はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 で AWS や Databricks を推進している nttd-saitouyun です。
6月に開催された Data + AI Summit で発表された Apache Hive メタストア と AWS Glue Data Catalog に対する Lakehouse Federation が 先日 2024年12月11日にリリースされました。
Data + AI Summit 2024 - Keynote Day 2 - Full(Youtube) より
今回は、AWS Glue Data Catalog に対する Lakehouse Federation を検証をしてみようと思います。
AWS Glue Data Catalog は、AWS が提供するマネージドのHiveメタストアです。AWS Glue 以外にも、Amazon EMR、Amazon Athena などのテーブルの管理にも利用することがきます。
なので、今回の機能アップデートでは、AWS のアナリティクスサービスの幅広いデータを Databricks から参照できるようになります。
Lakehouse Federation
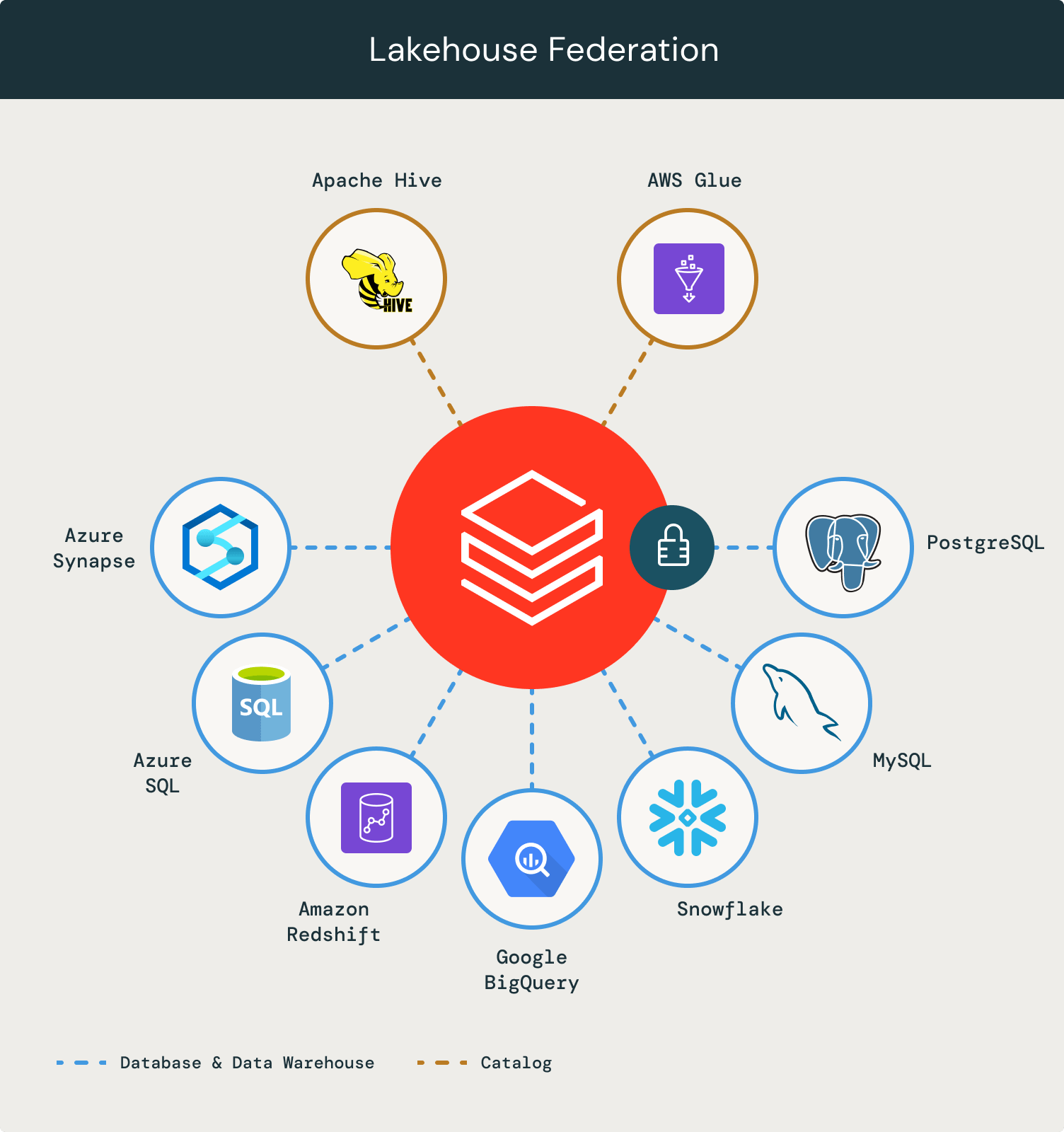
Lakehouse Federation / データの仮想化という技術が生まれた背景や課題感などついては以下の記事まとめています。
Databricks から AWS Glue Data Catalog につないでみる
