はじめに
この記事はNuco Advent Calendar 2022の5日目の記事です
対象読者
Pythonが注目されている理由のひとつは機械学習プロジェクトの主要な開発言語であるからといってもよいでしょう。多くの企業の業務システムのAIの開発言語はPythonです。そんなPythonの学習を始めてある程度文法の理解が進んできて、機械学習に触れてみたい方を対象にしています。
- Pythonの基本文法を理解している
- 機械学習を始めてみたい
チュートリアル概要
Pythonは長年機械学習で使用されているので、ライブラリも豊富にあります。本記事では機械学習用ライブラリのscikit-learn(サイキット・ラーン)を使用して教師あり学習を行い住宅価格を予測してみます。
何ができるようになるか
機械学習で使われる基本的な用語を理解し、学習の全体像をつかめるようになります。
機械学習の目的
機械学習とは
機械学習を始めようとするとAI、機械学習、ディープラーニングというワードを目にすると思います。まず、混合しがちなこれらの違いから説明すると、AI(人工知能)が最も広義の概念となります。機械学習はAIに含まれ、ディープラーニングもまたAIの一部であり、機械学習のアルゴリズムの1つでもあります。
集合で表現すると以下のようになります。
AI \supset 機械学習 \supset ディープラーニング
- AI
AIの研究の歴史は古く1950年代から始まってます。AIは知的な機械、特に、知的なコンピュータプログラムを作る科学と技術と言い表されるように、概念として広い定義がなされています。 - 機械学習
機械学習は、AIに内包され、特定のタスクをトレーニングにより機械に実行させるものです。
機械学習は入力と出力の関係性を見つけることを目的としています。この関係性を見つける手法(アルゴリズム)は様々あり、その中の一つとして、今回学習する回帰であったり、ディープラーニングがあります。実用化されている例では、顔画像からそれが誰であるかを判定する顔認証や車の自動運転などがあります。 - ディープラーニング
ディープラーニングとは、ニューラルネットワークという脳の神経回路の一部を模した数理モデルを多層に結合して表現・学習能力を高めた多層ニューラルネットワーク(ディープニューラルネットワーク)を用いる機械学習の一手法です。理論自体は数十年前からありましたが、学習を高速化させる手法の発見や、コンピュータの計算能力が向上したことで、近年になって様々な分野で実用化が進んでいます。
モデル
「モデル」とは、機械学習において、入力データに対して結果(=出力)を導き出す仕組みのことです。モデルは、入力されたデータを解析し、評価・判定を行った結果を出力として返します。ここでモデルが受け取る入力データや、結果の出力は機械学習の用途によって様々です。
例えば、写真を分類するモデルを考えてみます。モデルに写真の画像データを入力すると、モデルはその画像が何の画像であるかを評価・判定し、「猫」「犬」など写真の種類の判定を出力します。また、期待通りの出力を得るためには、事前にモデルを十分にトレーニングしておく必要があります。モデルに大量のサンプルの画像データを学習させて、画像データをどのように解釈すれば正しく分類できるのかを覚えさせます。
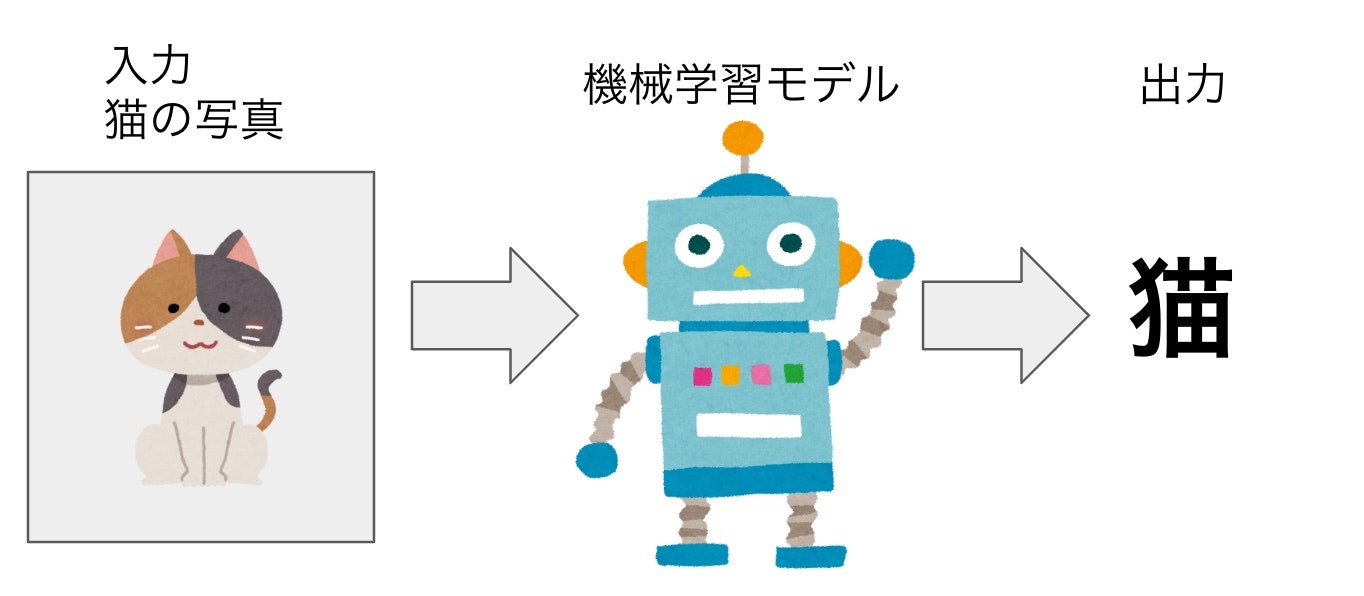
データセット
