Google Cloud Dataproc でデータ解析基盤を構築
GCP の Google Cloud Dataproc で手軽にビッグデータ解析の基盤が出来るらしいので触ってみました。
そもそもデータ解析ってなに?
蓄積されたデータを加工して集計しやすい形式にしたり、視覚化して傾向を捉えたり、
簡単な例でいうとデータの並べ替えとかも解析といえば解析になります。
ビッグデータの定義は
ビッグデータとは、従来のデータベース管理システムなどでは記録や保管、解析が難しいような巨大なデータ群。
明確な定義があるわけではなく、企業向け情報システムメーカーのマーケティング用語として多用されている。
多くの場合、ビッグデータとは単に量が多いだけでなく、様々な種類・形式が含まれる非構造化データ・非定型的データであり、
さらに、日々膨大に生成・記録される時系列性・リアルタイム性のあるようなものを指すことが多い。
今までは管理しきれないため見過ごされてきたそのようなデータ群を記録・保管して即座に解析することで、
ビジネスや社会に有用な知見を得たり、これまでにないような新たな仕組みやシステムを産み出す可能性が高まるとされている。
らしいです。
ビッグデータを解析して何が面白いのかというと、
例えば自動車メーカーで言うとカーナビのデータから事故が発生しやすいポイントを洗い出し、
安全運転のサポートに活用したり、キャッシュレス決済による購買行動を分析することで
最適なターゲットに訴求出来たりと多岐にわたります。
中国のとある企業では、高級車の販売にあたりビッグデータを活用し、
買う確率が高い層に訴求することで半年のノルマを数時間で達成したという話もあったりなかったり。