それでは、Lakehouse Federation で AWS Glue Data Catalog に接続する手順を見ていきます。
マニュアルは以下の通りです。
全体の流れをマニュアルより細かく整理してみました。
AWS と Databricks の作業を行ったり来たりするため少し複雑です。
-
IAMロールの作成
- IAMロールの作成(AWS)
- IAMポリシーの作成(AWS)
- 自己引き受け型ロールの適用ポリシーの設定(AWS)
-
サービス資格情報の作成
- サービス資格情報の作成(Databricks)
- IAMロールの信頼関係の修正(AWS)
-
接続・外部カタログの作成
- 接続の作成(Databricks)
- 外部カタログの作成(Databricks)
それでは、少し長いですが、1つずつ手順を見ていきます。
IAMロールの作成
Databricks が AWS Glue Data Catalog を操作するための IAMロールを作成します。
IAMロールの作成(AWS)
AWS 側の作業です。
IAMのサービスページから「カスタム信頼ポリシー」を選択し、IAMロールを作成します。
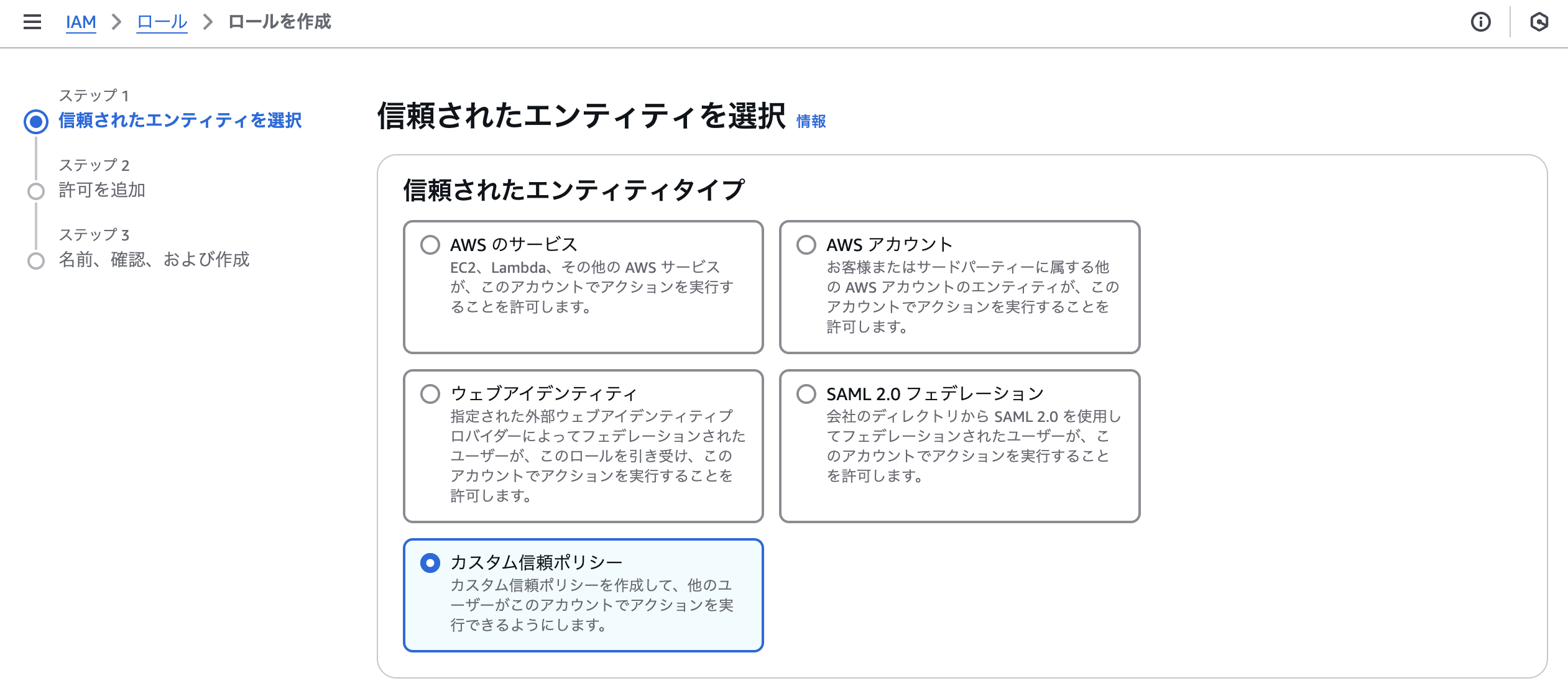
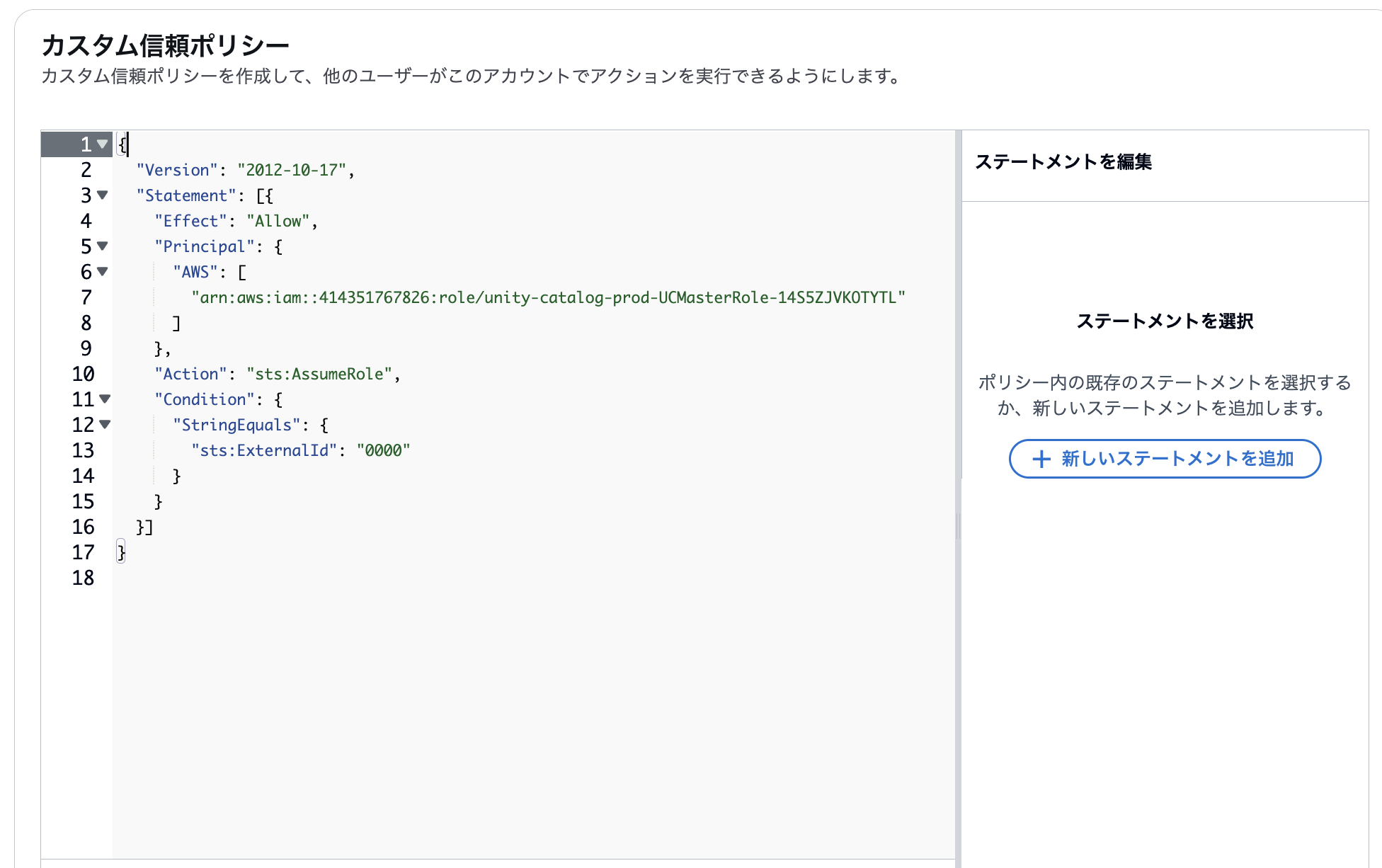
マニュアルに記載のある通り、以下のJSONをカスタム信頼ポリシーとして設定します。
※ExternalIdの「0000」は後の工程で修正するための仮の値です。
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"
]
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "0000"
