はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 で AWS や Databricks を推進している nttd-saitouyun です。
先月の8月1日に Lakehouse Federation が GAされました。今回はこの機能を活用して、Snowflake に接続してみたいと思います。
Lakehouse Federation
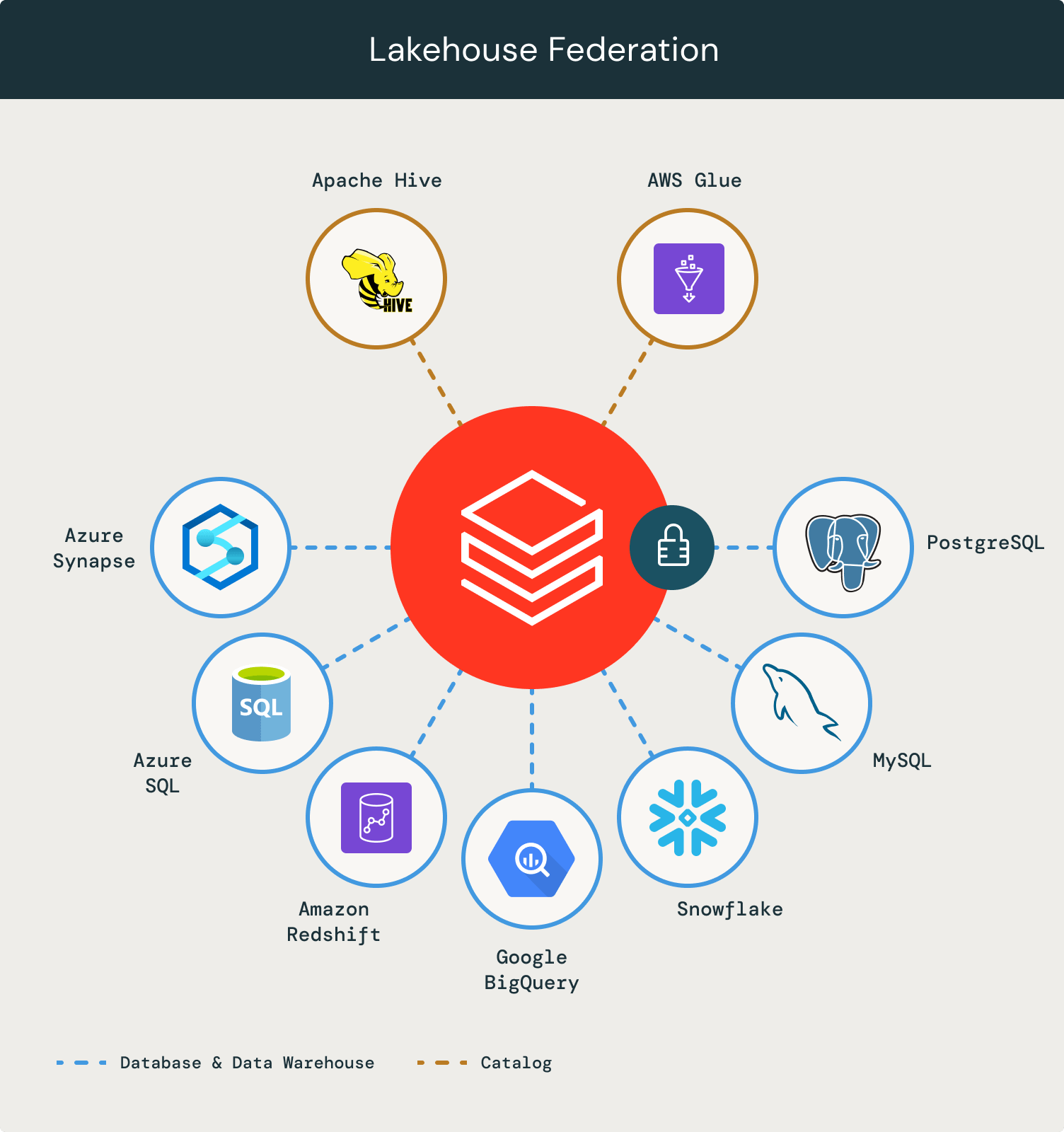
Lakehouse Federation / データの仮想化という技術が生まれた課題感はこちらに記載のあるとおりです。
世界中の組織は、規模や業界に関係なく、データとAIを活用して革新を推進しています。しかし、歴史的、組織的、技術的な理由から、データはしばしば複数の運用および分析システムに分散して残っています。
技術的だけでなく、歴史的、組織的と記載されているところが的を得ていますね・・・
本当は統合したいとは思っていても、いろいろな理由ですぐには難しいことは実際に多いと思います。
しかし、この問題を放置してしまうと以下のような問題が発生してしまいます。
この断片化はいくつかの課題を引き起こします:
- すべてのデータを発見し、アクセスするのが難しい
- エンジニアリングのボトルネックによる実行の遅延
- サイロ化されたシステム全体でのコンプライアンスの弱さ
複数のデータソースを管理したことがある方はよくわかるかと思います。
-
システム管理者は、複数のデータソースに同じようなグループ・ロールを作って、ユーザを払い出し、管理を行わなければならないですし、どのデータソースにどのようなデータが保存されているかも管理しないといけません。
-
ユーザも、複数のユーザ・パスワードで、複数のWeb UIやコマンドプロンプトを開き、どこに何があるのか考えながらデータ処理を作らなければなりません。
そのため、全部のデータをローカルに一度ダウンロードしているようなケースもよく見かけます。
これでは、管理の煩雑さや使いにくさでデータ活用やデータ分析に集中できません。
そこで、Lakehouse Federation の出番です。マニュアルに記載の通りの効果が見込まれます。
レイクハウスフェデレーションは、以下のような用途に適しています。
- Databricksにデータを取り込みたくない
- クエリで外部データベースシステムのコンピュートを活用したい
- きめ細かなアクセス制御、データのリネージ、検索など、Unity Catalogのインターフェースとデータガバナンスのメリットを活用したい
いろいろ書いてありますが、3つ目が重要です。仮想的に複数のデータソースを1元化し、データを管理しやすく、使いやすくすることができます。
前置きが長くなりましたが、実際に設定や利用のイメージをご紹介していきます!
