12月23日のきょうは今上天皇の御誕生日をお祝いする「天長節」。ついでに皇紀二六七六年(素数?いや、$2^2 \times 3 \times 223$)だそうで、謹んでお喜び申し上げるとともに、この佳き日にあたり呉港で満艦飾見物とでもいきたいところだが、手元不如意につき昼過ぎから難波の高架下にて南海電車のdefなバイブスとIPAをレフトハンドにつれづれなるまま、ここのところの手なぐさみである Jupyter Notebook のよくあるやつをものぐるおしげにログってみる。
よくあるやつ
- 数式エディタ
- グラフ描画
- 画像処理
- 自然言語処理
数式エディタ
ここ一年ほど師匠について群論なんぞをアラフォーの手習いでやっている。手書きのノートもそこそこ溜まってきたから清書してリポジトリに残しておきたい動機から LaTeX で数式メインのテキストを Markdown するのだが、肝心の数式の部分はセルのモードを Markdown にして案の定、
$LaTeX記法$
とすれば、あとは MathJax がよろしくやってくれる。
このあいだ well-defined が問題になる例を言え、ということだったから「分数の足し算を分子と分母、それぞれを足すことにする」などとたどたどしく出したら、微かにニヤリとされた刹那、分数の足し算の well-defined を瞬殺で示されたのでノートするしかないだろう(要点のみ抜粋)。
$\begin{eqnarray*}
\dfrac{a}{b} = \dfrac{a^{'}}{b^{'}} \nonumber \\
\dfrac{c}{d} = \dfrac{c^{'}}{d^{'}} \nonumber
\end{eqnarray*}$
とすると,
$\begin{eqnarray*}
{a}{b^{'}} - {a^{'}}{b} = 0 \nonumber \\