}
}
}]
}
以下のように貼り付け、次の設定へ進みます。
「許可を追加」のページは何も設定せずに次へ進みます。
「名前、確認、および作成」ではではロール名を入力し、ロールを作成します。

IAMポリシーの作成(AWS)
引き続き、AWS側の作業です。
同様に、IAMポリシーを作成します。AWS Glue と AWS Secrets Manager 用の2つのポリシーを作成し、先ほど作成したロールに割り当てます。
ポリシーエディタにマニュアルに記載のあるJSONを貼り付けます。リージョン、アカウントID、ロール名は自分の環境に合わせて修正が必要です。
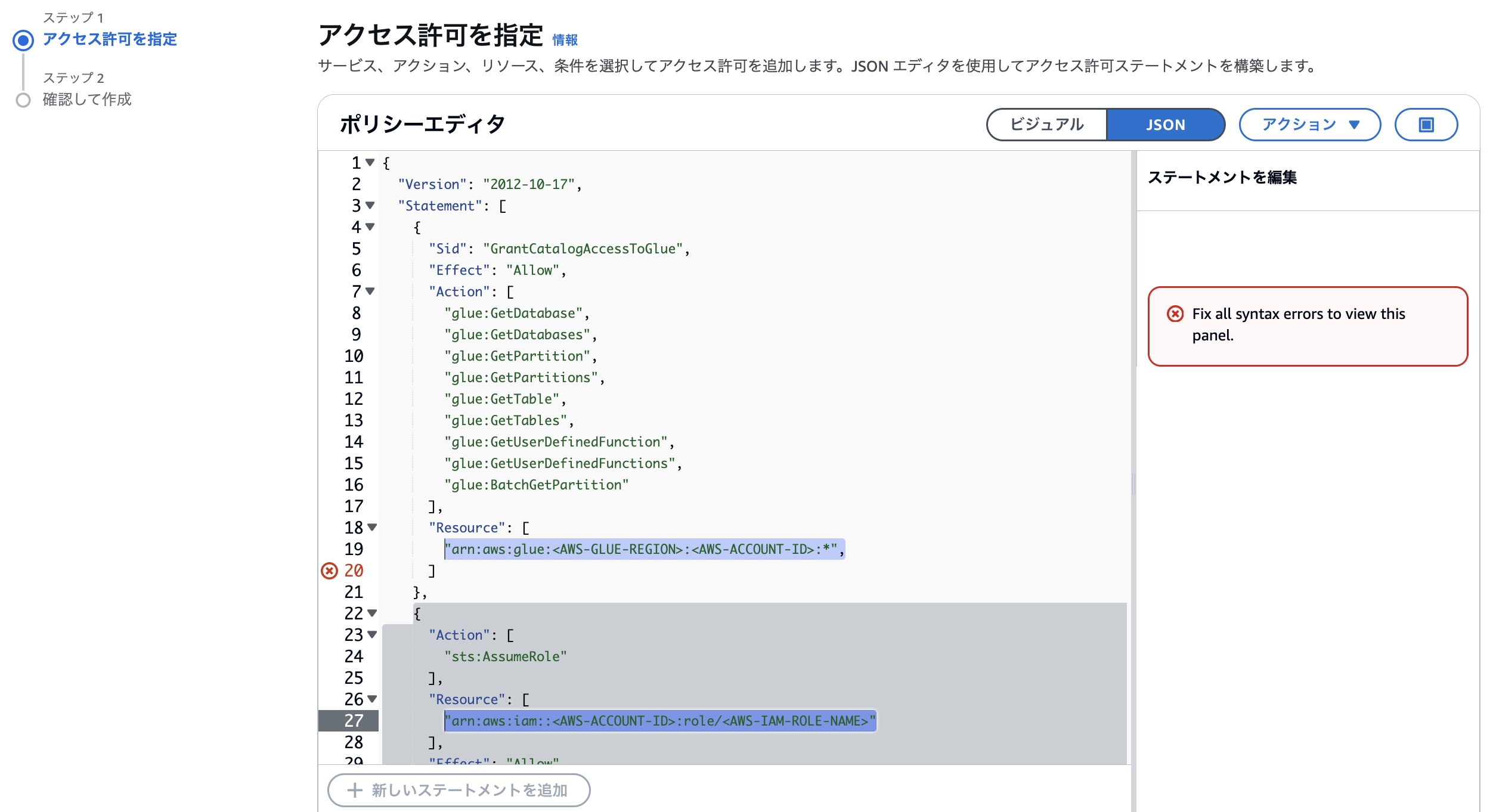
AWS Glue のポリシーは、上記の通り、そのまま貼り付けるとエラーになります。19行目の末尾の「,」は不要ですの削除してください。(そのうち修正されることを期待)
次のページに進み、ポリシー名を入力し、ポリシーを作成します。
2つのポリシーが作成できたらロールにアタッチします。
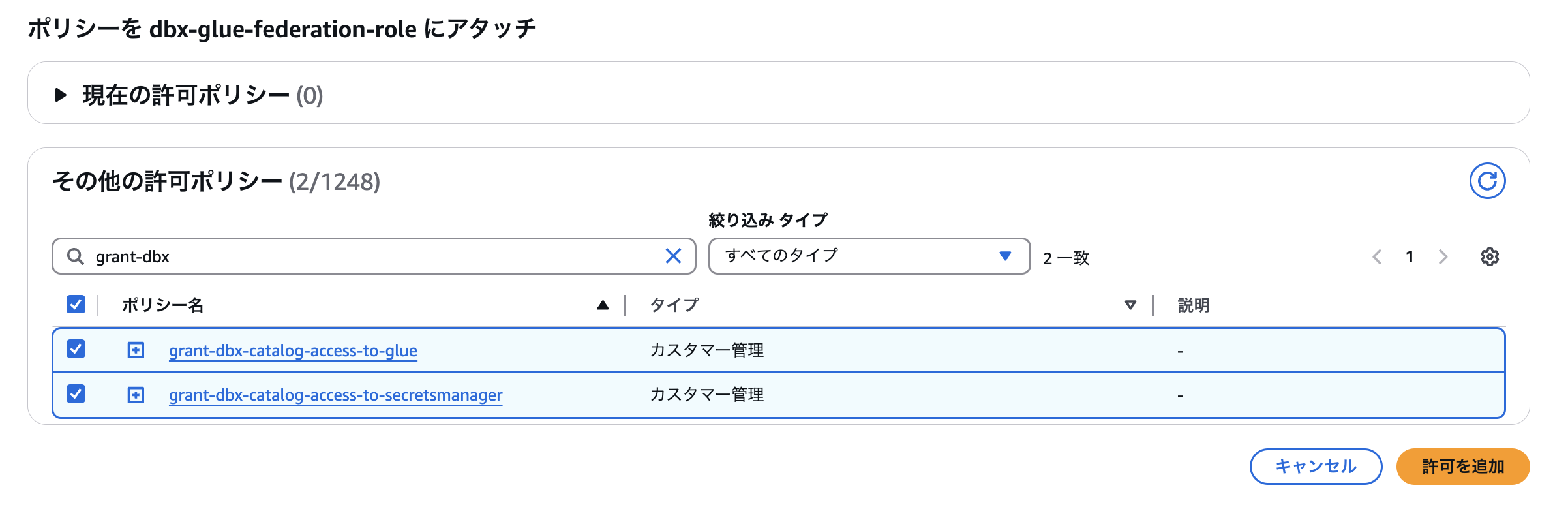
自己引き受け型ロールの適用ポリシーの設定(AWS)
引き続き、AWS側の作業です。
マニュアルのこちらに記載がある通り、自己引き受けの設定が必須となっていますので、ロールの「信頼関係」タブから信頼ポリシーを修正します。
以下のように自分自身のロールを信頼関係に含めます。
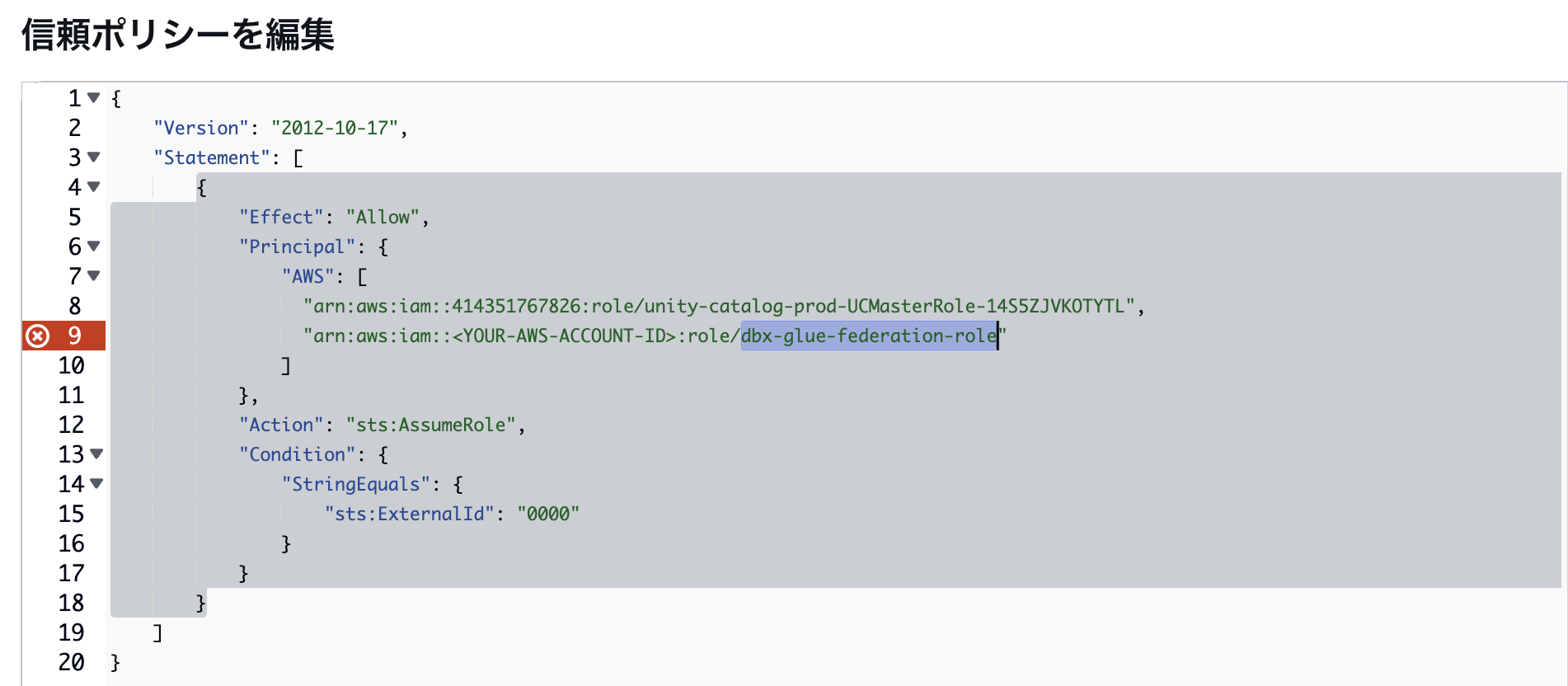
※図はAWSアカウントIDを入れていないのでエラーになっています。こちらの修正も忘れずに。
