,Náplava+ 19よりも高いスコアとなってしまいました.正直,F値70出たら嬉しいなぐらいの気持ちで始めたので,ちょっとよくわかりません.low-resourceな場合は,何千万文でのデータ拡張を頑張らなくても,数十万から百万文対程度の翻訳データをうまいこと使っても割とうまく行くということなのかもしれません.既存のデータ拡張手法がうまくいってないということかもしれません.よくわかりません.
この結果が,中間言語のような概念と関係してくるのかは,ちょっとまったくわかりませんが,アイデアとしてはありだと思います.中間言語の再現は,文法誤り訂正の新たなフロンティア(たぶん)であり,今後の発展が期待されます.これからがほんとうの地獄だ.
英語
| CoNLL 14 (test) | P | R | F 0.5 |
|---|---|---|---|
| シングル | 52.77 | 36.31 | 48.38 |
| アンサンブル | 55.07 | 36.10 | 49.83 |
| + R2L | 56.72 | 34.88 | 50.41 |
| + MLM | 60.94 | 39.80 | 55.09 |
Falko Merlin + WI&LOCNESS + FCE + IWSLT + Tatoebaでやってみて,CoNLL 14(英語文法誤り訂正評価データセット)で評価したところ,あんまり良いスコアではありませんでした.Lang-8とかも入れたら話は別かもしれませんが,気力がわきませんでした.実験してたのが夏だったので,暑かったからかもしれません.
実装
実験に用いたすべてのソースコードを公開しています.
github:nymwa/korrektur-arbeitsplatz: 前処理・学習・評価を実行するスクリプトやconfigurationなど
github:nymwa/korrektur-auxt: 学習や評価を行う実際のスクリプトを生成するコード
github:nymwa/korrektur-werkzeug: 学習や評価の際に呼び出されるutility
github:nymwa/korrektur-reguligilo: 文字の正規化を行うライブラリ
github:nymwa/korrektur-pyspm: sentencepieceのラッパー.BPE-Dropoutを実行する際に使う
さいごに
ドイツ語文法誤り訂正は初めてやったのですが,たのしいですね.もっといろんな言語の文法誤り訂正をやってみたい気持ちがあります.ドイツ語ということなので,名詞の性などがちゃんと訂正できているかとか,人工的にデータを作って評価してあげることもできそうです.言語ごとの特性を活かした評価なんかもやってみたいですね.
それはそうと,既存のデータ拡張の研究では逆翻訳がすごく流行っているわけなんですが,逆翻訳だとどうしても,誤り生成モデルを作ってあげるための学習者コーパスがある程度十分にないといけないし,あったとしても,生成される誤りの種類というのも,学習者コーパスの中に出てくるものに限定されてしまって,そこが限界になってしまうんじゃないかなという気持ちになります.誤りが訂正される過程を逆にたどることと,誤りが生成される過程をたどることは,言語における誤り訂正や,それに類する校正や添削等において,その人類的知的営為を支える両輪となっているのかもしれず,どちらかだけに踏み込むだけでは不十分なのかもしれません.
ドイツ語学習者は,英語母語話者でない人も英語も学んでいることが多いと考えられます.そのうえ,英語とドイツ語は同じ西ゲルマン語群で,語や文法の見た目がなんとなく似ているところも多く,英語が母語でない学習者であっても,英語からの転移が多く起きると考えられます.そのため,英語・ドイツ語というのは,この転移という現象を文法誤り訂正で扱うのに最も適している言語対かもしれません.文法誤り訂正では,ロシア語・ウクライナ語・チェコ語など,スラブ語派の言語での評価データセットが多く,こちらも,同様に良い対象となるかもしれません.
ニューラルネットを用いた手法が用いられるようになったことで,文法誤り訂正が実応用に適用できるようになってきたということもあり,今後,実際に使われることを想定して,より第二言語習得研究の知見を取り入れていく必要があるのではないかとも思いました.これは,この分野の社会的意義の中でも最も大きなものだと思うし,さらに,実応用上便利な技術であるのならば,文法誤り訂正側が第二言語習得分野に影響を与えるようにもなってくるかもしれません(自分が知らないだけでもうそうなってるのかもしれませんが...).なんか,夢がありますね.とにかく,そういう問題意識について考えることができて,こういう形ではあってもなんらかの問題提起のようなことができたというのはとてもよかったなと思っています.
ありがとうございました