Dockerベースで手軽に便利なスクレイピング環境を構築する手順をまとめました。
Selenium on DockerやGKEのサンプルとしてもどうぞ。
GitHub : https://github.com/nullnull/scraping_sample
この記事でできるようになること
- 本番環境(GKE)でスクレイピングのスクリプトを定期実行
- スクレイピングを実行中のSelenium(Chromeブラウザ)の様子をVNCで監視(本番/開発)
- スクレイピング結果をSlack通知(本番/開発)
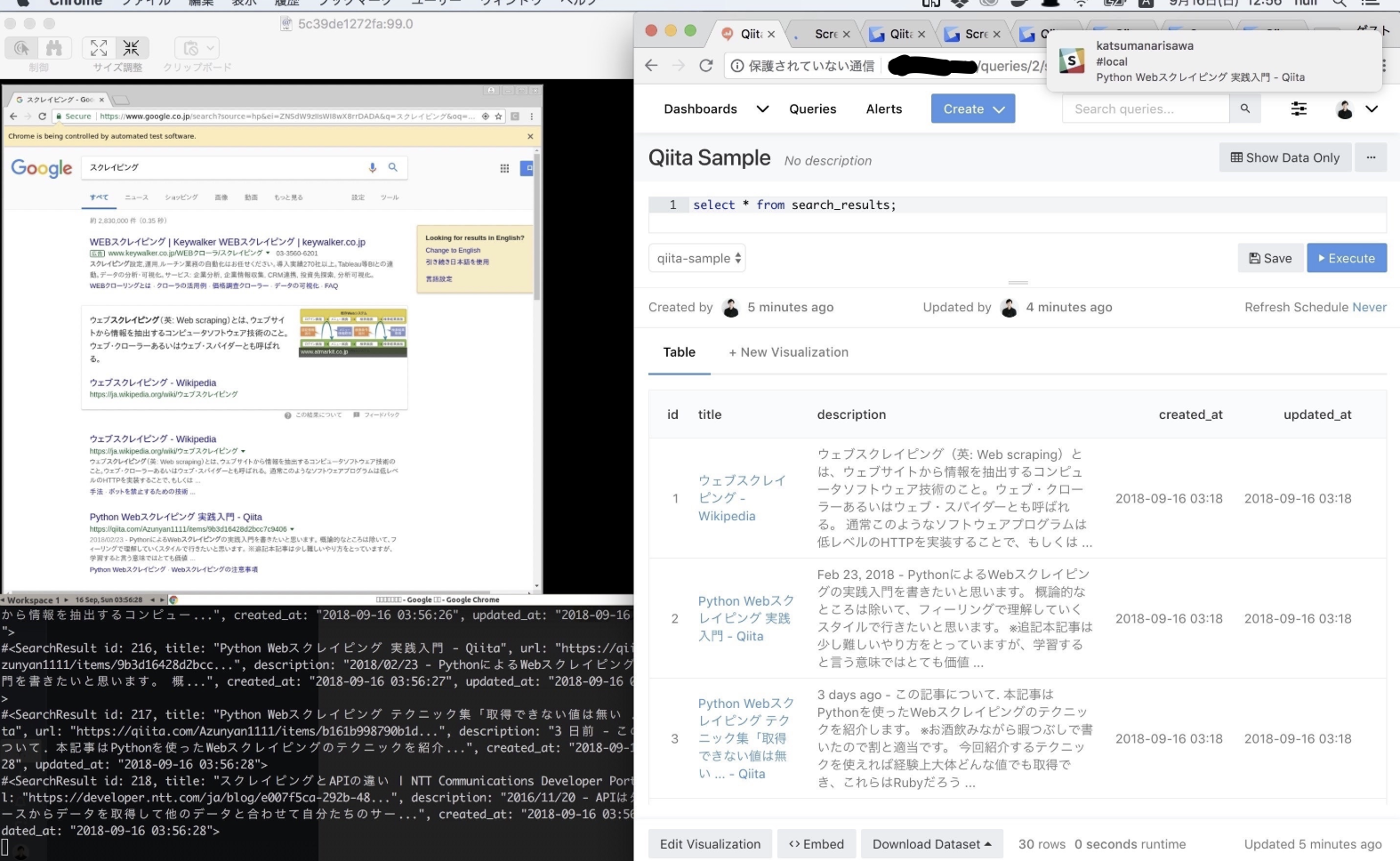
- スクレイピング結果をRedashでビジュアライズ(本番)
環境構築にかかるコマンドは数回だけで、スクリーンショットのように動作を確認しながら開発を行うことができます。(左がVNCを通したChromeブラウザ、右がRedash)
この記事で説明しないこと
- スクレイピングのコードそのものの説明
そもそもスクレイピングをした事がない方は、まず他の記事を参考にお願いします。
使用技術
- Ruby (ここはお好みで)
- Selenium (+Google Chrome)
- Docker
- GKE(Google Kubernetes Engine)
- Cloud SQL
- Container Registry
- (Optional) Redash on GCE
動作確認環境 : macOS High Sierra / v10.13.6
前提条件
開発環境でのスクレイピング
開発環境でも動作は同じなので、サーバー上で定期実行したいというわけではなく、手元で実行できれば十分…という場合はこれだけで準備完了です。
本番環境でのスクレイピング
- GKEプロジェクトの作成
- Cloud SQLの有効化
- Container Registryの有効化
スクレイピングの前に
著作権の勉強、対象サービスの利用規約をよく読むなどして、迷惑にならないスクレイピングをしましょう。
開発環境のセットアップ
git clone git@github.com:nullnull/scraping_sample.git
cd scraping_sample
docker-compose build
docker-compose run scraper sh setup.sh
これで終わりです。
slack通知をONにしたい場合は、docker-compose.yml の SLACK_WEBHOOK_URL にwebhookのURLを入れてください。
グーグルの検索結果を取得するサンプルを以下で動かせるようになっています。
docker-compose run scraper bundle exec ruby app/fetch_search_results.rb
# ※2018/09/16現在で動作を確認していますが、グーグルのhtmlが書き換わった場合は動作しなくなります。その場合は、サンプルコードのセレクタを編集してください。
実行中のChromeブラウザを確認したい場合は、以下コマンドを実行してください。
open vnc://localhost:5900/
# ウィンドウがでてきてパスワードを聞かれたら、secretと入力
本番環境のセットアップ
Cloud SQL
コンソール上で scraping-sample というインスタンスを作ってください。
(文字コードは utf8mb4, ciは utf8mb4_bin あたりを推奨)
その後、手元の開発環境で、プロキシユーザの作成とsecretへの登録をしましょう。
gcloud sql users create proxyuser --host cloudsqlproxy~% --instance=your-cloud-sql-instance --password=your-password
kubectl create secret generic cloudsql-db-credentials --from-literal=username=proxyuser --from-literal=password=your-password
# サービスアカウントのcredentials.jsonを登録
# IAMと管理 > サービス アカウントより、サービスアカウントを作成し、秘密鍵をDLし、以下のように指定する
kubectl create secret generic cloudsql-instance-credentials --from-file=credentials.json=/Users/null/Downloads/hoge-pjt-05beca437353.json
