この記事はなに?
前から「共起ネットワークで遊んでみたいな〜」と思っていて、実際に色々遊んでみた記録です。
環境構築
mecabなどのインストールは下記。
echo "mecab-python3==1.0.5
nlplot==1.4.0
pandas==1.4.3
beautifulsoup4==4.11.1" > pipfile
pip install -r pipfile
beautifulsoup4はhtmlからテキストを抽出するのに使用してるだけなので、必要ない人はなくても大丈夫です。
実装
詳細は省きますが、こんな感じで実装してます・
- mecabにない単語は、前後の単語を組み合わせてプログラム側で単語として判断するようにしている
- 名詞、動詞、形容詞を抽出対象に設定
- 名詞、動詞については無視する単語も設定(する、ある、いる、など)
- 単語の名寄せをしている(ざまあとざまぁがあったら、全てざまぁに寄せるなど)
- 個々の分析について共起が何回発生したかを見てplotに表示するかどうかを判断している
plot.py
import nlplot
def plot(title, df, graph):
npt = nlplot.NLPlot(df, target_col='words')
npt.build_graph(min_edge_frequency=graph)
npt.co_network(title=title)
text_analyzer.py
IGNORE_NOUN_WORDS = []
IGNORE_VERB_WORDS = []
ORIGINAL_DICT_LIST = []
TRANSLATION_LIST = {}
def analyze(genkei: str, midasi: str, hinsi: str, before: str, translate_dict: dict, wordlist: list):
word = translate(midasi, translate_dict)
unite_word = before + word
if unite_word in ORIGINAL_DICT_LIST:
if len(wordlist) > 0:
wordlist.pop()