サービス資格情報の作成
作成したIAMロールを Databricks 側で扱うための「サービス資格情報」オブジェクトを作成します。
サービス資格情報の作成(Databricks)
Databricks側の作業です。
「資格情報」を選択。
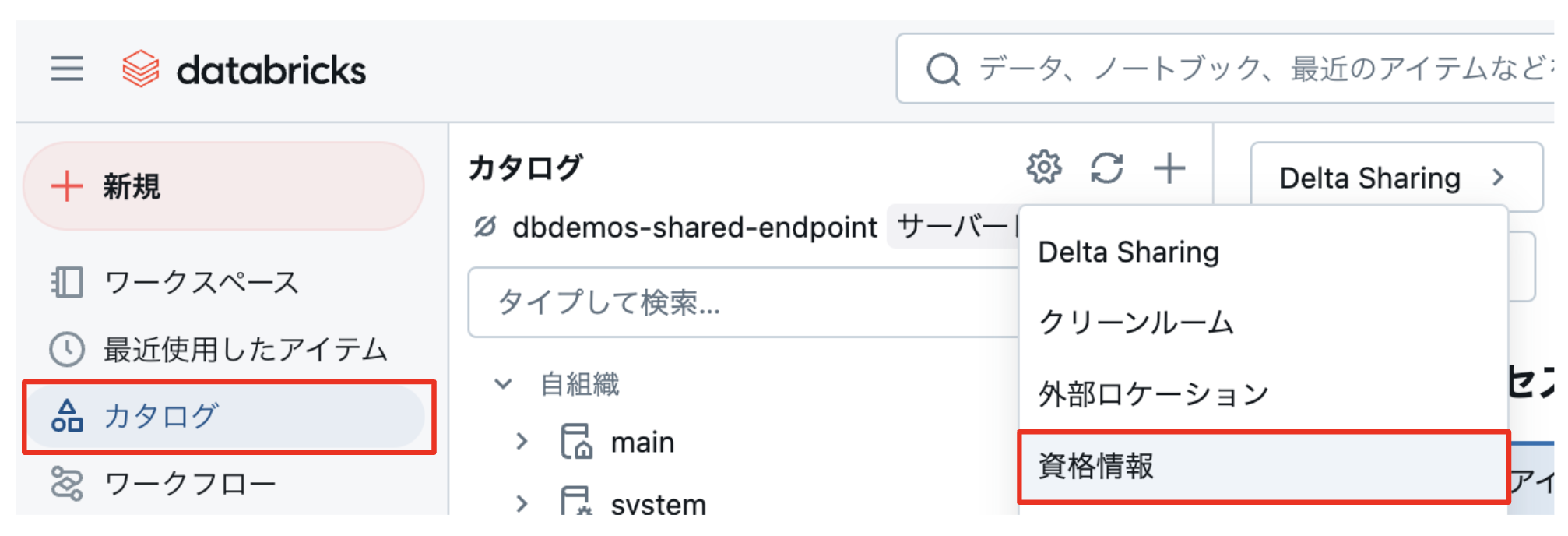
「サービス資格情報」を選択し、名前を入力します。
前ステップで作成したIAMロールのARNをコピペしてオブジェクトを作成します。
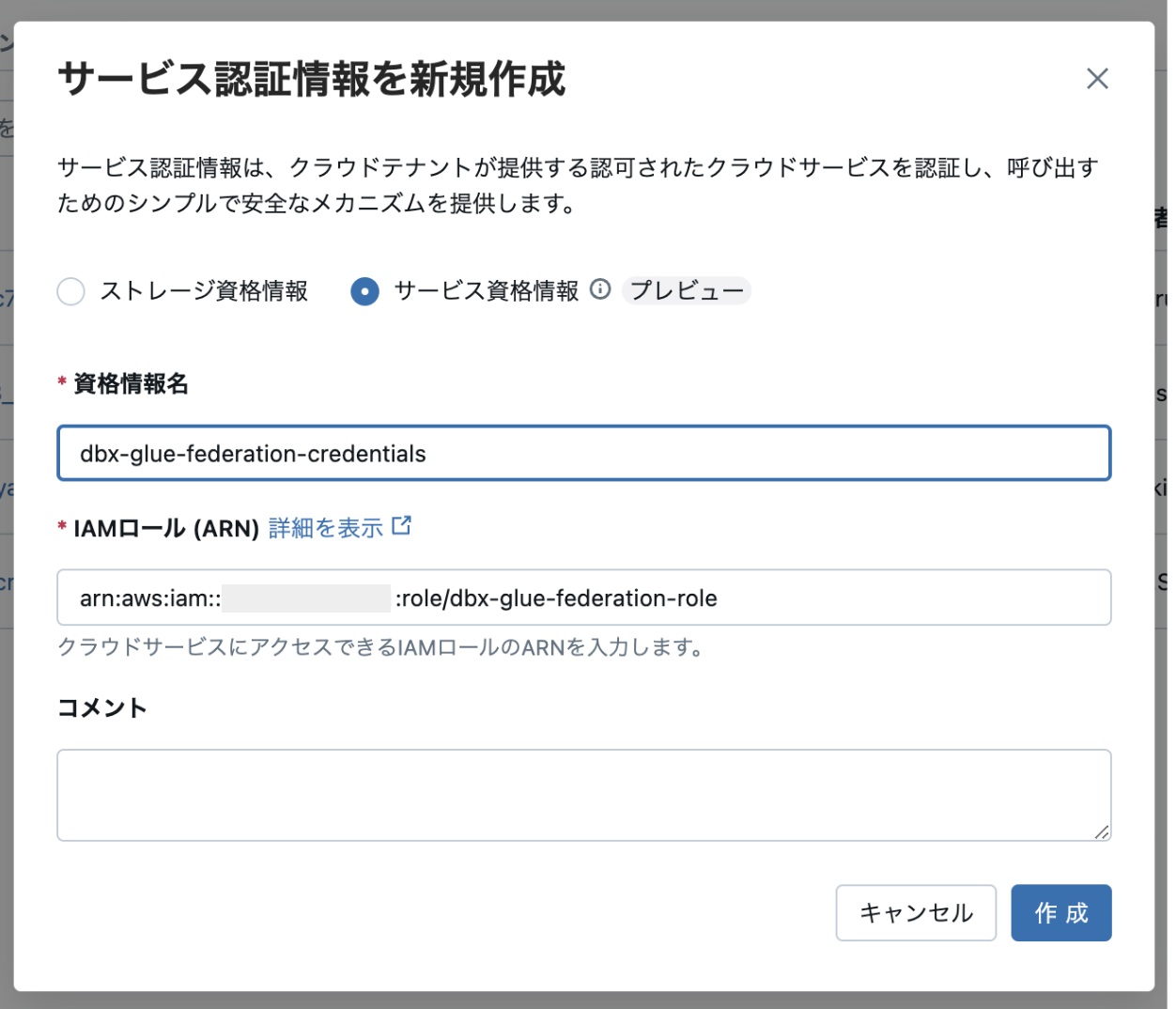
作成すると「外部ID」が以下の通りに払い出されます。
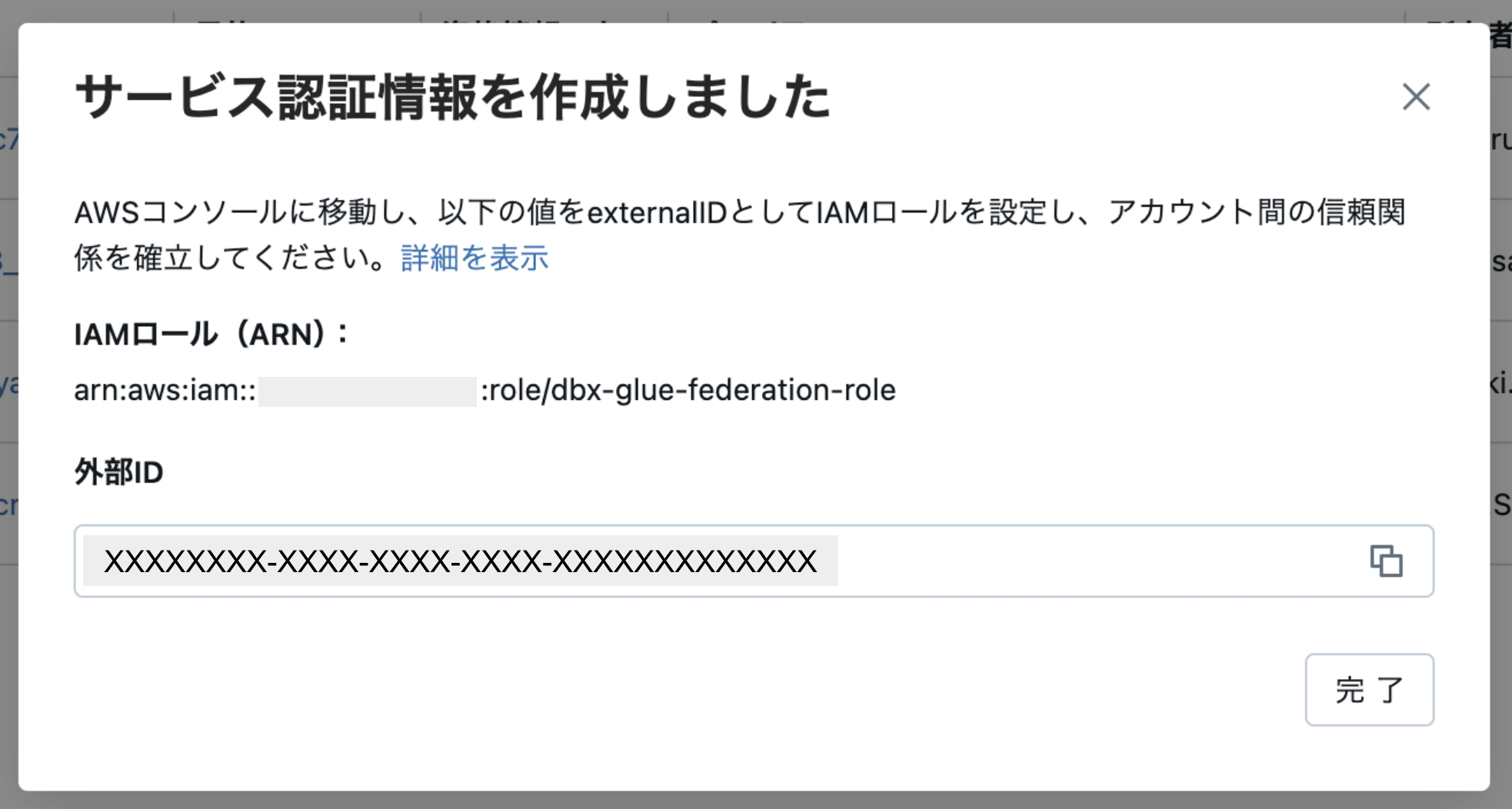
「作成しました」とありますが、実はまだ「サービス資格情報」の設定は終わっていらず、この外部IDをAWS側の設定に反映させる必要があります。
現段階で「構成を検証」を実行すると AssumeRole できずに以下のようなエラーになります。
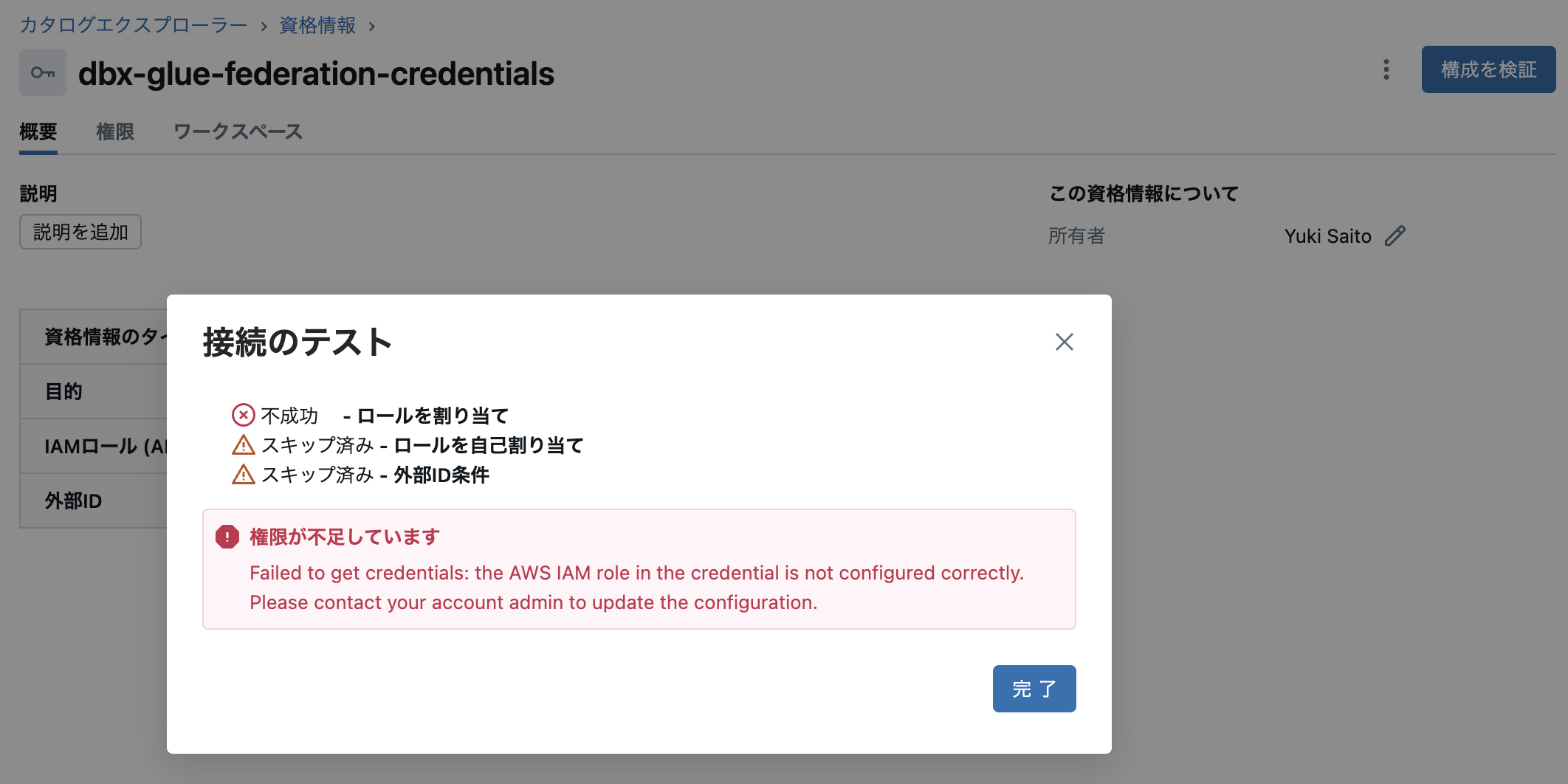
IAMロールの信頼関係の修正(AWS)
再びAWS側の作業です。
IAMロールの「信頼関係」タブから信頼ポリシーを修正します。ExternalIdを仮の値である「0000」から前ステップで払い出された値に置換し、ポリシーを更新します。

改めて、Databricks側に戻り、「サービス資格情報」の設定画面から「構成を検証」を実行します。以下のようにテストが成功すればOKです。
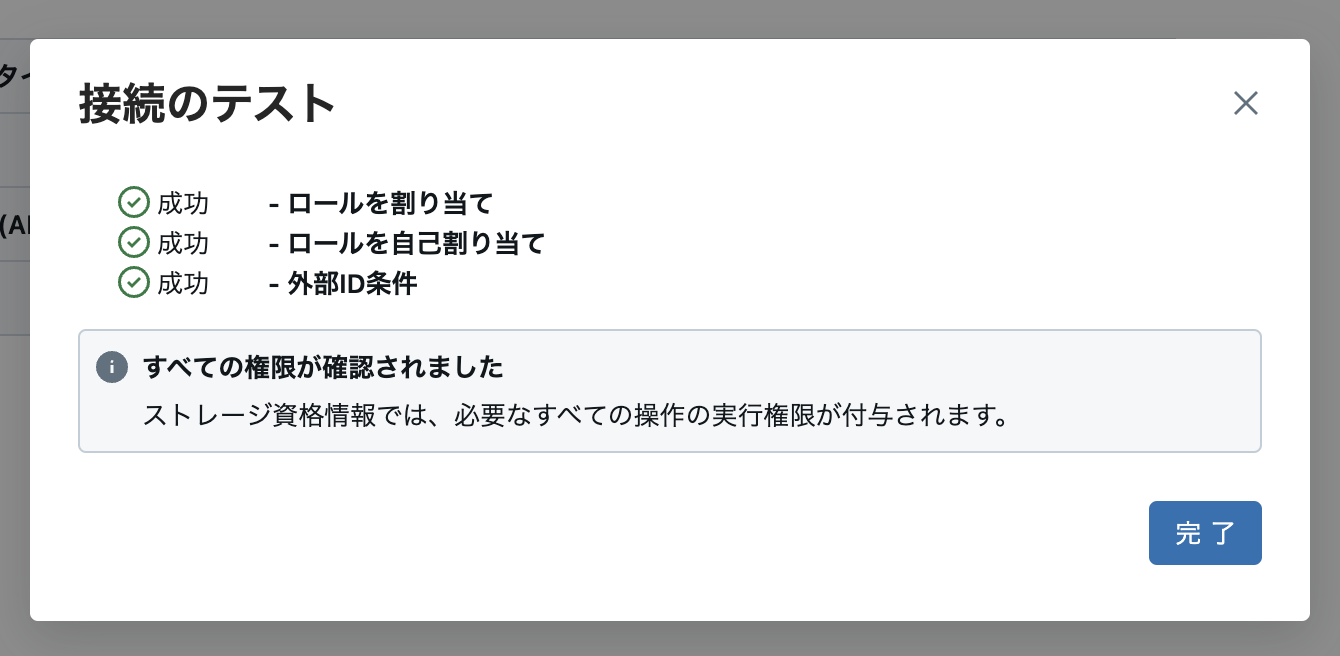
これで事前準備が完了しました!