{c}{d^{'}} - {c^{'}}{d} = 0 \nonumber
\end{eqnarray*}$
$\begin{eqnarray*}
\dfrac{ad+bc}{bd} = \dfrac{a^{'}d^{'}+b^{'}c^{'}}{b^{'}d^{'}} \nonumber
\end{eqnarray*}$
$\begin{eqnarray*}
(ad + bc)b^{'}d^{'} - bd(a^{'}d^{'} + b^{'}c^{'}) & = & adb^{'}d^{'} + bcb^{'}d^{'} - bda^{'}d^{'} - bdb^{'}c^{'} \nonumber \\
& = & dd^{'}(ab^{'} - a^{'}b) + bb^{'}(cd^{'} - c^{'}d) \nonumber \\
& = & 0 \nonumber
\end{eqnarray*}$
github でもそこそこ表示されるが、nbviewer を通したほうが手許の表現を忠実に再現してくれる。
グラフ描画
このあたりから口数を激減させる何かが体内に激しく分泌されるのを感じはじめたので、+IPAならびにレムニスケート曲線でも描いてやり過ごしてみるテスト。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
alpha = 1
t = np.linspace(0, 2*np.pi, num=1000)
x = [alpha * np.sqrt(2)*np.cos(i) / (np.sin(i)**2+1) for i in t]
y = [alpha * np.sqrt(2)*np.cos(i)*np.sin(i) / (np.sin(i)**2+1) for i in t]
plt.plot(x, y)
