■0.はじめに
仕事の関連でR言語に触れる機会がありまして。
特殊な言語でとっつきにくいっていう先入観がありましたが、実際に触ってみますと意外にとっつきやすく。
他の言語だとPythonと似たような匂いを感じました。
本文書の記載内容は、自分向けの備忘録的なものになります。
そのため、網羅的でなく体系立っていないですが、私と同じ先入観を持っている方へ、一歩先に進む道しるべになれば幸いです。
▼実行環境
・Windows10 64bit
・R 3.4.3
■1.R言語とは
R言語(あーるげんご)はオープンソース・フリーソフトウェアの統計解析向けのプログラミング言語及びその開発実行環境である。
R言語はニュージーランドのオークランド大学のRoss IhakaとRobert Clifford Gentlemanにより作られた。現在ではR Development Core Teamによりメンテナンスと拡張がなされている。
R言語のソースコードは主にC言語、FORTRAN、そしてRによって開発された。
なお、R言語の仕様を実装した処理系の呼称名はプロジェクトを支援するフリーソフトウェア財団によれば『GNU R』であるが、他の実装形態が存在しないために日本語での慣用的呼称に倣って、当記事では、仕様・実装を纏めて適宜にR言語や単にR等と呼ぶ。
Wikipedia
■2.インストール
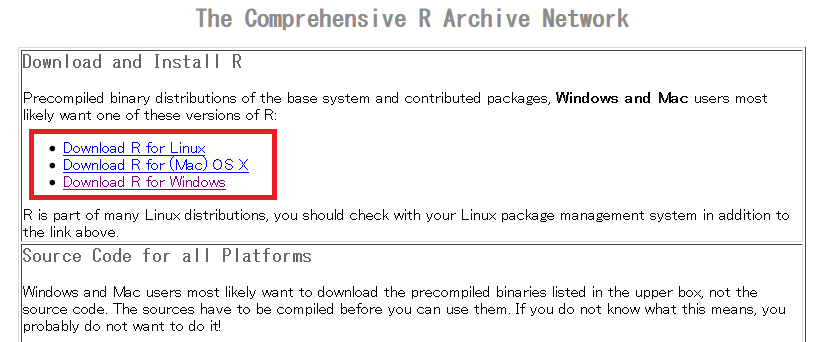
こちらから該当のOS用のインストーラーをダウンロードして実行する。
■3.実行するには?
Windowsの場合
スタートメニューから下記を選択
起動直後の画面
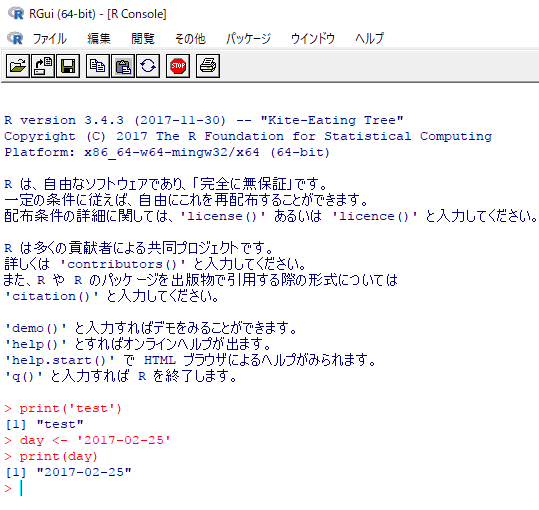
Rはインタプリタの言語なので、直接書いていけば都度実行結果が出てきます。
R言語で書かれたファイルをコンソールにドラッグアンドドロップしても実行できます。
バッチで実行するには
コマンドプロンプトから
rscript xxxx.R
のように、rscriptを使うことでバッチ実行できます。
rscriptにPATHを通しておく必要がありますので、
set PATH=%PATH%;C:\Program Files\R\R-3.4.3\bin
rscript xxxx.R
として、{Rのインストールフォルダ}/bin に一時的にPATHを通しておくとよいでしょう。
■4.基本
▼変数、コメントアウト
day <- '2017-02-25'
day = '2018-02-25'
'2017-02-25' -> day
3つとも同じことをしています。
ちなみに
day.start <- '2017-02-25'
day.end <- '2017-02-26'
学び始めた時、いろいろなサイトで変数名が"."(ピリオド)で区切られているのを見かけまして。
構造体とかクラス的な意味なのかな・・・と思ってんですが、特に意味はないそうですw
# コメント
とすると、その行をコメントアウトできます。
複数行の一括コメントアウトするには、地道に各行をコメントアウトするしかなさそうで、RStudioでは複数行を選択して一括でコメントアウトできるようになっていますが、内実は各行をコメントアウトしてるに過ぎません。