行ったり来たりするので、慣れていない方には難しく感じたかもしれません。
接続・外部カタログの作成
それでは、Lakehouse Federation の設定を行っていきます。
接続の作成
Databricks側の設定です。
以下のように「接続」を選択します。
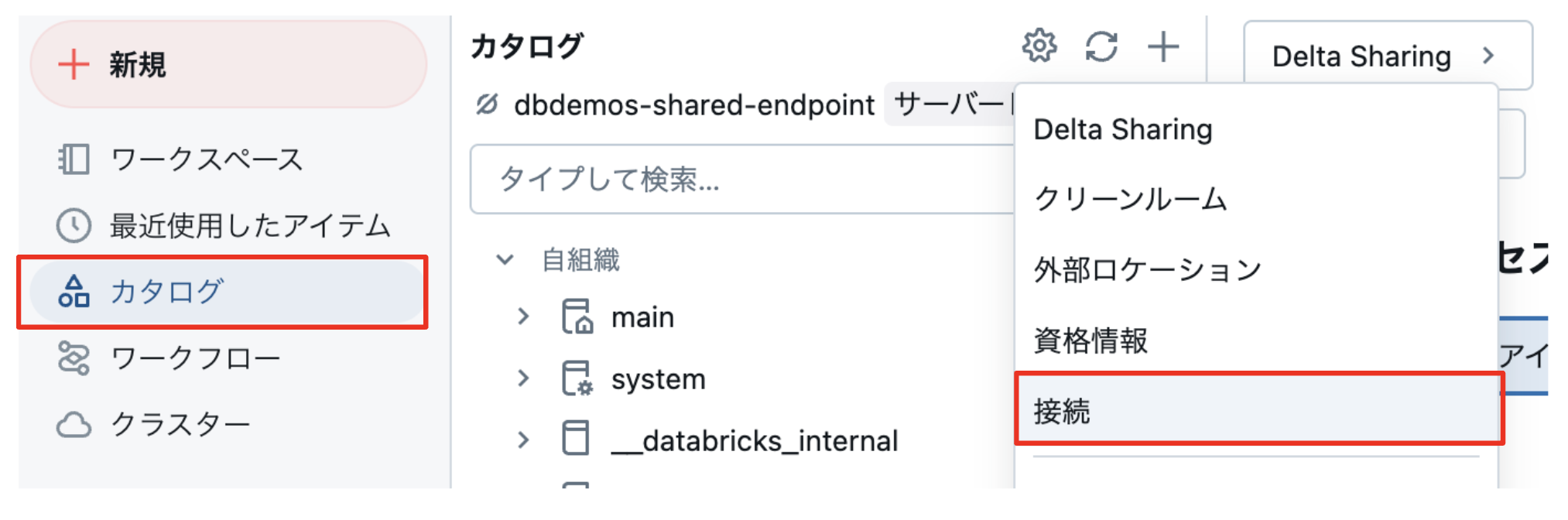
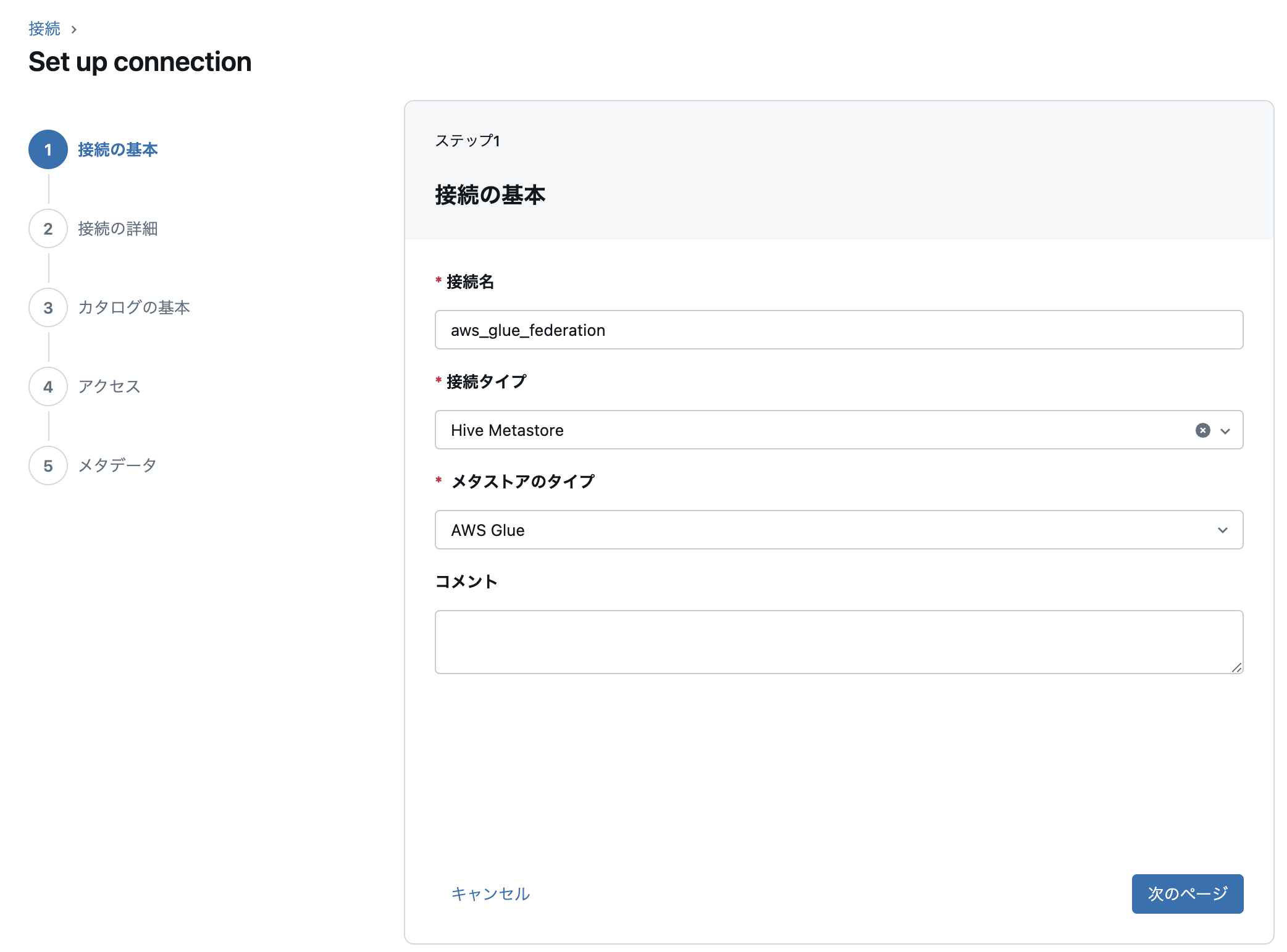
接続名を入力し、接続タイプに「Hive Metastore」、メタストアタイプに「AWS Glue」を選択します。
続いてAWSの情報と前工程で作成したサービス資格情報を指定します。
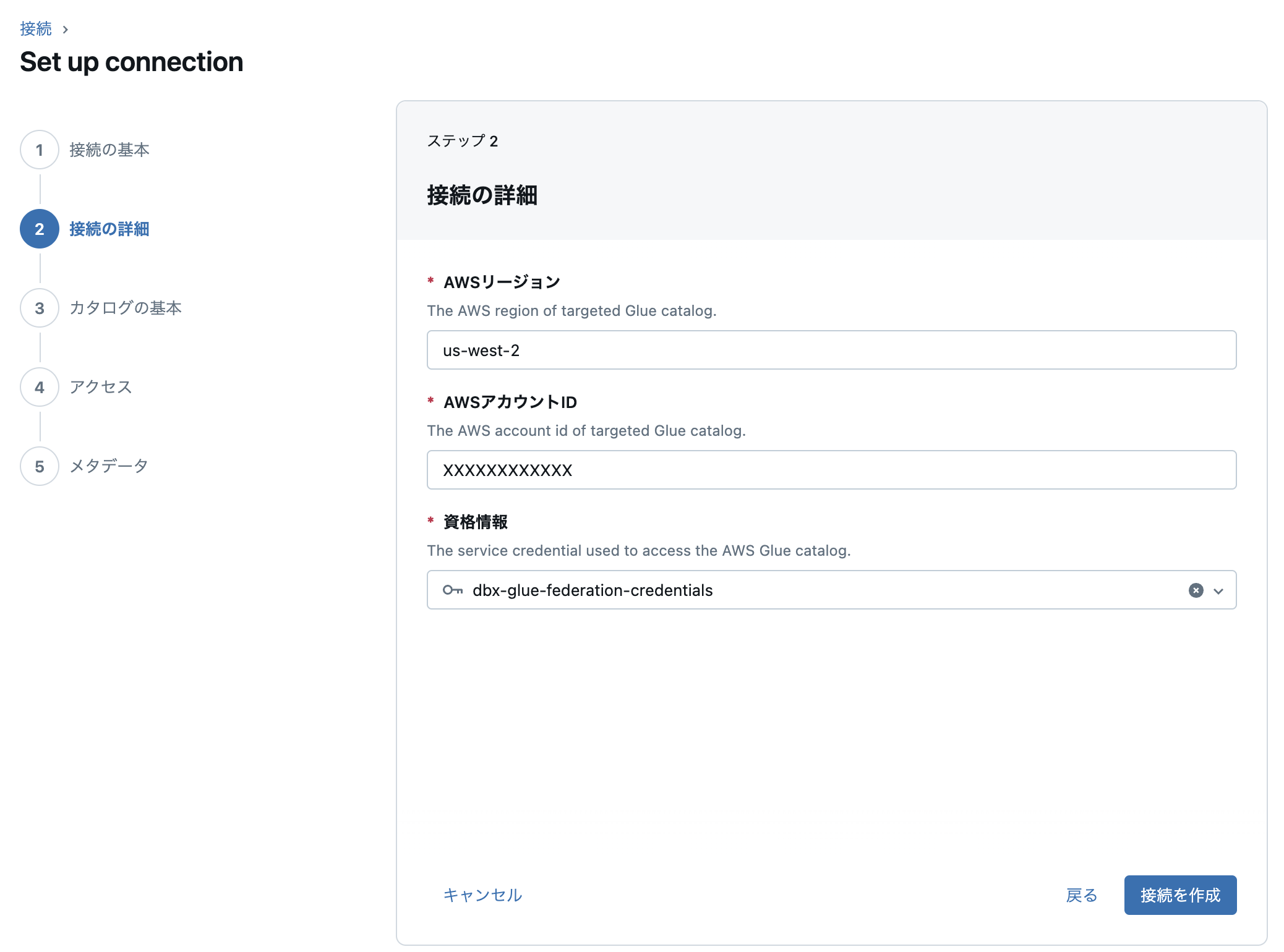
