QuestDBは、高スループットの取り込みと高速SQLクエリを実現するオープンソースの時系列データベースという事らしく、influxDBよりも高速に動作するという話なので両者の性能差を比較してみたいと思います。
前提
仮想マシンスペック: 8vCPU / 8GB_MEM
OS:Ubuntu 22.04.1 LTS
java: openjdk-11-jdk
Maven: 3.9.8
1. 必要packageのインストール
apt install openjdk-11-jdk git
wget https://dlcdn.apache.org/maven/maven-3/3.9.8/binaries/apache-maven-3.9.8-bin.tar.gz
tar zxvf apache-maven-3.9.8-bin.tar.gz
mv apache-maven-3.9.8 /opt/maven
JAVA_HOMEを設定していないとビルド時に失敗しますのであらかじめ設定しておきます。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
詳しくは下記公式サイトをご確認ください。
2. ビルド
githubからcloneしてビルドします。ビルドの際にテストをスキップするように「DskipTests」を追加し、実行可能バイナリとしてビルドするため、「build-web-console,build-binaries」もオプションを指定します。
git clone https://github.com/questdb/questdb.git
cd questdb
/opt/maven/bin/mvn clean package -DskipTests -P build-web-console,build-binaries
以下のように表示されればビルド完了です。
[INFO]
[INFO] --- jacoco:0.8.8:report (default-report) @ questdb-parent ---
[INFO] Skipping JaCoCo execution due to missing execution data file.
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for QuestDB 8.1.1-SNAPSHOT:
[INFO]
[INFO] QuestDB ............................................ SUCCESS [ 41.248 s]
[INFO] JMH benchmarks for QuestDB ......................... SUCCESS [ 6.641 s]
[INFO] Command line utils for QuestDB ..................... SUCCESS [ 2.252 s]
[INFO] Examples for QuestDB ............................... SUCCESS [ 0.308 s]
[INFO] Compatibility tests for QuestDB .................... SUCCESS [ 3.323 s]
[INFO] QuestDB ............................................ SUCCESS [ 0.386 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 54.331 s
[INFO] Finished at: 2024-08-05T09:25:23Z
[INFO] ------------------------------------------------------------------------
3. 起動設定
先程ビルドしたファイルを/usr/local/bin配下に配置します。
cp -pr core/target/questdb-8.1.1-SNAPSHOT-no-jre-bin.tar.gz /tmp/questdb.tar.gz
cd /tmp/
tar zxvf questdb.tar.gz
mv questdb-8.1.1-SNAPSHOT-no-jre-bin /usr/local/bin/questdb
mkdir /var/lib/questdb
続いてカーネルパラメータを調整しておきます。
vim /etc/sysctl.conf
fs.file-max=1048576
vm.max_map_count=1048576
:wq
sysctl -p
では起動設定ファイルを作成しましょう。
[Unit]
Description=QuestDB
Documentation=https://www.questdb.io/docs/
After=network.target
[Service]
Type=simple
Restart=always
RestartSec=2
LimitNOFILE=2147483647
# Adjust java path to match requirements of a given distro
ExecStart=/usr/lib/jvm/java-11-openjdk-amd64/bin/java \
--add-exports java.base/jdk.internal.math=io.questdb \
-p /usr/local/bin/questdb/questdb.jar \
-m io.questdb/io.questdb.ServerMain \
-DQuestDB-Runtime-66535 \
-ea -Dnoebug \
-XX:+UnlockExperimentalVMOptions \
-XX:+AlwaysPreTouch \
-XX:+UseParallelOldGC \
-d /var/lib/questdb
ExecReload=/bin/kill -s HUP $MAINPID
# Prevent writes to /usr, /boot, and /etc
ProtectSystem=full
StandardError=syslog
SyslogIdentifier=questdb
[Install]
WantedBy=multi-user.target
起動設定ファイルを有効化して、サービス起動してみます。
systemctl enable questdb.service
systemctl start questdb
早速ブラウザからアクセスします。URLは[http://IP:9000]でアクセスできます。

4. 性能比較
性能値についてGithub上にも記載はあるものの、テスト前提が96コアのうち24コア使用とかかれていて。。。。(そんなに準備できません)
Our demo is running on c5.metal instance and using 24 cores out of 96.
