Fivetranは、様々なデータソース(各種SaaSアプリやDBなど)から、クラウド型DWHを中心としたデータ分析基盤へ、データ同期を自動化させることができるツールです。
最短5分のセットアップでデータパイプラインを構築することができ、それ以降のデータ同期を自動してくれるとのこと。
今回は、このFivetranを使用して(RDS)PostgreSQLから(AWS)Databricksへのパイプラインを構築し、データ同期を行ってみました。
全体の流れ
- 同期先((AWS)Databricks)を登録します
- データソース((RDS)PostgreSQL)のコネクターを作成します ※この記事です
- データの増分同期を確認します
コネクター((RDS)PostgreSQL)を作成します
同期元のデータソースとの連携を設定し『Connector(コネクター)』を作成していきます。
(RDS)PostgreSQLの接続方法については選択肢となるポイントが2つありました。
①接続方法

②増分同期メカニズム

今回は最もシンプルかつ推奨のパターンで試してみたいので、
- 直接接続する
- pgoutputプラグインによる論理レプリケーション
で進めます。
メニューから『Connectors』を選択し、Connectors画面へ遷移します。
右上の「Add connector」ボタンから、設定を行っていきます。

前の手順で作成したDestinationを選択。

データソースのタイプは Postgres RDS を選択。

セットアップ入力画面まで遷移してきました。