Databricks から Snowflake につないでみる
それでは、Lakehouse Federation で Snowflake に接続する手順を見ていきます。
全体像は以下のようになっています。
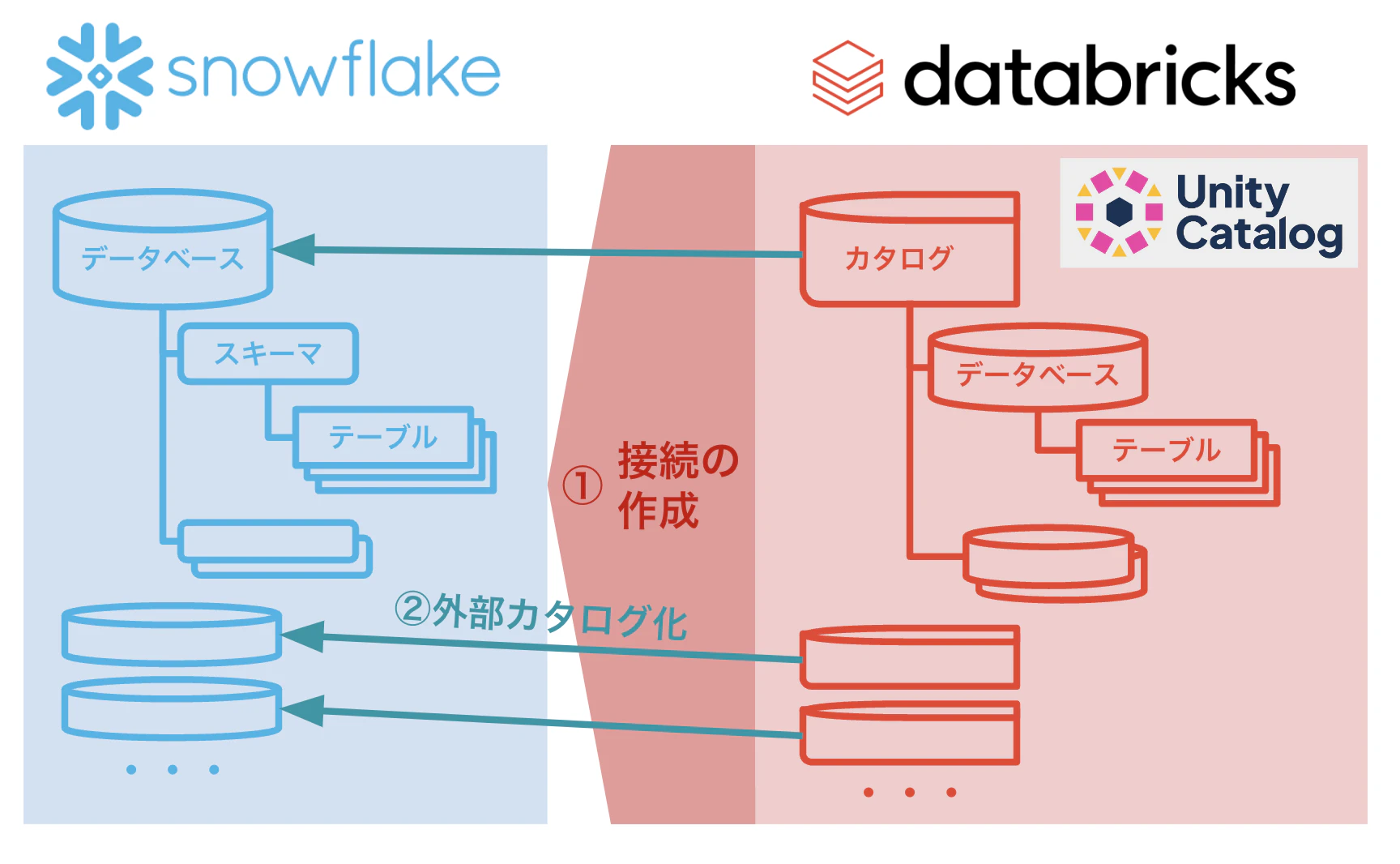
まず、Snowflake につなぐための定義である「接続」を作成します。
次に作成した接続を使って Snowflake の データベースを Databricks の Unity Catalog 内の「外部カタログ」として定義していきます。
データベース/スキーマの考えが Snowflake と Databricks とで違うので混乱しないように注意しましょう。
接続の作成
カタログエクスプローラーから歯車マークを選択し、「接続」をクリックします。