データセットとは、モデルが学習するために使われるデータの集合体です。今回紹介する教師あり学習に関して言えば、入力データとそれが何かを表すラベルがセットになったデータが集まったものという理解で十分かと思います。入力データの部分は学習タスクによってテキストであったり、画像や動画、音声や音楽などの場合もあります。
教師あり学習・教師なし学習・強化学習
機械学習は学習の方法から、「教師あり学習」「教師なし学習」「強化学習」の3つの枠組みに分けることができます。この章では、それぞれの学習方法を解説します。
教師あり学習
基本的な学習手法である教師あり学習とは何かを解説します。本記事のチュートリアルで用いる手法です。
教師あり学習は文字通り、正解がわかっているデータを教師としてモデルの学習を行う手法です。
前述のモデルの説明で用いた写真を分類するモデルの例で言えば、動物の写真とその写真に映っている動物が何であるか(ラベルといいます)を学習し、どのような写真が「猫」、「犬」または「馬」などどの動物であるかを出力するモデルを作る、というような手法です。
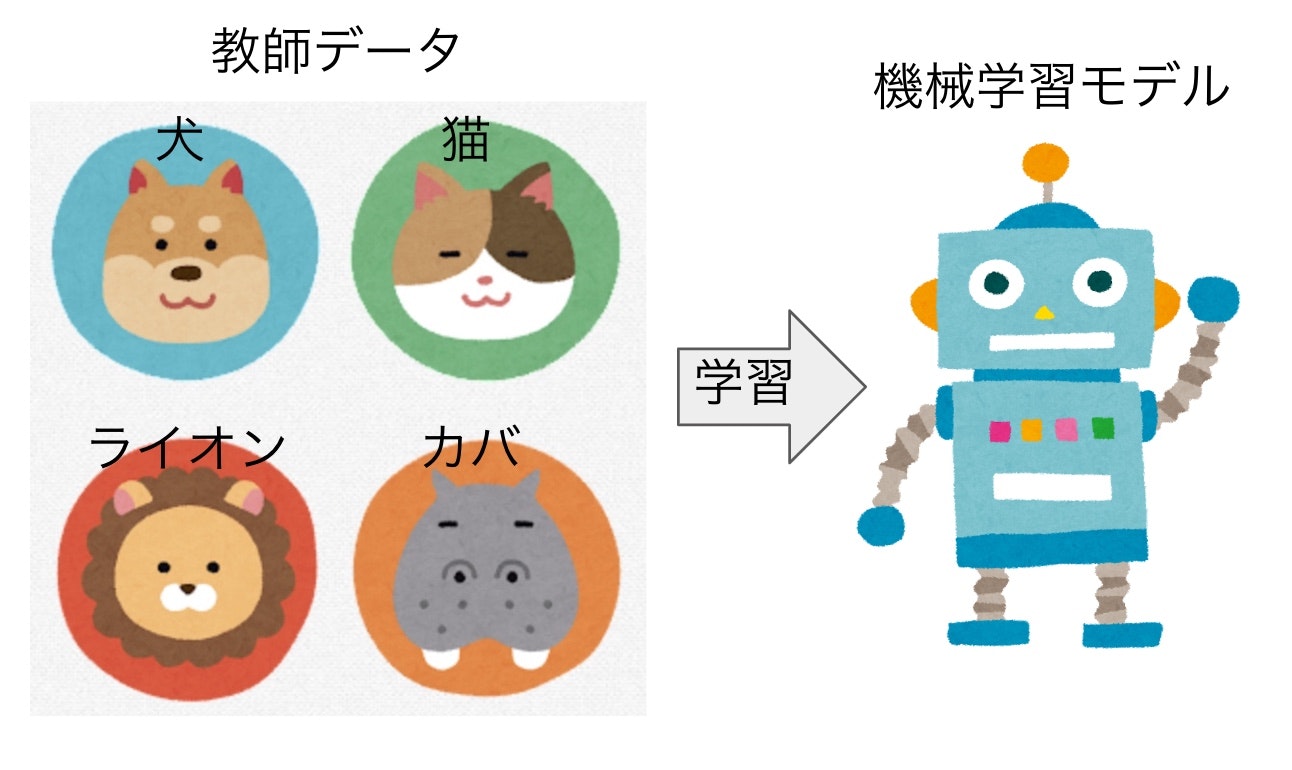
学習がうまく行っていると、動物の写真がどの動物かを出力できます。ただし教師データのラベルになかった動物は出力できません。

教師あり学習は、例に挙げた分類と回帰の問題に分けることができます。
分類
分類問題の目的は入力データが所属するカテゴリを予測することです。特に、YES or NOのように予測対象のカテゴリ数が2つの場合二値分類と呼びます。例えば、電子メールがスパムであるか、スパムでないかを予測する問題があります。
回帰
回帰の主な目的は、連続する値の傾向をもとに値の予測を行うことです。具体的な活用例では、企業がサービスの広告費用の増額を検討する際に、「広告費を増やすことでどのくらいの売上を見込めるか?」を予測する際に使われます。 次の章から始まる機械学習の実装では回帰の例を紹介します。
教師なし学習
教師なし学習とは、学習データに正解を与えない状態で学習させる手法です。たとえば大量のメールを教師なし学習で学習すると、文章の特徴が似ているか否かを導きグループ分けできます。
教師あり学習のように、メールが通常メールか迷惑メールかというような正解を与えて学習するわけではないため、そのグループがなにを示すのかは人が解釈する必要があります。
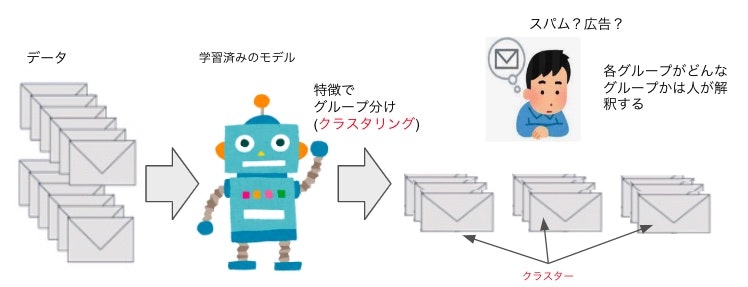
このように大量に集められたデータから、特徴が近い(似ている)データを集めて集団に分けることをクラスタリング、分けられたデータの集団をクラスターと呼びます。
強化学習
強化学習とは、試行錯誤を通じて目的として設定された報酬(スコア)を最大化するような行動を学習する手法です。
教師あり学習とよく似た問題設定ですが、与えられた正解の出力をそのまま学習すれば良いわけではなく、もっと広い意味でスコアを最大化する行動を学習しなければなりません。
例えば、テトリスでできるだけ高スコアを得るような問題は強化学習の枠組みで考えることができます。その時点で一番スコアが高くなるのは、一列でもすぐに消すようなプレイ方法ですが、より長期的には、できるだけブロックを溜めてから一度にたくさんの列を消したほうがスコアが高くなります。
将棋AI・囲碁AIといったゲームAIが打ち手を学習する際や、自動運転における状況判断の学習に活用されています。
機械学習の実装
全体の流れを確認
実装の流れは大きく以下の5ステップです