return translate(unite_word, translate_dict)
else:
if hinsi == '名詞' and genkei not in IGNORE_NOUN_WORDS:
return translate(genkei, translate_dict)
elif hinsi == '動詞' and genkei not in IGNORE_VERB_WORDS:
return translate(genkei, translate_dict)
elif hinsi == '形容詞':
return translate(genkei, translate_dict)
return None
def translate(word: str, translate_dict: dict):
if word in TRANSLATION_LIST:
return TRANSLATION_LIST[word]
if word in translate_dict:
return translate_dict[word]
return word
mecab.py
import MeCab
import text_analyzer
DICTIONARY_PATH = '/path/to/mecab-ipadic/2.7.0-20070801/lib/mecab/dic/ipadic'
def analyze_text(text: str, base_word: str):
mecab = MeCab.Tagger('-d %s' % (DICTIONARY_PATH))
node = mecab.parseToNode(text)
before = ''
wordlist = []
while node:
parts = node.feature.split(',')
value = text_analyzer.analyze(genkei=parts[-3], midasi=node.surface, hinsi=parts[0], before=before, translate_dict={}, wordlist=wordlist)
if value != None:
wordlist.append(value)
before = value
else:
before = node.surface
node = node.next
if base_word != '':
wordlist.append(base_word)
return wordlist
dataframe.py
import re
import pandas as pd
from bs4 import BeautifulSoup
def get_dataframe(pathes: list):
df = pd.DataFrame({ 'text': get_text_lines(pathes) })
df = df.loc [:, ['text']]
return df
def get_text_lines(pathes: list):
lines = []
for path in pathes:
data = get_contents(path)
result = re.split('\n', data)
for line in result:
line = line.strip()
line = re.sub(r'&#[0-9a-zA-Z]+;', '', line) # 文字参照は邪魔なので消す
if line == '' or line == '。':
continue
lines.append(line)
return lines
def get_contents(path: str):
f = open(path, 'r')
data = f.read()
f.close()
if path.find('.html') >= 0:
result = get_article_container(data)
return result.get_text()
return data
def get_article_container(content: str):
soup = BeautifulSoup(content, 'html.parser')
# 記事固有のDOM取得処理
# 以下は例
data = soup.find(id='article-container') or soup.find(id='main') or soup.find(id='page-body') or soup.find(id='content')