その他のセットアップ
-
kube/*.ymlやscripts/*.shに書いてあるyour-project-nameを、GCPのプロジェクト名に変更 -
kube/*.ymlのyour-cloud-sql-instanceをCloud SQLのインスタンス名に変更 - slack通知をONにしたい場合は、
kube/cronjob.yml,kube/deploy.ymlのSLACK_WEBHOOK_URLにwebhookのURLを入れる
上記とGKEのセットアップを終えていれば sh scripts/cronjob.sh でデプロイが完了します。デフォルトだと1分毎にスクレイピングが行われます。
※GKE周りの設定で自信がない方はこちらを参考にしてください。
本番環境で動いているChromeブラウザの動作確認をしたい場合は、k8sにはクラスタ内のpodのポートをローカルマシン側にバインドできるという神機能があるので、これを使って開発環境と同じように確認ができます。
kubectl get pods # podのidを確認
kubectl port-forward pod/<pod-id> 5900 5900
open vnc://localhost:5900/
(Option) Redashのセットアップ
Redashを使うと、手軽にスクレイピング結果のビジュアライズができるので、動作確認にぜひ使ってみてください。GCE上で動かす場合のコマンドは以下です。
$ gcloud compute images create "redash-2-0-0" --source-uri gs://redash-images/redash.2.0.0.b2990.tar.gz
$ gcloud compute instances create redash \
--image redash-2-0-0 --scopes storage-ro,bigquery \
--machine-type g1-small --zone asia-east1-a
# ここまでやったら、あとはGCEのGUIコンソールを開いて、以下を行ってください
# 1. 編集 > ファイアーウォールの設定 > httpアクセスの許可
# 2. VPCネットワーク > 外部IPアドレス > タイプ > 静的
# 3. SSLの設定やDNSの設定(面倒なので省略)
詳しくはこちらをどうぞ。
※Metabaseの方がdockerイメージ一発で起動できたり便利なのですが、Redashは特にv4より画像URLのSQL結果を画像として表示したり、URLをリンクとして表示したり、GUIでのフィルタやソートの機能が充実していたり…と大分リッチになったので、Redashがオススメです。
サンプルスクリプトの補足
スクリプトそのものについては、コードをご自身でお読みください。
standalone-chrome-debug
開発/本番環境ともに、seleniumを動かすのに selenium/standalone-chrome-debug というDockerイメージを使用しています。イメージを起動するだけでselenium + chrome + vncの環境が整う優れものなイメージです。
スクレイピングを行うrubyのコンテナからは、以下のようにしてseleniumのコンテナにアクセスします。
chrome_capabilities = Selenium::WebDriver::Remote::Capabilities.chrome
@driver = Selenium::WebDriver.for(
:remote,
url: "http://selenium-server:4444/wd/hub",
desired_capabilities: chrome_capabilities
)
ActiveRecord
データの保存にはmysqlを、ORMには使い慣れているActiveRecordを使用しました。スクレイピングしたい情報がどんどん変わるような場合は、NoSQLを使ったりすると良いのかも。
おわりに
dockerやk8sを使ったスクレイピング環境の説明記事があまりないようだったので、知り合いの作業を手伝うついでに書いてみました。リッチなスクレイピング環境をポータブルに構築できて便利ですね。
DockerやGKEの最初の学習コストがそこそこにかかるので、初心者には勧めづらいですが、とはいえチュートリアルを終わらせてセットアップを完了するのにはそこまで時間はかからないので、ぜひチャレンジしてみてください。