ということで、今回はビッグデータを解析するための足がかりを探ります。
どうやって実装するの?
ビッグデータ解析にあたっては複数のサーバを稼働させる必要があります。
それら複数のサーバに対して分散して処理をさせることで大量のデータを処理します。
分散処理には Hadoop や Spark を用いますが、それには処理を分散するためのマスタサーバ、
実際に処理を行うスレーブサーバを構築する必要がある。
もちろん解析するデータが大きければ大きいほどそれぞれのサーバのスペック、台数を拡張する必要がある。
なかなかハードル高い。。
ネットワークの設計からサーバ構築、運用まで含めると、
自前で上記の構成を準備するのは相応のコストがかかります。
Google Cloud Dataproc では分散処理で必要な Hadoop や Spark などのフレームワーク、サーバリソースを簡単に準備することができます。
とりあえず触る
残念ながら解析したいビッグデータは手元にないので、Spark に標準で付属する円周率計算のサンプルを使って Dataproc を触ってみる。
モンテカルロ法を使って円周率に近い数値を算出するものなので、3.1415... に近い数値が出ていることを確認する。
まずはGCPの管理画面からポチポチ行う。
1.クラスタを作成
- クラスタを作成する。

2.クラスタの設定
- リージョンやクラスタタイプなどを指定。

3.ノードの構成
- マシンタイプやノードの数を指定。
4.クラスタのカスタマイズ
- クラスタが配置されるネットワークを指定。
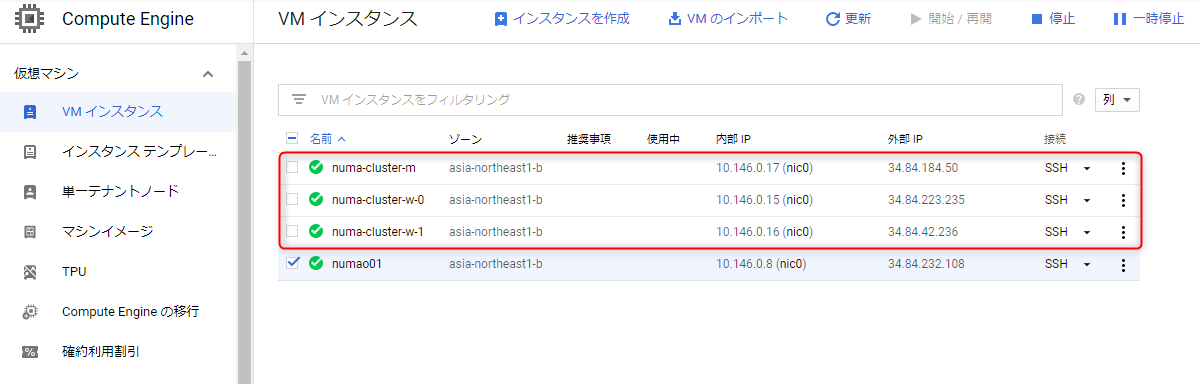
5.クラスタ作成完了