ほんのりとそれっぽいのができあがった。
なお、レムニスケート曲線についてはこちらの解説が素敵だ。
画像処理
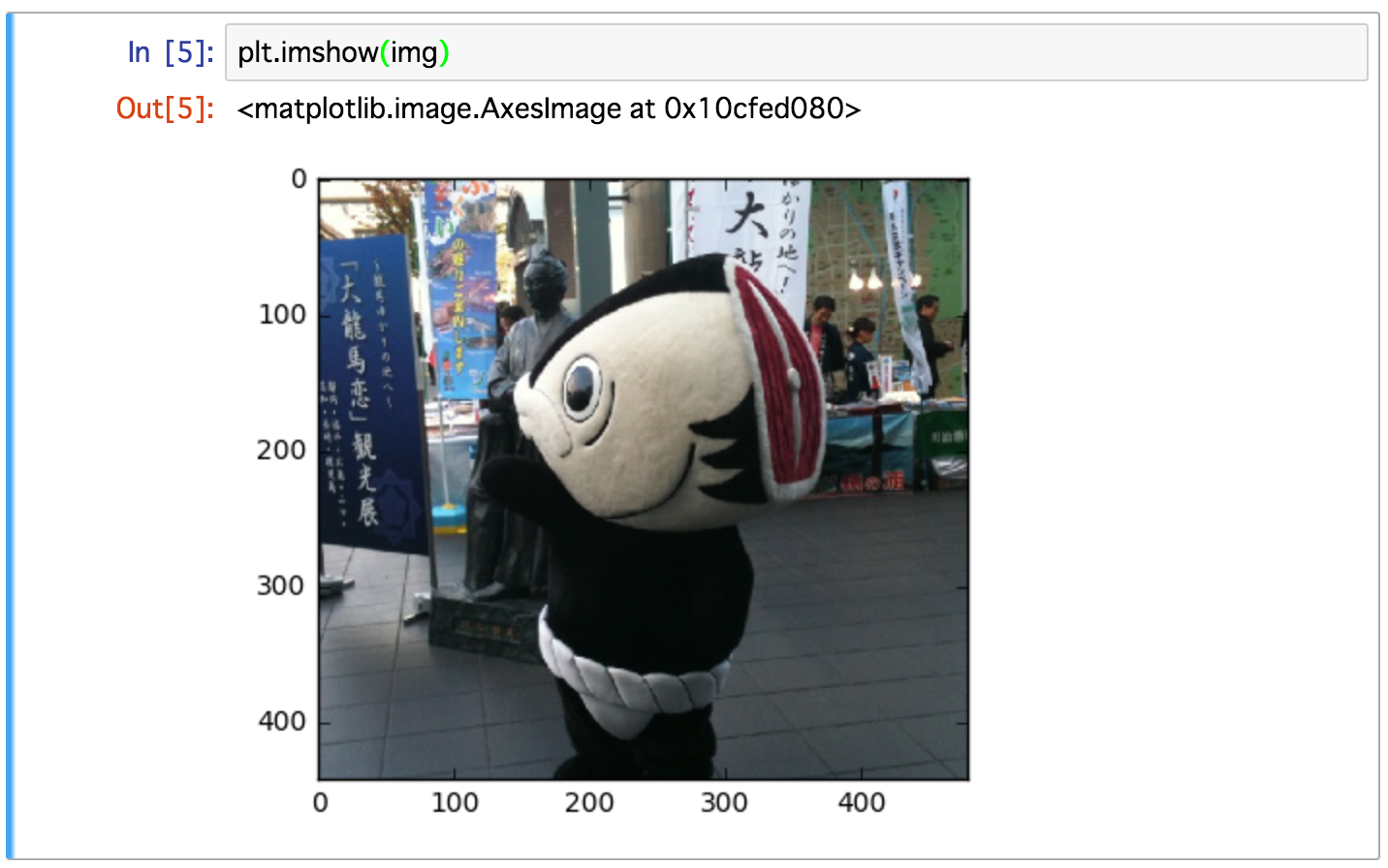
opencv を使って、画像上のいわゆる「人」の顔を認識させる例のやつ。とあるゆるキャラ(それほど、ゆるくないかもしれない)でやってみてどうなるかまずは確認。必要なライブラリとゆるキャラ画像をひっぱってくる。すべて Jupyter Notebook 上のワンストップオペレーションで完結する。
import cv2
from skimage import io
import matplotlib.pyplot as plt
%matplotlib inline
url = "https://qiita-image-store.s3.amazonaws.com/0/151745/8f4e7214-6c1c-c782-4986-5929a33f5a1b.jpeg"
img = io.imread(url)
plt.imshow(img)
あらかじめ人の顔の特徴を学習させた静的なデータ(カスケードフィルターファイル)が用意されている。
PATH_TO_CASCADE = "/Users/azki/anaconda3/share/OpenCV/haarcascades/haarcascade_frontalface_default.xml"
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier(PATH_TO_CASCADE)
faces = cascade.detectMultiScale(img_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
new_img = img