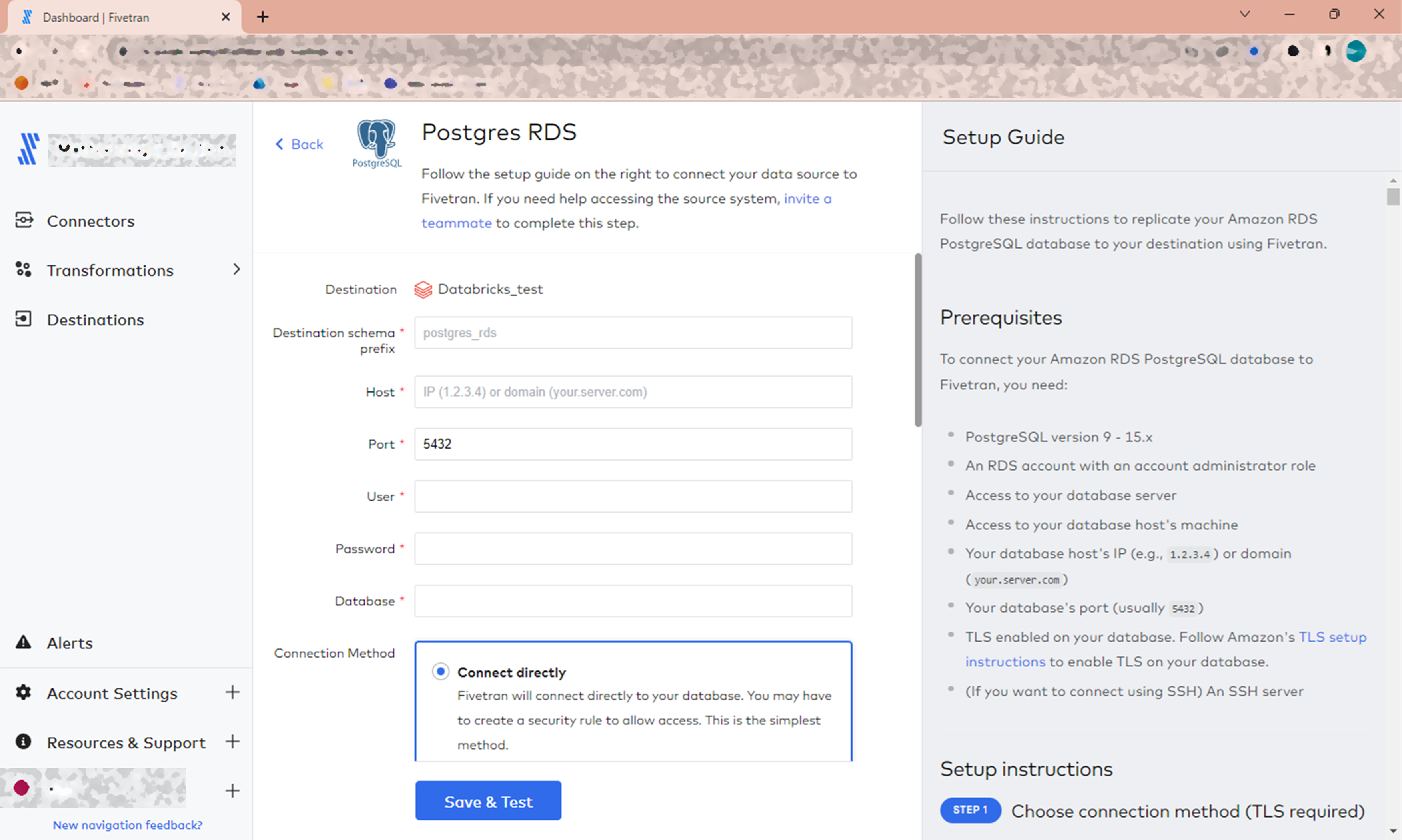
今回はデータベースの論理レプリケーションを有効化していく手順が入るため、少し長くなります。
先におおまかな流れを確認しておきます。
- データベースのアクセス制御設定見直し
- Fivetran専用のデータベースユーザー作成、権限設定
- 論理レプリケーションの有効化を実施
- レプリケーション用のオブジェクトを作成していく
- セットアップ入力画面に必要な内容を入力し、接続開始!
一つずつ進めていきます。
1. データベースのアクセス制御設定見直し
基本的にデータベースにはアクセス制御が行われていると思いますので、Fivetranによるアクセスが許可されるよう設定を変更してあげる必要があります。
今回はテスト用に作成したデータベースを使用するため割愛しますが、既存のアクセス制御が行われているRDSに接続する場合は
- セキュリティグループ
- (インスタンスがVPC内にある場合)ネットワークACL
の設定見直しが必要です。
2. Fivetran専用のデータベースユーザー作成、権限設定
まずはデータベースにアクセスしてFivetran専用のユーザーを作成します。
※ユーザー名/パスワードは任意のものを設定します
CREATE USER fivetran PASSWORD 'fivetran';
次に同期対象テーブルへの読み取り権限を付与します。
今回テスト用DBは次のように作成してみました。
全てのテーブルを同期対象とする方針とします。

