インラインアセンブラ版
PA0 に WS2812B のデータ線を接続します。
私は手元にあった4個入りの物を使いました。
Nucleo F303K8 は 16MHzで 動作させます。
/* USER CODE BEGIN 2 */
uint32_t data[4]={
// G R B
(0x00 << 16) | (0x00 << 8) | 0x20,
(0x00 << 16) | (0x20 << 8) | 0x00,
(0x20 << 16) | (0x00 << 8) | 0x00,
(0x08 << 16) | (0x08 << 8) | 0x08
};
const uint32_t bsrr = (uint32_t)&GPIOA->BSRR;
for (int i=0; i<4; i++) {
uint32_t d=data[i];
asm volatile(
"MOV r1, #1 \r\n" // BSRRに H を書くため PA0 = 0ビット目
"LDR r2, =(1<<16) \r\n" // BSRRに L を書くため PA0 = 0ビット目 = 16ビットのところ
"LDR r3, =(1<<23) \r\n" // 23番目のビットを調べる 兼 24ビット分ループ
".loop: \r\n"
"MOV r4, %[data] \r\n"
"ANDS r4, r3 \r\n" // dataのr3ビット目が1か調べる
"BNE .label1 \r\n" // 0じゃなきゃジャンプ
// 0 を出す
"STR r1, [%[bsrr]] \r\n" // set H
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"STR r2, [%[bsrr]] \r\n" // set L
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"B .label_end \r\n"
//
".label1: \r\n"
// 1 を出す
"STR r1, [%[bsrr]] \r\n" // set H