- データを取得する(データセットの準備)
- 訓練用データとテスト用データに分ける
- 学習用アルゴリズムを呼び出す
- 訓練用データを学習用アルゴリズムで機械学習
- 結果を確認する
実装にはGoogleColaboratory(以下Google Colab)を使用します。Google ColabとはGoogle社が無料で提供している機械学習の教育や研究用の開発環境です。開発環境はJupyter Notebookに似たインターフェースを持ち、Pythonの主要なライブラリがプリインストールされています。
- ノートブックの作成方法
GoogleDriveの「新規」→「Google Colaboratory」の順で選択していき、下の画像の画面になれば準備完了です。説明中に出てくるコードを入力・実行すると結果を確認しながら読みすすめることができます。
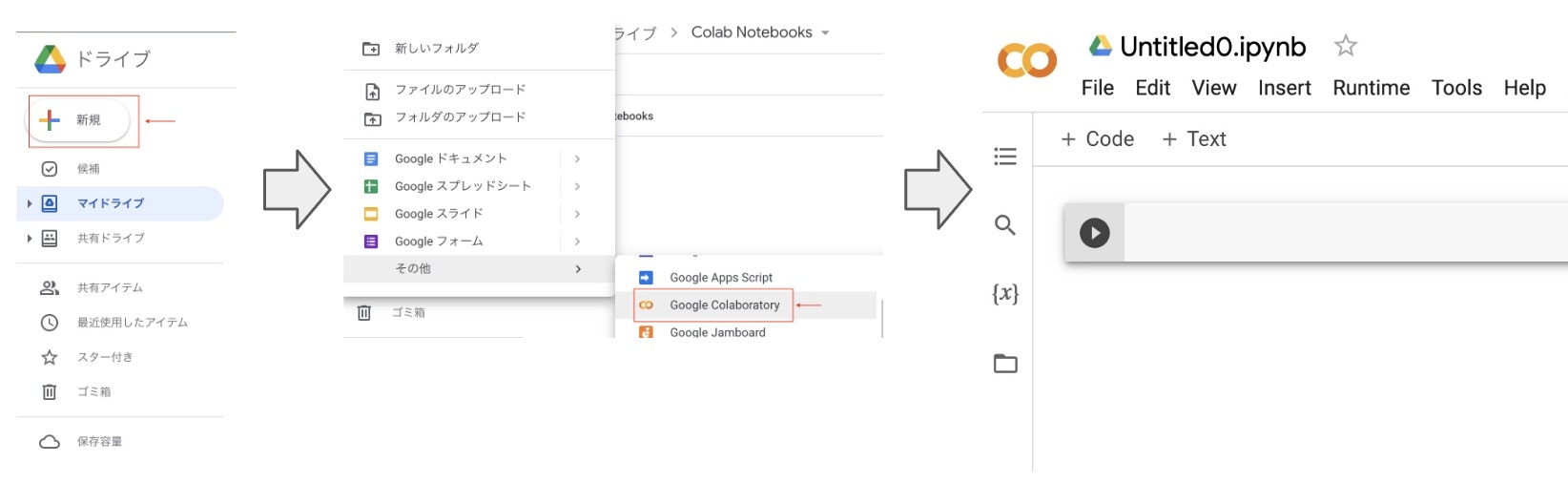
- コードの実行方法
- コードセルにコードを入力
- セル左の▶をクリックまたはShift+Enter(シフトキーを押しながらEnterキー)で実行
- 実行結果が出力される

ここまでの操作方法がわからない方は次のリンクから操作方法を学んでみてください。
Colaboratoryへようこそ
scikit-learn(sklearn)とは
scikit-learnはPythonのオープンソース機械学習ライブラリです。 様々な機械学習の手法が統一的なインターフェースで利用できるようになっています。scikit-learnではNumPyのndarrayでデータやパラメータを取り扱うため、他のライブラリとの連携もしやすくなっています。
本章では、この scikit-learnを用いて、データを使ってモデルを訓練し、評価するという一連の流れを解説します。
使用するデータセットを概観する
まずはデータセットを準備します。scikit-learnで試すことができるデータセットの1つのカリフォルニア住宅価格をダウンロードします。また、今回使用する全てのライブラリをインポートしておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
# カリフォルニア住宅価格のデータセット
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
df = pd.DataFrame(housing.data, columns=housing.feature_names)
df['Price'] = housing.target
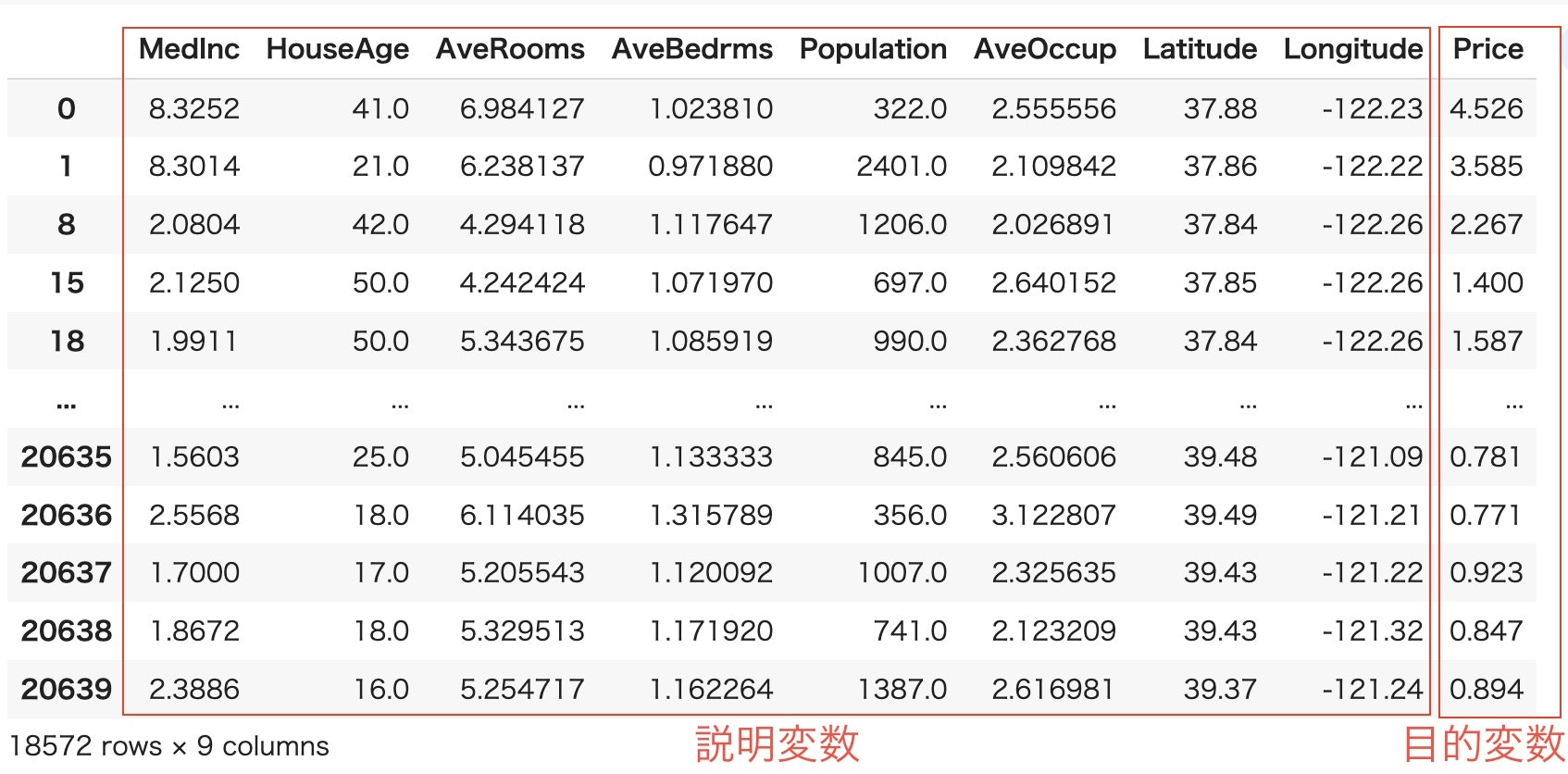
df.head()
実行するとこのような表が出力されます。

このデータセットは各行が「個別の家の値」ではなく「国勢調査のブロックグループごとにまとめた値(中央値や総数など)」になっていることに注意が必要です。ブロックグループとは、米国国勢調査局が1つの標本データとして扱う「最小の地理的単位」のことです。
| 項目 | 説明 |
|---|---|
| MedInc(median income) | 各ブロックグループ内にある世帯ごとの「所得」の中央値。 |
| HouseAge(median house age) | ブロックグループの「築年数」の中央値 |