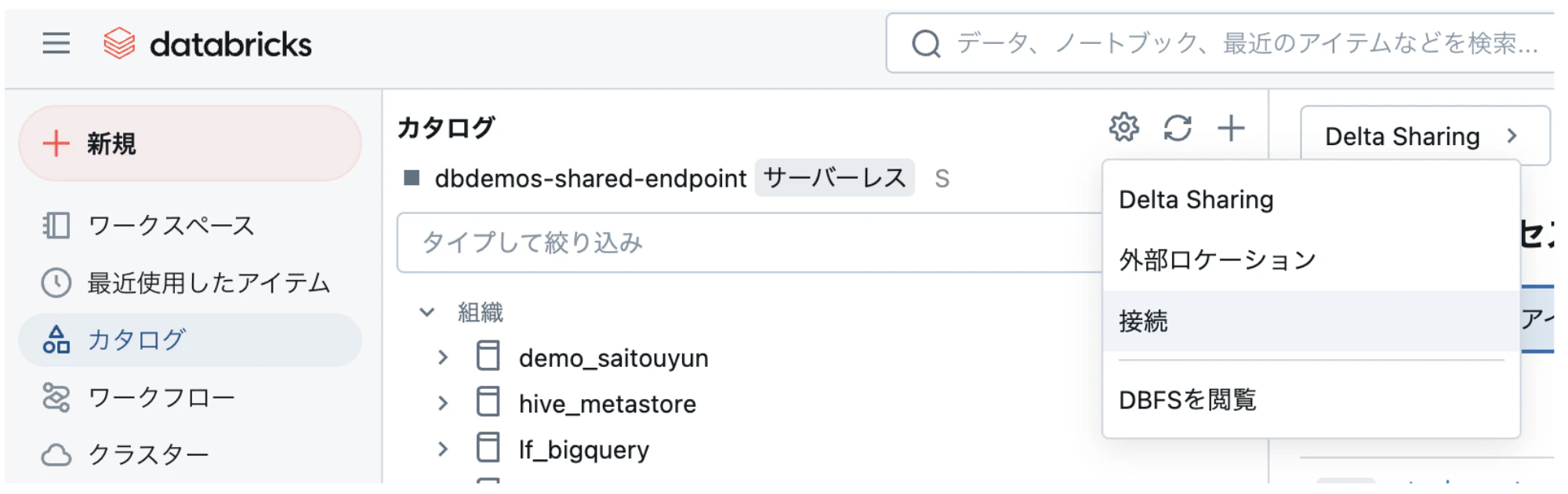
以下の権限が必要になりますので「接続」が表示されない方は管理者に問い合わせてみてください。ガバナンスの観点から接続の作成は強権限を持つユーザに制限されているケースが多いと思います。
接続を作成するには、メタストア管理者か、ワークスペースに接続されているUnity Catalogメタストアの CREATE CONNECTION 権限を持つユーザーである必要があります。
接続名と接続タイプ
任意の接続名を入力し、接続のタイプから Snowflake を選択します。
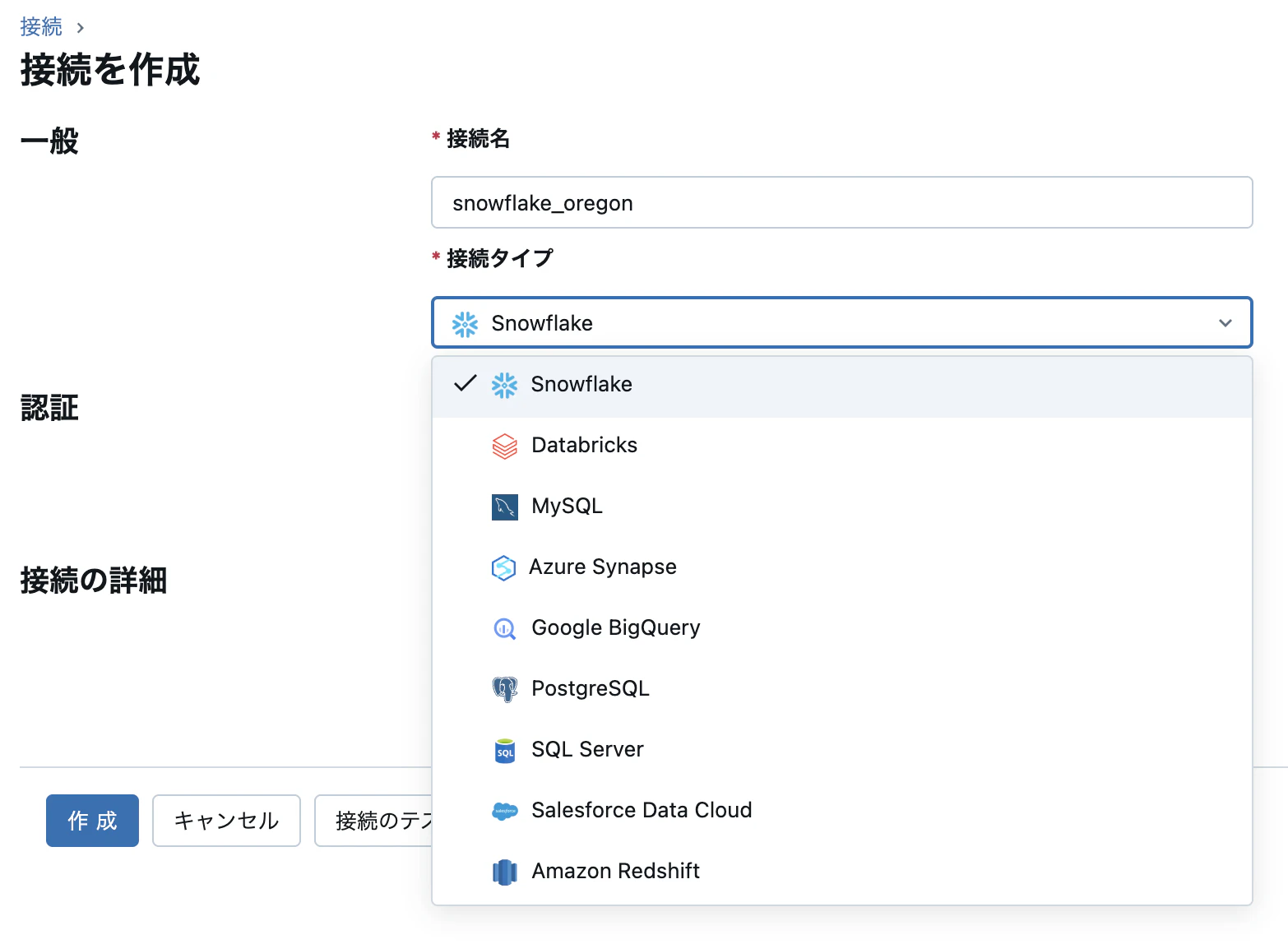
上記のようなデータソースに接続が可能です。こちらのラインナップは続々と増えてます!
