本記事はFringe81 アドベントカレンダー2017の6日目の投稿で、こちらの記事をQiita向けに書き直したものです。
2017/10/30まで開催されていたDeepAnalytics主催のレコメンドエンジン作成コンテストに参加し、見事優勝することができました。
今回はそのとき役に立ったデータ分析のテクニックを紹介します。
参加したコンテスト: オプトDSL・DeepAnalyticsコンテスト『レコメンドエンジン作成チャレンジコンテスト』
コンテストについて
今回のコンテストでは、オプト社が提供する2017年4月の行動履歴から、2017年5月1週目においてユーザーが関心を示す商品を予測して、その精度を競います。
行動履歴には人材、旅行、不動産、アパレルと異なる4業種が与えられ、それぞれ個別にモデリングをします。
ユーザの行動は、CV、クリック、ページ閲覧、カートに入れるの4種類のevent_typeがあり、各履歴にはタイムスタンプがついています。
予測精度の評価は、ランキング問題ではおなじみのnDCG(normalized discounted cumulative gain)が使用され、閲覧=1点、クリック=2点、CV=3点として計算されます。
精度を上げるための工夫
今回作成したレコメンドエンジンの精度を上げるのにした工夫は以下の3点です。
- 特徴量大量生産の仕組み
- 最近の行動をより重要視
- 最後の最後にアンサンブル
特徴量大量生産の仕組み
まず、他の参加者との一番の差になったのはおそらく特徴量を大量生産できたことだと思います。
本コンテストに限った話ではありませんが、基本的に予測タスクを解くときは1特徴量=1Featureクラスとして定義しています。
今回の問題におけるイメージは以下の図のようになります。
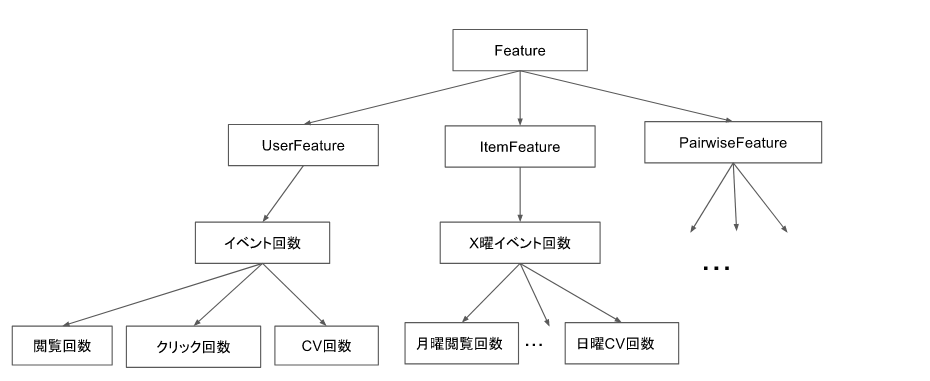
特徴量を作っていくと、作成過程で似たような処理がよく出てくることがあります。
例えば、ユーザの"閲覧"回数と"クリック"回数は、集計対象のevent_typeが異なるだけで、回数集計する処理は共通化できるはずです。
また、X曜日のイベント回数となると、掛け合わせが7曜日×4イベント種類=28パターンにもなるので、それをベタ書きしていくのはかなり辛いです。
そこで上図のように共通化できる処理は抽象クラスを設けてそこに記述することで、実特徴量クラスでは属性だけを指定すればよくなり、格段に特徴量定義の手間を抑えることができる上に、テストも楽に書くことができます。
また他の工夫としては、特徴量のクラス名を日本語で定義したことです。
日本語特徴量名を採用した理由は以下の3点です。
- 良い英名を考える時間が無駄
- 日本語の方が情報密度が高いので特徴量名を短く的確に表現しやすい
- Python3では識別子にUnicodeが使える
コード内に日本語が入るのは気持ち悪い感じもしますが、名前を考えるのが億劫になって特徴量が作れなくなるよりはマシなんじゃないかと思います。
