はじめに
Domo(ドーモ)は、データの接続や可視化を特別な知識がなくても、直感的に実現することができるBI製品です。
データを接続するための多くのコネクターが用意されており様々システムからDomoへデータを簡単に取り込むことができます。
「まずはデータをDomoへ集約しよう!」と、Domo導入初期には、社内と様々なシステムに接続してみた経験がある方もいらっしゃるのではないかと思います。
必要なデータが揃い、社内のユーザーも意欲的にDomoを活用し始めた頃、所有者の異なる似たようなDatasetがあることに気づく…こんな場面のお話です。
Datasetの重複はなぜ発生する?
Domoでのデータの管理方法には様々な方針があると思います。
可視化に使用するデータを社内の運営チームなど一部の担当者で管理している場合、Datasetの重複は比較的起きにくいと思われます。
一方、業務に必要なデータは各々でDomoへ取り込みできる権限を解放している場合、Domoのデータ接続の容易さが裏目に出てしまう場面があります。
- 同じExcelデータを別々の人がアップロード
- 同じ外部システムから個々のアカウントで同じデータを取得
データ取り込みの権限について制限をかけていても、Domo内の同じDatasetをソースに複数のユーザーが似たようなDataflowを組み新たなDatasetを作成することで重複Datasetが生まれる可能性もあります。
インスタンス内のDatasetが増えるほど、重複Dataset発生の可能性も比例していきます。
Dataset重複発生によるリスク
Datasetの重複が発生すると以下のようなリスクが挙げられます。
- 重複したデータによる行クレジット消費
- ユーザーが使用すべきデータを絞り込めないことによる混乱
放置していると、重複DatasetをソースとしたDataFlowにより行クレジット消費は鼠算式に増える可能性があります。
そのため、適切な管理をする必要があります。
Datasetを重複させない予防策
データの民主化とデータガバナンスの両立は難しい課題ではあります。
ここでは、”重複Datasetを発生させない”という観点でいくつかの対策例を挙げてみます。
①データ接続(取り込み)の制限
Domo上に重複したデータが取り込まれてしまうと、カードやDataflowに使用され、その後の削除が難しくなります。
データを取り込む時点からきちんと管理することが重要です。
データ接続できる権限を不特定多数に解放せず、少人数でコネクター権限を管理、運用していく体制を作ることが対策として有効です。

※「コネクターを管理」の権限は、デフォルトでは管理者のみです。
管理者メニュー>機能設定>コネクターから、使用できるコネクターやユーザーを制限することができます。