直近ですと7月10日に Salesforce Data Cloud が追加されています。
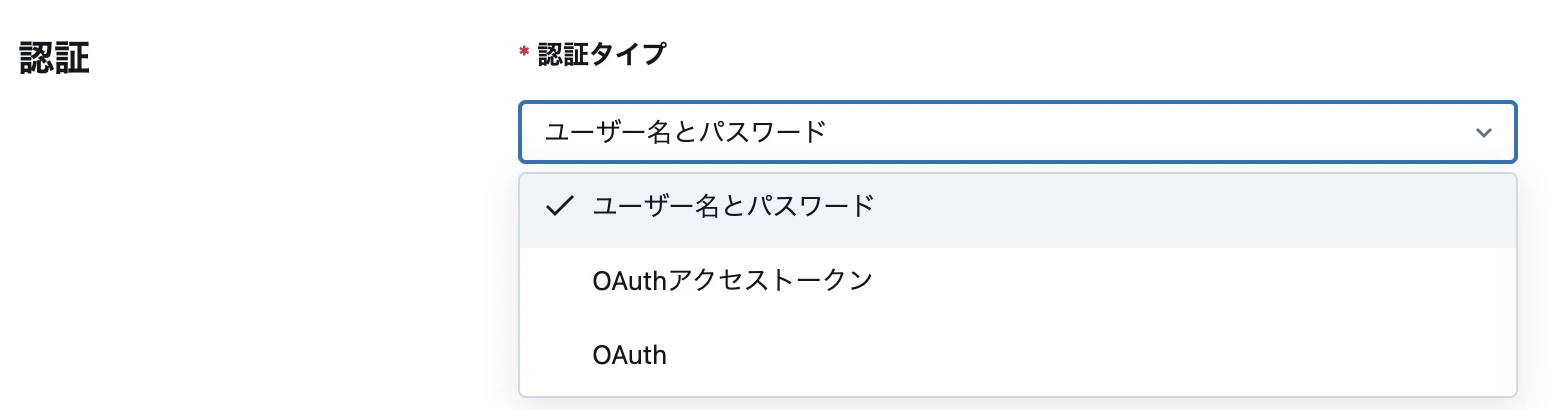
認証タイプ
今回は簡易な検証であるため、ユーザ/パスワードで行います。
ホストとポート
Snowflake のホスト名を調べるには SYSTEM$ALLOWLIST関数を使います。詳細はSnowflake のマニュアルをご覧ください。
SELECT SYSTEM$ALLOWLIST();
でも調べられますが、JSONで結果が返ってくるので次のSQLの方がわかりやすいです。
SELECT t.VALUE:type::VARCHAR as type,
t.VALUE:host::VARCHAR as host,
t.VALUE:port as port