スキーマごとに、以下3つの権限付与を行うコマンドを実行していきます
- スキーマへのアクセス権限付与
- スキーマ内のテーブルの参照権限付与
- スキーマ内に今後作成されるすべてのテーブルに対して、デフォルトで参照権限を付与するよう設定
-- public は PostgreSQL のデフォルトスキーマ
GRANT USAGE ON SCHEMA "public" TO fivetran;
GRANT SELECT ON ALL TABLES IN SCHEMA "public" TO fivetran;
ALTER DEFAULT PRIVILEGES IN SCHEMA "public" GRANT SELECT ON TABLES TO fivetran;
-- 複数のスキーマを対象とする場合は、同じように繰り返し権限付与
GRANT USAGE ON SCHEMA "testschema" TO fivetran;
GRANT SELECT ON ALL TABLES IN SCHEMA "testschema" TO fivetran;
ALTER DEFAULT PRIVILEGES IN SCHEMA "testschema" GRANT SELECT ON TABLES TO fivetran;
3. 論理レプリケーションの有効化を実施
AWSマネジメントコンソールにアクセスし、対象のデータベースに論理レプリケーションの有効化を行っていきます。
必要なのは下記のパラメーター設定です。
- rds.logical_replication : 1
- wal_sender_timeout : 0
今回は新規に"postgres-logical-replication"というパラメーターグループを作成し、適用させる手順にしました。
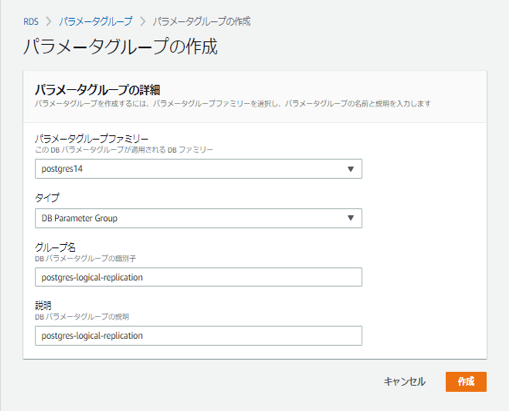
rds.logical_replication : 1 に設定。
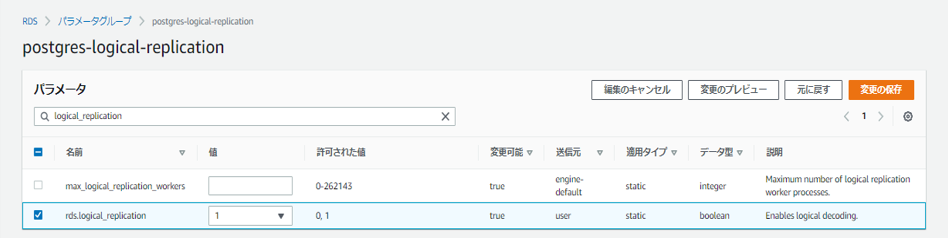
wal_sender_timeout : 0 に設定。

