はじめに
はじめまして。
NTTデータ ソリューション事業本部 デジタルサクセスソリューション事業部 の @nttd_mskitagawa です。
Informatica(インフォマティカ) のクラウドデータマネージメントプラットフォーム「Intelligent Data Management Cloud」上でSaaSとして提供される
Multidomain MDM SaaS というマスタデータ管理ソリューションがあります(※1)。
※1:
「Multidomain MDM」の他に特定の要件に対して予めパッケージングされたドメイン限定型のMDMも存在します(「Customer 360」、「Supplier 360」、「Product 360(PIM)」 )。

今回は、ドメイン限定型のMDMである「Customer 360」を使用して、ファイルをもとにMDMにデータをセットアップする方法を説明します。
Customer 360にはファイルを画面から取り込むことでマスタデータを登録できる機能があります。
例えばMDMを導入し運用開始する際、既存システム等から抽出した初期データを移行するケースが考えられますが、そういった際に当機能を使用したり、マスタ管理業務の通常運用としてマスタデータの登録や更新をファイルインポートにて実施する場合などに使用することもあります。
どのようにファイルインポートを実施できるのか、エラーなどの扱いはどうなるのか、など実際に直面しそうな困りごとの参考になる情報がお伝えできればと考えています。
本記事は、Multidomain MDM SaaSの機能・実装を紹介するシリーズの一遍です。
シリーズではマスタデータ管理の下記のプロセスに沿って複数人で記事を執筆しています。
- 管理するマスタデータを定義する
- マスタデータを守る ‐ データ品質(入力チェック)の定義 ‐
- 複数言語圏の利用者に対応する ‐ ローカライゼーション(多言語化対応)‐
- ユーザ要望に沿った画面を作る(UI/UXの追求) ‐ カスタム画面の作成 ‐
- ユーザの入力を補助する ‐ データ品質(入力補助)の定義 ‐
- Multidomain MDM SaaSと企業で導入されている認証基盤と連携する ‐ SSO -
- マスタにデータをセットアップする ‐ ファイルインポート機能で一括登録・更新 ‐ ★本記事です★
こんな方はぜひ、続きをどうぞ。
- データマネジメントに興味がある
- Informatica社のMDMに興味があるが、まだ触ったことがない
- Informatica社のMDMでファイルインポートによるマスタ登録のイメージを知りたい
「Customer 360」でファイルをもとにMDMにデータをセットアップする方法
前提環境・バージョン
記事執筆時の環境・サービスのバージョンを下記に示します。
バージョンによっては画面UIなどが異なる可能性があるのでご注意ください。

手順の概要
以下の手順で行います。
- ファイルの準備
- ファイルインポート(登録)、インポート結果の確認
- ファイルのエクスポート
- ファイルインポート(更新)、インポート結果の確認
詳細手順
【1】 ファイルの準備
「Multidomain MDM」では、マスタデータをBE(ビジネスエンティティ)として定義し、
そのBEにマスタデータを登録して管理します。
製品がデフォルトで用意するBEもありますが、実際には独自にBEを作成することも多いと思いますので、
今回は独自に作成したBE「Sample_Customer_02」へファイルインポートしようと思います。
※ BEの作成方法については、以下の記事を参照ください。
「InformaticaのMDMでデータマネジメント 〜BE作ってみた+標準(新規登録、参照更新)画面〜」
BE「Sample_Customer_02」の定義は以下の通りです。背景が白の項目はルート項目、薄いグレーに塗られている「家族会員ID」以降の家族関連の項目はフィールドグループ項目と呼ばれる項目として定義されており、本人1件に対して複数の家族のデータを登録することができます。このBEに格納するマスタデータを作成します。
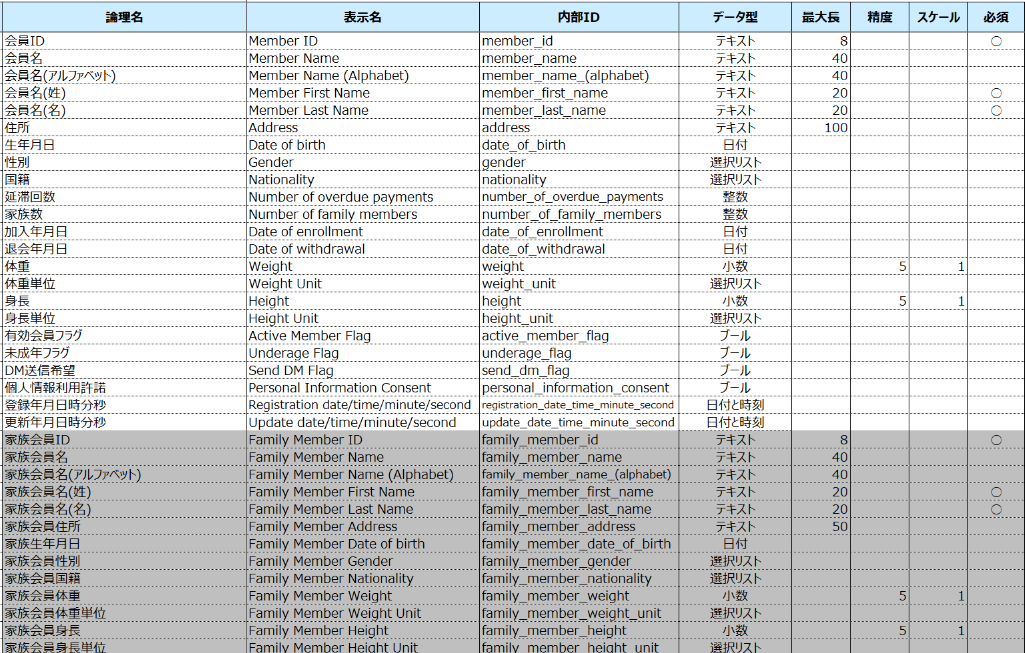
ファイルは以下のように作成します。
- ファイル名は「Customer.csv」、ファイルの形式はTSVとします(CSVでもかまいません)
- インポートの際にどの項目の値か分かるよう、1行目に項目名を表す行を入れておきます
- フィールドグループのデータは1件につき1行で作成し、ルート項目は同じ値をセットしておきます
- 各データの値はそのままセットします(ダブルクォーテーション等で囲む形式も可能です)
- 「選択リスト」の項目については、値のみで設定します
- 「日付」「日付/時刻」の項目はyyyy/MM/ddで設定します("yyyy/MM/dd"や"MM-dd-yyyy HH:MM:ss"などいくつかの形式での設定が可能です)※ HH:MM:ss の MM は実際には小文字 mm が正しいです(画面上、正しく表示されないので、大文字で記載しました)
このファイル作成時には以下にの制約条件に注意してください。変更があるかもしれませんので、最新のマニュアルを確認してください。
- ファイルの文字コードはUnicode(UTF-8、UTF-16BEなど)である必要があります(Shift-JIS等はNG)
- 1ファイルあたりの制限は、以前は1万レコードでしたが、今はマニュアル上では100MBが上限だそうです
- 「Source Primary Key」では使用できない文字があります:スラッシュ (/)、バックスラッシュ (\)、ピリオド (.)、パーセンテージ (%)、セミコロン (;)、二重引用符("")
- フィールドグループの「Source Primary Key」では、記号はコロン (:)、ハイフン (-)、パイプ (|)、またはアンダースコア (_) のみ
- フィールド値に単一のバックスラッシュ (\) を設定することはできません
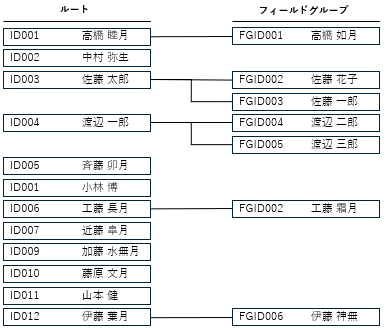
以上を踏まえ、今回は以下のような内容を含むデータをUTF-8で作成します。BEの定義とは合わない値など、意図的にエラーとなるデータを入れます。
- フィールドグループのデータがあるデータ:(1行目)
- フィールドグループのデータが無いデータ:(2行目、7~13行目)
- フィールドグループが複数あるデータ1: 家族のデータが2件あり、本人の項目の値を2件とも記載(3,4行目)
- フィールドグループが複数あるデータ2: 家族のデータが2件あり、2件目の本人の一部の項目を空欄(5,6行目)
- 必須項目が空欄のデータ: 「会員ID」「会員名」以外が全て空欄のデータ(7行目)
※ 必須項目の中で、「会員名(姓)」「会員名(名)」に値が設定されていない - 主キーが重複するデータ:「会員ID」が重複するデータ(8行目)
- フィールドグループの主キーが重複するデータ: 「家族会員ID」が重複するデータ(9行目)
- データ型と値が不一致なデータ(選択リスト):「性別」に文字列「X」と設定されているデータ(10行目)
- データ型と値が不一致なデータ(日付、数値): 「生年月日」と「体重」に文字列「不明」と設定されているデータ(11行目、12行目)
- データ型と値が不一致なデータ(ブール): 「有効会員フラグ」に文字列「〇」と設定されているデータ(13行目)
- 桁数と値が不一致なデータ(小数): 「身長」に定義された小数以下の桁数を超える値のデータ(7行目、11行目)
用意したデータの構造と実際の値は以下の通りです。意図的にエラーとなるデータはデータのセルが薄い赤で塗られているところです。

