昨日の@hcpmiyukiさんの記事では、Supabaseという今あついBaaSについて書いてくれました!
MYJLab Advent Calendar 2021の3日目はGPT-3に関してです
論文を要約してAPIで遊びます
GPT-3とは
イーロン・マスク氏が共同会長を務める非営利のAI研究企業であるOpenAIが発表した、汎用言語モデルの3世代目です
ネット上のテキストの次の単語を予測するためだけに訓練されたTransformerベースの自己回帰言語モデルで、なんと1750億個のパラメータで動作するそうです
あまりの精度の高さに以前話題沸騰でした
This is mind blowing.
— Sharif Shameem (@sharifshameem) July 13, 2020
With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
W H A T pic.twitter.com/w8JkrZO4lk
以下サイトで紹介されているものもGPT-3が使われています
去年の9月にMicrosoftがOpenAIからライセンスを取得しています
論文要約
2020年に公開された以下論文をざっくりと要約します
いつか読みたいなと思っていたのですが、量が多いので、いつかいつかと先延ばしになっていました
このアドベントカレンダーを機に
1 Introduction
ファインチューニングが近年のトレンドだった(BERTやRoBERTaなど)
ただ、ファインチューニングには以下のようなデメリットがある
- 新しいタスクのたびに、タスクに特化したラベル付きのデータセットとタスクに特化した微調整が必要になる
- 大量のラベル付きデータを収集することが難しいタスクもある
ラベル付きの教師データがなくても、人間みたいに妥協できる範囲内で新しいタスクを実行できるようになりたい
上記デメリットを解決するアプローチの1つがメタ学習
- 教師なしの事前学習
- 1つのシーケンスの中に、繰り返されるサブタスクが含まれている場合があることを示している
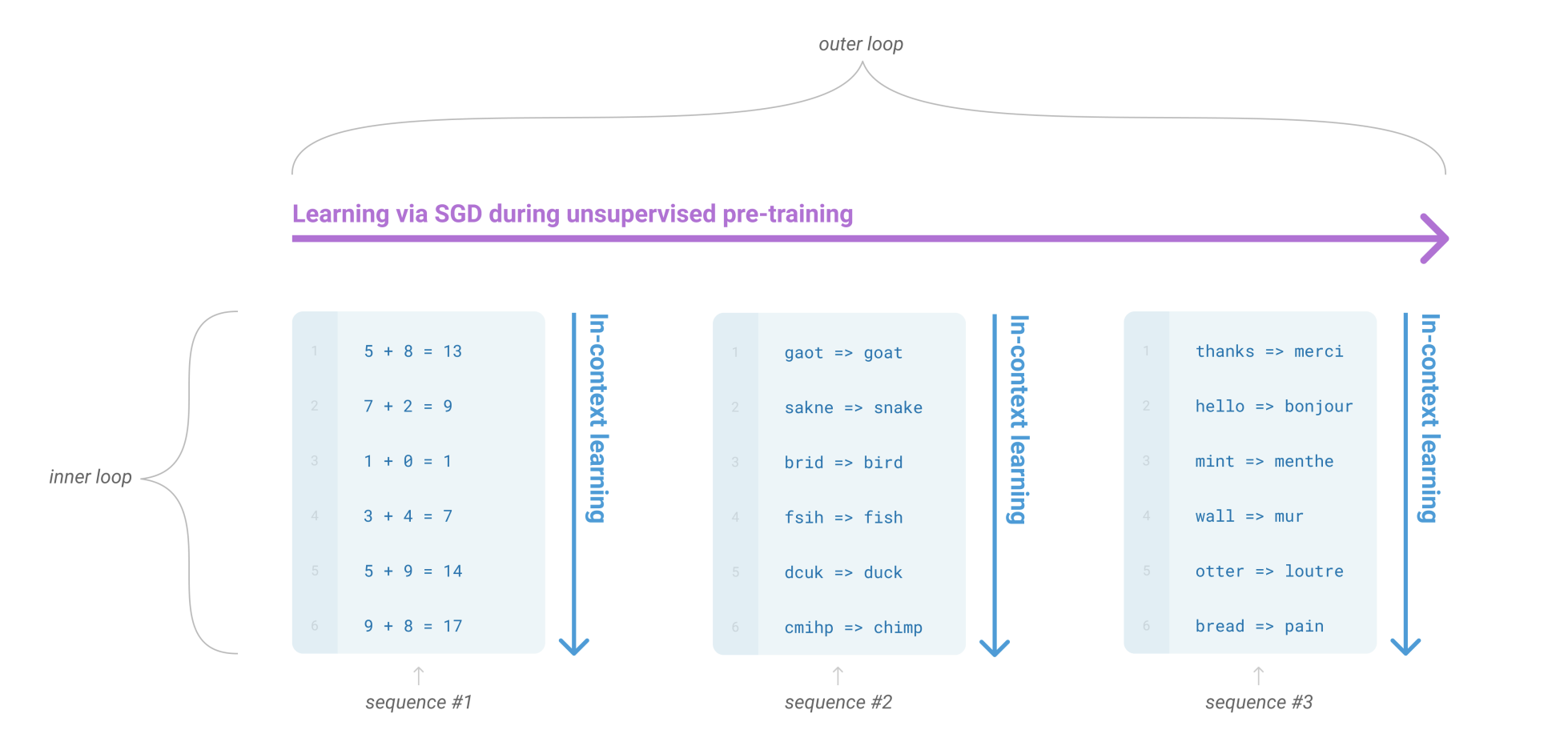
- 内包される様々な言語タスクへの処理能力の獲得が期待できる(in-context learning)
しかし、メタ学習は、実用的な活用にはまだ改善が必要
そこで近年、億単位のパラーメータにして言語モデルを大きくするのが流行ってることに着目(スケーリング則)
こいつはどうやら、文章生成能力や下流タスクの処理能力も向上することが報告されているらしい
→大幅にパラメータ数を増やした自己回帰言語モデルであるGPT-3を学習することで、スケーリング則とin-context learningの性能を検証する
2 Approach
事前学習モデルを利用するアプローチ
Fine-tuning
- 近年の最も一般的な手法