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"NOP \r\n"
"STR r2, [%[bsrr]] \r\n" // set L
"NOP \r\n"
".label_end: \r\n"
"ASRS r3, #1 \r\n" // 右 1ビットシフト
"BNE .loop \r\n"
: // 結果を収めるレジスタ なし
: [bsrr] "r"(bsrr), // GPIOA BSRR レジスタのアドレスを渡す
[data] "r"(d) // データ
: "r1", "r2", "r3", "r4" // 使うレジスタ
);
}
/* USER CODE END 2 */
いわゆる NeoPixel とか言われているやつです。SPIを使う方法等が紹介されていますね。
ここでは愚直に,ポートをパタパタです。せっかくなので少しかじったインラインアセンブラを使ってみました。
ポートの位置を変えるにはいろいろ手直ししなきゃいけないし,何よりCPUの動作スピードが変わったら... 再利用性はかなり無視です。
Cortex-M4 のアセンブラは初めてでした。同じだろうと思っていたのですが,SUBとSUBSなど,細かいところで違いました。せっかくのNucleoですからデバッガを思い切り使い,かつ安くて便利なUSBロジアナで波形を確かめながら進めました。波形を見ながら NOP の数を調整していくのは,それだけでも楽しかったです。
アセンブラに24ビットデータを渡し,本当に1ビットずつ調べて H または L の波形を出すようにしました。
さすがに8MHz動作では,ビットの切り替えの処理で時間を取ってしまい,規定時間を守れなくなってうまく光らなくなってしまいましたので,16MHz動作にしました。
更にがんばれば配列のアドレスを渡して複数LEDを一気に扱えそうでしたが,面倒になってきたので 試しに普通に for ループで回したらうまく動いたのでそのままにしています。
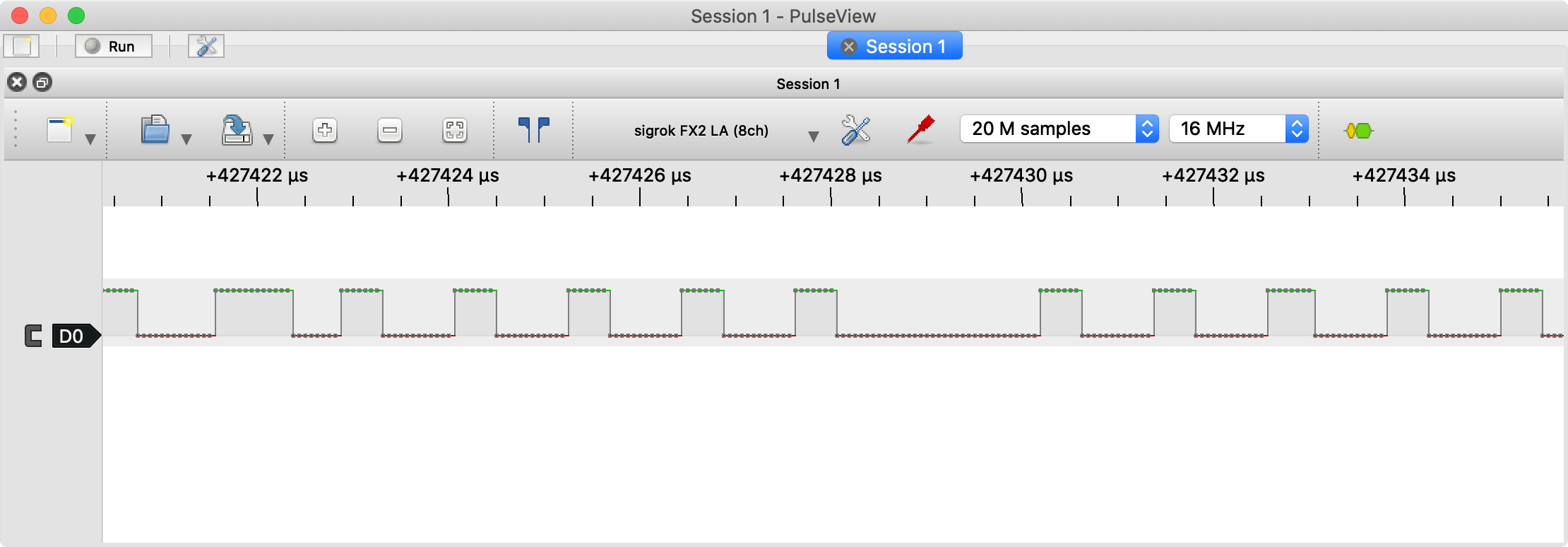
以下はLEDの1個めのデータの終わりから2個めのデータの始めの部分の波形です。この程度だったらリセットと判断されず大丈夫のようでした。