- クラスタが作成されました。

- ComputeEngine でノードが作成されていることも確認。
6.ジョブを送信
- 今度は上記作成したクラスタに円周率計算のサンプルのジョブを送信してみます。
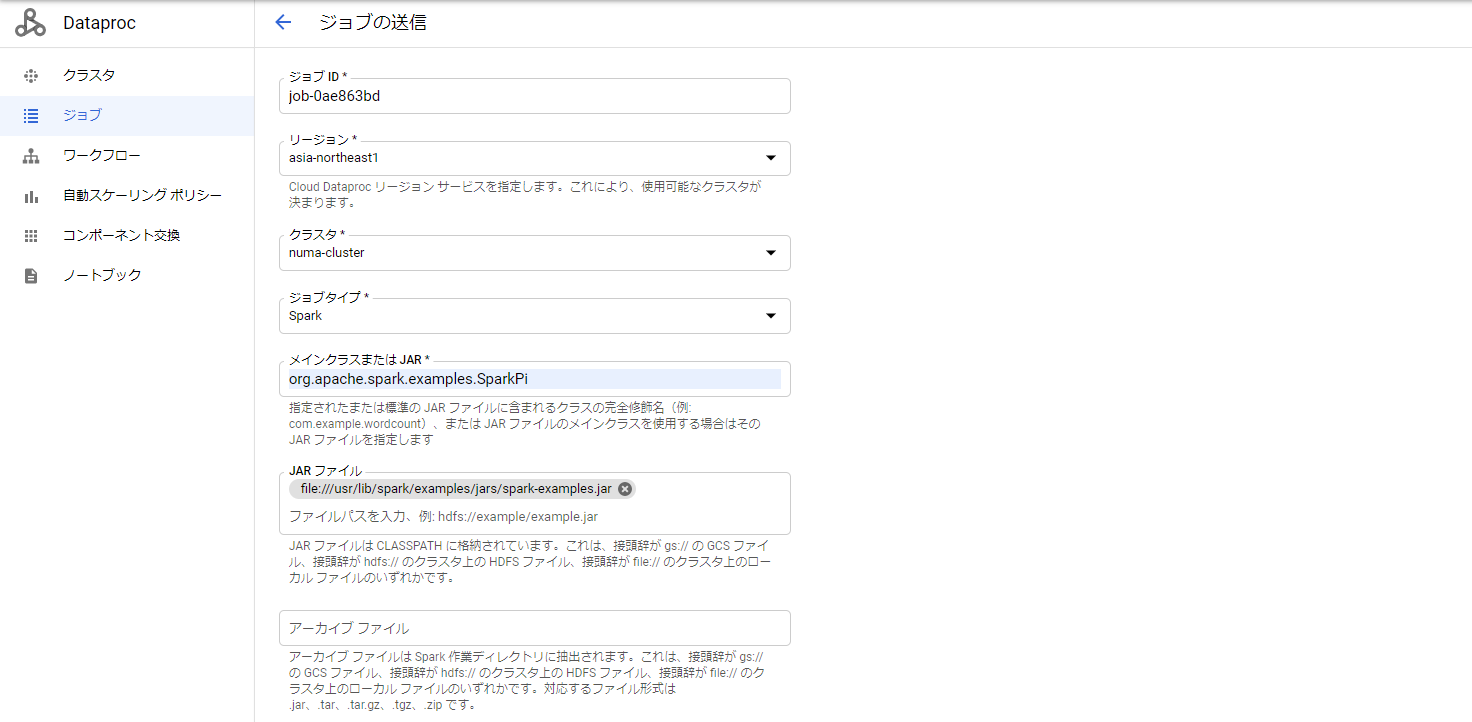
7.クラスタやジョブの内容を記入
- サンプルを使用するため以下を指定する。
| 項目 | 値 |
|---|---|
| ジョブタイプ | Spark |
| メインクラスまたはJAR | org.apache.spark.examples.SparkPi |
| JARファイル | file:///usr/lib/spark/examples/jars/spark-examples.jar |
| 引数 | 1000 |
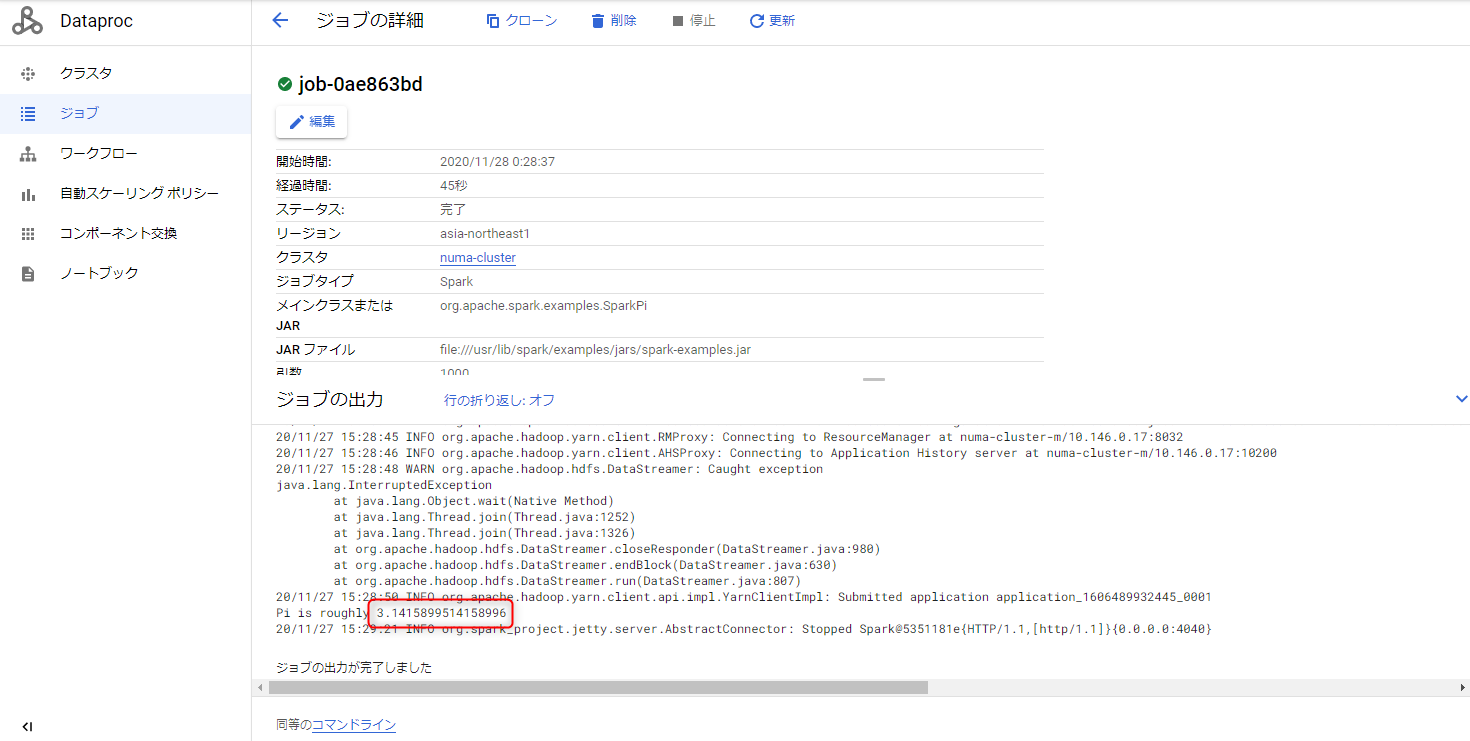
8.ジョブが実行されていることを確認
- 円周率に近い数値が出ているため成功。
9.クラスタ削除
- 処理が終わったらクラスタを削除しておく。

コマンドラインでもできるみたいなので叩いてみる
先ほど作ったのと同じ内容のクラスタ、ジョブをコマンドラインからやってみる。
同一VPC内にVMインスタンスを1台立ててそこから実行します。
1.クラスタを作成
$ gcloud dataproc clusters create cluster-numao02 --subnet=default --zone=asia-northeast1-b --region=asia-northeast1 --no-address --num-workers=2
- 作成されていることを確認。