for x,y,w,h in faces:
cv2.rectangle(new_img, (x,y), (x+w, y+h), (0, 0, 255), thickness=2)
plt.imshow(new_img)
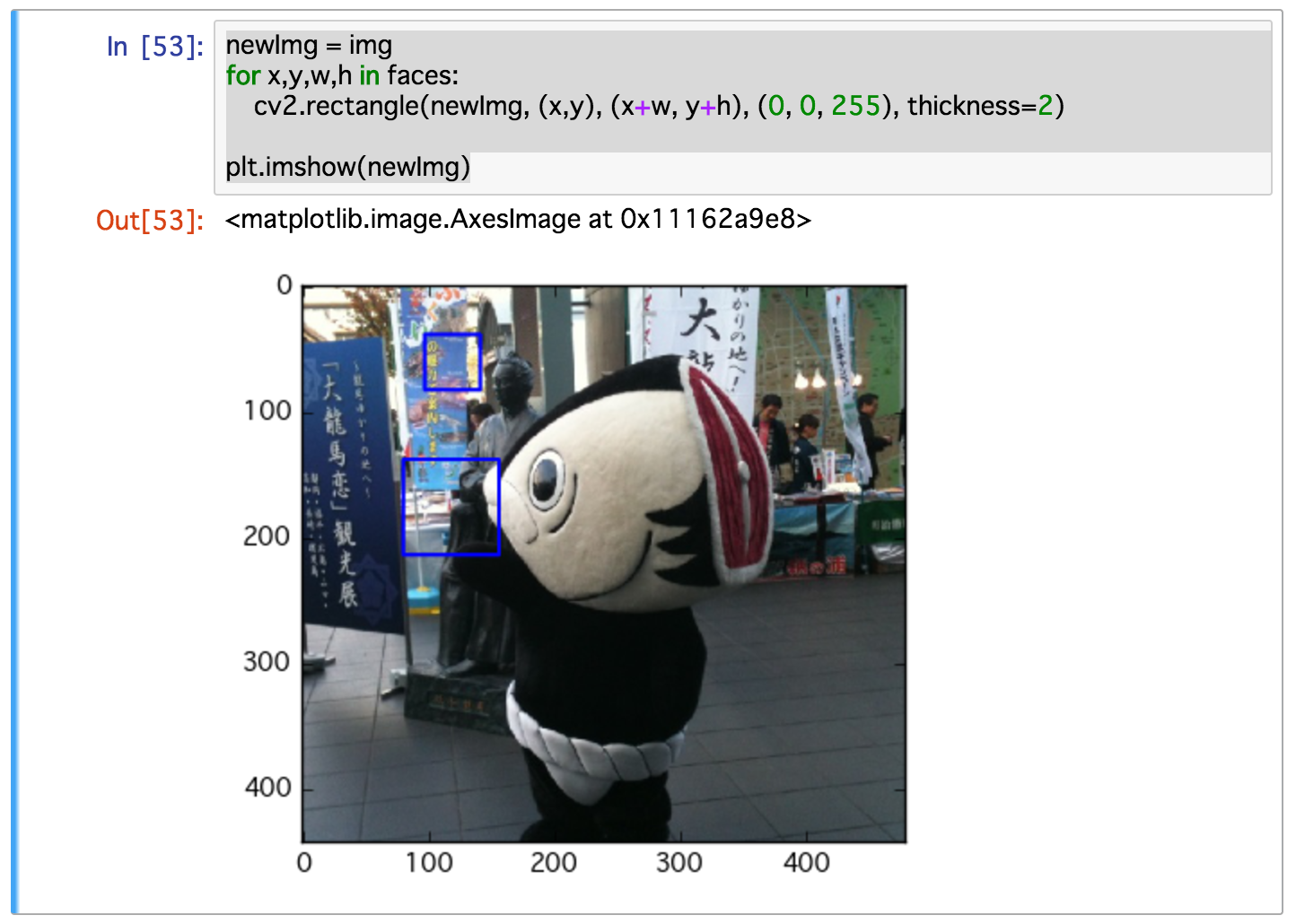
なにやら2箇所、人の顔として認識されているようだが(青い四角。龍馬っぽい銅像は完全にスルー)、見なかったことにして別の画像で試してみる。
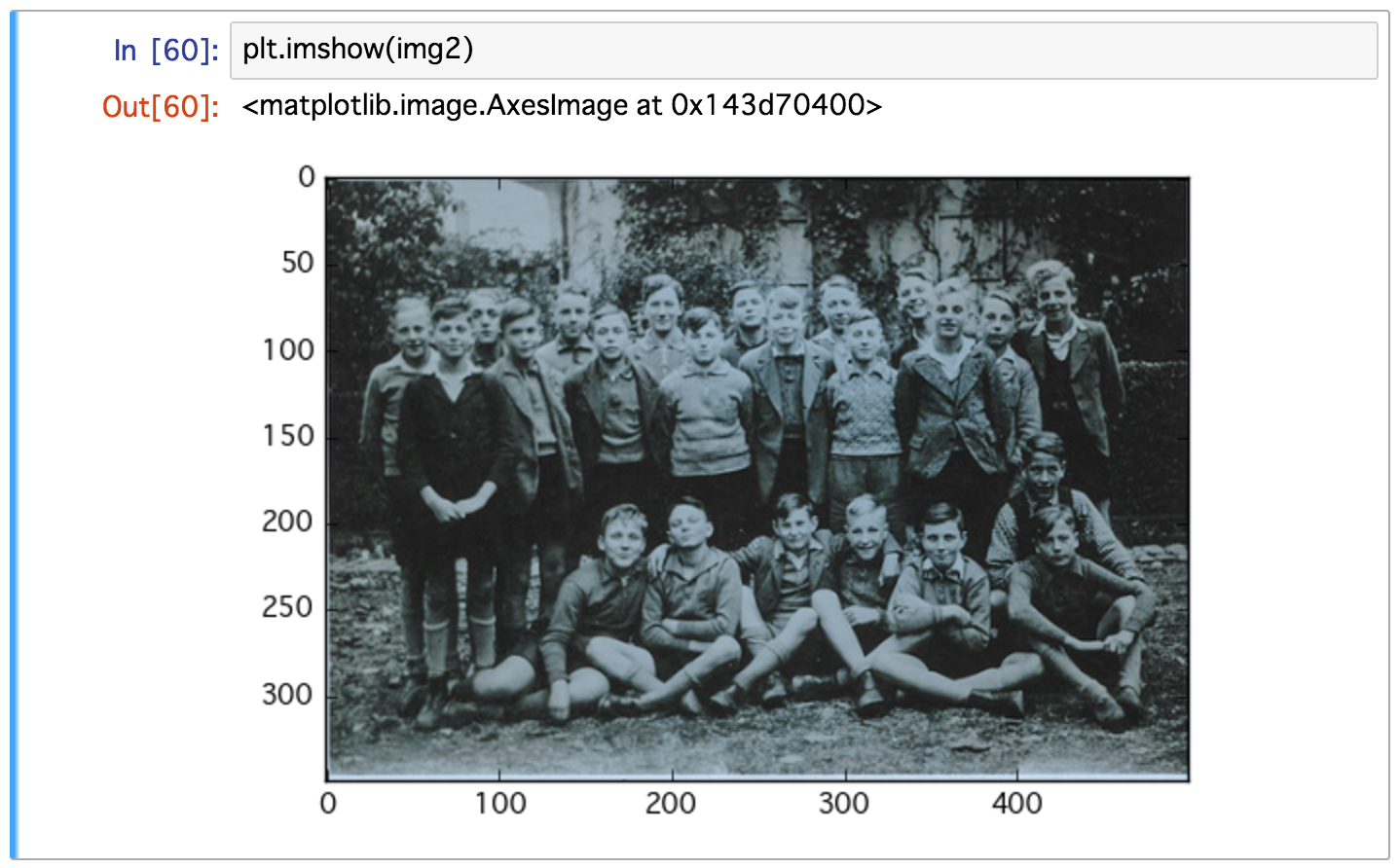
img2 = cv2.imread('gymnasium.jpg', cv2.IMREAD_COLOR)
plt.imshow(img2)
さきほどのゆるキャラとおなじフィルタを適用する。
img2_gray = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier(PATH_TO_CASCADE)
faces = cascade.detectMultiScale(img2_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
new_img2 = img2
for x,y,w,h in faces:
cv2.rectangle(new_img2, (x,y), (x+w, y+h), (0, 0, 255), 2)
plt.imshow(new_img2)

幾つか誤爆しているようだが、悪くない結果だ。
このように人の顔をだいたいスライスできたので、そこからモザイクをかけるもよし、感情やシチュエーションなどを機械的かつ大規模に解析できるはずだ。
自然言語処理
佳子は、毎朝、夫の登庁を見送って了うと、それはいつも十時を過ぎるのだが、やっと自分のからだになって...