デフォルトでは制限はかかっていないため、編集ユーザー以上であれば誰でもデータ接続できる状態です。

②必要データの事前準備
重複データは既にDomo上にある状態で、同じデータを取り込むことで発生します。
取り込みを行うユーザーは必要なデータがDomo上に存在しないと考え、データ接続している場合がほとんどです。
このような追加でデータ接続する場面を根本的に作らないよう、事前に管理・運営チームで業務ユーザーが必要なデータをDomo内に準備しておくことも重要です。
そのためには日ごろのコミュニケーションやエンドユーザーの業務への理解など組織横断的な運営が理想です。(コミュニケーションの取れる運営体制構築が一番の難課題だったりもしますが…)
③データカタログの用意
管理・運営チームでDomo上にどのようなデータが存在しているか把握していても、エンドユーザーが把握していない。という状況はよく耳にします。
Domoではセキュリティの面からも管理者以外のユーザーは、アクセス権限のないデータを通常知る術はありません。
せっかく準備したデータも利用するユーザーに周知が不足していると、ユーザーはDomo上に存在しないものと思い、新たにデータを取り込もうとするかもしれません。
どのようなデータがDomo上に既に接続されているか公開することが重要です。
これを解決するのがデータカタログです。
データカタログとして最低限の情報は、DomoStatsやDomo Governance DataSetなどを活用すると簡単に取得可能です。
Datasetの説明もきちんと入力していれば、以下のようなカードが作成できます。(この記事では詳細割愛します)
| Dataset ID | Dataset Name | Description |
|---|---|---|
| 123456 | Sales | 日毎の営業所単位の商品別売上データ |
※データは全てダミーデータです
まずはExcelで作成したDatasetリストをDomo上で公開だけでも効果的です。
DomoStats、Domo Governance Connecterは、管理者権限でのみ接続可能なコネクターになっています。管理者権限以外のユーザーは、社内の管理者ユーザーへ接続を依頼する必要があります。
Datasetの重複を検知する
命名規約の徹底
Datasetの重複が発生してしまった際に検知し易くする方法として、予めDatasetの命名規約を決めて徹底することは有効です。
データの中身までは詳細な確認が必要ですが、同じ命名規約であれば同一名称のDatasetとして作成される可能性が高いため、同一名称のDatasetを検知することで重複の可能性があるDatasetの発見を早めることが可能です。
Datasetの重複判定
ここからは重複Datasetを発見した後の対応について説明します。