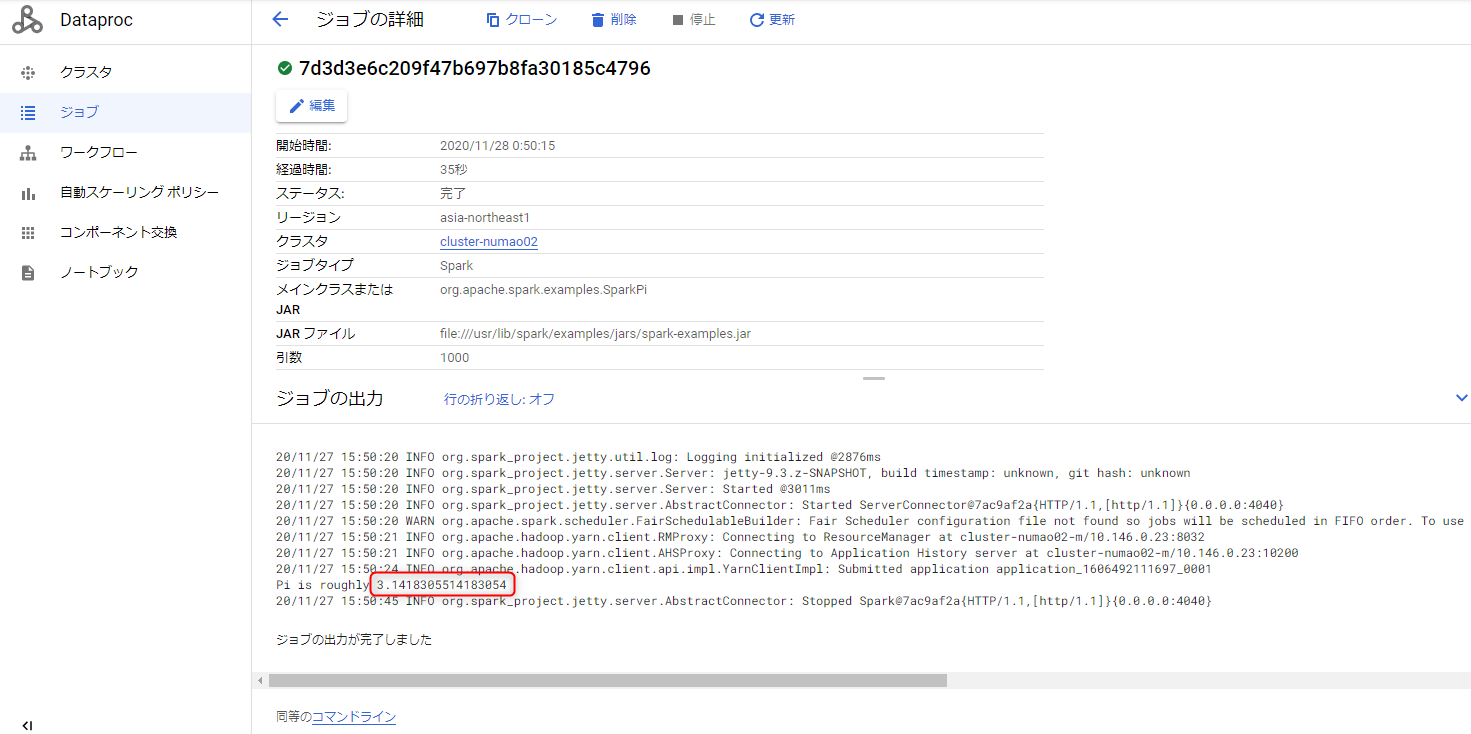
2.ジョブを送信
$ gcloud dataproc jobs submit spark --cluster cluster-numao02 --class org.apache.spark.examples.SparkPi --jars file:///usr/lib/spark/examples/jars/spark-examples.jar --region asia-northeast1 --project numaotest -- 1000
- 円周率に近い数値が出ているため成功。
3.クラスタ削除
- 処理が終わったらクラスタを削除しておく。
$ gcloud dataproc clusters delete cluster-numao02 --region=asia-northeast1
最後に
ビッグデータ解析にあたってネックとなる、サーバリソース、
Spark の実装が Dataproc を使うことで簡単に準備することが出来ました。
今回はサンプルでしたが、実際に解析する場合は、
解析したデータを Cloud Strage に吐き出し、Data Studio で可視化するなど
他サービスとの連携することでより分かりやすくできるので、それはまた追々。
![]() FORK Advent Calendar 2020
FORK Advent Calendar 2020
![]() 2日目 strapi+nuxt.jsでアドベントカレンダーを作ろう @sunnyplace
2日目 strapi+nuxt.jsでアドベントカレンダーを作ろう @sunnyplace