【2】 ファイルインポートを実行
【1】で作成したファイルをインポートします。
-
ログイン後のサービス選択画面にて、Customer 360を押下します。

-
Customer360の左メニューから「ファイルのインポート」を選択します。
-
「すべてのデータのインポート」の「開始」を押下します。

-
「ファイルの選択」の「ここにCSVファイルをドラッグ」に作成したファイルをドラッグ&ドロップします。「参照」から、ファイルを選択して指定してもOKです。

-
次に、ファイルのアップロードに関する設定を行います。
「プレビュー」で取り込むデータの最初の10件が表示されますので、これを参考に「プレビュー」の下に表示される、以下の項目の設定を行います。-
「ソースシステムの選択」
「ソースシステム」は、このファイルのデータを生成したシステムを指定します。今回は「Default」とすることにします。 -
「レコード更新の強制」
「インポートタイプ」は、ファイルで更新等を行う際、変更しない項目も含めて全て値を設定したファイルを作成する場合は、「レコードの作成または上書き」、変更しない項目の値は空欄でファイルを作成する場合は「レコードセクションの更新」を選択します。今回は「レコードの作成または上書き」を選択します。 -
「ファイルの設定」
以下の項目を設定します。- 区切り文字(カンマ、タブ、その他): 「タブ」
- テキスト修飾子(一重引用符、二重引用符): 今回は値を引用符で囲んでいないので、デフォルトで表示された「二重引用符」のまま
- エンコーディングタイプ(UTF-8、UTF-16BE、UTF-16LE、UTF-32BE、UTF-32LE):「UTF-8」
- 行から始まるデータを使用する(データが開始まる行):「2」
- カラムヘッダーを含みます:カラムヘッダを含むかどうか : チェックを入れる
- カラムヘッダー行の位置(何行目か): 「2」
-
「地域設定」
日付や日付と時刻項目の形式、小数点を持つ数値の形式、区切り文字を指定する必要がある場合、チェックを入れて設定します。- 日付パターン(yyyy/MM/ddなど):「yyyy/MM/dd」
- 日付/時刻パターン(yyyy/MM/dd HH:MM:ssなど):「yyyy/MM/dd HH:MM:ss」※ ここもHH:MM:ss の MM は実際には小文字 mm が正しいです
- 小数点記号: 「.」
- 桁区切り記号: 該当する値は無いですが「,」
これらを設定後、右上の「次へ」をクリックします。

-
-
格納先のビジネスエンティティを設定します。
左側にインポートするデータが表示されます。最初の5件分の確認ができます。インポートするファイルの内容が合っていることを確認したのち、右側の「ターゲットビジネスエンティティ」の設定を行います。
「+」を押下すると、推奨のビジネスエンティティが表示されます。中でも緑色のアイコン(信頼性インジケータ)のものがファイルとの適合度が高いと判断しているとのことです。この中から、格納先のビジネスエンティティを選択します。
ここでは、「Sample_Customer_02」の左にチェックを入れます。