「接続の作成」から接続の作成が成功すればOKです。そのままカタログの作成に移ります。
カタログの作成
引き続き、Databricks側の設定です。
カタログ名と外部ロケーションを指定します。こちらは普通のカタログの設定と同様です。
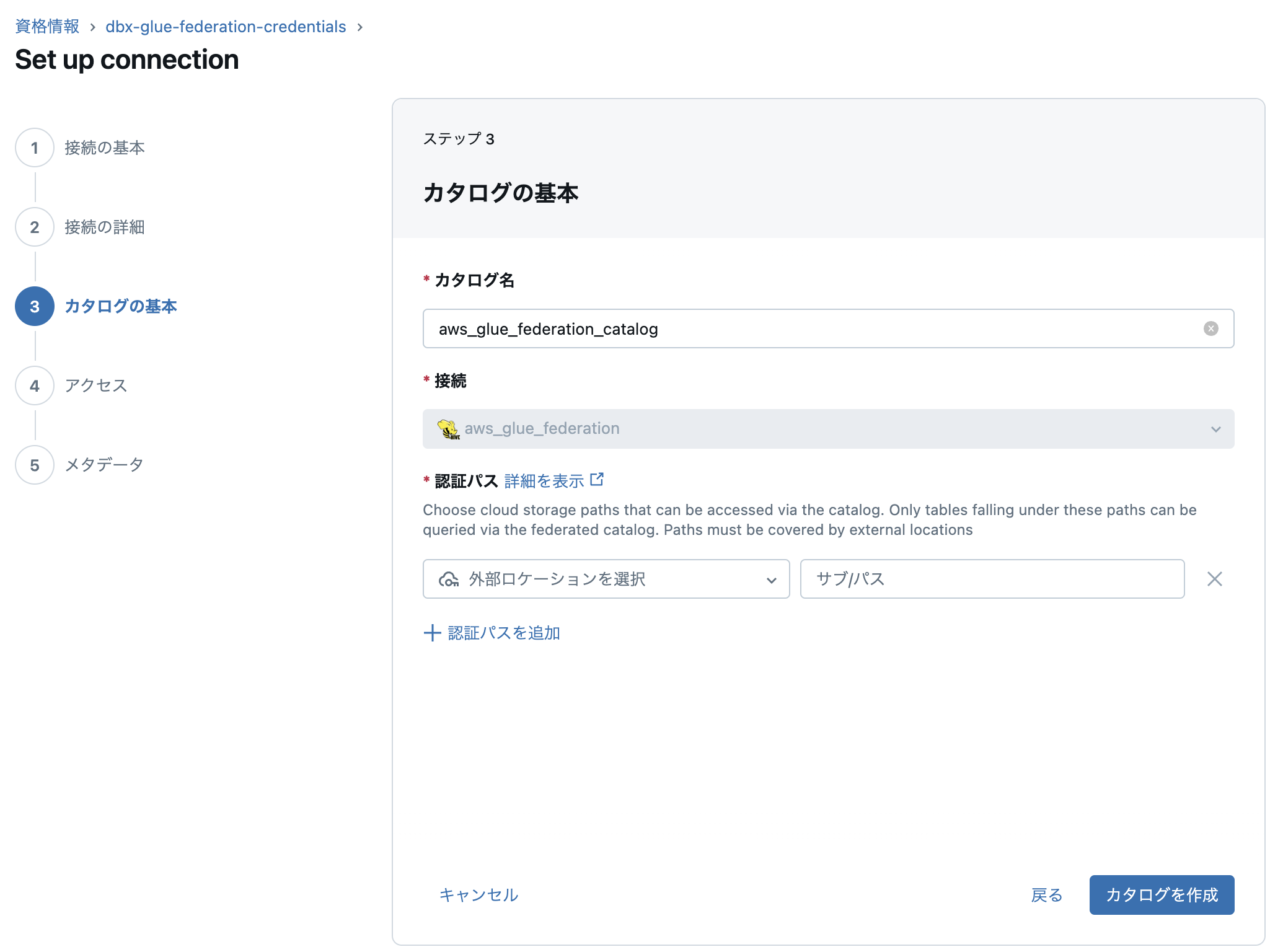
アクセス権の設定です。ここはデフォルトで進めます。
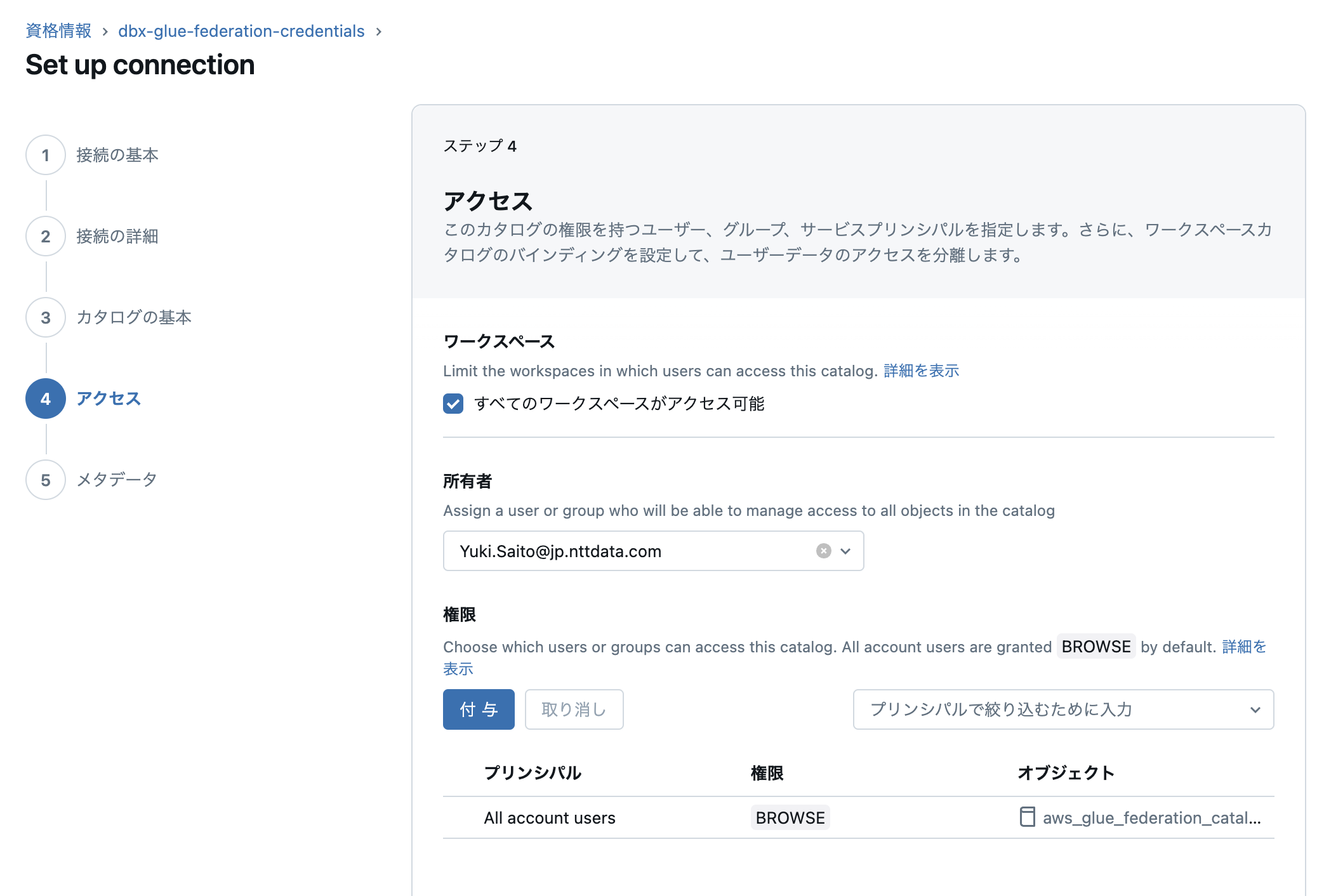
最後にカタログに対するメタデータの設定です。ここは何も設定せずに「保存」を押します。
これで正常にカタログが作成されれば Lakehouse Federation の設定は完了です!