裏技的に下記のようにすれば複数行を一括コメントアウトすることはできるようですが、個人的にはちょっとイマイチ感があります。
if(0){
コメント1
コメント2
}
▼データ型
データ型の確認
mode(a):変数aの型を表示
is.numeric(a):変数aの型がnumericであればTRUE、異なればFALSE
...など
> a <- 7
> mode(a)
[1] "numeric"
> is.numeric(a)
[1] TRUE
> is.integer(a)
[1] FALSE
> b <- '7'
> mode(b)
[1] "character"
> is.character(b)
[1] TRUE
> is.numeric(b)
[1] FALSE
> c <- TRUE
> mode(c)
[1] "logical"
> is.logical(c)
[1] TRUE
データ型の変換
as.~(変数名)
> a <- '7'
> mode(a)
[1] "character"
> a <- as.integer(a)
> is.integer(a)
[1] TRUE
▼文字列の操作
文字列の結合
pasteを使います。
> a <- paste('This', 'is', 'Test.', sep=' ')
> print(a)
[1] "This is Test."
渡す文字列はいくつでも構わなく、文字列間をsepで指定された文字で結合します。
上記例では半角スペースで結合しています。
> a <- paste('これは', 'テスト', 'です。', sep='')
> print(a)
[1] "これはテストです。"
上記のようにすることで結合文字を使用しないこともできます。
文字列の検索
部分一致の検索にはgrepを使います。
> data <- c('test.txt', 'test.xlsx', 'text.txt', 'test.com')
> # '.txt'を含む要素を検索
> grep('.txt', data)
[1] 1 3
> # 戻り値を添え字にすれば該当データの一覧が取得できる
> data[grep('.txt', data)]
[1] "test.txt" "text.txt"
完全一致検索にはmatchを使います。
> data <- c('test', 'es', 'ese', 'testset')
> match('es', data)
[1] 2
> data[match('es', data)]
[1] "es"
文字列から一部を切り出す
substrを使います。
substr(対象文字列, 切り出し開始位置, 切り出し終了位置)
> substr('test.xlsx', 2, 4)
[1] "est"
他のプログラミング言語と異なり、先頭の添え字は0ではなく1という点に注意が必要です。
▼日付の扱い
基本的な考え方
R言語では日付型は1970年1月1日を基準点とした経過日であったり経過時間で表されるそう。
1970年以前はマイナス値で表すらしいです。
日付型を表現できるクラスとしては、
Date:年月日
POSIXct:年月日時分秒
などがあります。
(他にもPOSIXlt, POSIXtがありますが、上記の2つで基本は事足りそうな感じが...)