「この2つのDatasetは同じものかも?」と発見しても、Dataset名、列名、行数だけで安易に同じ中身とは判断できません。その上、どちらのDatasetもすでに利用されている場合は影響が大きく安易に削除できません。
一見同じように見える2つのDatasetを取捨選択するためには2つのデータが完全一致しているという確証が必要ではないかと思います。
行/列数が少ないDatasetであれば、Excelの数式で比較することもできますが、多くの場合この方法は苦労します。(Excelで扱えないサイズをDomoで扱っているケースが多い)
私は「2つのデータの完全一致の確認」という課題に、同僚からアドバイスをもらいSQLで実践することができました。
この方法をMagic ETLを使うことでより簡単実践することができましたので紹介します。
前提
比較する2つのDatasetの列数、行数の一致はDataset詳細画面などで確認が可能です。
列数、行数は一致している前提で、データの中身が一致しているかを確認していきます。
比較するデータは以下AとBのサンプルデータで解説します。
A
| date | item | sales |
|---|---|---|
| 2025-04-01 | Apple | 200 |
| 2025-04-01 | Orange | 100 |
| 2025-04-01 | Orange | 100 |
| 2025-04-02 | Apple | 200 |
| 2025-04-02 | Apple | 200 |
B
| date | item | sales |
|---|---|---|
| 2025-04-01 | Apple | 200 |
| 2025-04-01 | Orange | 100 |
| 2025-04-01 | Orange | 100 |
| 2025-04-02 | Apple | 100 |
| 2025-04-02 | Apple | 100 |
STEP1:グループ化
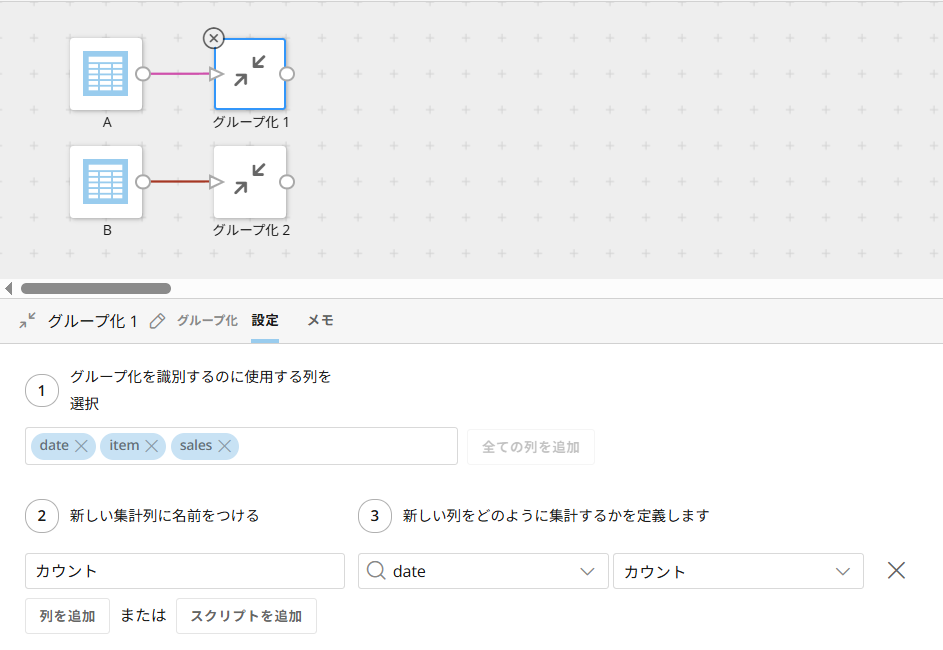
まずは、それぞれのDataset内での重複行をグループ化します。
「グループ化」で、「全ての列を追加」を押下して、集計列は重複の行数をカウントした値になるようにします。(ここではカウントという列名にします)
※値がすべての行に入っている列を選択してください。
A、Bどちらも同じ内容のタイルになるようタイルの複製を利用しましょう。
STEP2:行を追加
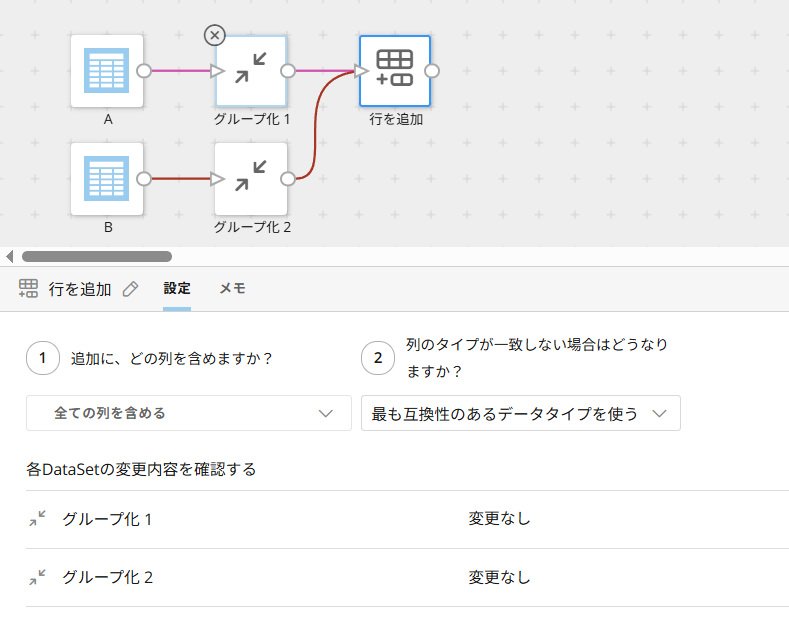
それぞれのデータ内での重複がなくなった状態になったら、「行を追加」で結びます。
列名、列数が一致している前提になるので、どちらのDatasetも「変更なし」となっているか確認しましょう。
STEP3:グループ化