| AveRooms(avarage number of rooms) | 各ブロックグループ内にある世帯ごとの「部屋数」の平均値(=1世帯当たりの部屋数。) |
| AveBedrms(avarage number of bedrooms) | 各ブロックグループ内にある世帯ごとの「寝室数」の平均値(=1世帯当たりの寝室数。) |
| Population | ブロックグループの「人口」(=居住する人の総数) |
| AveOccup(average occupancy rate) | 各ブロックグループ内にある世帯ごとの「世帯人数」の平均値(=1世帯当たりの世帯人数。) |
| Latitude | ブロックグループの中心点の「緯度」。値が+方向に大きいほど、そのブロックグループは北にある |
| Longitude | ブロックグループの中心点の「経度」。値が-方向に大きいほど、そのブロックグループは西にある |
| Price | 「住宅価格」の中央値。単位は10万ドル。通常はこの数値が目的変数として使われる |
今回のタスクは、各ブロックに当たる住宅価格の中央値を予測することです。不動産屋が予測された住宅価格の中央値を元に、そのブロックへ投資すべきかを判断する場面を想像してください。正確に予測できるモデルを用意できれば不動産屋の利益を増やすことにつながるでしょう。
データの中身を見てみます。欠損値(NaN)が含まれていると、機械学習モデルでは学習できないので取り除く必要があります。
pandasデータフレームのinfo()を使うと、データの総数、各属性に対する総数、データのタイプを確認することができます。
df.info()
実行すると以下の出力が得られます。データの数は20640個あり、それぞれの属性も同じ数だけあることが分かるので、欠損値は含まれていないことが分かります。そしてfloat型、つまり全ての属性は数値データとなっています。

次に各属性の統計値を確認します。
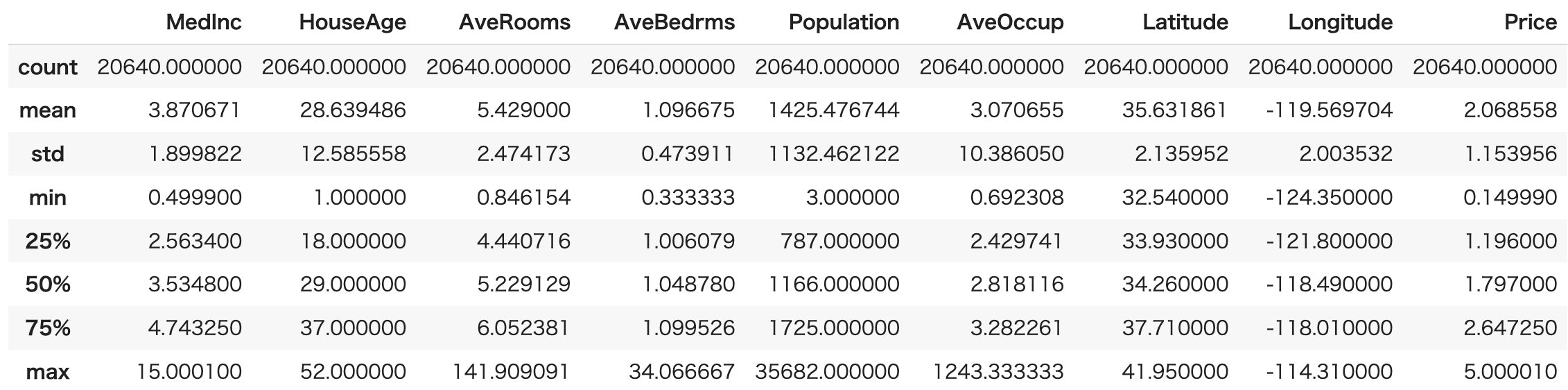
統計値を見ることによって、それぞれにどのような特徴があるのか感覚的に掴むことができます。pandasデータフレームのdescribe()を使うと統計値を一覧で見ることができます。
df.describe()
実行すると以下の表が出力されます。
- count: データ数
- mean: 平均値
- std: 標準偏差
- min: 最小値
- 25%: 第1四分位数
- 50%: 第2四分位数
- 75%: 第3四分位数
- max: 最大値
ヒストグラムにしてデータを可視化してみます。
df.hist(bins=50, figsize=(15, 13))
plt.show()
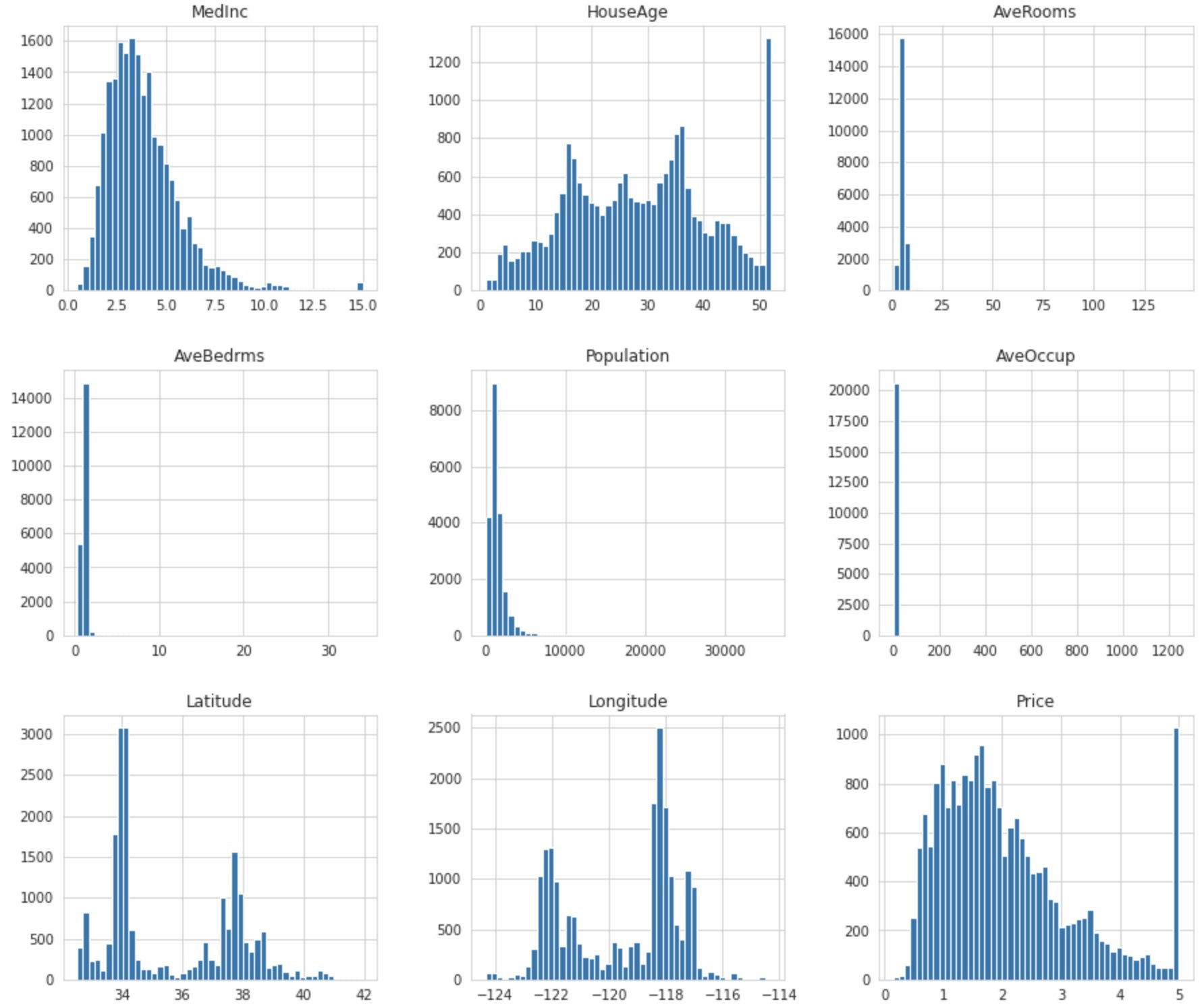
MedInc(所得中央値)、AveBedrms(平均寝室数)、AveOccup(平均世帯人数)、AveRooms(平均部屋数)、Population(人口)のグラフに注目してみると、右側が大きく開いているのが見て取れます。
そしてHouseAge(築年数)とPrice(住宅価格)では最大値の数が不自然なまでに多くなっています。このような値を外れ値といい、機械学習モデルに悪い影響を与えることがあるので、後のデータの前処理の段階ではこの外れ値を取り除く処理を行います。
次に属性間の相関関係を見てみます。
pandasデータフレームのcorr()を使います。
df.corr()