FROM TABLE(FLATTEN(input => PARSE_JSON(SYSTEM$ALLOWLIST()))) AS t;
実行結果のイメージは以下のとおりです。
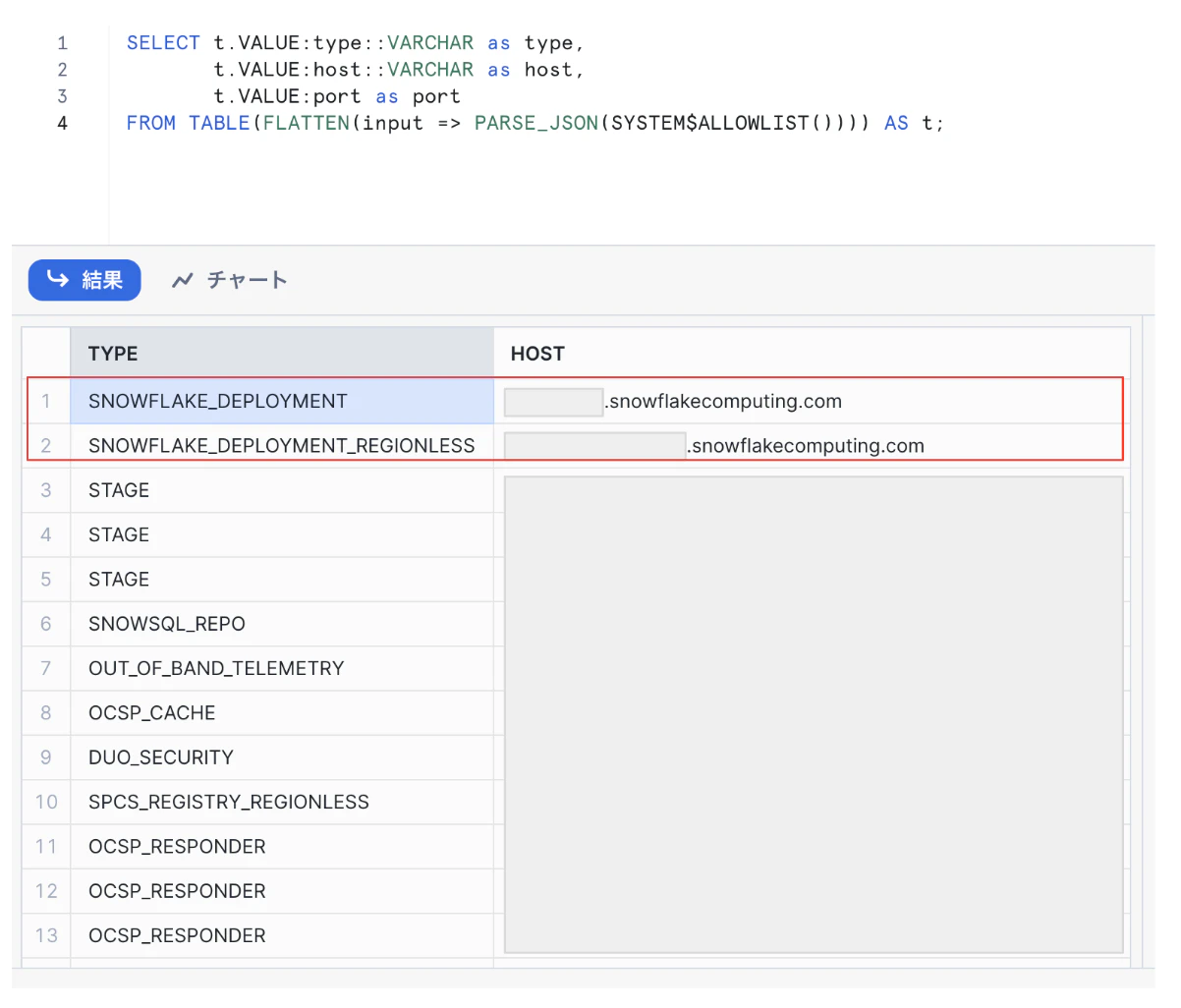
SNOWFLAKE_DEPLOYMENT と SNOWFLAKE_DEPLOYMENT_REGIONLESS の値を控えてください。どちらの値もこの後の設定に使えますので、どちらを使うのかは Snowflake の設計方針に従ってください。
控えたホスト名を Databricks の設定値として入力してください。
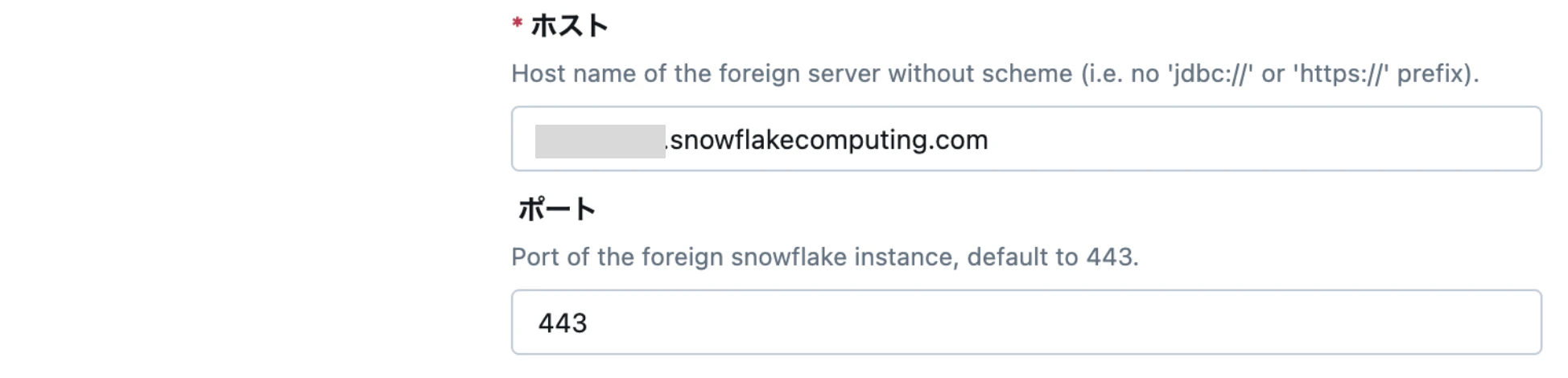
※PrivateLinkの環境では、SYSTEM$ALLOWLIST_PRIVATELINK を使用する必要がありますおでご注意ください。詳細はこちらをご覧ください。