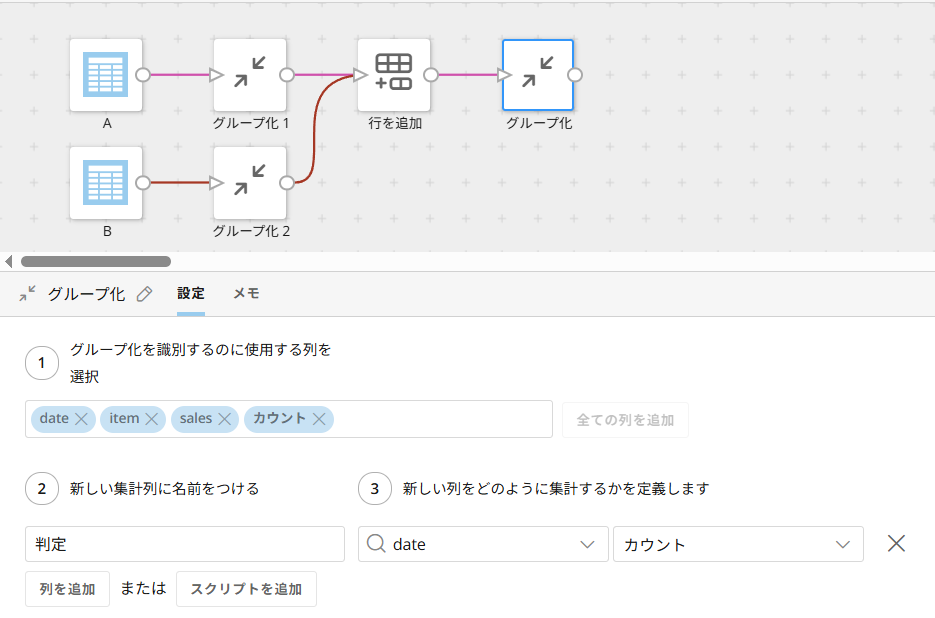
続いてSTEP1と同じく「グループ化」で集計します。(ここでは集計列は「判定」という列名にします)
この処理でA、Bが同じ列・同じ値である行は、1行に集計されます。→判定=2
| date | item | sales | カウント | 判定 |
|---|---|---|---|---|
| 2025-04-01 | Apple | 200 | 1 | 2 |
| 2025-04-01 | Orange | 100 | 2 | 2 |
| 2025-04-02 | Apple | 200 | 2 | 1 |
| 2025-04-02 | Apple | 100 | 2 | 1 |
STEP4:フィルタ
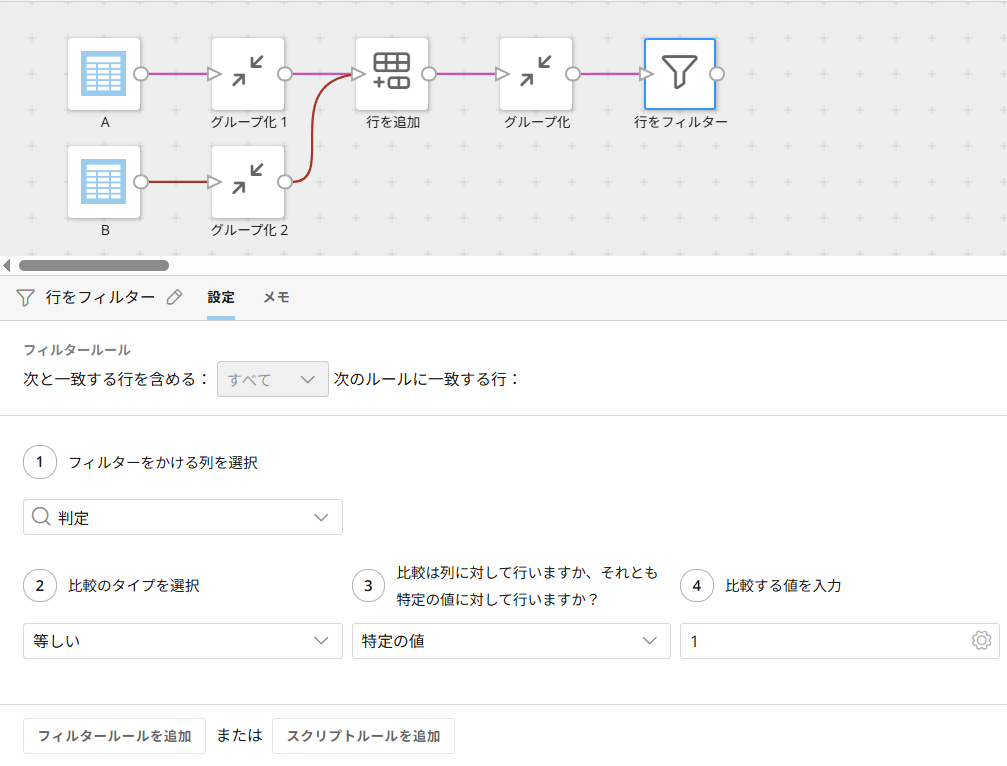
「フィルタ」を使い、グループ化で作成した集計列(今回は判定という列名)を選択、値=1でフィルタをかけます。
判定=1が発生した場合、一方のDatasetにしか存在しないデータと言えるため、2つのDatasetは完全一致ではないと判断できます。
今回の例では、2行該当するためAとBはデータが重複していないと判定できます。
| date | item | sales | カウント | 判定 |
|---|---|---|---|---|
| 2025-04-02 | Apple | 200 | 2 | 1 |
| 2025-04-02 | Apple | 100 | 2 | 1 |
STEP5:出力(完成)
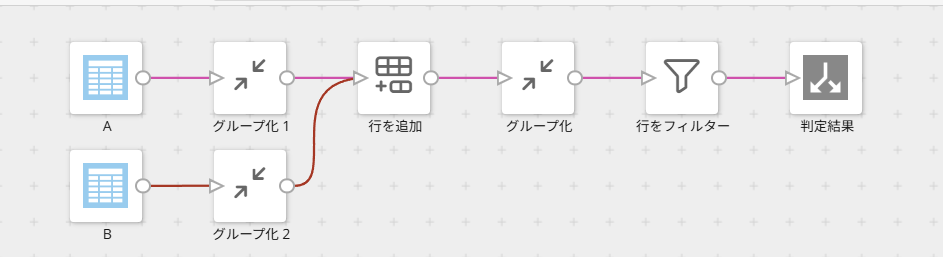
最後にDatasetを出力します。
出力結果が0行であれば、比較した2つのDatasetは行×列のレベルで完全一致と言えます。
出力結果が1行以上あった場合は、2つのデータセットの中身が異なることを示します。
結果が0行であることを確認できれば、残す方のDatasetにbeastmodeの複製も忘れずに行ってください。(これを失念するとDataset切替時にカードへの影響が出てしまいます)
削除する方のDatasetで使用されているカードやDataflowの切替を全て終えれば、安心してDatasetの削除が行えるのではないかと思います。
また、SQLが苦手な方でもこの手順なら比較的簡単に実施できるのではと考えます。
まとめ
重複Dataset発生の予防と、発生時の対応について紹介しました。
データ利用の原則に、Single Source of Truthという概念があります。
重複したデータが増えることは、データによる意思決定が鈍るリスクに繋がるため、適切な管理でリスクを取り除くことが重要です。
データの重複に立ち向かう手段の一助になれば幸いです。