ということで貧弱な仮想マシンでどれくらい差がでるのか試してみます。同じ仮想マシンにinfluxDBとQuestdbを入れて試しました。
まずはデータをdummyデータを生成します。
import pandas as pd
import numpy as np
import datetime
Num_Records = 1000000
timestamps = pd.date_range(start='2023-01-01', periods=Num_Records, freq='T')
sensor_ids = np.random.choice(['sensor_1', 'sensor_2', 'sensor_3', 'sensor_4', 'sensor_5'], size=Num_Records)
values = np.random.normal(loc=20, scale=5, size=Num_Records)
data = pd.DataFrame({'timestamp': timestamps, 'sensor_id': sensor_ids, 'value': values})
data.to_csv('dummy_sensor_data.csv', index=False)
作成されたデータdummyデータをQuestdbおよびinfluxDBにimportします。以下スクリプトを作成してそれぞれ実行しておきましょう。
from influxdb import InfluxDBClient
import pandas as pd
data = pd.read_csv('dummy_sensor_data.csv')
client = InfluxDBClient(host='x.x.x.x', port=9000) # ご自身のIPに置き換えてください。
client.switch_database('live-est001')
batch_size = 10000
points = []
for i, row in data.iterrows():
point = {
"measurement": "sensor_data",
"time": row['timestamp'],
"tags": {
"sensor_id": row['sensor_id']
},
"fields": {
"value": row['value']
}
}
points.append(point)
if i % batch_size == 0 and i > 0:
client.write_points(points)
points = []
if points:
client.write_points(points)
from influxdb_client import InfluxDBClient, Point, WritePrecision
from influxdb_client.client.write_api import SYNCHRONOUS
import pandas as pd
data = pd.read_csv('dummy_sensor_data.csv')
url = "http://x.x.x.x:8086" #ご自身の環境に置き換え
token = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" #ご自身のTokenに置き換え
org = "live-est001" #ご自身の環境に置き換え
bucket = "live-est001" #ご自身の環境に置き換え
client = InfluxDBClient(url=url, token=token, org=org)
write_api = client.write_api(write_options=SYNCHRONOUS)
batch_size = 10000
points = []
for i, row in data.iterrows():