(追記)SPI版
/* USER CODE BEGIN 2 */
#define DATA_H 0b01110
#define DATA_L 0b01000
#define num_LEDs 4
uint8_t data[24 * num_LEDs];
uint32_t data_GRB[num_LEDs] = {
0x000020,
0x002000,
0x200000,
0x000000
};
/* USER CODE END 2 */
/* Infinite loop */
/* USER CODE BEGIN WHILE */
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
for (int c=0; c<num_LEDs; c++){
for (int i=0; i<24; i++) {
if( data_GRB[c] & (1<<i) ) {
data[c * 24 + 23 - i]=DATA_H;
} else {
data[c * 24 + 23 - i]=DATA_L;
}
}
}
HAL_SPI_Transmit(&hspi1, &data, 24*num_LEDs, HAL_MAX_DELAY);
uint32_t d=data_GRB[0];
for (int c=0; c<(num_LEDs - 1); c++ ){
data_GRB[c]=data_GRB[c+1];
}
data_GRB[num_LEDs-1]=d;
HAL_Delay(1000);
}
/* USER CODE END 3 */
}
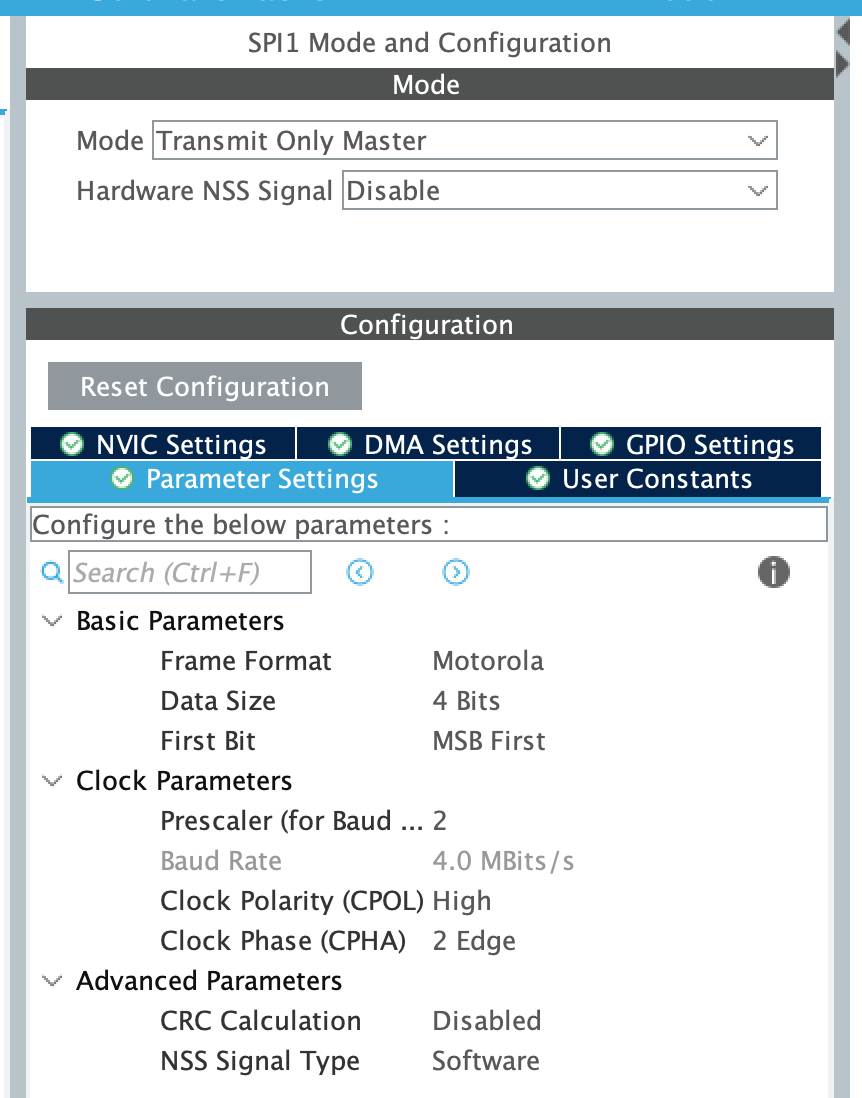
web記事を参考に,4Mbpsの4ビットで1と0を表現しました。
SPIのクロックはプリスケーラで指定するのですね。初めて知りました。8MHz / 2 = 4Mbps です。
その場合,少しデータ送信が途切れる時があるのですが,WS2812B的には問題ないようです。
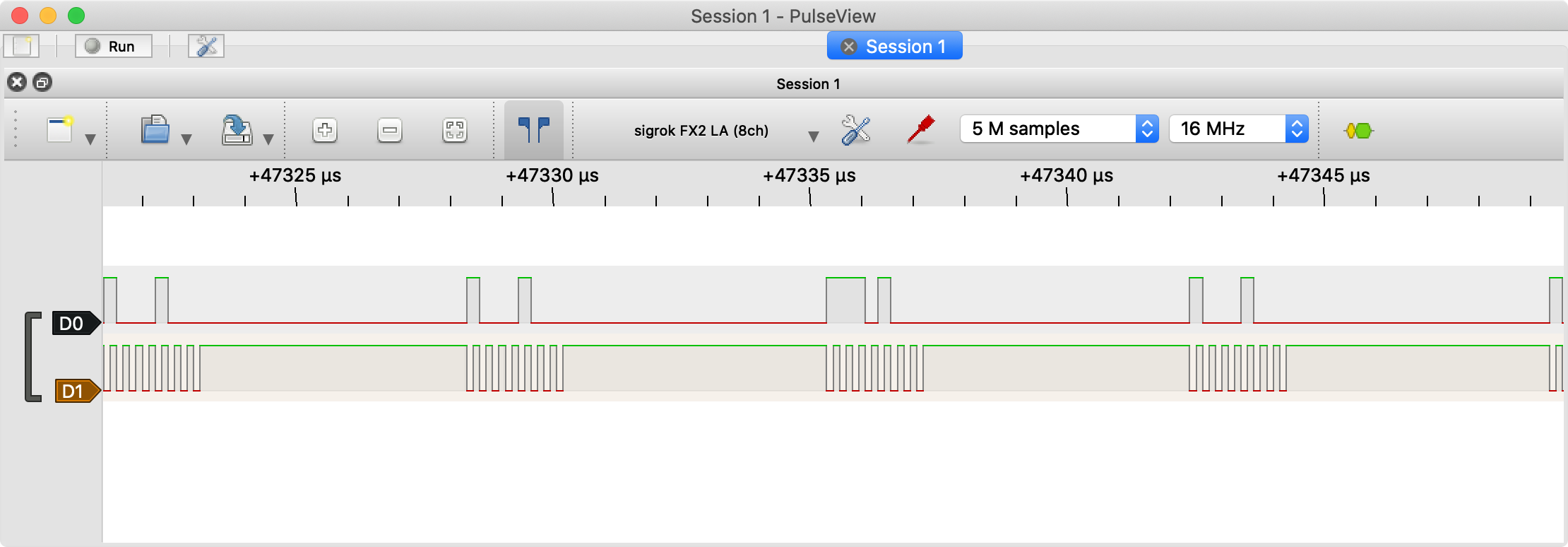
32MHz動作で div 8 ならデータも途切れないようです。