ユーザーとパスワード
Databricks から Snowflake へクエリをする際に使用する Snowflake のユーザを指定します。Snowflake からはこのユーザがクエリを実行しているように見えます。
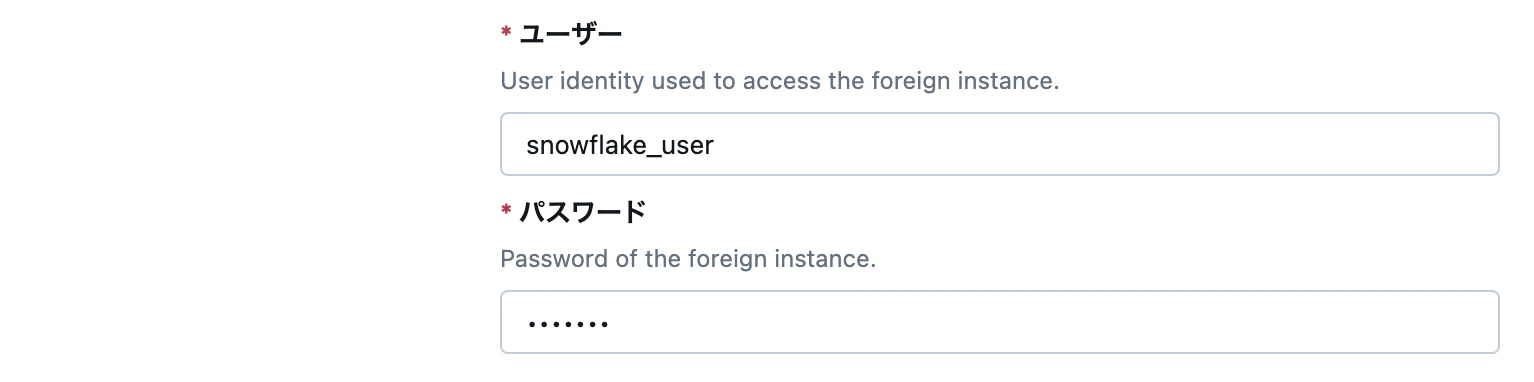
必要以上のデータが Databricks から見えてしまわないように、このユーザに割り当てる権限には気をつけましょう。
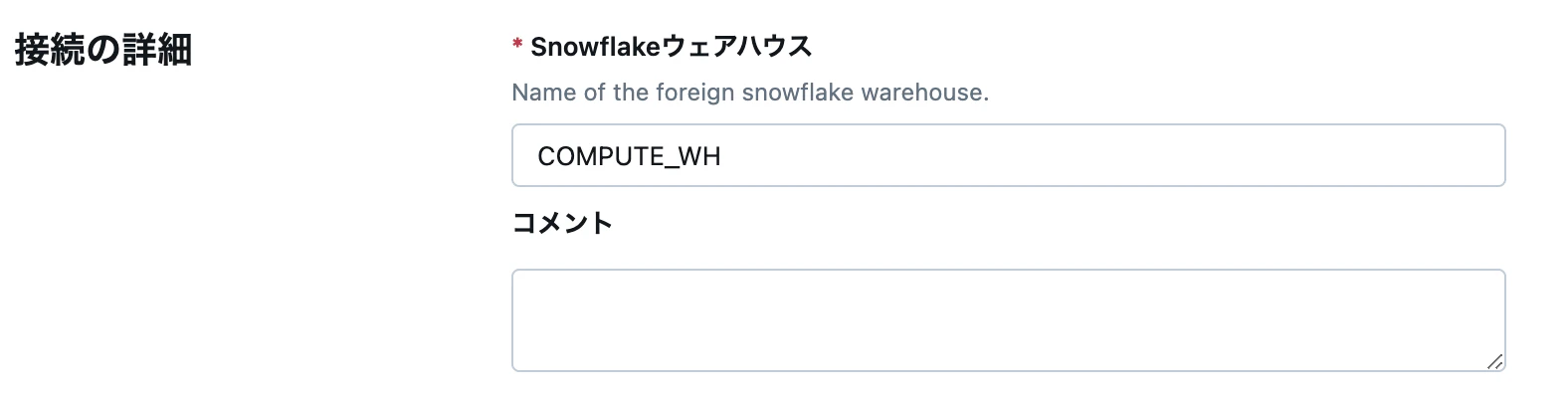
Snowflakeウェアハウスとコメント
Snowflake 側でデータを処理するのに使用するウェアハウス名を指定します。また、任意でコメントの入力も可能です。
設定は以上です。簡単です。