対象のDBインスタンスを選択して、パラメータグループの変更を行います。
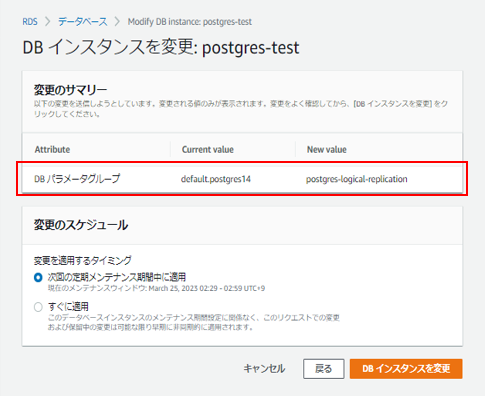

変更を反映するためにはDBを再起動する必要があります。
パラメーターグループのステータスが『再起動を保留中』になったら再起動を行います。
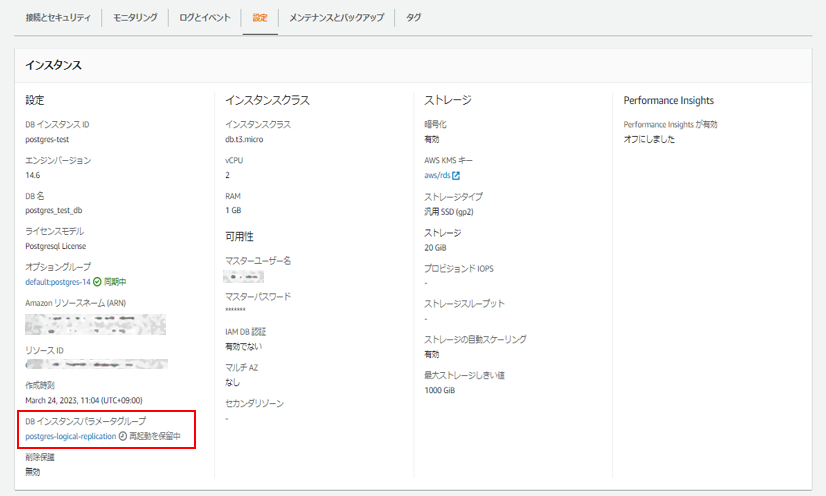
再起動後。

4. レプリケーション用のオブジェクトを作成していく
まず、テーブルのパブリケーションを作成します。
ALL TABLEを指定してパブリケーションを作成する方法もありますが、今回は後から対象の追加/削除ができるよう、個別にテーブルを指定してパブリケーションを作成していきます。
-- 2テーブル指定して作成(publicスキーマ以外のテーブルはスキーマ名から)
CREATE PUBLICATION test_fivetran_pub FOR TABLE item, testschema.tbl_a;
次に、論理レプリケーションスロットを作成します。
-- 'test_fivetran_pgoutput_slot'が論理レプリケーションスロット名
SELECT pg_create_logical_replication_slot('test_fivetran_pgoutput_slot', 'pgoutput');
パブリケーションが正しく作成されていることを確認します。
SELECT * FROM pg_publication_tables;