- 事前に学習したモデルの重みを更新する
- 多くのベンチマークで強力なパフォーマンスを発揮してる
- 欠点は、タスクごとに新しい大規模なデータセットが必要なこと、一般化がうまくいかない可能性があること
Few-shot
- タスクに関する説明と少量のタスクの例を与える
One-shot
- few-shotにおいてタスクの例を1つ与える
Zero-shot
- タスクに関する説明のみ与え、タスクの例は与えない

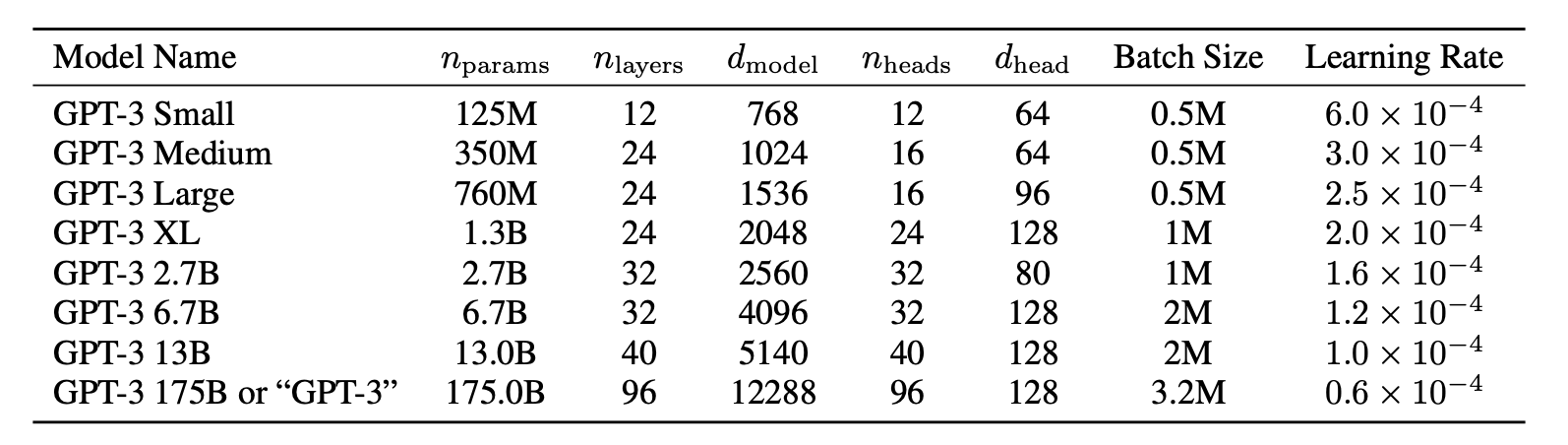
モデルのアーキテクチャ
-
GPT-2と基本は同じモデル
- ベースはTransformer
- Sparse Transformerのように局所的なAttentionパターンを使用
- 自己回帰による学習
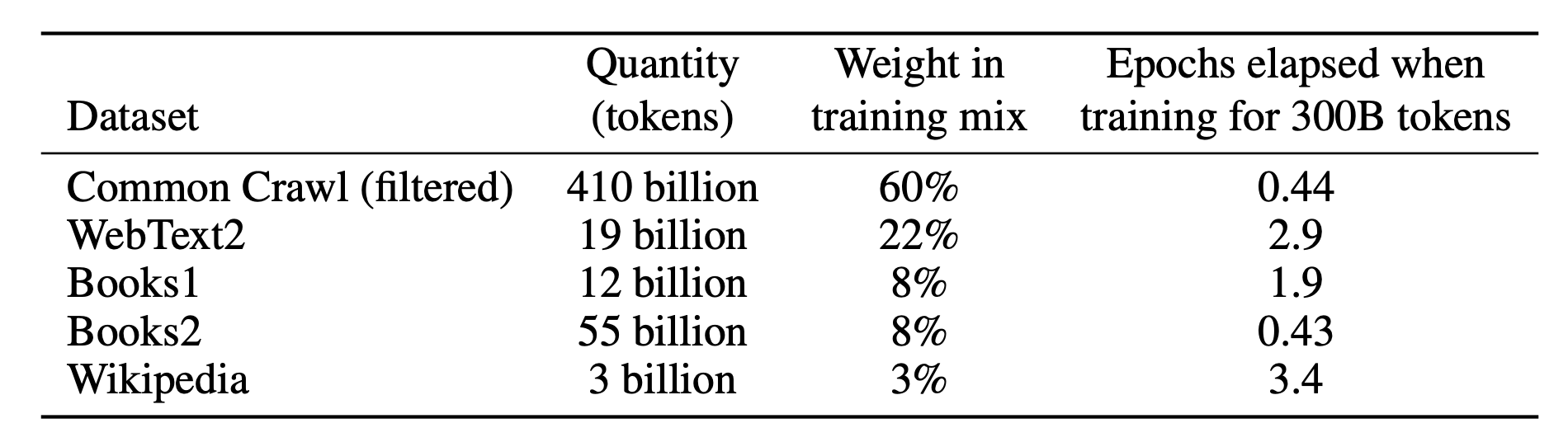
データセット
- Common Crawlのデータセットを使う
- 単語数は約1兆個も
- Common Crawlのデータセットは質が低いものがあるので、質の高いデータセットと、類似度によってフィルタリングするなどして対応する
3 Results
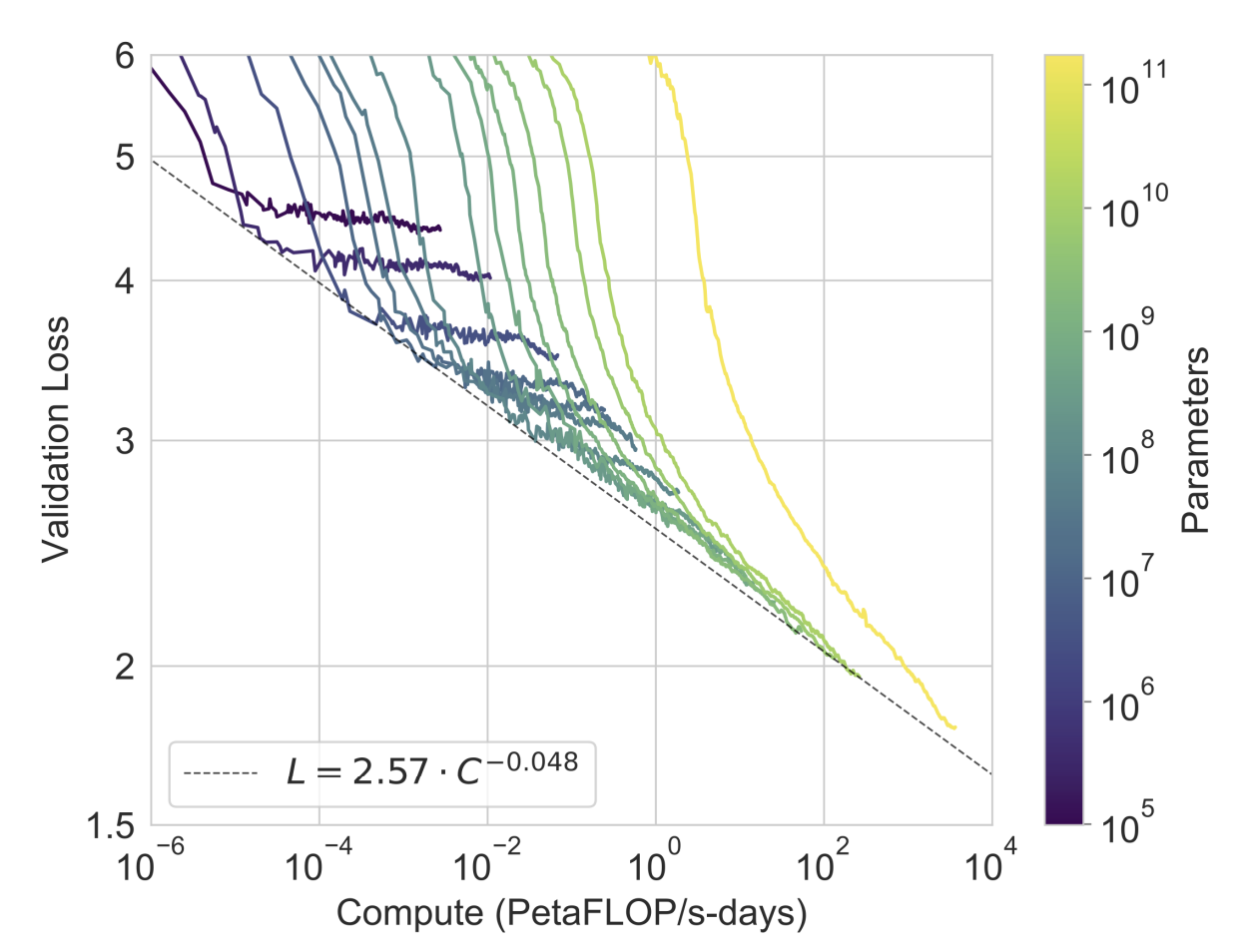
モデルサイズと計算量に対するパフォーマンス
- 言語モデリングの性能はべき乗に従うと報告されている