接続のテスト
接続を作成する前にテストをすることができます。設定項目に問題がなければ以下のようなメッセージが表示されます。

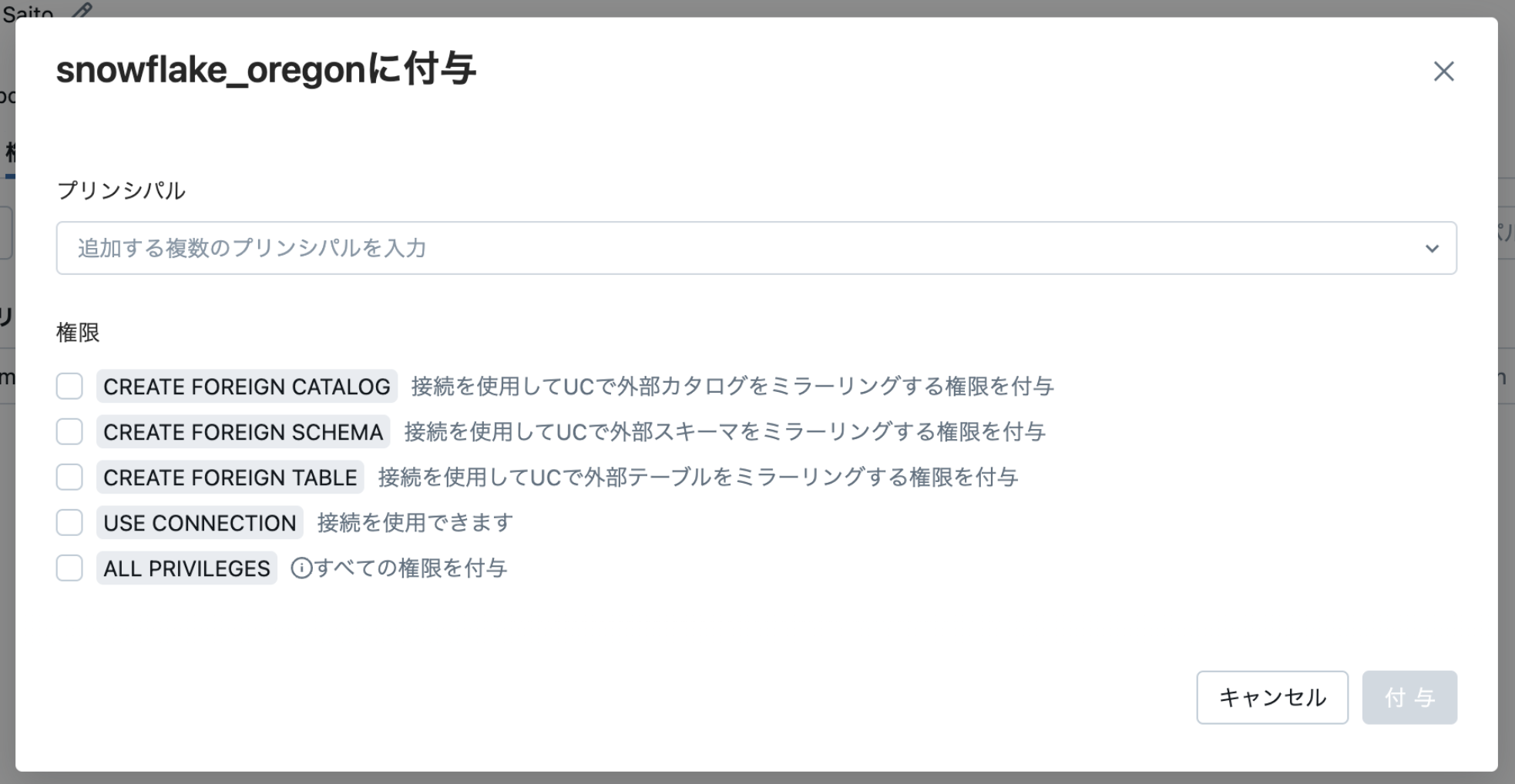
権限付与
接続が作成できたら権限制御が可能となります。後続の外部カタログを作成する人が別の場合は権限付与を忘れないようにしましょう。(システム管理者が接続を作成し、カタログの管理はデータスチュワードが実施するケースも多いと思います。)
外部カタログの作成
作成した接続の右側の「カタログを作成」をクリックします。

以下の権限が必要となりますので、うまくいかない場合はマニュアルを確認してください。
メタストアの CREATE CATALOG 権限、接続の所有権または接続の CREATE FOREIGN CATALOG 権限。