という、一節からはじまり、
原稿には、態と省いて置きましたが、表題は「人間椅子」とつけたい考えでございます。
では、失礼を顧みず、お願いまで。匆々。
で、終わる江戸川乱歩の『人間椅子』。
自らがデザインした椅子の中に身を潜め、失礼どころか他人宅に勝手に忍び込み、一種のセンサーと化したかのように感覚を研ぎ澄ませ、郵便局という当時最大のメッセージングプロトコルとインテグレーションし、ログならぬ手紙という非同期な、そして極めて一方的な「想い」を送信。好奇心でデッドロックされた受信者はありえない現実に慄きつつ、「さてこのキモい椅子、どう処分しようかしら?」と、仕事から帰宅したご主人に相談したのかどうか。
この「人間椅子」が最終的にどう処分されたのかを知るすべもないし、そもそも知りたくもないのだが、書簡体と地の文が絶妙にブレンドされた卓越した構成からなる、夢野久作の『瓶詰地獄』にも比肩する大正時代のラノベであるこの作品を、単語の羅列からなるデータとしてword2vecで解析してみることにしよう。
ルビやヘッダ・フッタなどのノイズをあらかじめクレンジングしておいたテキストを MeCab で形態素解析してトークン化。それらトークンからなるリストを入力として、word2vec で『人間椅子』を構成する語彙をベクトル空間で表現する。空間内での距離(cos値)が近いほど意味的に類似しているとみなす。また、単語どうしの演算(加減)も可能になる。参考。
ともあれ青空文庫からテキストを入手。
!curl -O http://www.aozora.gr.jp/cards/001779/files/56648_ruby_58198.zip
!unzip 56648_ruby_58198.zip
file = codecs.open('ningen-isu.txt', 'w', 'utf-8')
for line in codecs.open('ningen_isu.txt', 'r', 'shift_jis'):
file.write(line)
file.close
# ここで適当なエディタでテキストをクレンジングしてね。
形態素解析。品詞が「名詞」の単語をチョイス。
import MeCab
tagger = MeCab.Tagger ('-F"%f[6] " -U"%m " -E"\n" -b 50000 -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
tagger.parseToNode('')
text = open('ningen-isu.txt')
tokens = []
for line in text:
node = tagger.parseToNode(line)