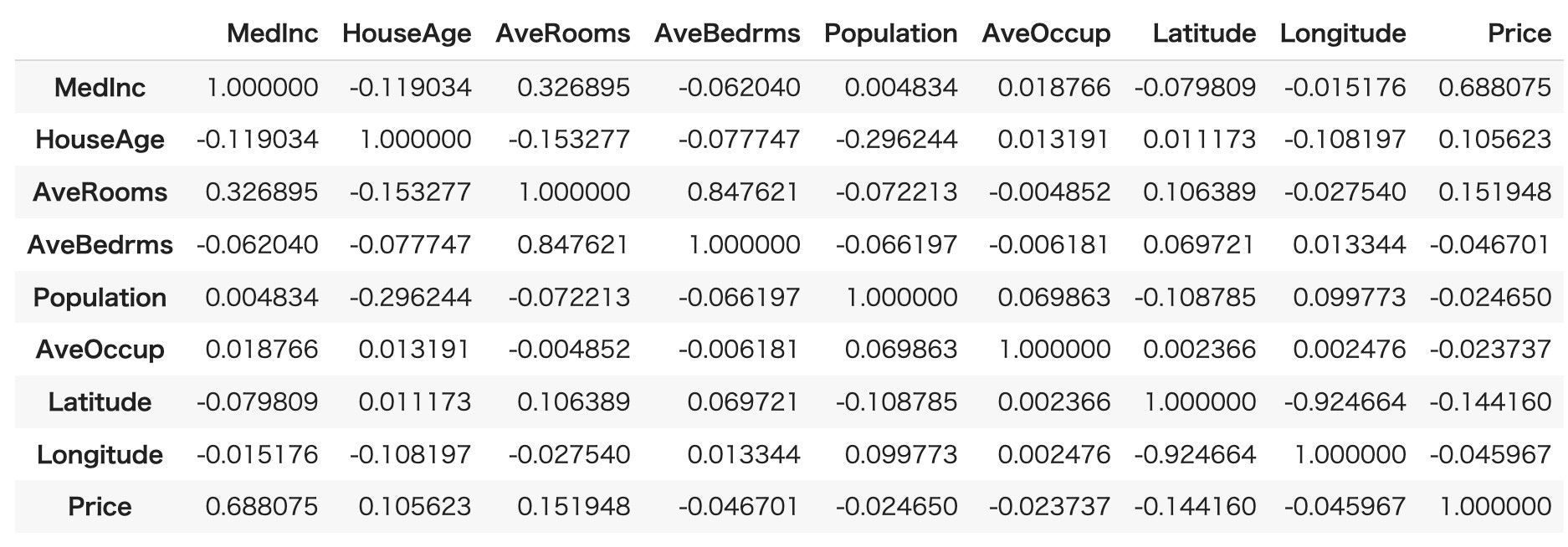
値がプラスの1に近ければ正の相関、マイナスの1に近ければ負の相関、0に近ければ相関が低くなります。
今回モデルが予測するPrice属性を軸に関係性を見ることによって、各属性に対しての影響度合いを知ることができます。
データの前処理
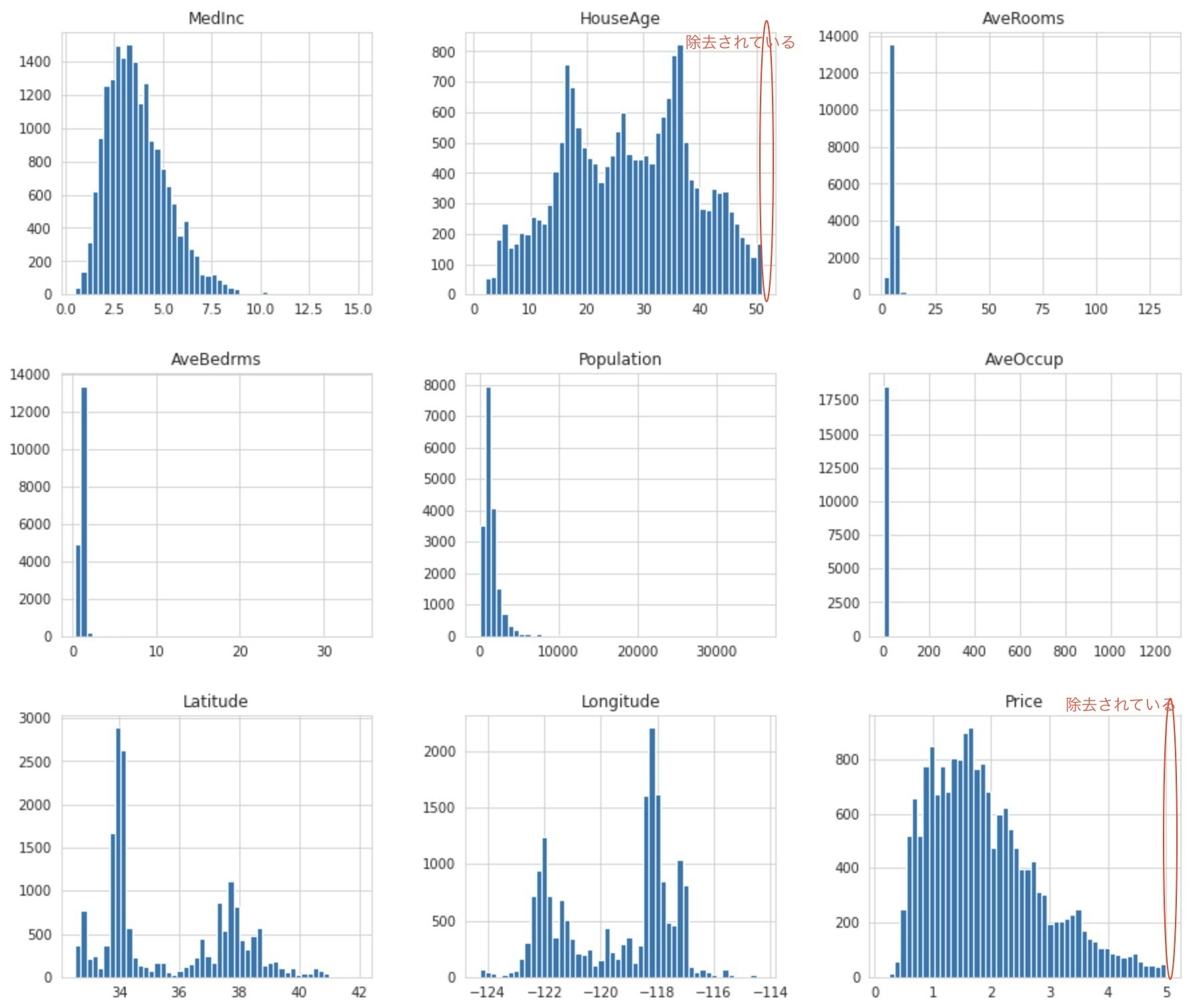
HouseAge(築年数)とPrice(住宅価格)の最大値に不自然な数のデータがあることが確認できたので、モデル作成に悪影響を及ぼしてしまいます。なので、まず、こういったデータを除去します。
df = df[df['HouseAge'] < df['HouseAge'].max()]
df = df[df['Price'] < df['Price'].max()]
データをinfo()で確認すると、データ数が減っていて除去されていることが確認できます。
df.info()

ヒストグラムにしてデータを可視化してみても、HouseAge(築年数)とPrice(住宅価格)の最大値にあった不自然な数のデータが除去されていることが確認できます。
df.hist(bins=50, figsize=(15, 13))
plt.show()
データを訓練データ・テストデータに分割
モデルの学習を行う前に、下準備をします。まずカリフォルニア住宅価格のデータフレームを説明変数Xと目的変数yに分割します。
一旦、説明変数と目的変数について説明します。
- 説明変数とは結果に影響を与えている要因を意味します。
- 目的変数とは要因から影響を受けて起きた結果を意味します。
例えば、「年齢」(要因)から「年収」(結果)を予測したい場合は「年齢」を説明変数に,「年収」を目的変数にします。
今回のカリフォルニア住宅価格の例だと、MedInc〜Longitudeが説明変数、Priceが目的変数になります。
データフレームを説明変数Xと目的変数yに分割するコードです。
# 説明変数
X = df.drop(['Price'], axis=1)
# 目的変数
y = df['Price']
次は説明変数Xに対して、標準化を行います。
標準化は、平均を0、分散を1にしてデータの散らばり具合を縮小させます。これによって範囲の異なるそれぞれの変数を同様に扱うことが可能になります。こちらは、scikit-learnのStandardScalerで実装します。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
#標準化
X = scaler.fit_transform(X)
ここからは、データセットを訓練データ、テストデータとなるように機械学習の精度を評価するために分割していきます。
scikit-learnのtrain_test_splitを使って分割します。訓練データとテストデータを8対2の割合で分割します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
print(X_train.shape, X_test.shape)
出力から8対2に分けられていることが確認できます。
# 出力
(14857, 8) (3715, 8)
学習
それでは準備が整ったので、さっそく訓練を行っていきます。
今回使用する機械学習モデルは、モデルの中で最も単純なアルゴリズムである線形回帰の正規方程式です。