if data:
return data
return soup.find('body')
main.py
import dataframe
import mecab
import plot
MECAB_LIST = {
# 'title': {
# 'list': [
# '/path/to/analyze_target.txt',
# ],
# 'graph': 10, # 共起ネットワークに表示する組み合わせの出現回数の下限
# 'translate': {}, # 分析対象特有の単語の差し替え辞書
# }
}
def main():
for k in MECAB_LIST:
df = dataframe.get_dataframe(MECAB_LIST[k]['list'])
df['words'] = df['text'].apply(mecab.analyze_text, base_word=MECAB_LIST[k]['base_word'])
plot.plot(k, df, MECAB_LIST[k]['graph'])
if __name__ == "__main__":
main()
例1: 概要を把握する
読書メーターの感想から概要を把握する
読書メーターの感想から本の概要を把握することはできるのか、ということで試しに『億万長者をめざすバフェットの銘柄選択術』の概要を出せるか調べてみました。
ベーステキスト
共起ネットワーク
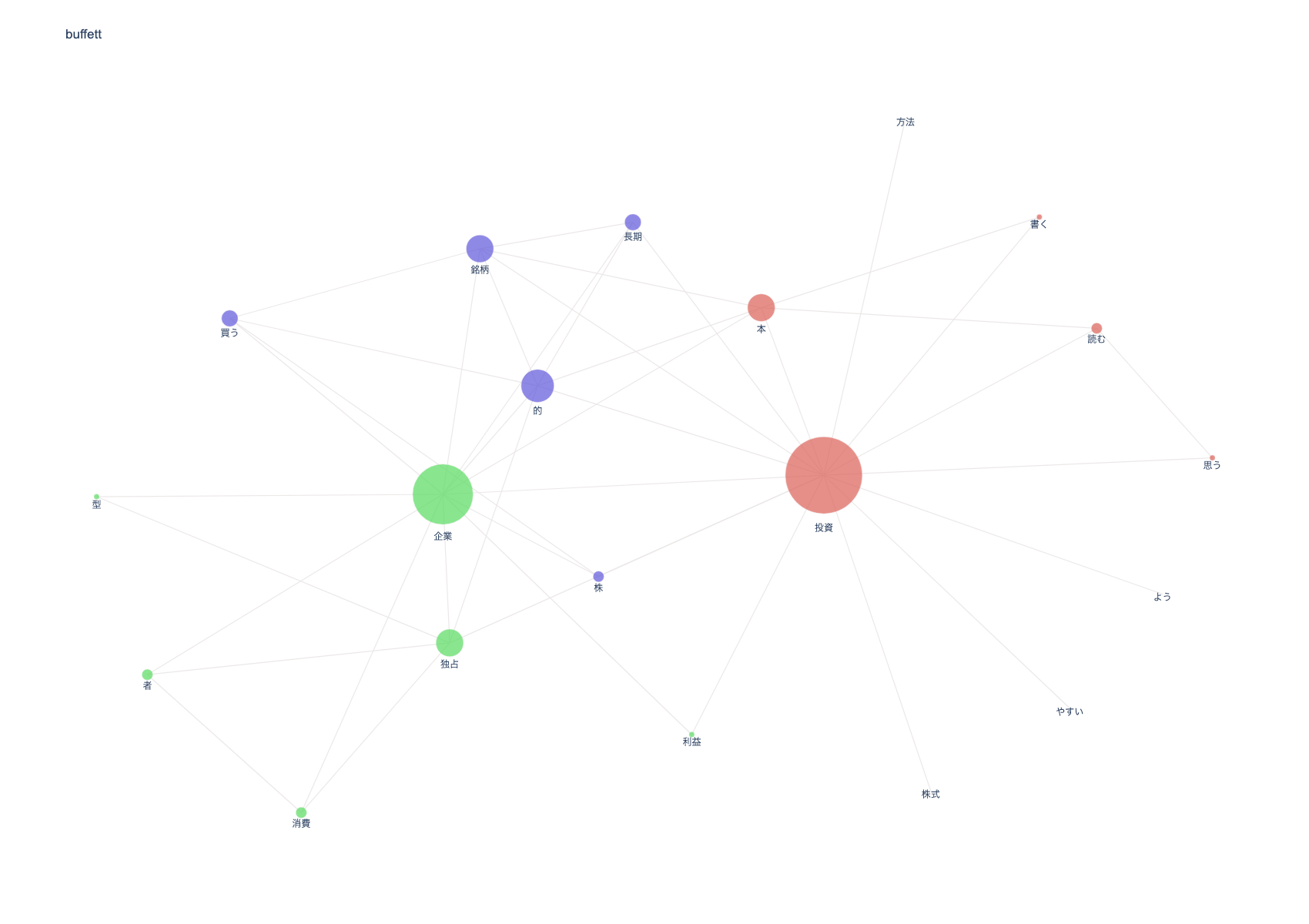
ネットワークの分析
- 株式、投資、方法が関連づいてるため、株式投資の方法について書かれている
- 銘柄と長期的が関連づいているため、銘柄を長期保有せよという内容が書かれていると推測される
- 消費者、企業、独占、型が関連づいているため、消費者独占型企業についての言及されている
例2: トレンドを把握する
小説家になろうのランキングのトレンドを把握する
ベーステキスト(2023/01/21時点)
共起ネットワーク
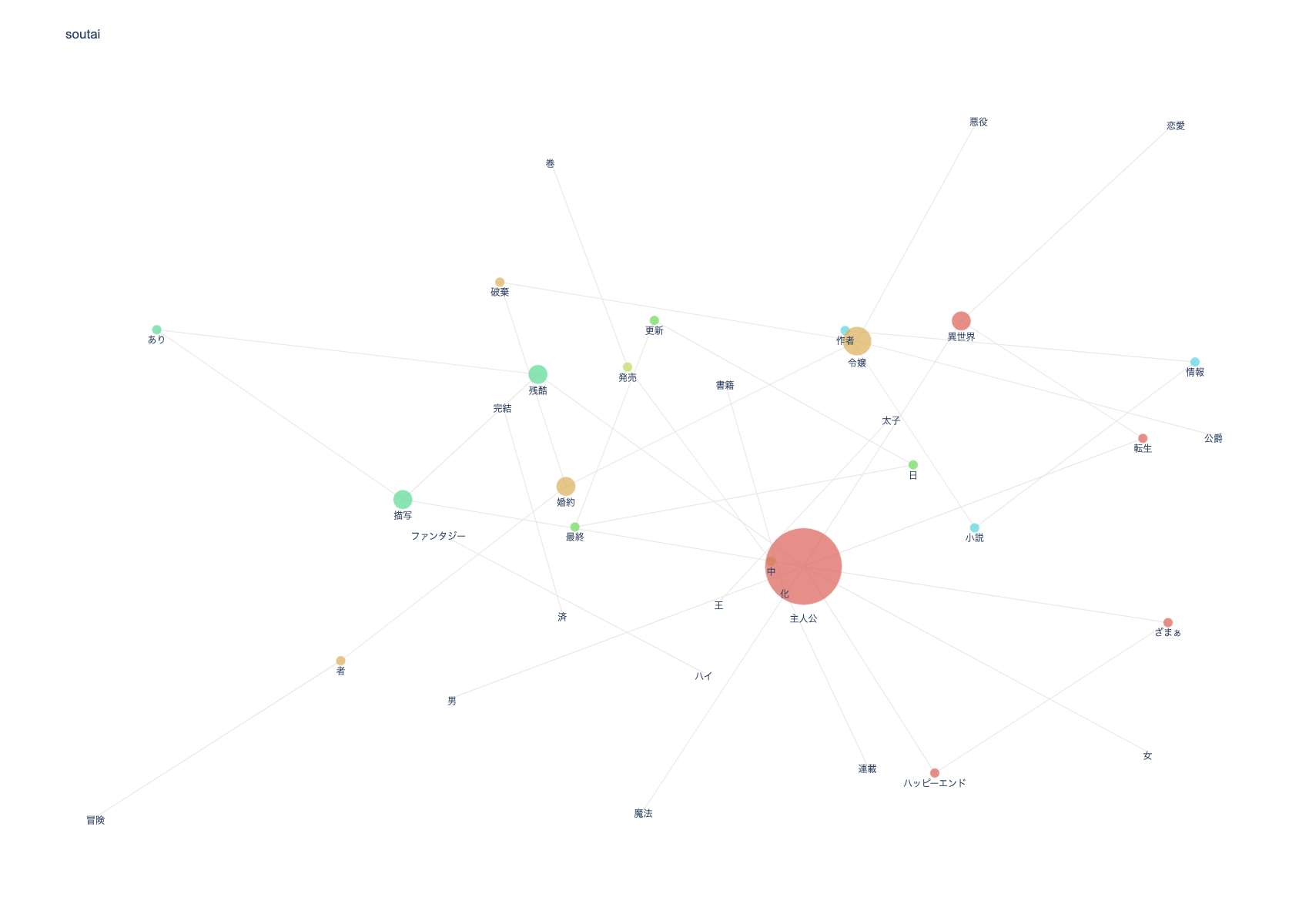
ネットワークの分析