point = Point("sensor_data")\
.tag("sensor_id", row['sensor_id'])\
.field("value", row['value'])\
.time(row['timestamp'], WritePrecision.NS)
points.append(point)
if i % batch_size == 0 and i > 0:
write_api.write(bucket=bucket, org=org, record=points)
points = []
if points:
write_api.write(bucket=bucket, org=org, record=points)
client.close()
ではdummyデータがそれぞれのDBに入りましたので、比較してみます。
一定期間内(2024年1月1日~12月31日)のセンサーごとの最大値、最小値、平均値を取得するクエリをそれぞれ流してみました。
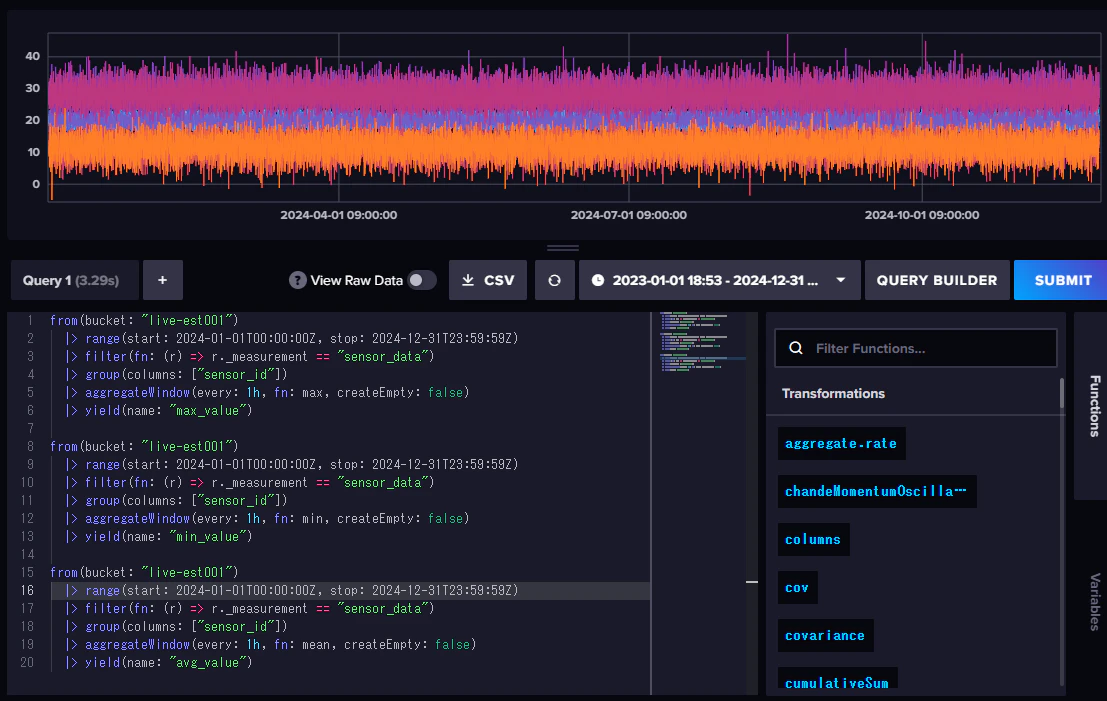
influxDB(Fluxスクリプト)
from(bucket: "live-est001")
|> range(start: 2024-01-01T00:00:00Z, stop: 2024-12-31T23:59:59Z)
|> filter(fn: (r) => r._measurement == "sensor_data")
|> group(columns: ["sensor_id"])
|> aggregateWindow(every: 1h, fn: max, createEmpty: false)
|> yield(name: "max_value")
from(bucket: "live-est001")
|> range(start: 2024-01-01T00:00:00Z, stop: 2024-12-31T23:59:59Z)
|> filter(fn: (r) => r._measurement == "sensor_data")
|> group(columns: ["sensor_id"])
|> aggregateWindow(every: 1h, fn: min, createEmpty: false)
|> yield(name: "min_value")
from(bucket: "live-est001")
|> range(start: 2024-01-01T00:00:00Z, stop: 2024-12-31T23:59:59Z)
|> filter(fn: (r) => r._measurement == "sensor_data")
|> group(columns: ["sensor_id"])
|> aggregateWindow(every: 1h, fn: mean, createEmpty: false)
|> yield(name: "avg_value")
実行結果
QuestDB
SELECT
sensor_id,
MAX(value) AS max_value,
MIN(value) AS min_value,
AVG(value) AS avg_value
FROM
sensor_data
WHERE
timestamp BETWEEN '2024-01-01T00:00:00Z' AND '2024-12-31T23:59:59Z'
GROUP BY
sensor_id;
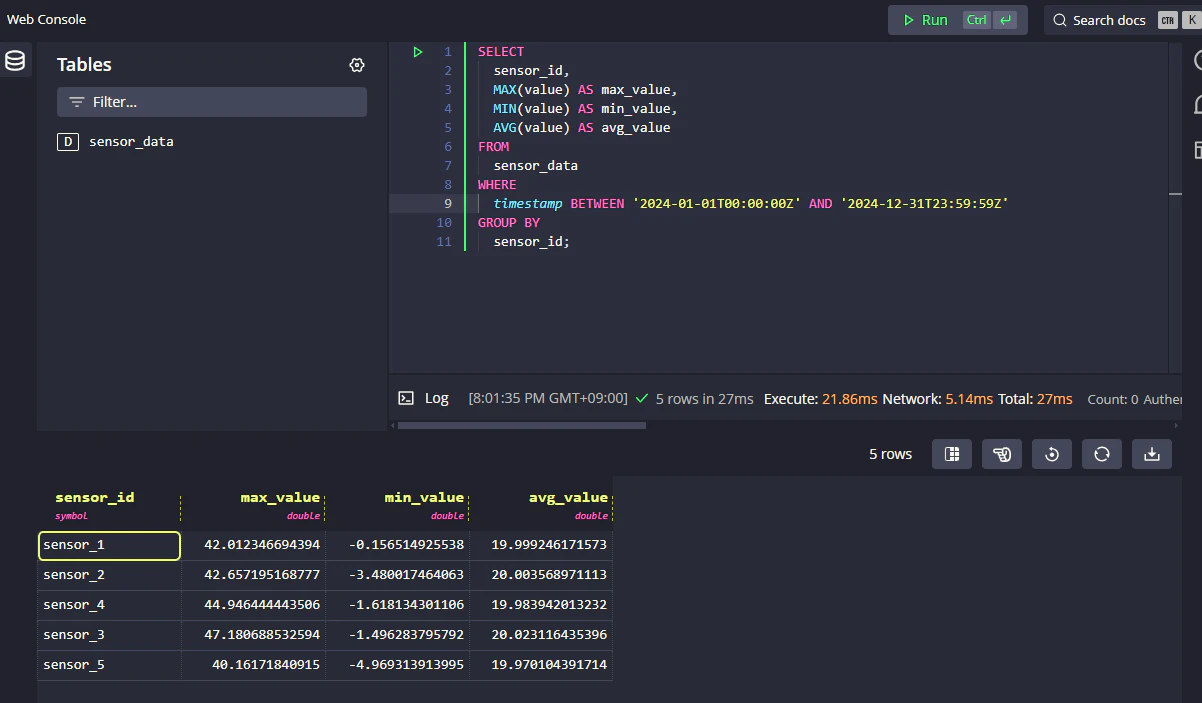
実行結果
性能比較
なんと約1/122でした!
| influxdb | Questdb |
|---|---|
| 3.29s | 27ms |
その他
今回はそれほど込み入った比較をしておりませんが、性能は圧倒的ですね。詳細は以下に記載がありますのでご確認ください。