-
項目のマッピングを設定します。
インポートするファイルの項目と、格納先のビジネスエンティティの項目の対応付けを行います。ファイルの作成時に項目名を入れておきましたので、「スマートマッピング」により自動的にマッピングされています。念のため、マッピングされている内容が正しいことを確認します。
次に、ターゲットフィールドの項目「ソースプライマリキー」(Sample_Customer_02とフィールドグループの2項目あります)を設定します。項目名の後ろに鍵のアイコンが表示されており、設定が必須となっていますが、項目名が一致していないため「スマートマッピング」では設定されないことから、手動で設定する必要があります。この項目には、ファイル内で一意に識別できる項目を指定します。初回のインポートののち、ファイルで更新を行う際のキーにもなります。
ここでは「Sample_Customer_02」には「member_id」、フィールドグループ側には「family_member_id」を設定します。
最後にインポートしたい項目が全て設定されているかどうかを確認します。画面左の入力ファイルの項目でインポートしたい項目が全て「マップ済み」となっていればOKです(マップ済みの後ろの数字は、右側のターゲットに紐づけられている項目の数です)。
終わりましたら、右上の「次へ」をクリックします。

-
インポートを実行します。
インポートの前に、今後も同じ内容でインポートする場合に備え、ひとつ前で設定したマッピングを保存しておくことができます。一つの環境(org)で100個まで保存可能です。
今回は「保存しない」を選択します。
次に、ファイル内のデータがビジネスエンティティに格納されるプレビューが確認できます。
問題なければ、右上の「インポート」をクリックします。

-
インポートの実行結果を確認します。
画面「インポートジョブを開始しました」のファイル名をクリックすると、インポート実行ジョブが表示されます。
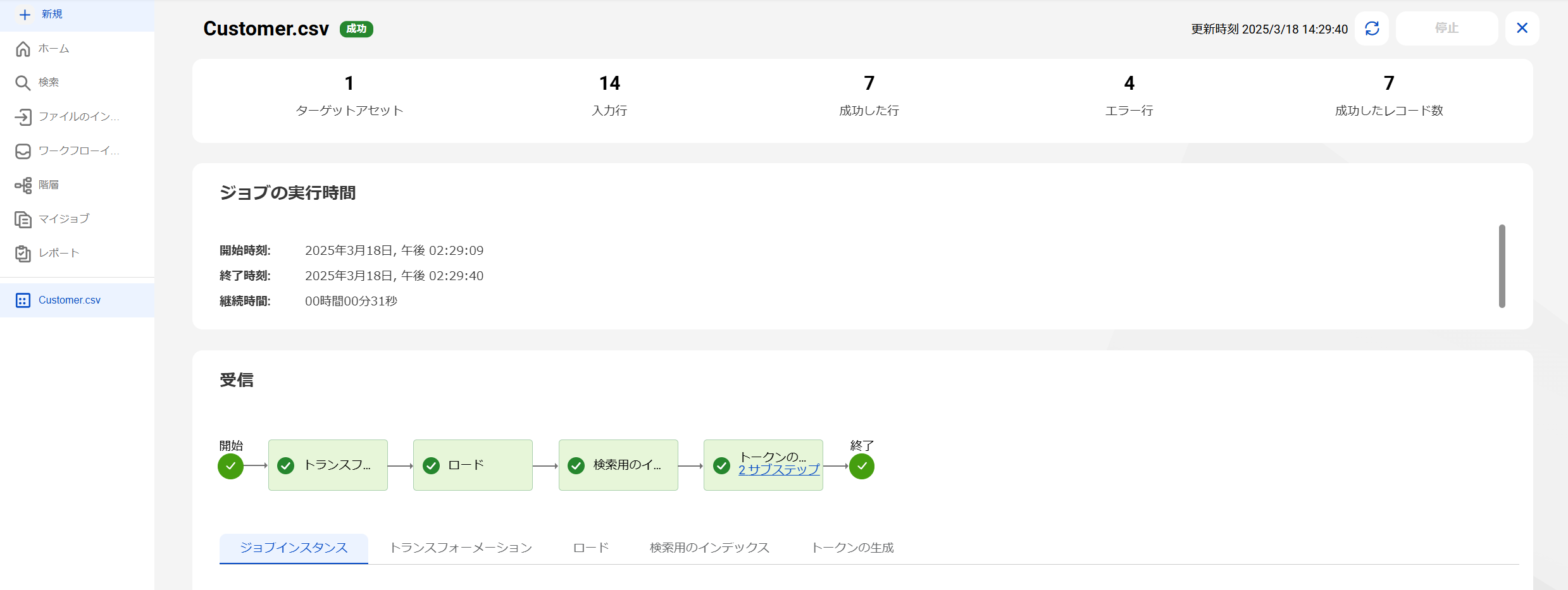
「受信」エリアで処理状況を見ることができ、内容が更新されない場合は、画面右上の「更新」ボタンを押下します。「開始」「トランスフォーメーション」「ロード」「検索用のインデックス」「トークンの生成」「終了」まで、緑色のチェックのアイコンが表示されたら、インポートの処理は完了です。この完了は、処理が異常終了せず完了したことを表しており、エラーとなったデータがあったとしても、エラーメッセージを出力する等の処理が正しく動作すれば、完了となります。
そして一番上に処理件数が表示されます。用意したファイルの14行がすべて処理されていますが、エラー行が4行あったことがわかります。ですが、エラーとなるデータは4行以外にもあるはずです。インポートしたデータがエラー無く処理されたかどうかは「トランスフォーメーション」「ロード」のそれぞれの結果を確認する必要がありますので順に見ていきます。-
「トランスフォーメーション」の処理結果の確認
「トランスフォーメーション」タブをクリックします。

エラーレコードが1件あったことがわかります。左の「エラー」タブをクリックします。

「拒否されたレコード」「検証エラーのあるインポートされたレコード」の項目にそれぞれ「ダウンロード」というリンクが表示されていますので、それぞれクリックしてダウンロードし、内容を確認します。- 「拒否されたレコード」のログ
CSV形式で出力されるので、表形式に整理しました。

