この記事は Howtelevision Advent Calendar 2022の10日目の記事です。
日頃、分析から基盤構築まで行っている2年目のエンジニアです!
本日は、DBTの活用例について一部紹介したいと思います!
DBTとは?
DBT(Data Build Tool)は、ELTの"T"を担ってくれるツールでデータウェアハウスやデータレイクの構築、管理、および分析用のデータを効率的かつ一貫した方法で準備することができます。また、データを加工したり変換したりするための豊富な機能を提供しています。
DBTのメリットとしては、
- SQLのみで完結
- Git管理ができる
- jinja, macroを活用することでSQLだけでは表現できない処理も実行可能
があるでしょう。
DBTのインストールはこちらからできます!
今回はチュートリアルは省きますがデフォルトで用意されているsqlファイルを用います。
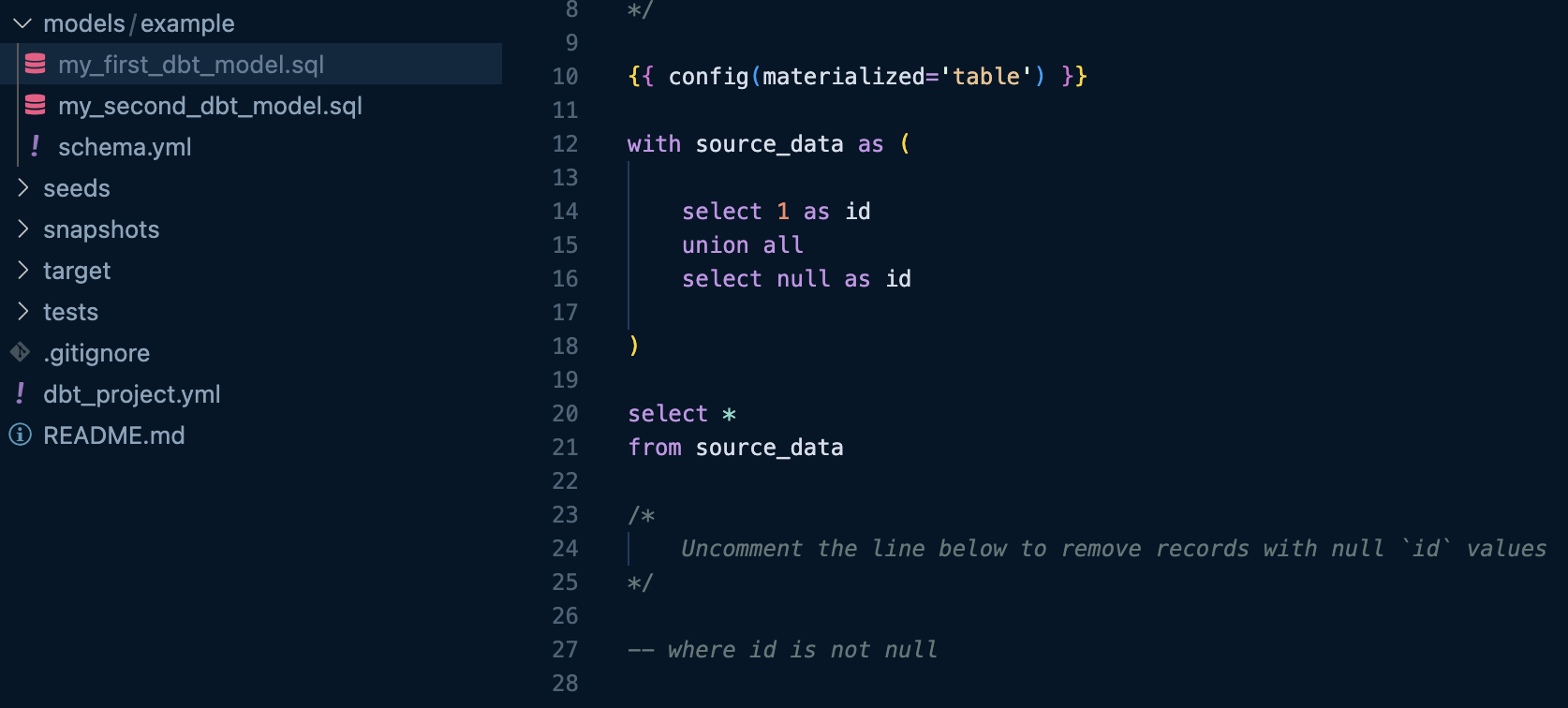
ここからは基本的な事を中心にカスタマイズを紹介しようと思います。
出力名をカスタマイズする
DBTでは、SQLのファイル名が出力先のテーブル名として保存されます。しかし、それぞれを別名にしたいと感じる事もあると思います。
そんな時は以下をmacrosディレクトリ下に作成します。
## get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name is none -%}
{{ node.name }}
{%- else -%}
{{ custom_alias_name | trim }}
{%- endif -%}
{%- endmacro %}
これを用いて, my_first_dbt_model.sqlを書き換えてみましょう。
{{ config(alias='first_model') }} -- configの部分でaliasを変更する。
with source_data as (
select 1 as id
union all
select null as id
)
select *
from source_data
これを実行すると指定した名前で保存されるのがわかります。
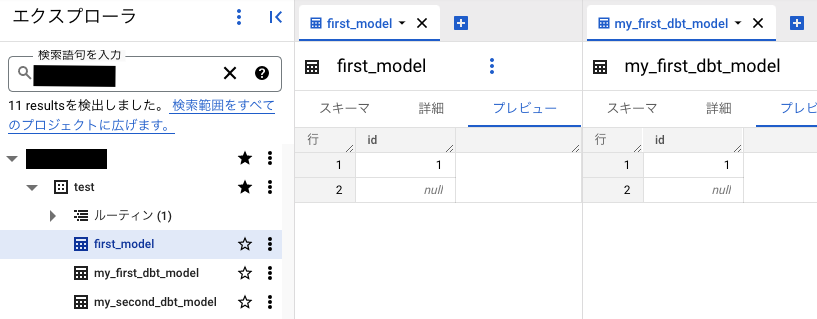
出力先を自由にカスタマイズする
デフォルトでは、profiles.ymlで設定したdatasetに実行結果が格納されます。
dbt_project.ymlで、
+database: projectID(BigQuery)
+schema: dataset(BigQuery)
を追加することでprojectとdatasetを指定することができます。
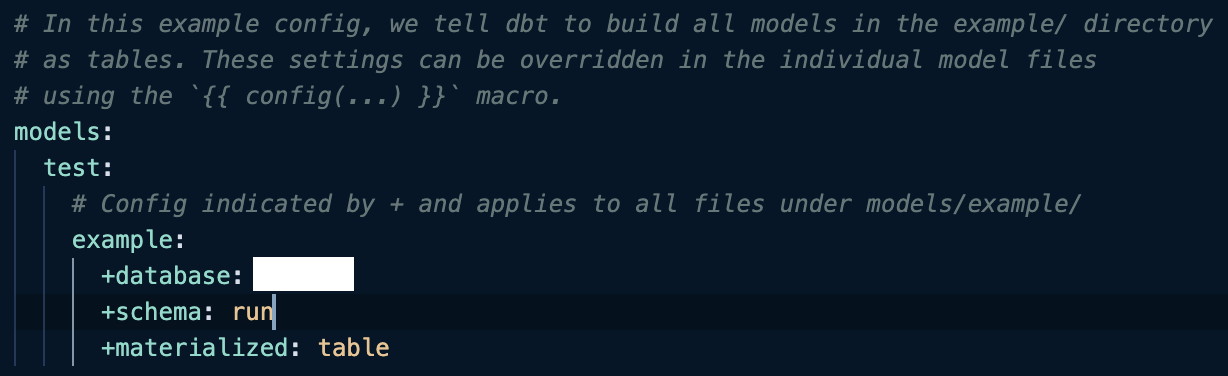
しかしこの状態で実行すると、デフォルトで指定したデータセットの語尾に指定した名前が追加される形で新しいデータセットが作成されてしまい、意図していたアウトプットにはなっていません。

これを解決するためには、
以下をmacrosディレクトリ下に作成します。
## get_custom_schema.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custome_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
改めて実行すると以下のようになります。