こうした工夫の結果、最終的に約400個もの特徴量を作成することができました。
最近の行動をより重要視
レコメンドエンジンでユーザのある商品についての興味を示す指標としてその商品に対する閲覧回数やクリック数がすぐに思いつくかと思います。
しかし、単純に閲覧回数やクリック回数のように時間軸を無視して集約してしまうと、「いつ行動したのか?」という情報が潰れてしまいます。
ユーザの関心や需要は時間ともに変化するはずなので、3日前の閲覧1回と30日前の閲覧1回は3日前の閲覧1回の方が価値が高いということが予想されます。
その直感を特徴量に落とし込むために、減衰率をrとして、X日前の行動の重みW(X)を指数関数で以下のように定量化しました。
W(X) = r^X \ \ (0 < r < 1)
減衰率rを変化させたときの過去1〜30日前の重みは以下の図のようになります。
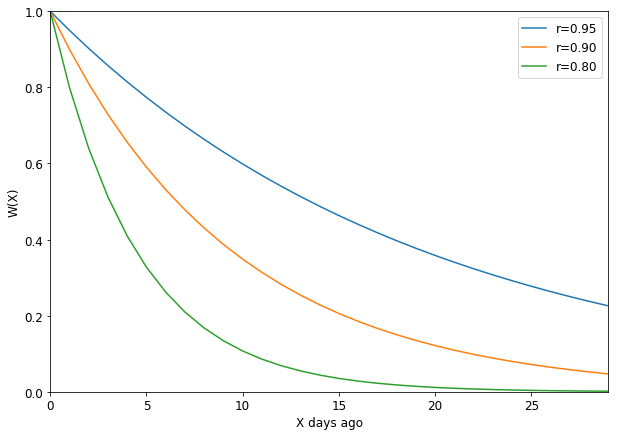
回数の合計値を計算するときに、減衰関数で計算した重みを掛けることによって、最近の行動を強調できるようになります。
減衰率は複数の設定を変えたものを別の特徴量として追加していき、結果として時間減衰に関わる特徴量だけでも80個近い個数になりました。
この特徴量は締め切り2日前に追加して、1ヶ月近く超えられなかったnDCG=0.27の壁を突破する鍵となりました。
最後の最後にアンサンブル
集団(アンサンブル)学習は複数の学習モデルを組み合わせて強力な1つのモデルを構築する手法です。
アンサンブル学習はコンテストで勝つためには必須と言っても過言ではない強い手法ですが、モデルの訓練に時間がかかるというデメリットがあります。
約2ヶ月という制限時間の中で精度を競うのには、実験サイクルの回転効率は競争力を上げるための重要な要素となるため、早々からアンサンブル学習に手を出すのは筋が良くないだろうと考えていました。
そこで今回のコンペでは、データの前処理方法や特徴量追加などオリジナリティが出る部分での実験の効率を上げるため、締め切り2日前までは線形モデルの1種であるElasticNetと中間層1層のシンプルなニューラルネットを予測モデルとして採用していました。
その結果、最終日まで精度を伸ばし続けることができて、2位以下に大きな差をつけて勝つことができました。
ちなみに最終的にはGBDTを予測モデルとして採用しました。
GBDTの学習自体はxgboostやlightgbmなどの洗練された実装があるので高速ですが、パラメータチューニングまで含めると線形モデルに比べて時間がかかるため、正しい選択だったと思います。
感想
初めてのデータ分析コンテストの参加でしたが、真面目にやると結構時間が取られてしまい、いかに効率的なPDCAの仕組みをつくるかが大事だなと感じました。
コンテストを掛け持ちで参加して上位にランクインしている参加者の人たちは本当にすごいですね…。
今度はKaggleで世界のデータサイエンティストたちと勝負してみたいと思います。