- ID002、ID005、ID007、ID009、ID010、ID011は、フィールドグループの主キー「家族会員ID」のデータが無いことによるフィールドグループの登録のエラーです。フィールドグループのデータ自体が無くて正しいため、問題ないエラーです。
- ID001は、エラーメッセージからは分からないですが、主キー「会員ID」が重複していることによるエラーと思われます。
- ID009、ID010、ID011、ID012は、データ型と値が不一致、もしくは桁数と値が不一致による本人(ルート項目)データの登録時のエラーです。ルート項目側のエラーのため、この4件はデータが登録されなかったと読み取れます。インポートジョブの結果画面の上部にあった、「エラー行:4」はこの4件のエラーを指していると思われます。また、ID012は、本人のデータ(ルート項目)がエラーとなったため、フィールドグループのデータは問題なかったが登録できなかったためと思われるエラーも出力されています。
- 「検証エラーのあるインポートされたレコード」のログ

選択リストの「性別」に、定義されていない値「X」を設定していましたが、この値がエラーとなっています。
- 「拒否されたレコード」のログ
-
「ロード」の処理結果の確認
トランスフォーメーションと同様、ロードの方も確認します。

ロードではエラー無く処理できたようです。 -
「検索用のインデックス」の処理結果の確認
検索用インデックスの処理結果も確認します。