Databricks から AWS Glue Data Catalog のデータを参照する
それでは Databricks から AWS Glue Data Catalog のデータを参照してみます。
Amazon Athena でテーブルを作成する
AWSのコンソールから Amazon Athena のサービスページを開き、クエリエディタからテーブルを作成します。
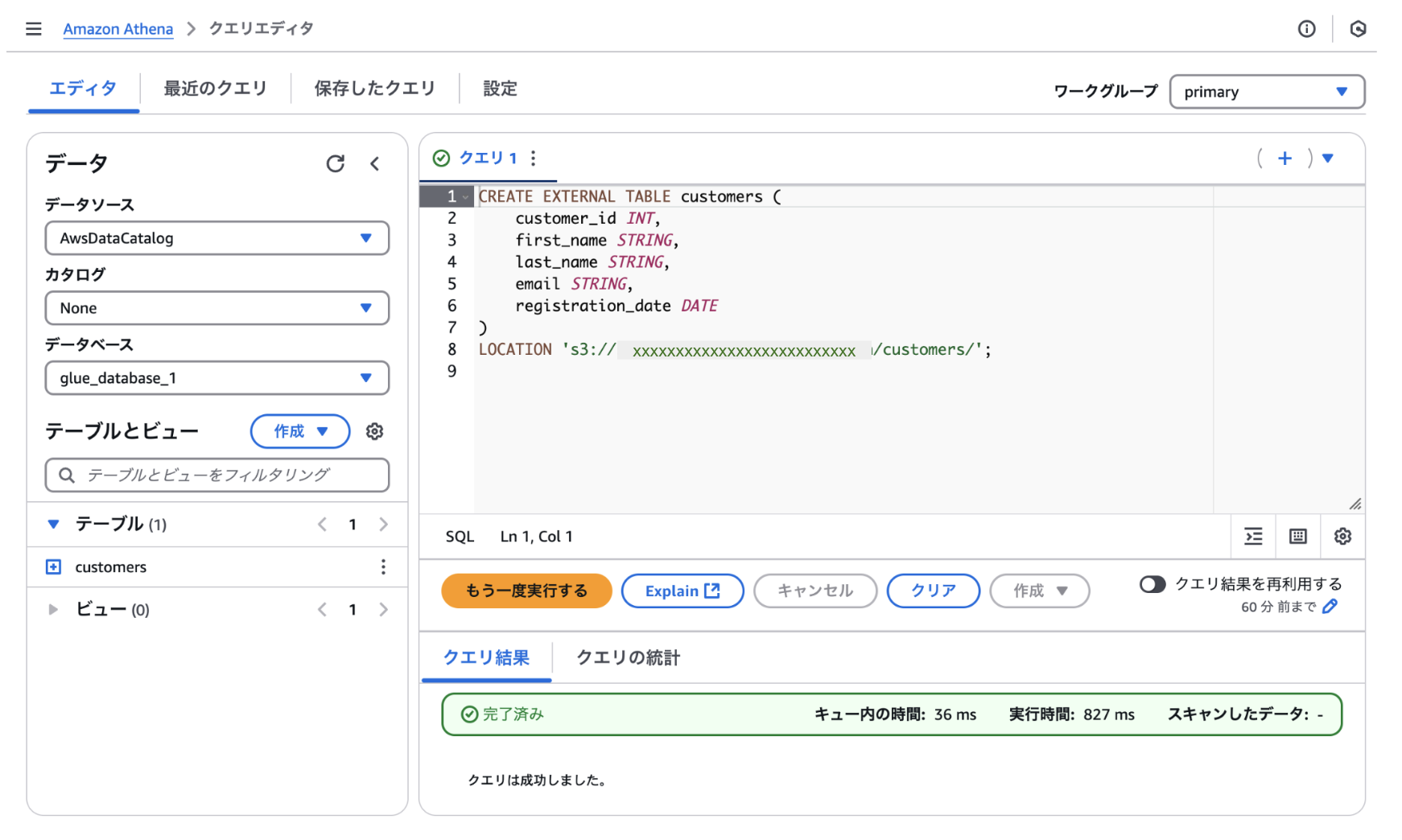
カタログエクスプローラーからテーブルを確認
作成したテーブルが Databricks から参照できました!
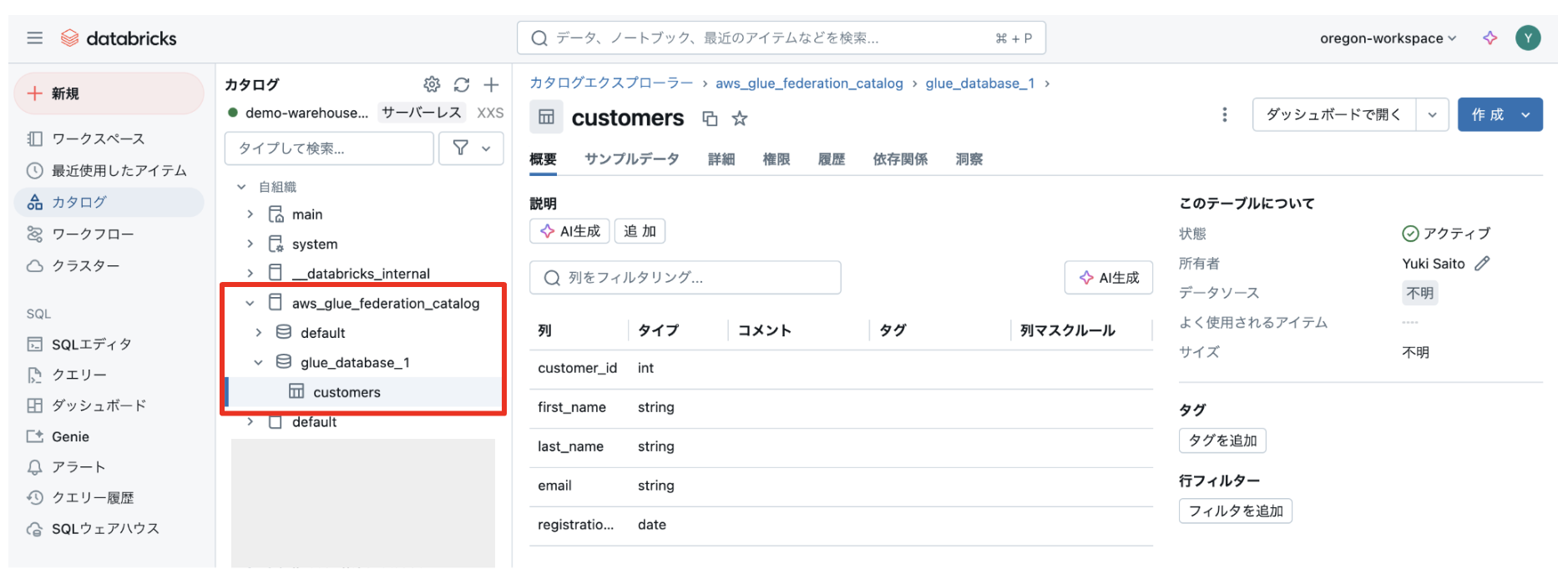
Databricks, Amazon EMR, Amazon Athena, AWS Glue, Amazon Redshift、Amazon RDS など、あらゆるデータソースを Databricks で一元管理できます。
Amazon Athena でテーブルにデータを登録する
続いて、Amazon Athena からデータを登録し、Databricks から見えることを確認します。
適当なサンプルデータをLLMで生成し、INSERTします。
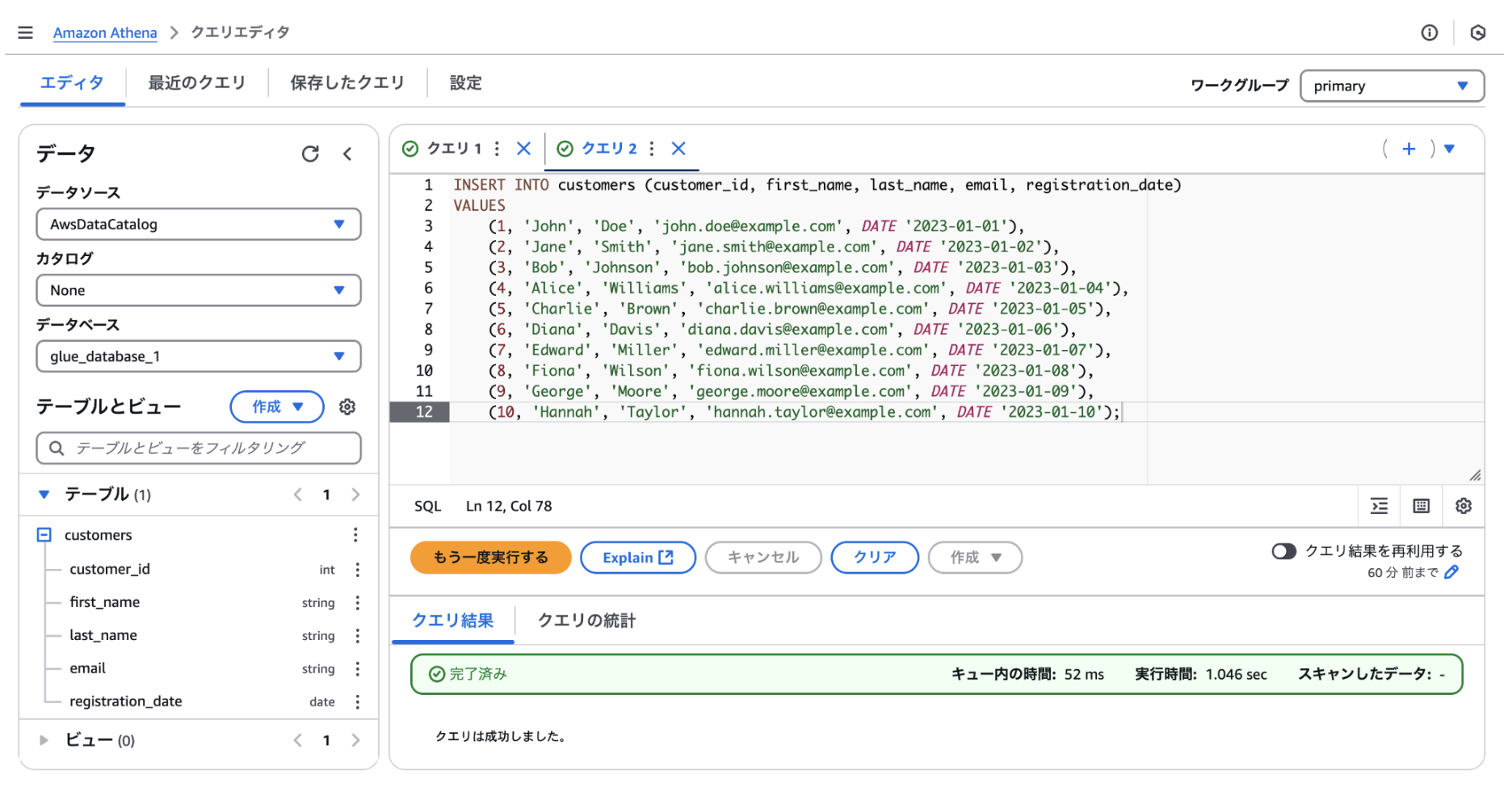
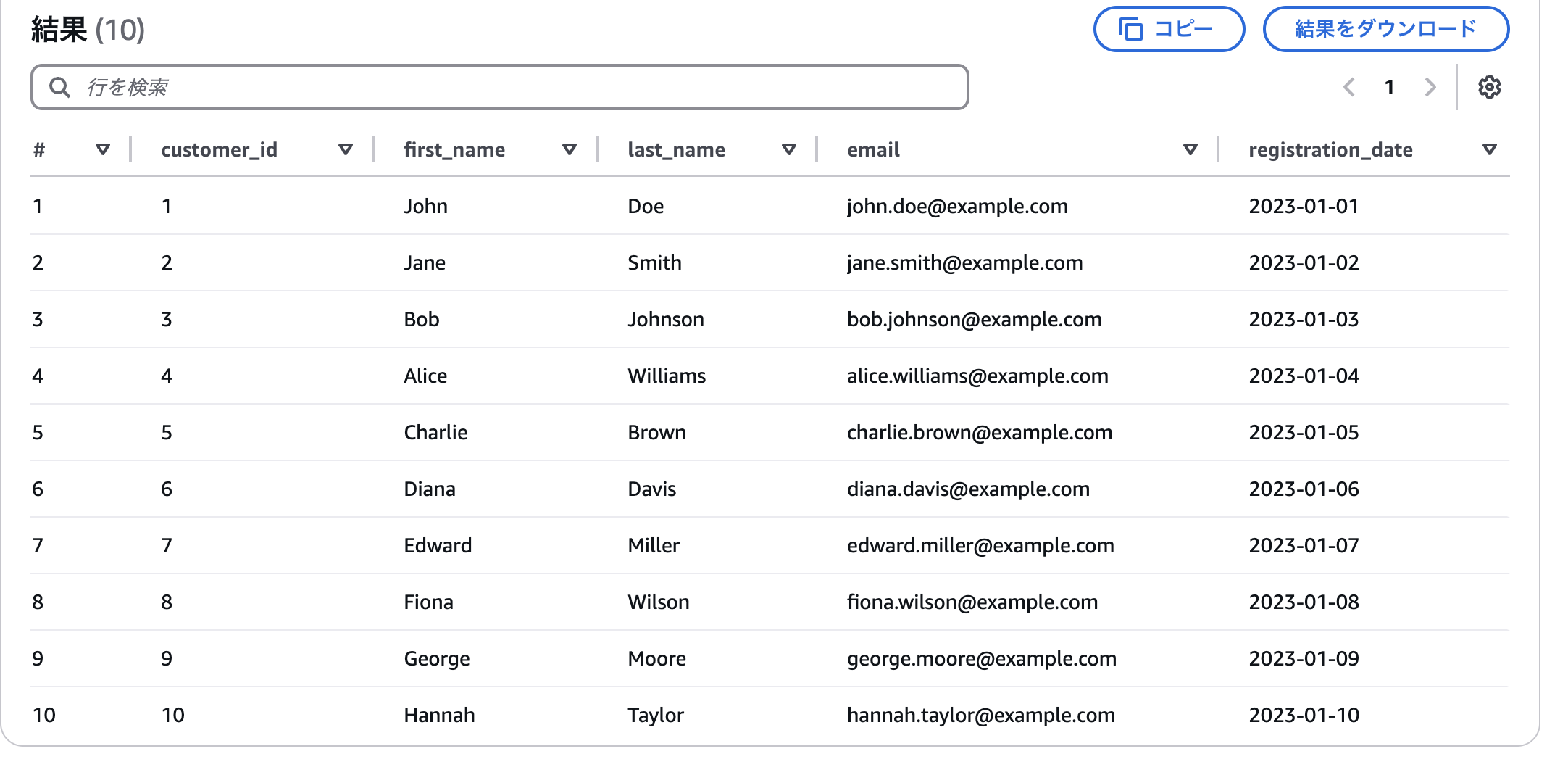
Amazon Athena から SELECT * FROM customers でデータを見てみます。