これで、思い通りのデータセットに出力させることができるようになりました。
プロジェクト名も同様で以下のファイルをmacros下に作成することでプロジェクトを横断してデータを出力させることができます!
## get_custom_database.sql
{% macro generate_database_name(custom_database_name=none, node=none) -%}
{%- set default_database = target.database -%}
{%- if custom_database_name is none -%}
{{ default_database }}
{%- else -%}
{{ custom_database_name | trim }}
{%- endif -%}
{%- endmacro %}
出力したテーブルにメタ情報を追加する
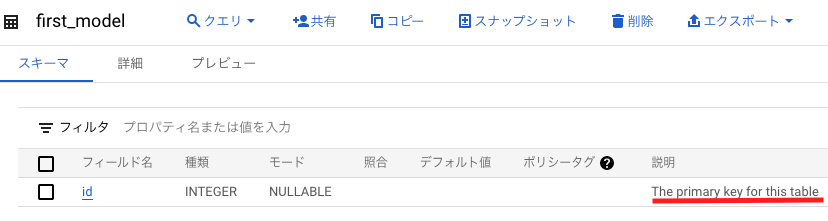
model下にあるschema.ymlは、出力データのメタ情報を管理するファイルです。ここでデータの型やテーブルの説明、カラムの説明...etcをまとめることができるのですが、デフォルトでは説明が出力先のテーブルに反映されることはありません。
DBT内だけでなく、データウェアハウス側でもメタ情報が反映されると便利ですよね。
改善するのは簡単で以下のコードをdbt_project.ymlに追加することで反映されます。
# In this example config, we tell dbt to build all models in the example/ directory
# as tables. These settings can be overridden in the individual model files
# using the `{{ config(...) }}` macro.
models:
# モデルの各schema.ymlのdescriptionをBigQueryに反映させる。
+persist_docs:
relation: true
columns: true
test:
# Config indicated by + and applies to all files under models/example/
これによってデータウェアハウス側にも反映されるようになります。
以上です。
今回は、基本的な細かな機能をまとめさせていただきました。
参照
- https://docs.getdbt.com/docs/build/custom-aliases
- https://docs.getdbt.com/docs/build/custom-schemas
- https://docs.getdbt.com/docs/build/custom-databases
- https://docs.getdbt.com/reference/resource-configs/persist_docs
最後に
ハウテレビジョンの開発部ではチームのプロダクト生産性を日々高めております。 ぜひ一緒に取り組んでくれるエンジニアの方、募集しております!