はじめに
Pandasのデータの探索と操作に関しての備忘録です。
コードを書き始めて1年以内の若輩者です😅
もし間違いがあれば、ご指摘いただけると助かります🙇
🦁結論🦁
データを選択できる操作を理解して取得方法を理解することでデータフレームの扱いの基本が学べる。
.loc[], .iloc[]: 行列の選択
.items(): カラム名とデータをペアとして取得
.values: データフレームの値のみを取得(numpy形式)
ブールインデックスで抽出に条件をつけて取得
この4つを理解する。
DataFrameの基本操作
- df['列名']で列の選択にて選択するのが基本。
- df[['列名1', '列名2']]にて列名1と列名2を選択。
- この形では列名1から列名5までを選択することはできない。(.loc[]を使う)
注意点
- items()を使って列を反復処理する順序が重要な場合は、データフレームの列の順序を事前に確認しておく必要がある。
メソッド一覧
.loc[]
DataFrameやSeriesのラベルに基づいてデータを選択できる。
スライスを使用して範囲選択が可能。
論理値のリストを使って条件に基づく選択が可能。
行と列の両方を指定してデータを選択できる。
.loc[]の基本の型
df.loc['index', '列名']
1行目から5行目までの中の金額の列を選択。
df.loc[0:4, '金額']
金額の列を選択。
※基本使わない→df['金額'] これで書くことが多い。
df.loc[ :, '金額']
.iloc[]
print(df.iloc[0]) # 最初の行を選択
print(df.iloc[:, 0]) # 最初の列を選択
.items()
column+列の全てのデータをペアで取得できる。
全ての列に対して繰り返し処理を加えたりできる。
columnごとに処理を行える。
columnの順序はデータフレームの順序に依存する。
for label, content in df.items():
print(f"Label: {label}")
print(f"Content:\n{content}\n")
.values
データフレームの値をNumpy配列として取得する。
列名やインデックスなしでデータにアクセス可能。
大規模なデータセットの操作に適している。
values = df.values
print(values)
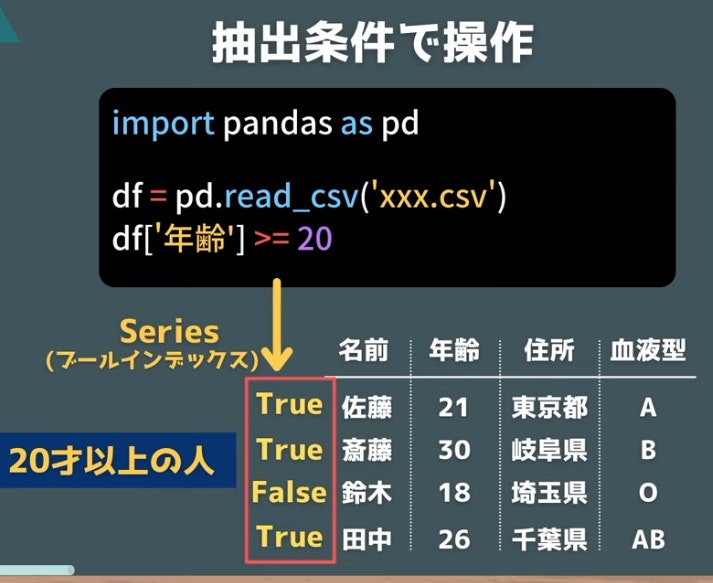
ブールインデックス
ブールインデックスとは「真偽値で表すindex」
index部分にそのソートしたい内容のtrueか falseで示されたindexを発行してソートすることができる(indexに上塗りなどはしない)
columnを指定して、データをソートして絞り込める。
例)年齢のcolumnから20歳以上に絞り込んでデータを取得する
df = pd.read_csv('xxx.csv')
df[df['年齢'] >= 20]
and条件→ &
20歳以上 かつ A型以外の方のデータを抽出
df[(df['年齢'] >= 20) & (df['血液型'] != 'A')]
or条件→ |
20歳以上 または B型の人を抽出
df[(df['年齢'] >= 20) | (df['血液型'] == 'B')]
まとめ✍️
事前準備は重要だなと再認識。
データがあってるかあってないか?それが漏れただけで、やり直しは時間の無駄になる。
参考にした記事📕
[【Pythonプログラミング】Pandasの基本~表形式データ・データ分析~初心者向けのDataFrameの操作入門!](https://youtu.be/HYWQbAdsG6s?si=WRW_Ld81eWhSVSSP)
ブールインデックス