- 上の表の8つのモデルに、10万パラメータの6つの小さな(!?)モデルも追加して確認する
- 黄色の線が175BのGPT-3のLoss(まだまだいける)
※PetaFLOP/s-days : 1秒間に1ペタ(10の15乗)回のニューラルネット上の演算操作を、1日分行った計算量
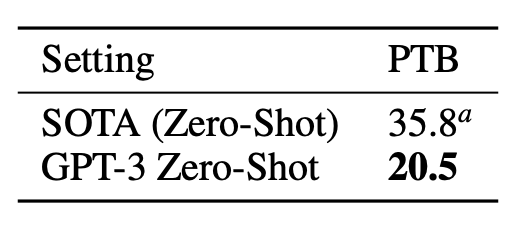
言語モデル
- PTBデータセットを使用する
- SoTA、GPT–3ともに、Zero-Shotでの結果を出す
- ちなみにPTBデータセットでは学習してない
- perplexityで確認する
- SoTAから15.3ポイントも差をつけて改善
Q&A
以下3つのデータセットで確認
- NaturalQS
- WebQS
- TriviaQA
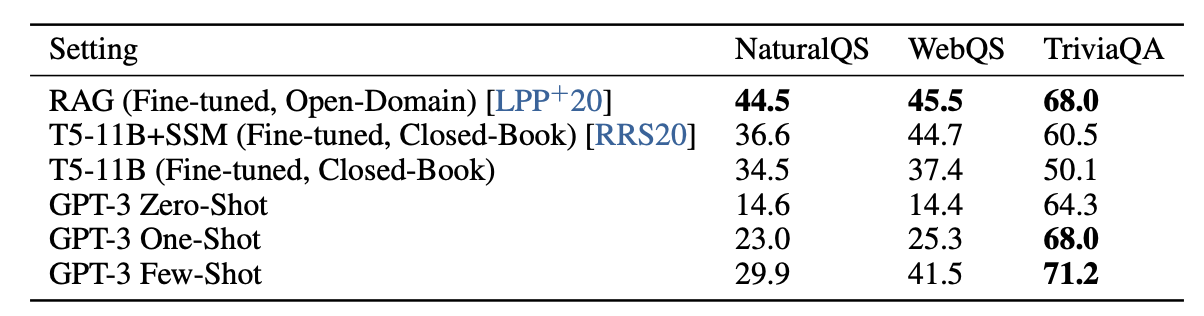
その中でもTriviaQAに関しては、GPT-3のFew-shotがSOTAを達成
翻訳
BLUEスコア
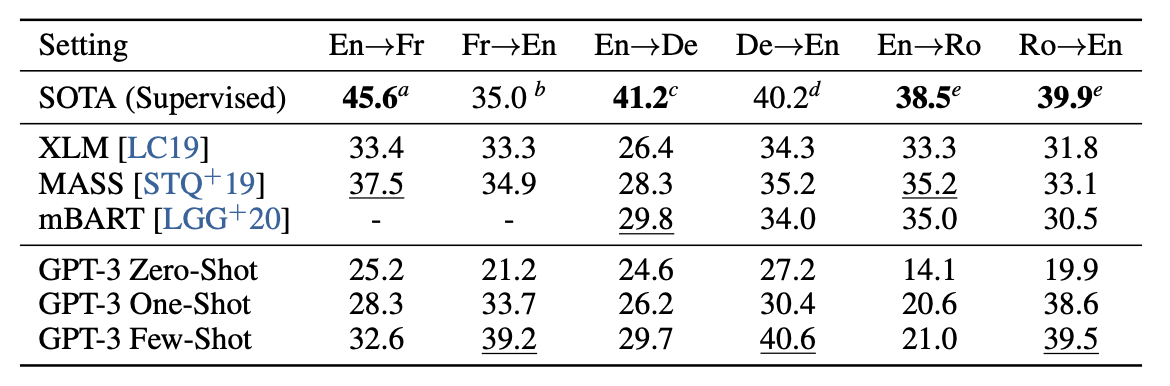
フランス語から英語、ドイツ語から英語に関してはSoTAを達成
上記以外にも、非常に多くのタスクで高い性能を発揮
4 Measuring and Preventing Memorization Of Benchmarks
- インターネットから供給されたデータセットなので、ベンチマークのテストセットを一部で学習しちゃってる可能性がある