while node:
word = node.surface
pos = node.feature.split(',')[0]
if '名詞' in pos:
tokens.append(word)
node = node.next
with open('ningen-isu-wakati.txt', 'w') as file:
file.write(" ".join(tokens))
text.close
file.close
単語をベクトル空間で表現。また、その一部を可視化するまで。
# 必要なライブラリをインポート
import sys
import codecs
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from matplotlib.font_manager import FontProperties
from sklearn.manifold import TSNE
from gensim.models import word2vec
%matplotlib inline
# 単語ベクトルの生成
# 生成された "ningen-isu-w2v" ファイルの一行目は行ごと消しといてね。
data = word2vec.LineSentence('ningen-isu-wakati.txt')
model = word2vec.Word2Vec(data, size=200, min_count=1)
model.save_word2vec_format("ningen-isu-w2v", binary=False)
# 可視化のための日本語フォントのセットアップ
font_path = '/Library/Fonts/Osaka.ttf'
font_prop = matplotlib.font_manager.FontProperties(fname=font_path)
matplotlib.rcParams['font.family'] = font_prop.get_name()
matplotlib.rcParams['font.size'] = 10.0
# word2vec フォーマットのファイルを可視化用データに加工する関数。
def load_embeddings(file_name):
with codecs.open(file_name, 'r', 'utf-8') as f_in:
vocabulary, wv = zip(*[line.strip().split(' ', 1) for line in f_in])
wv = np.loadtxt(wv, delimiter=' ', dtype=float)