モデルクラスLinearRegressionをインポートしモデルを初期化します。初期化されたモデルのfit()引数に訓練データを与えて、学習を開始します。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
学習後のモデルがどうなっているかを見てみます。
print(model.intercept_)
print(model.coef_)
#出力
1.8964579610625685
[ 0.67460487 0.05781326 -0.25591254 0.27658163 -0.00491303 -0.03601714
-0.79234518 -0.75099038]
intercept_の1.89645に当たる部分がバイアス項や切片項と呼ばれ、coef_の配列データは各属性の重みである係数となります。
今回使用したLinearRegressionは下式で表される重回帰式を求めるクラスで、intercept_が $w_0、 $coef_配列の各値は$w_1$~$w_n$に相当します。また、$y$は予測したい目的変数Price(住宅価格)、$x_1$~$x_n$は説明変数MedInc〜Longitudeに相当します。
$$ y = w_0 + w_1 x_1 + \cdots + w_nx_n \qquad $$
試しに訓練データの一部を入力して見ます。モデルに入力して目的変数を予測させるにはpredict()を使います。 y_someが正解の値で、X_someを入力して得られる予測値との比較用に表示します。X_some = X_train[:4]
y_some = y_train[:4]
print(f'予測結果{np.round(model.predict(X_some), 3)}')
print(f'正解ラベル{list(y_some)}')
予測結果[1.547 3.661 2.145 0.709]
正解ラベル[3.313, 2.962, 2.158, 0.771]
正解ラベルと比べると、それとなく正解に近い値を出していることが分かります。
ここでは学習に使った訓練データを入力しているので、次の章では学習に使用していないテストデータを入力した場合と比較してモデルの性能を評価していきます。
性能評価
回帰モデルの評価方法
改めて学習させたした回帰モデルのタスクを確認します。タスクは、各ブロックに当たる住宅価格の中央値を予測することでした。なので、モデルが出力した住宅価格の予測値と実際の住宅価格が近ければ近いほど性能の良いモデルだと言えます。予測値と実際の値の差を誤差といい、回帰ではこの誤差がどれくらい小さいかを見ることでモデルを評価します。回帰の評価指標でメジャーな平均二乗誤差(MSE) と 二乗平均平方根誤差(RMSE) について説明します。
平均二乗誤差(MSE: Mean Squared Error)
平均二乗誤差(MSE)とは、実際の値と予測値の絶対値の2乗を平均したものです。MSEの値が小さいほど誤差の少ないモデルと言えます。
MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y_i})^2
平均平方二乗誤差(RMSE: Root Mean Squared Error)
RMSEもまた回帰問題でよく使われる性能指標です。