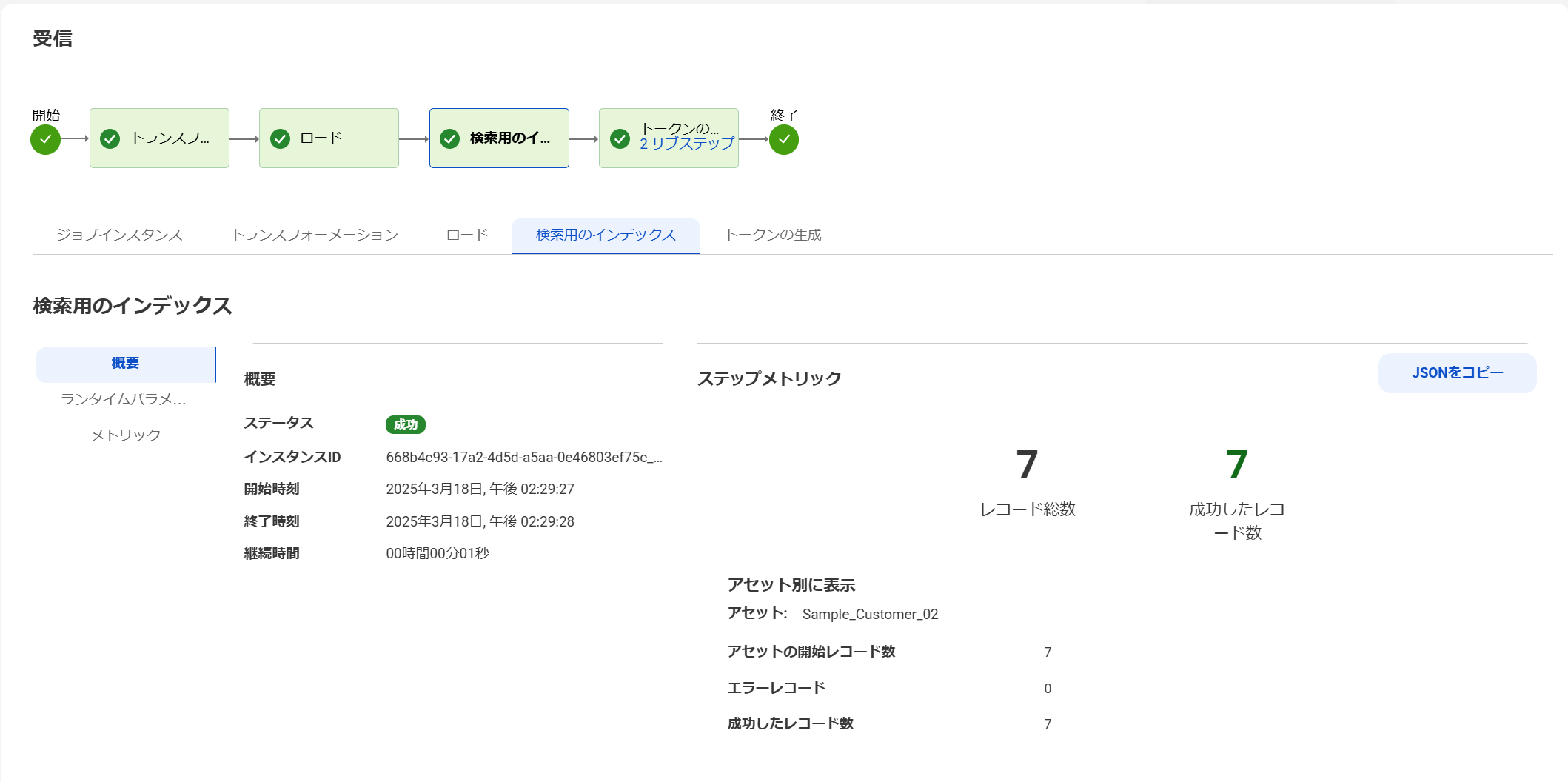
ここもエラー無く処理できたようです。
-
画面上部の「エラー行」が仮に0件だったとしても、その数字には現れないエラーが発生している可能性があるので、インポートの処理全体が完了していても「トランスフォーメーション」「ロード」「検索用のインデックス」の処理結果も個別に確認する必要があります。
これらのエラーメッセージを確認して、エラーとなったデータを修正する等の対応を行うことになります。
【3】インポートされたデータを確認する
インポートでエラーが発生していますが、どのように登録されたのかを確認します。
Customer 360の画面の上部の検索窓で、ビジネスエンティティ「Sample_Customer_02」にチェックをいれ、「*」(半角のアスタリスク)を入力して、虫メガネのアイコンをクリックすると、「Sample_Customer_02」に格納されているデータの全てがリストで表示されます。
先ほど確認したインポートジョブの結果では成功が7件でしたので、同じく7件が表示されていることが確認できました。
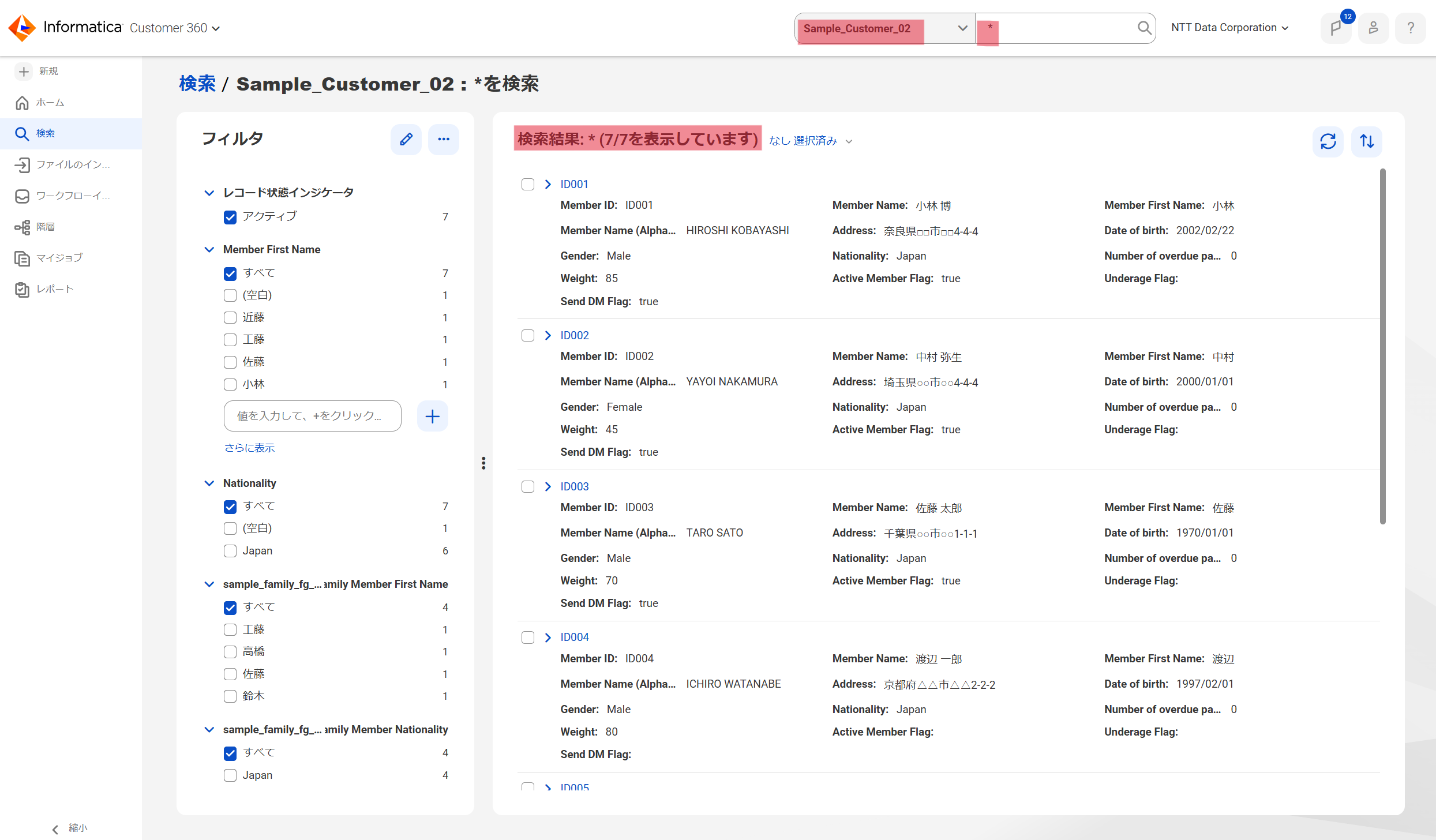
ちなみに、検索結果の表示は1万件までという制限がありますので、1万件より多い件数がヒットした場合は、条件で絞る等の必要があります。
それでは取り込まれたデータの内容を確認していきます。
-
フィールドグループのデータがあるデータ:(1行目)
問題なく取り込まれています。