return wv, vocabulary
# グラフの生成
embeddings_file = "ningen-isu-w2v"
wv, vocabulary = load_embeddings(embeddings_file)
tsne = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = tsne.fit_transform(wv[:200,:]) # 一部の単語に限定
plt.figure(figsize=(20,20))
plt.scatter(Y[:, 0], Y[:, 1])
for label, x, y in zip(vocabulary, Y[:, 0], Y[:, 1]):
plt.annotate(label, xy=(x, y), xytext=(0, 0), textcoords='offset points')
# plt.show()
plt.savefig('ningen-isu.png', bbox_inches='tight')
plt.close()
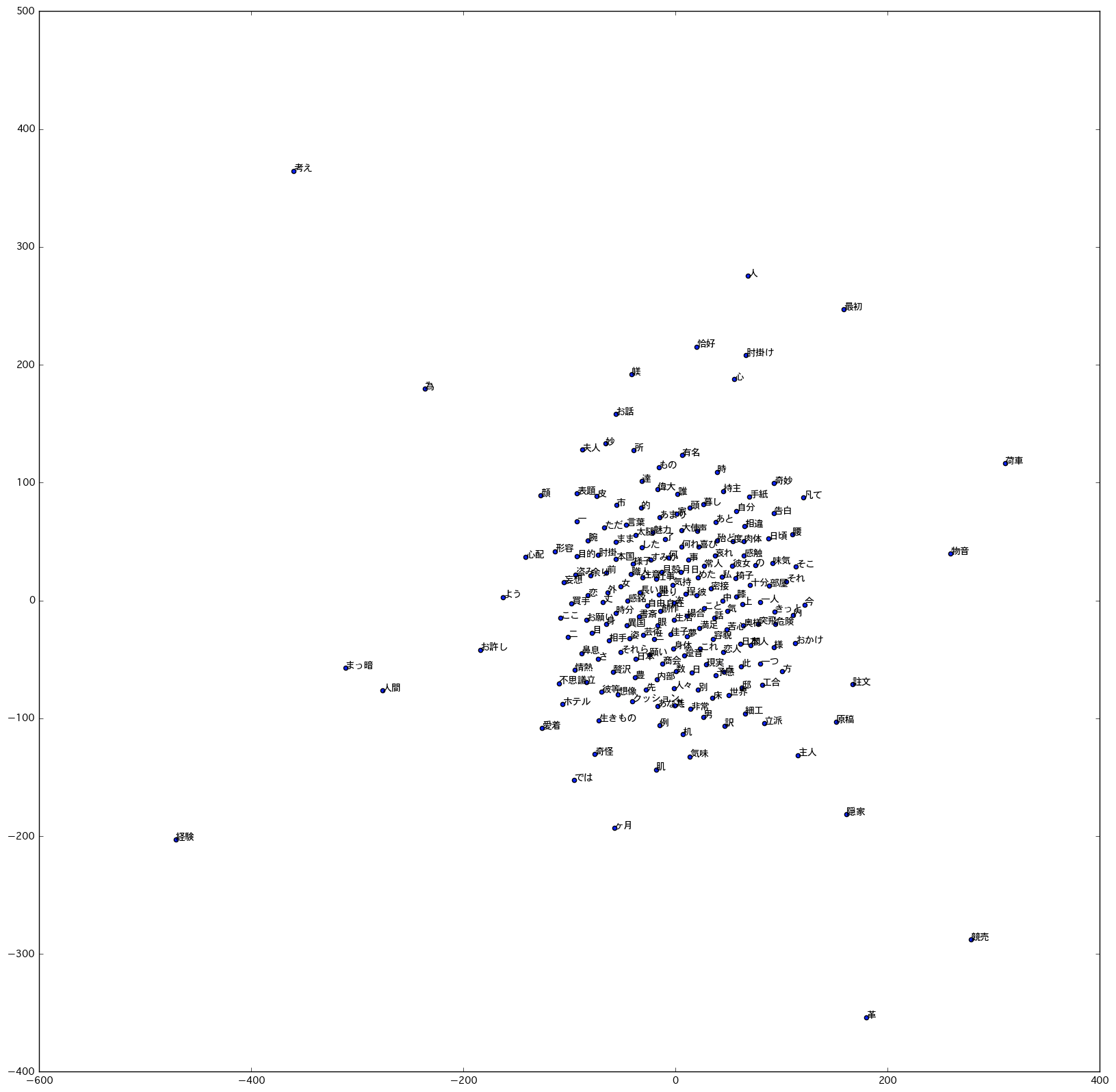
「私」「椅子」「感触」などといった単語の距離が近いことなどが見て取れるな、うん。
特定の単語の距離(cos値)もいくつかサンプリングしておこうか。
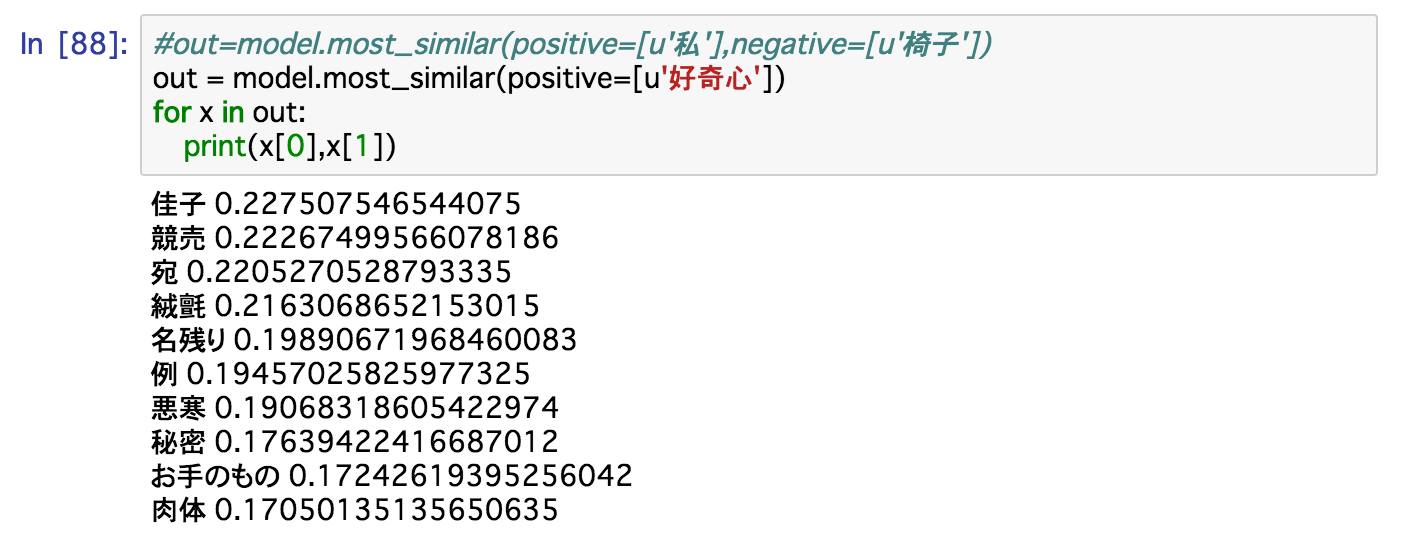
ふむ。では「私」から「椅子」を引くどうなるというのか。

「微妙」。
IoT だの Blockchain だのと喧しい昨今、もし乱歩がご存命ならば、どのような『人間椅子』を新たにぶち上げてくれていただろうか、などと解析結果とはほとんど関係ない主観的な感想を結語といたしまして、以上。
おわり。
POSTSCRIPT
# グラフの生成
embeddings_file = "ningen-isu-w2v"
wv, vocabulary = load_embeddings(embeddings_file)
tsne = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = tsne.fit_transform(wv[:200,:]) # 一部の単語に限定
上記関数中、Y = tsne.fit_transform(wv[:200,:]) で、こちらの Issue がローカル環境で再現された。
https://github.com/scikit-learn/scikit-learn/issues/6665
Issue のコメントにもあるように、筆者環境でも pip install --pre scikit-learn -U で fix できた。