誤差の計算方法は、予測値-ラベルの二乗をし、全て足し合わせます。足し合わせた合計をデータの数で割り、平均値を出します(ここまではMSEの計算)。二乗をすることによりマイナスの値をプラスに置き換えられるので、その差の合計は全て足されることになります。その平均値の平方根をとることで、全体の平均±の誤差を算出できます。
RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y_i})^2}
- n: データ数
- i: 各データのインデックス
- $ y_i $: i番目データの正解値
- $ \hat{y_i} $: i番目データの予測値
訓練データのRMSEを計算してみます。
model_pred = model.predict(X_train)
err_sum = ((y_train - model_pred) ** 2).sum()
mse = err_sum / len(y_train)
rmse = np.sqrt(mse)
print(f'誤差の合計:{err_sum}')
print(f'誤差の平均値(MSE):{mse}')
print(f'RMSE:{rmse}')
#出力
誤差の合計:5761.223137444673
誤差の平均値(MSE):0.38777836288918843
RMSE:0.622718526213239
またRMSEはscikit-learnのmean_squared_error()を使ってMSE(平均二乗誤差)を算出することでも計算できます。
from sklearn.metrics import mean_squared_error
model_train_pred = model.predict(X_train)
model_train_mse = mean_squared_error(y_train, model_train_pred)
model_train_rmse = np.sqrt(model_train_mse)
print(f'誤差の平均値(MSE):{model_train_mse}')
print(f'RMSE:{model_train_rmse}')
mean_squared_error()を使わないときと計算結果が一致しています。
#出力
誤差の平均値(MSE):0.38777836288918843
RMSE:0.622718526213239
テストデータで予測
学習に使用していないテストデータをモデルに入力してみます。
model_test_pred = model.predict(X_test)
model_test_mse = mean_squared_error(y_test, model_test_pred)
model_test_rmse = np.sqrt(model_test_mse)
print(f'誤差の平均値(MSE):{model_test_mse}')
print(f'RMSE:{model_test_rmse}')
誤差の平均値(MSE):0.37717254637755165
RMSE:0.6141437505808812
訓練データで計算したRMSEとほぼ同じ結果となりました。
機械学習モデル自体は過学習を起こさずに、上手く汎化されていることが分かります。
過学習とは訓練データにだけ適応した学習ばかりが過剰に進んでしまい、未知のデータに対して予測する性能が下がってしまうことです。訓練データだけでなく未知のデータに対しても正しく予測できる性能のことを汎化性能といいます。