-
フィールドグループのデータが無いデータ:(2行目、7~13行目)
問題なく取り込まれています。フィールドグループのデータが無かったためにエラーのログが出力されていましたが、本人(ルート項目)のデータは登録されています。以下は2行目のデータ(ID002)です。

-
フィールドグループが複数あるデータ1: 家族のデータが2件あり、本人の項目の値を2件とも記載(3,4行目)
フィールドグループの2件の家族のデータまで取り込まれていることが確認できました。

-
フィールドグループが複数あるデータ2: 家族のデータが2件あり、2件目の本人の一部の項目を空欄(5,6行目)
更新ファイルインポート時の設定「レコード更新の強制」を「レコードの作成または上書き」としていたので、2件目のデータで空欄にしていた項目は、空欄で更新されることを想定していました。ですが、空欄にならず値はそのままでした。フィールドグループのデータの追加は行われましたので、そちらの処理が優先されたのかもしれません。ファイルインポートで空欄で更新するパターンは、【4】で改めて実施したいと思います。

-
必須項目が空欄のデータ: 「会員ID」「会員名」以外が全て空欄のデータ(7行目)
必須項目の「会員名(姓)」「会員名(名)」は値が空欄で取り込まれました。なお、このデータを画面から更新する際、ファイルインポート時とは異なり、必須項目が空欄のまま更新するとエラーとなりますので、必須項目に値を設定する必要があります。

-
主キーが重複するデータ:「会員ID」が重複するデータ(8行目)
エラーとなったため、取り込まれていません。 -
フィールドグループの主キーが重複するデータ: 「家族会員ID」が重複するデータ(9行目)
そのまま取り込まれています。ID003のフィールドグループのデータと、ID006のフィールドグループのデータで、「家族会員ID」が重複していますが、「会員ID」(ルート項目の主キー)が異なればOKのようです。

-
データ型と値が不一致なデータ(選択リスト):「性別」に文字列「X」と設定されているデータ(10行目)
「検証エラーのあるインポートされたレコード」のログでエラーとして出力されていましたが、値が空欄で取り込まれました。