作成が完了したので、レプリケーションスロットを読み取る権限をFivetranユーザーに付与します。
GRANT rds_replication TO fivetran;
正しくアクセス許可が設定されたことを確認します。
Fivetranユーザーでログインして下記を実行し、クエリが成功すればOKです。
-- パブリケーション名と論理レプリケーションスロット名を指定します
SELECT count(*) FROM pg_logical_slot_peek_binary_changes('test_fivetran_pgoutput_slot', null, null, 'proto_version', '1', 'publication_names', 'test_fivetran_pub');

パブリケーションに指定したテーブルは、「レプリカアイデンティティ」の設定をしなければ、その後UPDATE、DELETEの操作ができなくなってしまいます。
主キーがあればデフォルトでレプリカアイデンティティになりますが、主キーがないテーブルの場合はレプリカアイデンティティが設定されていないことになるそうです。
もしも同期対象に主キー無しのテーブルが含まれる場合、注意が必要そうです。
https://www.postgresql.jp/document/14/html/logical-replication-publication.html
5. セットアップ入力画面に必要な内容を入力し、接続開始!
以下の内容で入力し、接続を実行します。
- Destination schema prefix:
Databricks内に複製される際にプレフィックスとして付けられる文字列
自由に指定できますが、後から変更はできません
今回は"test_postgres"とします - Host:RDSエンドポイント
- Port:RDSポート
- User:作成したFivetran用のデータベースユーザー
- Password:↑のパスワード
- Database:対象のデータベース名 ※今回でいうと"mydb"(インスタンス名ではない)
- Connection Method:直接接続する(Connect directly) を選択
- Update Method:pgoutputプラグインによる論理レプリケーション(Logical Replication of the WAL using the pgoutput plugin) を選択
- Replication Slot:作成したレプリケーションスロット名
- Publication Name:作成したパブリケーション名

入力できたら「Save&Test」ボタンで接続します。
またFivetran側でいくつかテストが行われます。Destinationの時より項目が多そうです。
証明書の確認が要求されました。
今回特に何もしていないので、RDSのデフォルトのものが有効になっているはずです。
一番上を選択して進めることにします。
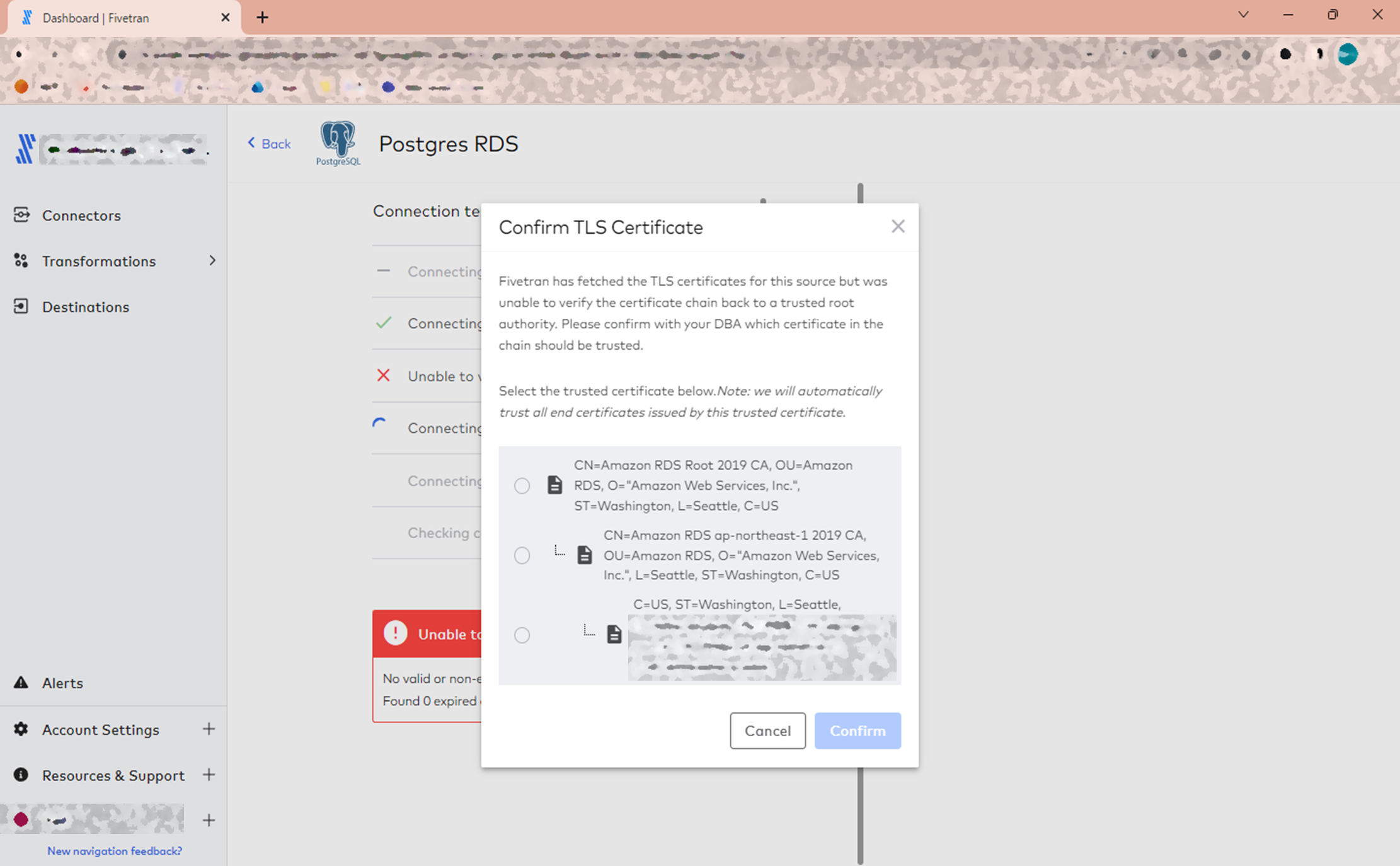
証明書を含む諸々のチェックは終了したようで、最後に下記の警告だけ表示されました。