受験勉強で例えると訓練データは試験の過去問、テストデータは本番の試験だとします。過去問はちゃんと解けるんだけど、本番の試験は解けないのは過学習している状態、本番の試験もしっかり解けるのは汎化性能があるということです。
結果の可視化
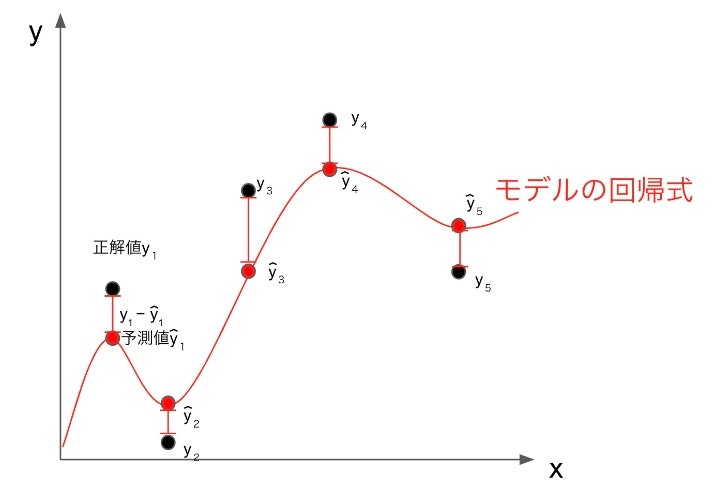
実際の値とモデルによる予測値の散布図を描画してみます。予測値と実際の値が近ければ近いほどプロットは下図のような二次関数でいうy = xの直線上に集まり、正の相関を示します。

plt.figure(figsize=(5,5))
plt.xlim(-1, 6)
plt.ylim(-1, 6)
plt.plot(model.predict(X_test), y_test, 'o')
plt.title('RMSE: {:.3f}'.format(model_test_rmse))
plt.xlabel('Predict')
plt.ylabel('Actual')
plt.show()
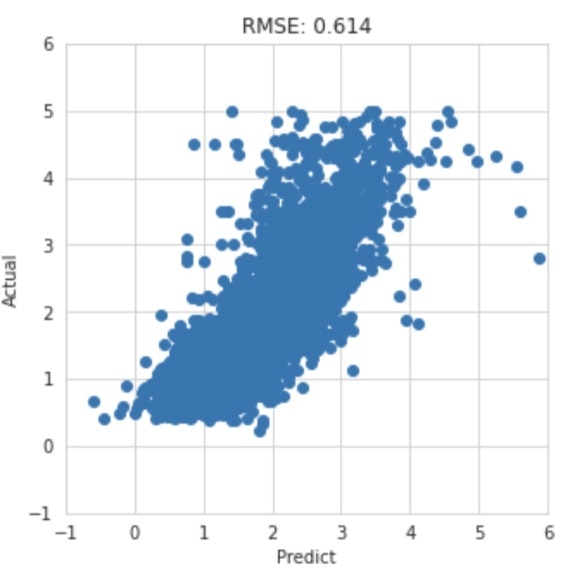
おおむね正の相関があることが確認できます。
結果からモデルを評価
ここまで見てきた結果をふまえるとこのモデルはいいモデルと言えるのでしょうか?
まず、訓練データとテストデータのRMSEを比較すると過学習はしていなさそうです。ではモデルの出す予測をもとに不動産投資しても良さそうでしょうか?
訓練データでの誤差の平均値(MSE)は0.388、目的変数Price(住宅価格)の単位は10万ドルなので、誤差の平均値は3.8万ドルということがわかります。日本円にすると500万円を超えます。投資主にもよるのでしょうが、個人的な感覚としてはこのモデルを投資判断の材料にするのはリスキーなので、データを集め直したり、学習方法を見直すなどしてモデルの精度を上げたいところです。
別のデータセットでもやってみよう
糖尿病のデータセット
scikit-learnではさまさまなデータセットを扱うことができます。練習として糖尿病患者のデータセットdiabetesを紹介します。
以下のコードでデータをロードできます。説明変数は年齢、性別、BMI、血圧...等、目的変数は1年後の糖尿病の進行度合になります。機械学習の練習としてぜひモデルを作ってみてください。
from sklearn.datasets import load_diabetes
data_diabetes = load_diabetes()
Kaggleに挑戦
Kaggleとは
最後まで読んでいただきありがとうございます。機械学習に慣れてきた読者の方に次のステップとしてKaggleを紹介させていただきます。
Kaggleとは企業・政府・教育等の機関と共に機械学習やデータサイエンスに携わっているエンジニアのプラットフォームです。Kaggleは機械学習のコンペ形式のサービスとなっており、組織がデータ分析に関する課題をKaggleに投稿します。
Kaggleはコンペ形式と聞くと難易度が高いのでは?と心配になると思いますが、Kaggleは初心者にとっても難しいものではありません。他のユーザーが投稿した予測モデルに関してコードと説明が公開されているので初心者はそれを見ながら実際にコードを書くことで知識を深めることができます。また、Kaggleは無料で利用が可能です。
https://www.kaggle.com/
おわりに
弊社では、経験の有無を問わず、社員やインターン生の採用を行っています。
興味のある方はこちらをご覧ください。