> today <- Sys.Date() # システム日付
> today
[1] "2018-02-16"
> today - 1 # Date型の最小単位は日なので、-1は前日になる
[1] "2018-02-15"
> unclass(today) # クラス情報を取り除く
[1] 17578 # 1970年1月1日からの経過日数
> today <- Sys.time() # システム日時
> today
[1] "2018-02-16 14:15:51 JST"
> today -1 # POSIXct型の最小単位は秒なので、-1とすると1秒前となる
[1] "2018-02-16 14:15:50 JST"
> unclass(today) # クラス情報を取り除く
[1] 1518758151 # 1970年1月1日からの経過秒数
> strptime('2/13/2018 13:15:45', "%m/%d/%Y %H:%M:%S")
[1] "2018-02-13 13:15:45 JST"
> strftime(Sys.Date(), '%Y%m%d')
[1] "20180216"
▼条件分岐
条件分岐はif~else if~else。
if(条件1){
条件1がtrue時の処理
} else if(条件2){
条件2がtrue時の処理
} else {
条件1、条件2ともにfalse時の処理
}
まあ一般的な書き方ではあるのですが、一点だけ書き方に注意が必要でして。
elseの前で改行するときで、例えば下記のコードはエラーになります。
x = 0
if(x == 0){
print('x = 0')
}
else {
print('x != 0')
}
これはelseの前の}でif文が終わりとみなされ、elseを新たな命令と判断→そんな命令はないのでエラーとなるようです。
> x = 0
> if(x == 0){
+ print('x = 0')
+ }
[1] "x = 0"
> else {
エラー: 予想外の 'else' です in "else"
> print('x != 0')
[1] "x > 0"
> }
エラー: 予想外の '}' です in "}"
エラーとしないためには、elseの前に}を付けるか
x = 0
if(x == 0){
print('x = 0')
} else {
print('x != 0')
}
全体を{ }で括る必要があります。
{
x = 0
if(x == 0){
print('x = 0')
}
else {
print('x != 0')
}
}
後者はあまり見かけない書き方ですね...
▼繰り返し(for, while)
どちらも他の言語と同じような書き方なのでハマることはないでしょう。
x = 3
for(i in 1:x){
print(i)
}
[1] 1
[1] 2
[1] 3
x = 1
while(x <= 5){
print(x)
x <- x + 1
}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
▼break、continue
breakも他の言語と同じような書き方。
x = 1
while(x <= 5){
print(x)
x <- x + 1
if(x == 3){
break
}
}
[1] 1
[1] 2
continueですが、そのような命令はなく、nextという命令が同じ機能を有しています。
x = 0
while(x <= 5){
x <- x + 1
if(x == 3){
next
}
print(x)
}
[1] 1
[1] 2
[1] 4
[1] 5
[1] 6
■5.ベクトルと行列
▼ベクトル
コンピューターの世界では「ベクトル」は一次元の配列として表現されるデータ構造のことを指すそうです。
> z <- c(2, 4, 6)
> z
[1] 2 4 6
> z[1]
[1] 2
> length(z)
[1] 3
> y <- c('abc', 'defg', 'hi', 'j')
> y[2]
[1] "defg"
> y[1:2]
[1] "abc" "defg"
> length(y)
[1] 4
x[n]でベクトルxのn番目の要素を参照できます。(n=1~)
x[m:n]でベクトルxのm~n番目の要素を参照できます。
length(x)でベクトルxの要素数を求めることができます。
▼行列
言葉の定義としてはベクトルをいくつか並べたものを言うそうです。
> z <- matrix(c(1,2,3,4,5,6)) # 行数、列数未指定
> z
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
[5,] 5
[6,] 6
> z <- matrix(c(1,2,3,4,5,6), nrow=2, ncol=3) # 行数、列数指定
> z
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> z <- matrix(c(1,2,3,4,5,6), nrow=2, ncol=3, byrow=T) # 与えたベクトルの値を一行ずつセットしていく(デフォルトは一列ずつ)
> z
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
> z <- matrix(c(1,2,3,4,5,6), nrow=2) # 行数のみ指定
> z
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> z <- matrix(c(1,2,3,4,5,6), nrow=3)
> z
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> z[1,]
[1] 1 4
> z[1,1]
[1] 1
最もわかりやすい行列の作成手順は以下になります。
1.行列の要素をベクトルで用意する
2.matrix関数で行数、列数を指定し、ベクトルから行列に変換する
x[m, n]で行列xのm行n列目の値を参照できます。
x[m, ]と行のみ指定すると指定行の全列を参照でき、
x[,n ]と列のみ指定すると指定列の全行を参照できます。
> z <- matrix(c(1,2,3,4,5,6), nrow=2, ncol=3, byrow=T)
> z
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
> z <- rbind(z, c(7, 8, 9)) # 行の追加
> z
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> z <- cbind(z, c(4,5,6)) # 列の追加
> z
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 4 5 6 5
[3,] 7 8 9 6
> z <- z[, c(1,3,2,4)] # 列の並び替え
> z
[,1] [,2] [,3] [,4]
[1,] 1 3 2 4
[2,] 4 6 5 5
[3,] 7 9 8 6
> colnames(z) <- c('one', 'two', 'three', 'four') # 列名の設定
> z
one two three four
[1,] 1 3 2 4
[2,] 4 6 5 5
[3,] 7 9 8 6
行の追加はrbind、列の追加はcbindを使います。
x[, c(新しい並び順)]とすることで列の並び替えができます。
(列が多いと大変そう...)