ちゃんとデータが入っていることを確認できました。
カタログエクスプローラーからデータを確認
カタログエクスプローラーからcustomersテーブルを選択し、「サンプルデータ」タブを表示してみます。
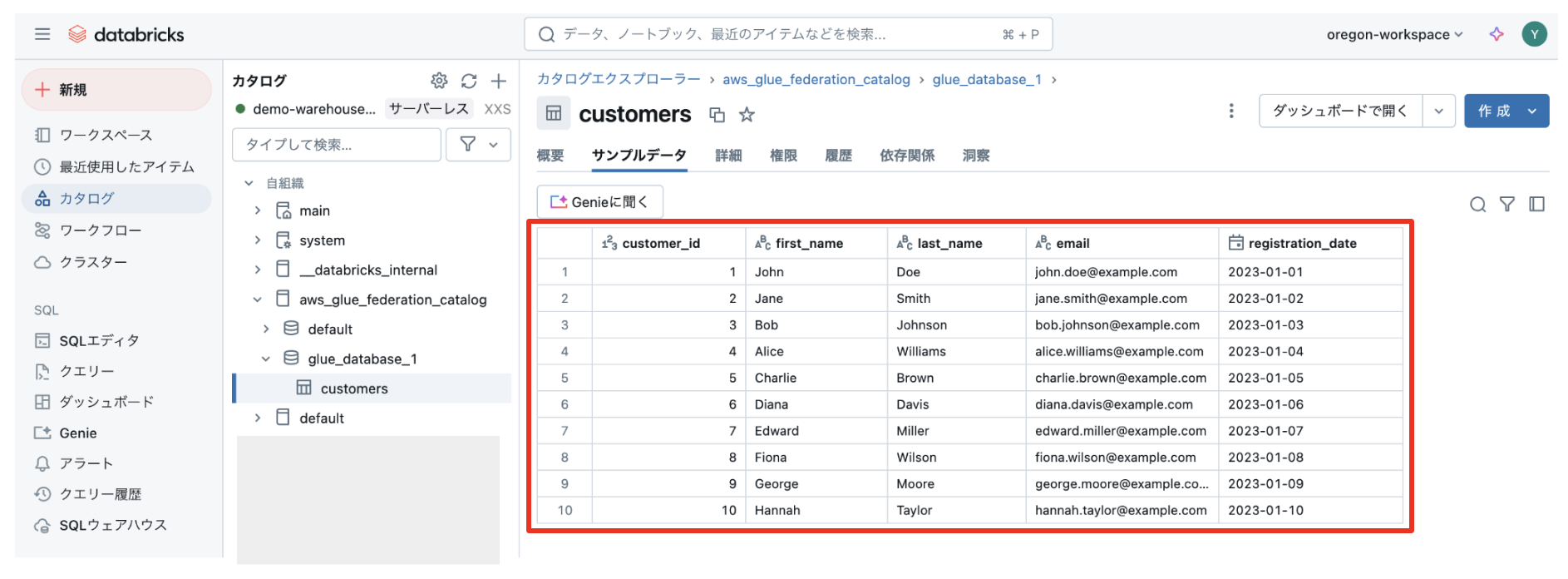
先ほど Amazon Athena のページから見た結果と同じ結果が得られました!
おわりに
これまでも S3 上のデータを共有することで、AWS Glue や Amazon Athena などの AWSマネージドサービス と Databricks は連携をすることはできました。
今回、さらにデータカタログ層も統合されることでよりシームレスなデータ統合が可能になりました。
すでに何らかのAWSサービスを使っているケースも多いと思います。
本書が、Lakehouse Federation を活用し、より活用のしやすいデータプラットフォームを実現するヒントになれば幸いです。
他にも Databricks の記事を書いていますので、ぜひご覧ください!!
先日 AWS re:Invent 2024 で発表された、データとAIのオールインワン・データプラットフォームである次世代 Amazon SageMaker についてもブログも書いております。ぜひご覧ください!!!
AWS最新サービス「Amazon SageMaker Unified Studio」をいち早く解説! ~オールインワン・データプラットフォームの台頭~
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。