- 令嬢物が支配的(悪役令嬢もジャンルとして残存している)
- 令嬢物は大抵婚約者か婚約破棄がセットでついてくる
- 残酷描写ありが意外に多い
- ハッピーエンドであることを明確化している作品が多い
- 異世界物が圧倒的に多く、ジャンル的には「異世界(恋愛)」と「ハイファンタジー」が多そう
- 転生、ざまぁは相変わらず多そうだが、転生とざまぁの間に共起は発生していない(現地主人公物が多い?)
- 王太子という単語の出現率が高い(おそらく異世界恋愛もののスパダリか、婚約破棄してくる相手)
以上の分析結果から、現状の「小説家になろう」は**「女性主人公による異世界恋愛ものが多く、ジャンルの傾向から読者層も女性読者の数が多い」のと「男性向けにしろ女性向けにしろざまぁ的な展開(婚約破棄されたけどハッピーエンド)が望まれている」**ことが読み取れそうです。
例3: 小説の概要や特徴を把握する
江戸川乱歩『少年探偵団』(出典:青空文庫)から概要や特徴を抽出する
ベーステキスト(2023/01/21時点)
共起ネットワーク
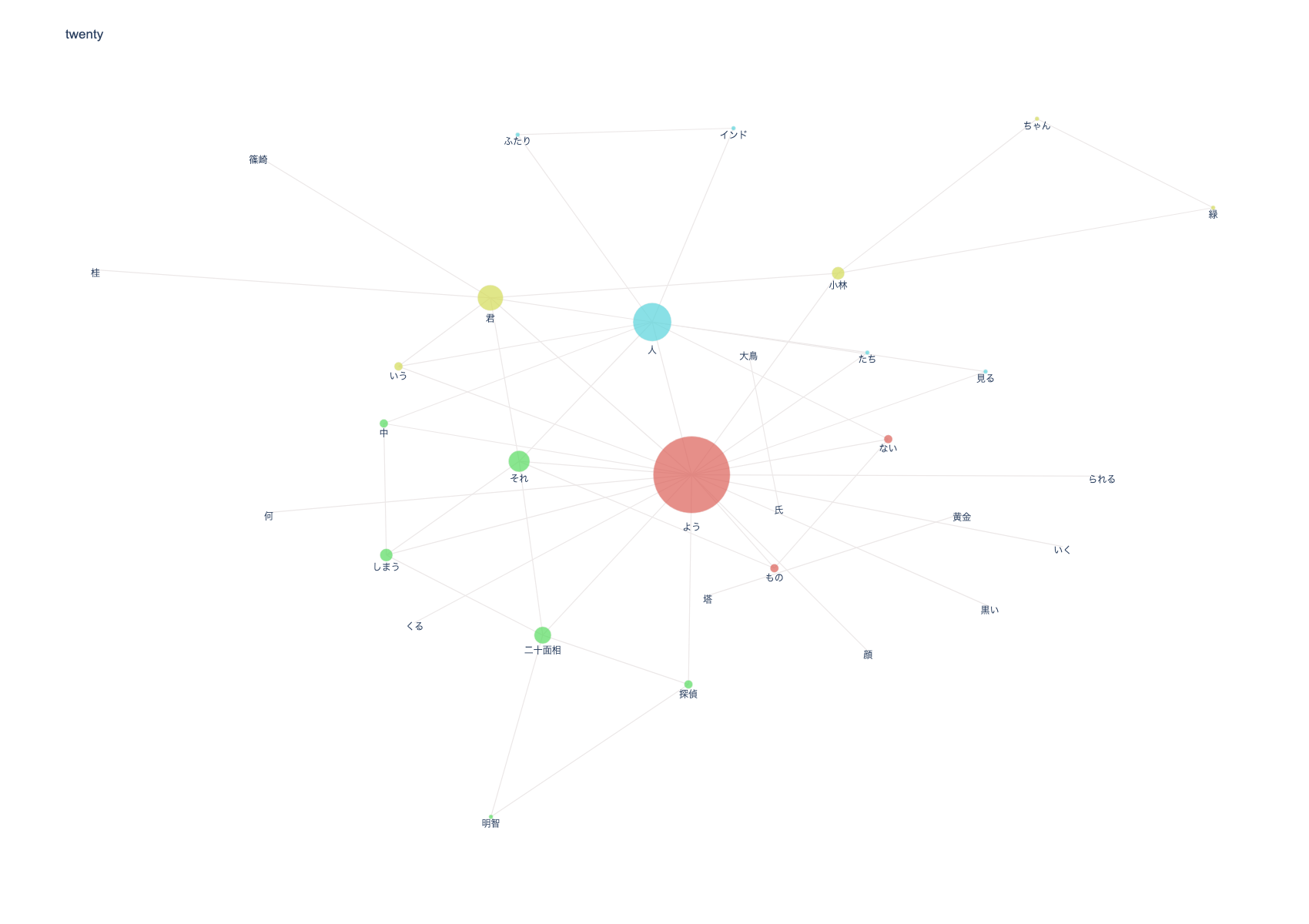
ネットワークの分析
- 君、ようの出現回数が非常に多い
- ●●君、〜〜のような、などが頻出する乱歩の文体の特徴が抽出されている
- 「ない」と「もの」の組み合わせも「〜〜ないものですから」という乱歩の文体の特徴
- 明智探偵と二十面相、小林君と緑ちゃんなど、主要人物の関係性が抽出されている
- インドと人、黄金と塔から、インド人や黄金の塔などが話に関連していると思われる
まとめ
- 共起ネットワークではふんわりと概要を把握することはできるが、ふんわりとしか概要をつかめない
- 細部まで追おうとすると図が複雑になりすぎて図の分析が大変になるため、細部を把握したい場合はもっと別の手段を使った方がいい
- 頻出単語表と合わせたり、共起ネットワークを細分化できたらまた違うのかも
- ランキングなどのトレンドの把握、文体の特徴抽出などはもっと伸び代ありそう
- 現状汎用的な分析コードを一律で流しているが、もっと特化型の分析をしてもよさそう
- 文体抽出は抽出対象の品詞を入れ替えるとか
- 現状汎用的な分析コードを一律で流しているが、もっと特化型の分析をしてもよさそう