- インターネット規模のデータセットからのテストの汚染を正確に検出することは、新しい研究分野であり、確立されたベストプラクティスは存在しない
(汚染を調査せずに大規模なモデルを訓練することは一般的に行われているが、事前訓練用データセットの規模が大きくなっていることを考えると、この問題に取り組むことはますます重要になってる)
5 Limitations
GPT-3の限界について
- 文書レベルで意味的な繰り返しがあったり、十分な長さの文章でまとまりがなくなったり、矛盾が生じたり、時折、連続しない文章や段落が含まれていたりする、などなど
6 Broader Impacts
社会に与える悪いインパクトに関して
- GPT-3の誤用、公平性、エネルギー使用など
- 生成される文章に偏見を含む可能性がある
- 上記に関して分析
- 性別、人種、宗教に関連するバイアスを特定するなど
- 偏見を緩和する規範的、技術的、実証的な課題を結びつける共通の用語体系が必要
7 Related Work
関連研究
- ここ数年の自然言語処理のトレンドは,データサイズ・モデルサイズ・訓練時間を同時に上げてパフォーマンスを改善すること
- LSTMベースの言語モデルのパラメータ数を10億以上に増やしたもの など
8 Conclusion
- タスクに特化した教師データによる学習が不要になる
- 非常に大きなモデルを非常に大きなコーパスで学習することで、より汎用的なモデルを構築できた
すごい
特定のタスクに特化した学習をせずに事前学習のみで、めちゃ多くのタスクで高い性能を出しまっくってるっていう、本当にただただすごいしか出てこない
APIで遊ぶ
日本語版のAPIで諸々試していきます
1. 登録
まず、OpenAIのベータ版サイトで利用申請をします
少し待って、申請が認証されてwelcomeメールが届いたら、登録完了です
最初の3ヶ月間に利用できる$18の無料クレジットが提供されるので、この範囲内で遊びます
(1.5 おまけ サイト上で試してみる)
Playgroundに移動して
試しに、「お腹すいた」と入力して
※Few-shotで試すべきなんだろうけど後で試すので、あえてお腹すいたで
左下のGenerateボタンを押してみると...
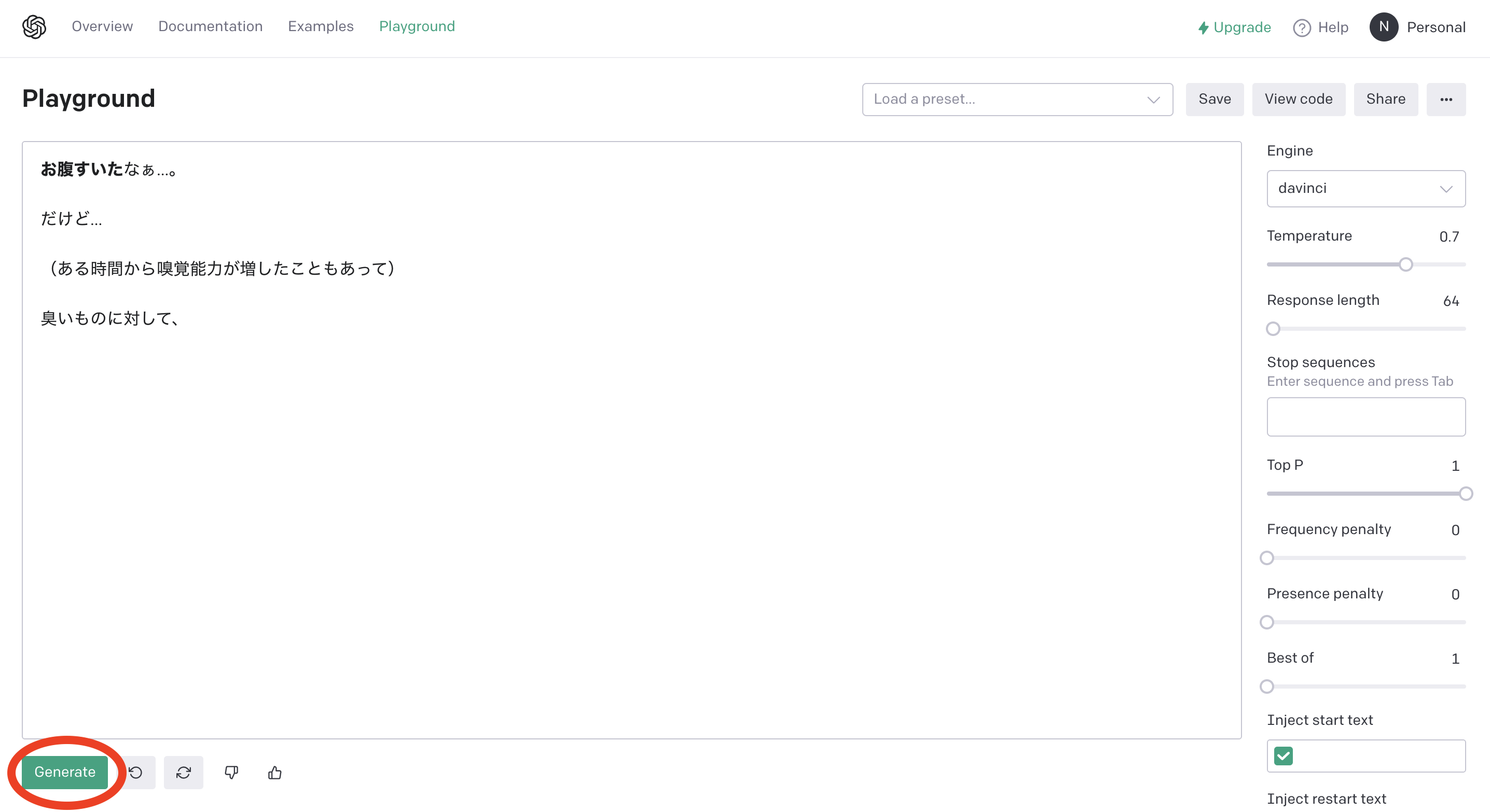
文章が!
Generateボタンを押していくと、どんどん続きを書いてくれる
すごい楽しい
Playgroundでも十分色々なタスクを試せます
2. APIキーを取得
右上から確認できます
3. pip install
$ pip install openai
4. 実行
import openai
openai.api_key = "APIキー"
APIキーを設定したら、以下色々試していきます
チャット
start_sequence = "\nAI:"
restart_sequence = "\n私: "
prompt = '''チャットボットです。
私: こんにちは、調子はどう?
AI: 元気です
私: 最近何してるの?
AI:'''
response = openai.Completion.create(
engine='davinci',
prompt=prompt,
max_tokens=30,
stop="\n")
print(prompt+response['choices'][0]['text'])
結果
チャットボットです。
私: こんにちは、調子はどう?
AI: 元気です。
私: 最近何してるの?
AI: 調子がいいから、努力して何かしはじめました。
Q&A
start_sequence = "\nA:"
restart_sequence = "\nQ: "
prompt = '''私は真実を答える賢い質問応答ボットです。
Q: 日本の人口は?
A: 約1億人です。
Q: 世界で一番人口が多い国は?
A: '''
response = openai.Completion.create(
engine='davinci',
prompt=prompt,
max_tokens=100,
stop="\n")
print(prompt+response['choices'][0]['text'])
結果
私は真実を答える賢い質問応答ボットです。
Q: 日本の人口は?