-
データ型と値が不一致なデータ(日付、数値): 「生年月日」と「体重」に文字列「不明」と設定されているデータ(11行目、12行目)
エラーとなったため、取り込まれていません。 -
データ型と値が不一致なデータ(ブール): 「有効会員フラグ」に文字列「〇」と設定されているデータ(13行目)
エラーとなったため、取り込まれていません。 -
桁数と値が不一致なデータ(小数): 「身長」に定義された小数以下の桁数を超える値のデータ(7行目、11行目)
エラーとなったため、取り込まれていません。
上記の通り、データ型・桁数に合わないデータは該当する項目が空欄になるのではなく、その1行分が取り込まれませんので、インポート用のファイルを作成する際には、BEの定義に合わない値が含まれていないか、注意が必要です。
一方、必須項目に値が無い状態でも取り込まれてしまうこと、「選択リスト」は値が存在しない場合でも該当する項目が空欄で取り込まれてしまうことも注意点です。
【4】ファイルからデータを更新する
次にMDMへ取り込んだデータに対し、ファイルから更新します。
-
更新用のファイルを準備します
まずは、取り込んだデータに対して変更を行うファイルを作成します。以下のような変更を行います。- 値の変更: 住所を変更します(1件目)
- 値の削除: 住所を空欄にします(2件目)
- データの削除: データを削除します(3件目)
データを削除するには、操作を表す列「Operation Type」を追加し、その項目に「Delete」をセットします。

-
ファイルをインポートします
【2】で実施した方法と同様に、インポートします。②フィールドのマッピングの画面で、ターゲットフィールドの「操作タイプ」という項目(ルート項目とフィールドグループ項目の2か所あります)に、入力ファイルの「Operation Type」をマッピングしてください。

-
インポート結果を確認します
インポートのジョブは正常に完了となり、「エラー行」は0、「トランスフォーメーション」「ロード」「検索用のインデックス」いずれもエラーは0になりました。-
値の変更: 住所を変更します(1件目)
変更した箇所が正しく更新されています。変更していない項目もそのままとなっています。
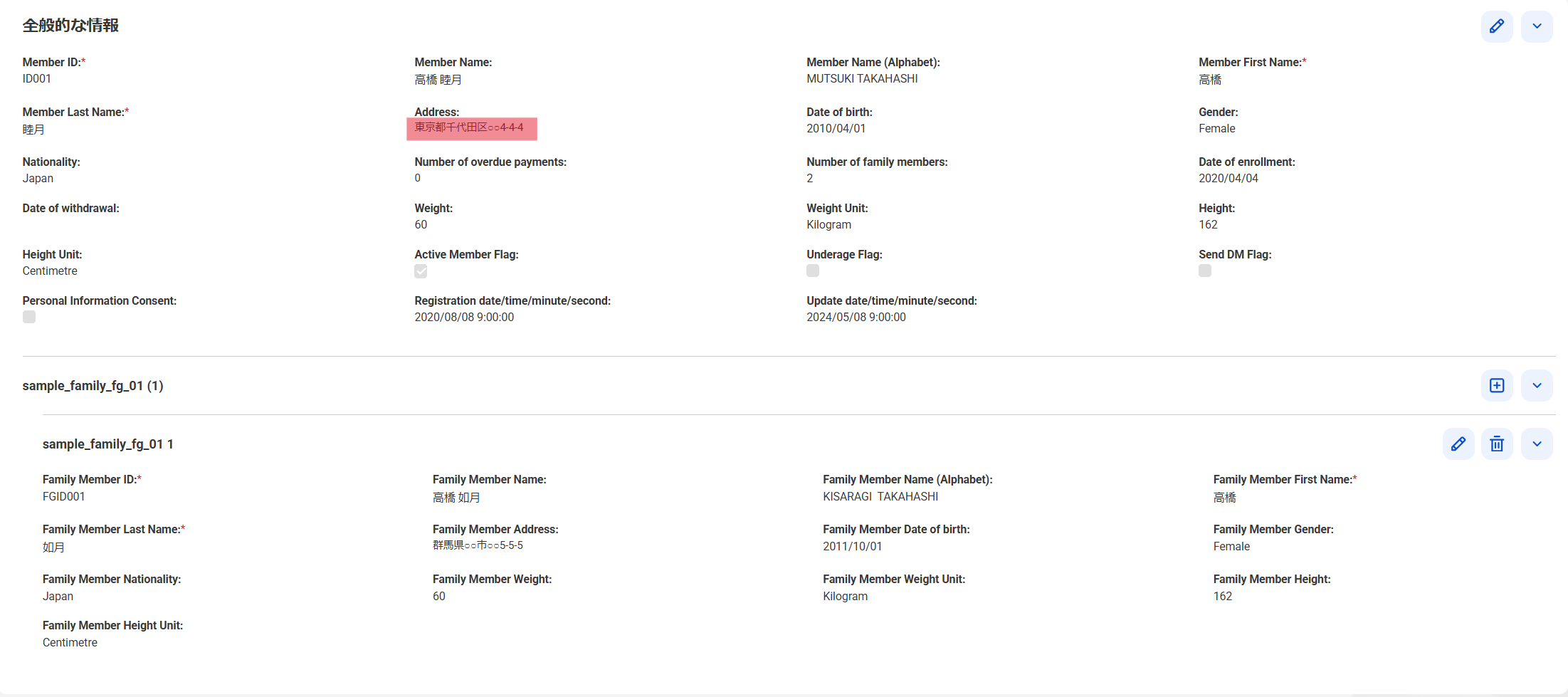
-
値の削除: 住所を空欄にします(2件目)
変更した箇所以外を空欄としたため、値が削除されています。
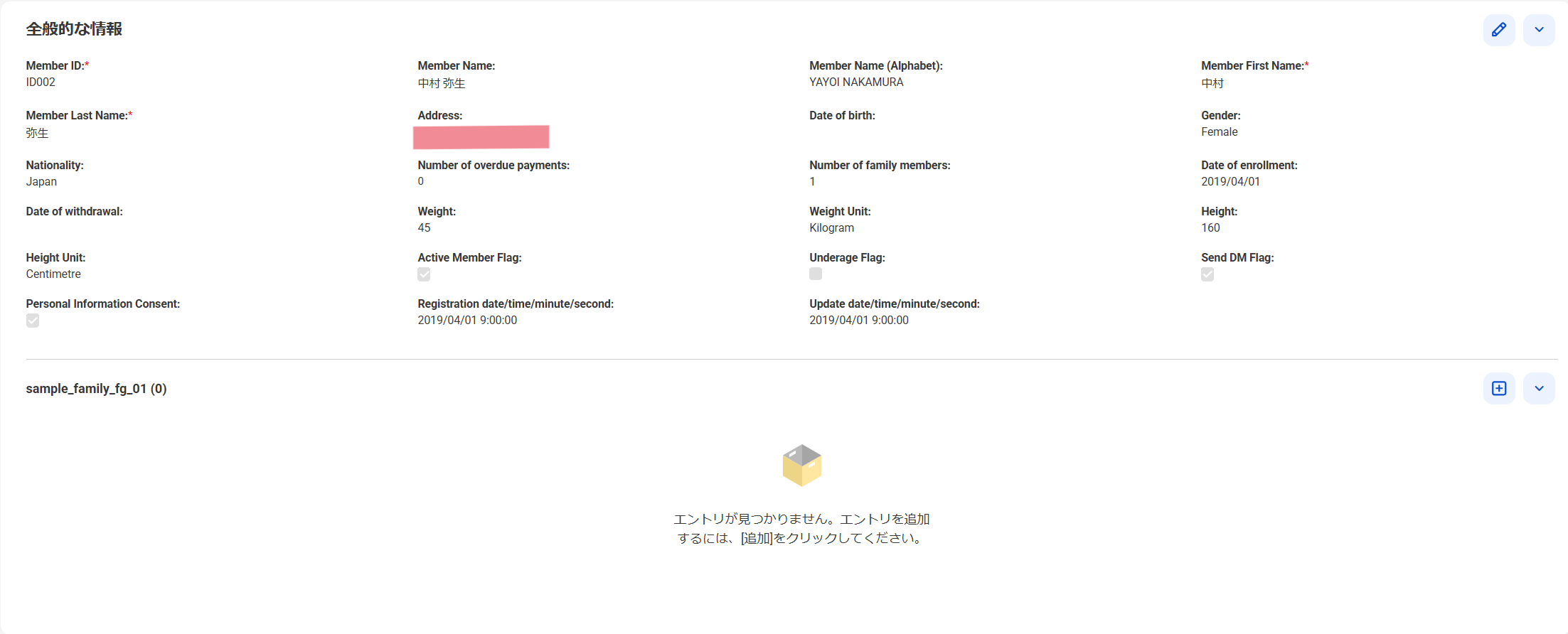
-
データの削除: データを削除します(3件目)
削除すると指定したデータについては削除されています。上と同じ検索方法では、削除したデータは検索結果に表示されないため、左側の「フィルタ」の「レコード状態インジケータ」で「削除済み」を選択し、「アクティブ」のチェックを外します。すると、検索結果に削除した「ID006」が表示されました。「削除済み」というステータスも表示されています。削除したデータは、画面上で参照は可能ですが、更新は行えなくなっています。