■6.CSVファイルの読み書き
読み込みにはread.csv()
書き出しにはwrite.csv()
datetime,status,detail
2018/2/13 13:23:45,Normal,Start
2018/2/13 13:35:03,Fatal,Fatal Exception
2018/2/13 13:23:45,Normal,End
> data <- read.csv('test.csv', header=T, stringsAsFactor=F, colClasses=c("POSIXct", "character", "character"))
> data
datetime status detail
1 2018-02-13 13:23:45 Normal Start
2 2018-02-13 13:35:03 Fatal Fatal Exception
3 2018-02-13 13:23:45 Normal End
header=Tとすると、先頭行をヘッダーとして列名に適用してくれます。
stringsAsFactor=Fとしないと、各列の値が文字列の場合はfactor型として解釈されます。
(factor型がどういうケースに便利なのかよくわかってない現時点の私のレベルでは面倒くさい型という認識ですw)
colClassesで各列の型を指定しています。
> write.csv(data, 'test_out.csv', quote=F, row.names=F)
quote=Fとすると、データの引用符"がつかないそうです。
row.names=Fとすると、データの行番号が出力されません。
datetime,status,detail
2018-02-13 13:23:45,Normal,Start
2018-02-13 13:35:03,Fatal,Fatal Exception
2018-02-13 13:23:45,Normal,End
■7.行列をSQLっぽく操作する
dplyrというパッケージが便利でした!
データ操作に特化したパッケージで、これを使うことで行列をSQLっぽく操作できます。
# パッケージを読み込む
library(dplyr)
使用時にパッケージを読み込むのを忘れずに。
result <- data %>%
dplyr::filter(Status == 'Normal') %>%
dplyr::group_by(TimeStamp)
%>%演算子を使って複数の命令を連結し、一つの処理として扱うのが基本的なお作法のようです。
上記の例では、dataからStatus == 'Normal'の行を絞り込み、TimeStamp列でグループ化しています。
result <- data %>%
dplyr::filter(Status == 'Normal')
filter(列名 == 値)で行の絞り込みを行います。
SQLだとwhereと同じ役割です。
SQLで言うlike(部分一致)検索を行いたい場合はgreplを使うのが便利です。
下記例では、Detail列に'SRC='を含む行に絞り込んでいます。
result <- data %>%
dplyr::filter(grepl('SRC=', Detail))
複数条件を指定する場合は&(AND)、|(OR)を使います。
# AND
result <- data %>%
dplyr::filter(Status == 'Normal' & ID =='M001')
# OR
result <- data %>%
dplyr::filter(Status == 'Normal' | Status == 'Warning')
列を絞り込むにはselectを使います。
result <- data %>%
dplyr::select(TimeStamp, Detail)
データを集約するにはsummarise。
集計関数(max, min, mean, sumなど)と一緒に使います。
result <- data %>%
dplyr::summarise(max_temperature = max(temperature))
データをグループ化するにはgroup_by。
下記例では、TimeStampごとのtemperatureの最大値を求めています。
result <- data %>%
dplyr::group_by(TimeStamp) %>%
dplyr::summarise(max_temperature = max(temperature))
SQLだとグループ化した列ごとの件数を求めたいことがよくあります。
select TimeStamp, count(*) from data group by TimeStamp;
上記をdplyrを使って表すと下記のようになります。
result <- data %>%
dplyr::group_by(TimeStamp) %>%
dplyr::summarise(count = n())
行の並び替えはarrange。
SQLで言うorder byの役割です。
result <- data %>%
dplyr::arrange(TimeStamp) # 昇順に並び替え(デフォルト)
result <- data %>%
dplyr::arrange(desc(TimeStamp)) # 降順に並び替え
■8.総括
・Python触ったことあれば違和感なく使える
・データ操作に長けており、統計解析向けの異名は伊達ではない