wal_buffersの設定値がベストプラクティスに沿っていないとのこと。
今回は無視して進めますが、実際に導入する環境によっては設定値周りの検討も必要そうです。
「Continue」で続けます。
画面から同期対象にするスキーマ/テーブル/カラムを選択できます。
デフォルトは全て選択の状態です。

カラムを選択してハッシュ化することもできます。
デフォルトはハッシュ化なしです。

今回はデフォルトのままでいきます。
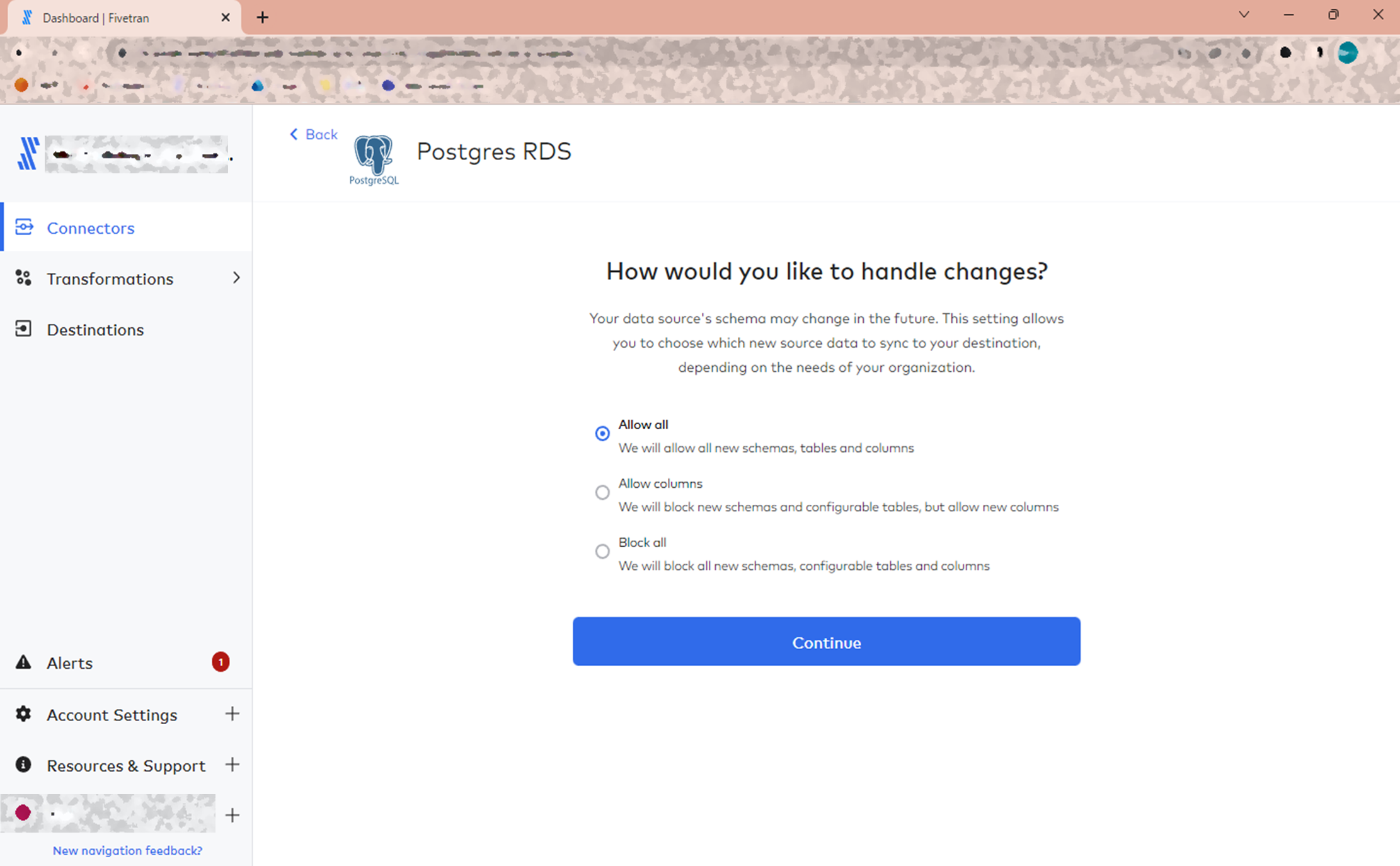
データソースのスキーマ変更を宛先に同期させるかを選択することができます。
デフォルトでは全ての変更を同期させる選択になっています。
こちらも今回はデフォルトのままでいきます。
接続が完了しました!

あとは「Start Initial Sync」を押すと初期同期が始まります。
初期同期!
それでは、初期同期を行ってみます。
同期中の画面。

終了。

初期同期が完了しました。今後は増分同期と呼ばれる同期がパイプラインによって自動で行われます。
上の画面からは、次回は3時間後に増分同期が実行されることが分かります。
結果確認!
最後に同期先であるDatabricksの方を見てみます。
カタログは特に指定しなかったためか、hive_metastoreに作られていました。
スキーマ名は、セットアップ画面で入力したプレフィックス+スキーマ名になっています。

中には同期したテーブルと、Fivetranが自動で作成する監査テーブル(fivetran_audit)が入っています。

中身のデータも同期されていました。

見比べてみると、いくつかのカラムが同期の際に自動で追加されていることが分かります。
- fivetran_synced :Fivetranが最後にその行の同期に成功した時刻
- fivetran_deleted :ソースデータベースで削除された行をマークする削除フラグ
- fivetran_id :Fivetranの内部ユニークID ※主キー無しテーブルに追加される
実は、今回確認に使用したテーブルは次のようなパターン分けを行っていました。

そのため、fivetran_synced と fivetran_deleted は両方のテーブルに追加され、testschema.tbl_a の方にはさらに fivetran_id が追加されたのです。
・・・以上。
少し長かったですが、コネクター作成が完了し、同期データの確認もできました。
以降のデータ同期(増分同期)は自動で行われます。
増分同期については、次でまとめます。
スキーマ変更が発生した場合の同期についても、確認していきます。
⇒ ③自動同期(増分同期) 編