A: 約1億人です。
Q: 世界で一番人口が多い国は?
A: 南アフリカです。
翻訳
start_sequence = "\nJapanese:"
restart_sequence = "\nEnglish: "
prompt = '''日本語を英語に翻訳します。
English: I am a student.
Japanese: 私は学生です。
English: I do not speak Japanese.
Japanese:私は日本語を話しません。
English: I love him very much.
Japanese: '''
response = openai.Completion.create(
engine='davinci',
prompt=prompt,
max_tokens=100,
stop="\n")
print(prompt+response['choices'][0]['text'])
結果
日本語を英語に翻訳します。
English: I am a student.
Japanese: 私は学生です。
English: I do not speak Japanese.
Japanese:私は日本語を話しません。
English: I love him very much.
Japanese: 私は彼をとても愛しています。
映画を絵文字で表現
prompt = '''
Back to Future: 👨👴🚗🕒
Batman: 🤵🦇
Transformers: 🚗🤖
Wonder Woman: 👸🏻👸🏼👸🏽👸🏾👸🏿
Winnie the Pooh: 🐻🐼🐻
The Godfather: 👨👩👧🕵🏻♂️👲💥
Game of Thrones: 🏹🗡🗡🏹
Spider-Man:'''
response = openai.Completion.create(
engine='davinci',
prompt=prompt,
temperature=0.8,
max_tokens=100,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop="\n")
print(prompt+response['choices'][0]['text'])
結果
Back to Future: 👨👴🚗🕒
Batman: 🤵🦇
Transformers: 🚗🤖
Wonder Woman: 👸🏻👸🏼👸🏽👸🏾👸🏿
Winnie the Pooh: 🐻🐼🐻
The Godfather: 👨👩👧🕵🏻♂️👲💥
Game of Thrones: 🏹🗡🗡🏹
Spider-Man: 🕷👪
キーワードの提示
start_sequence = "\nテキスト:"
restart_sequence = "\nキーワード: "
prompt = '''
テキスト: 宮治研究室(宮治ゼミ)
本研究室では,ネットやウェブなどに加えて,センサやカメラなどによって収集した実世界の情報を融合することによって,社会や生活の役に立つサービスを創出することを目的としています.
その実現の為には,「データ採取」「データ分析」「情報提示」「通信・連携」の 4 領域の技術が必要となります.
キーワード:'''
response = openai.Completion.create(
engine='davinci',
prompt=prompt,
max_tokens=100,
stop="\n")
print(prompt+response['choices'][0]['text'])
結果
テキスト: 宮治研究室(宮治ゼミ)
本研究室では,ネットやウェブなどに加えて,センサやカメラなどによって収集した実世界の情報を融合することによって,社会や生活の役に立つサービスを創出することを目的としています.
その実現の為には,「データ採取」「データ分析」「情報提示」「通信・連携」の 4 領域の技術が必要となります.
キーワード: リモートセンシング, IC ラップ, レーザコンピューティング, センサ, カメラ, インタラクション, カラーチャネル, ウェブモデル, 交流, GPS, 位置情報, 実世界情報
CSSのカラーコードの提案
prompt = '''
明るくて綺麗な空の色みたいな青のカラーコード:
background-color: #'''
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
temperature=0,
max_tokens=64,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=";"
)
print(prompt+response['choices'][0]['text'])
結果
明るくて綺麗な空の色みたいな青のカラーコード:
background-color: #00b2ff
おわり
時々失敗することはあれど、かなりの汎用性の高さと自然な日本語にびっくりしました
このレベル感でタスクに特化した学習をしてないっていうのが本当にすごいです、、
簡単に試せて楽しかったです
上記で試したもの以外にも色々あります(感情分析、キャッチコピージェネレータ、難しい文章を優しい文章に要約、住所の抽出、Pythonを自然言語で解説、自然言語からSQLを作成、JavaScriptをPythonに変換、などなど...)
参考文献