なお、削除したデータは画面上の操作で復元させることができますし、同じくファイルインポートでも復元させることが可能です。更新用のファイルを作成し、項目「Source Primary Key」で削除したデータの値をセットして、項目「Operation Type」に「Restore」とセットします。このファイルを同じ手順でファイルインポートすれば可能です。
以上でインポートした結果が確認できました。
-
参考までに、取り込んだデータをエクスポートするとどのようなデータが出力されるか、確認します。
再び、Customer 360の画面の上部の検索窓で、ビジネスエンティティ「Sample_Customer_02」にチェックをいれ、「*」(半角のアスタリスク)を入力して、虫メガネのアイコンをクリックすると、同じく「Sample_Customer_02」に格納されているデータがリストで表示されます。
「検索結果:*(6/6を表示しています)」の右の「∨」をクリックし、メニューから「すべて選択」を選択します。さらにもう一度、「∨」をクリックし、メニューから「エクスポート」を選択します。

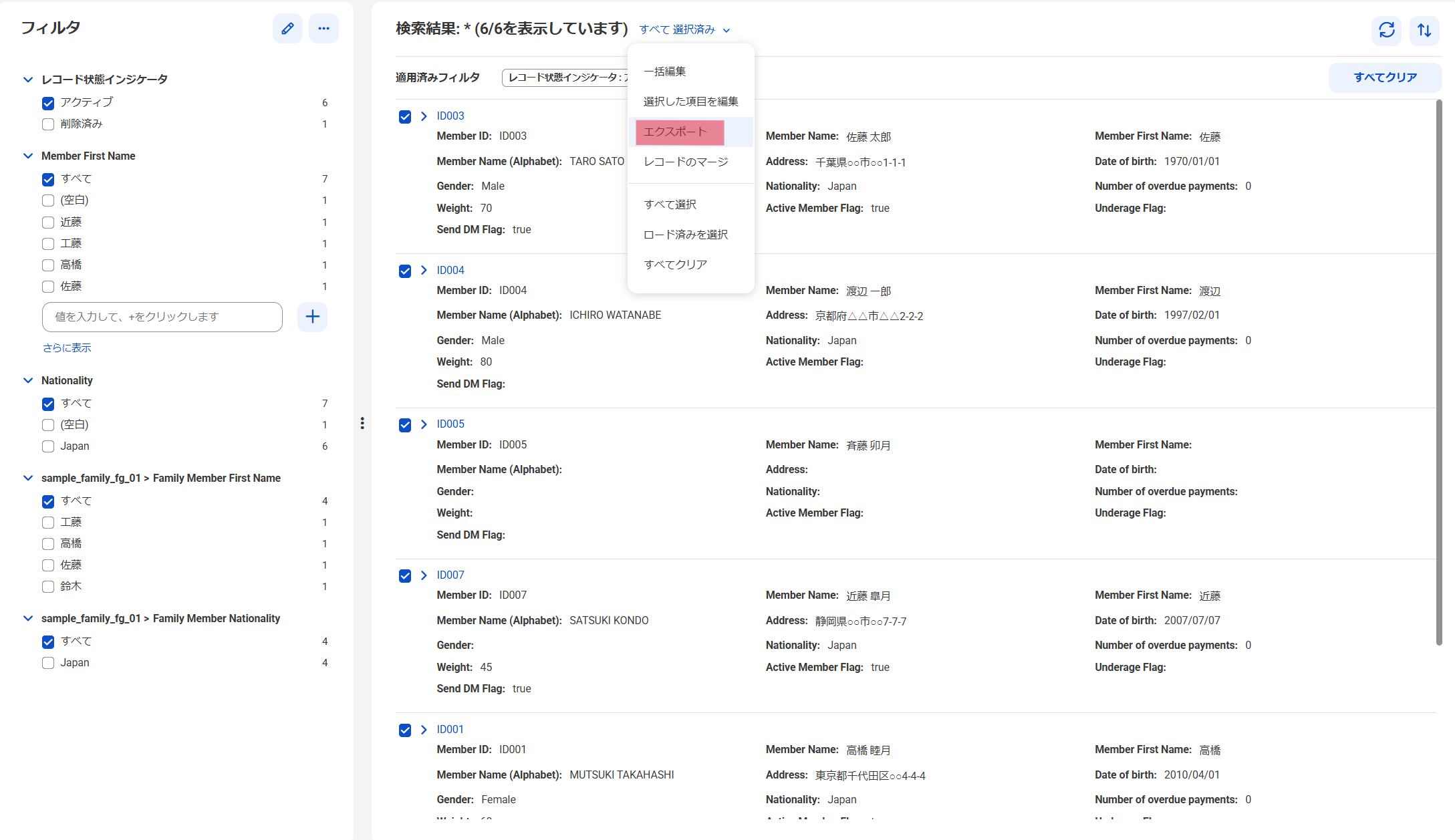
「すべてのレコードをエクスポート」という画面が表示されますので、「エクスポート」ボタンを押下します。すると選択したデータがダウンロードされます。

エクスポートしたファイルの特徴は以下です。
- CSV形式(文字コードはUTF、値はダブルクォーテーションで囲まれています)
- 「検索結果」に表示されている項目のみエクスポートされる
- 「日付」項目は、YYYY-MM-DD の形式
- 「日付と時刻」項目は、エポック秒の形式
- 「選択リスト」項目は、値ではなく、値の名称のみ(Reference 360で登録された値の名称)
- 「ブール」項目は「True」
エクスポートしたファイルを元に更新用のファイルを作成して、インポートによる更新を行うような場合、「日付」「日付と時刻」「選択リスト」「ブール」等の項目は取り込める内容・形式に修正が必要となりますので、注意してください。
ちなみに、ファイルインポートではなく画面から登録したデータも、同じようにファイルインポートによる更新が可能です。画面から登録したデータは、「ソースレコード」を表示する画面(作成されていれば)か、対象のデータをエクスポートすれば、ファイルインポート時に指定する「Source Primary Key」が分かります。この値を使って更新用のファイルを作成し、インポートすることで同様に更新が可能です。但し、ファイルインポート時の「ソースシステムの選択」の設定は、画面からの登録時に設定される「Informatica Customer 360」を選択してください。他のソースシステムを選択してファイルインポートした場合、値の更新はされますが、MDMの内部的な主キーである「ビジネスID」が別の値に更新され、過去の変更履歴等が全て削除されてしまいます(delete + insertを実施したような結果となります)。ご注意ください。
おわりに
MDM SaaSのCustomer 360を使用してファイルインポートでデータを登録・更新する手順を紹介しました。
ファイルインポート機能では、BEの項目名と合った項目名をファイル内に記載しておくことで、自動的にマッピングされますので、比較的簡単にマスタデータを取り込むことができます。またファイルにBEの定義と合わない値がセットされていると、一部の例外を除き、マスタデータに取り込まれない仕様となっているので、マスタデータの品質を確保できます。
冒頭でもお伝えしましたが、実際の業務では、MDMを導入し運用開始する際の初期データ移行や、データ登録や更新をファイルインポートにて実施する運用とした場合などで実施することが想定されますので、この記事が皆様の業務に役立つことを願っています。
なお、シリーズでMDM SaaSの関連で下記の記事が公開されています、もしくは公開予定です。
- InformaticaのMDMでデータマネジメント 〜BE作ってみた+標準(新規登録、参照更新)画面〜
- マスタデータを守る ‐ データ品質(入力チェック)の定義 ‐
- ユーザ要望に沿った画面を作る(UI/UXの追求) ‐ カスタム画面の作成 ‐
- ユーザの入力を補助する ‐ データ品質(入力補助)の定義 ‐
本記事を読んでInformaticaのMDMが気になった方は、是非、関連記事もご覧ください。
仲間募集中!
NTTデータ ソリューション事業本部 デジタルサクセスソリューション事業部 では、以下の職種を募集しています。
1. 「クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)」
クラウド/プラットフォーム技術の知見に基づき、ITアーキテクトまたはPMとして、DWH、BI、ETL領域における、ソリューション開発の推進や、コンサルティング工程のシステムグランドデザイン策定時におけるアーキテクト観点からの検討を行う人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=808
2. AI/データ活用を実践する「クラウド・ソリューションアーキテクト」
AI/データ活用を実践する「クラウド・ソリューションアーキテクト」として、クラウド先進テクノロジーを積極活用し、お客様のビジネス価値創出活動を実践。AI/データ活用の基本構想立案コンサルティングからクラウドプラットフォーム提供・活用を支援しています。お客様のAI・データ活用を支援するクラウド・ソリューション提案、アーキテクチャ設計・構築・継続活用支援(フルマネージドサービス提供)、および最新クラウドサービスに関する調査・検証で、クラウド分析基盤ソリューションのメニュー拡充を実施する人材を募集します。
https://nttdata.jposting.net/u/job.phtml?job_code=807
また、取り扱う主なソリューションについては、以下のページも参照ください。
ソリューション紹介
1. NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。2. Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。