任意のカタログ名を指定し、割り当てるデータベース名を指定します。
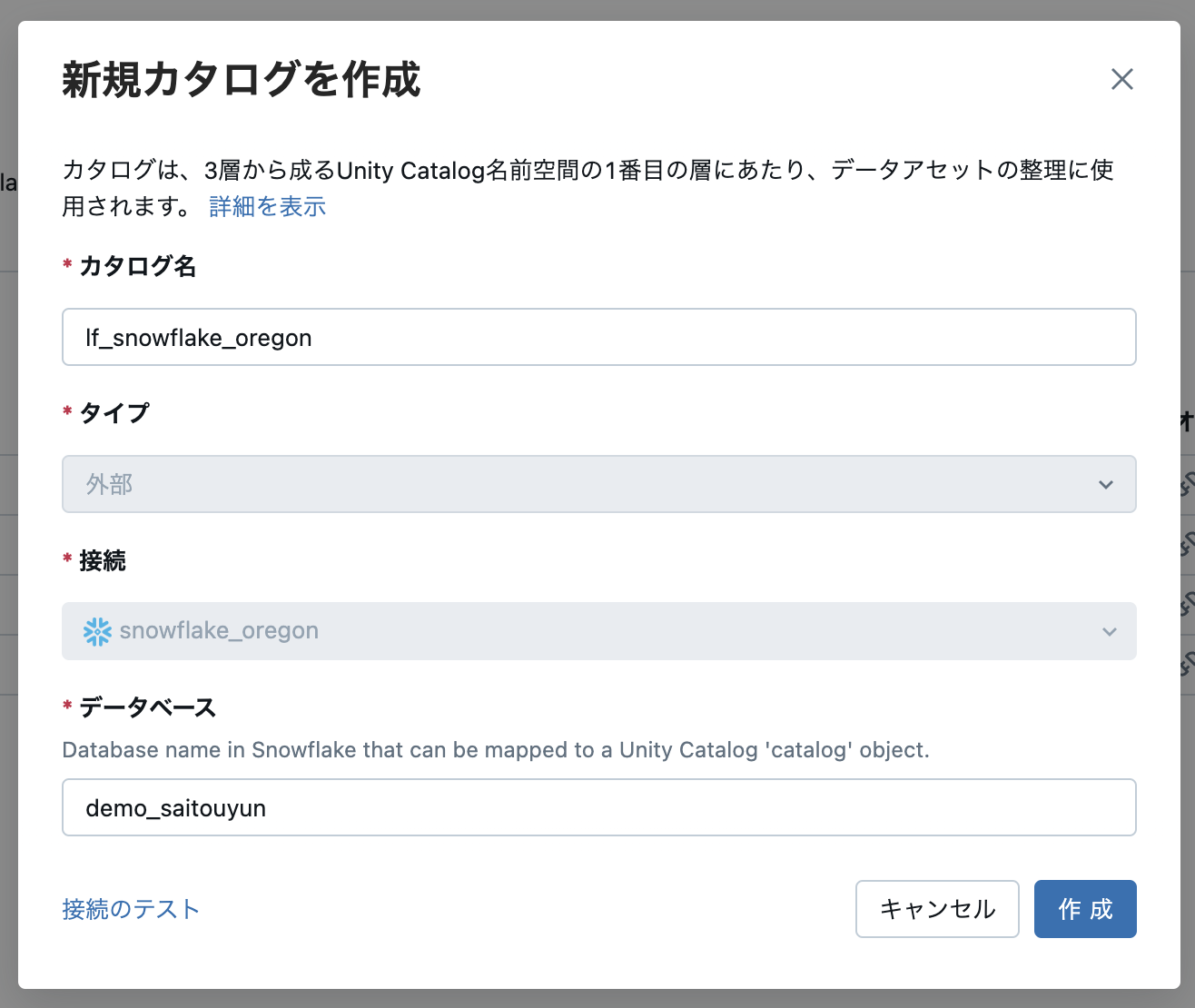
先ほどと同様に接続のテストをすることができます。データベース名が間違っていたり、存在しないとこのタイミングでエラーになります。
※カタログの作成は、カタログエクスプローラーの「+」からも作成することができます。
Databricks から Snowflake を操作する
それでは Databricks から Snowflake を操作してみます。
カタログエクスプローラーでメタデータ管理
カタログエクスプローラーを見るとカタログが作成されています。操作方法は他のカタログと同じです。
Unity Catalog のオブジェクトですので、タグをつけたりなどメタデータ管理をすることができます。
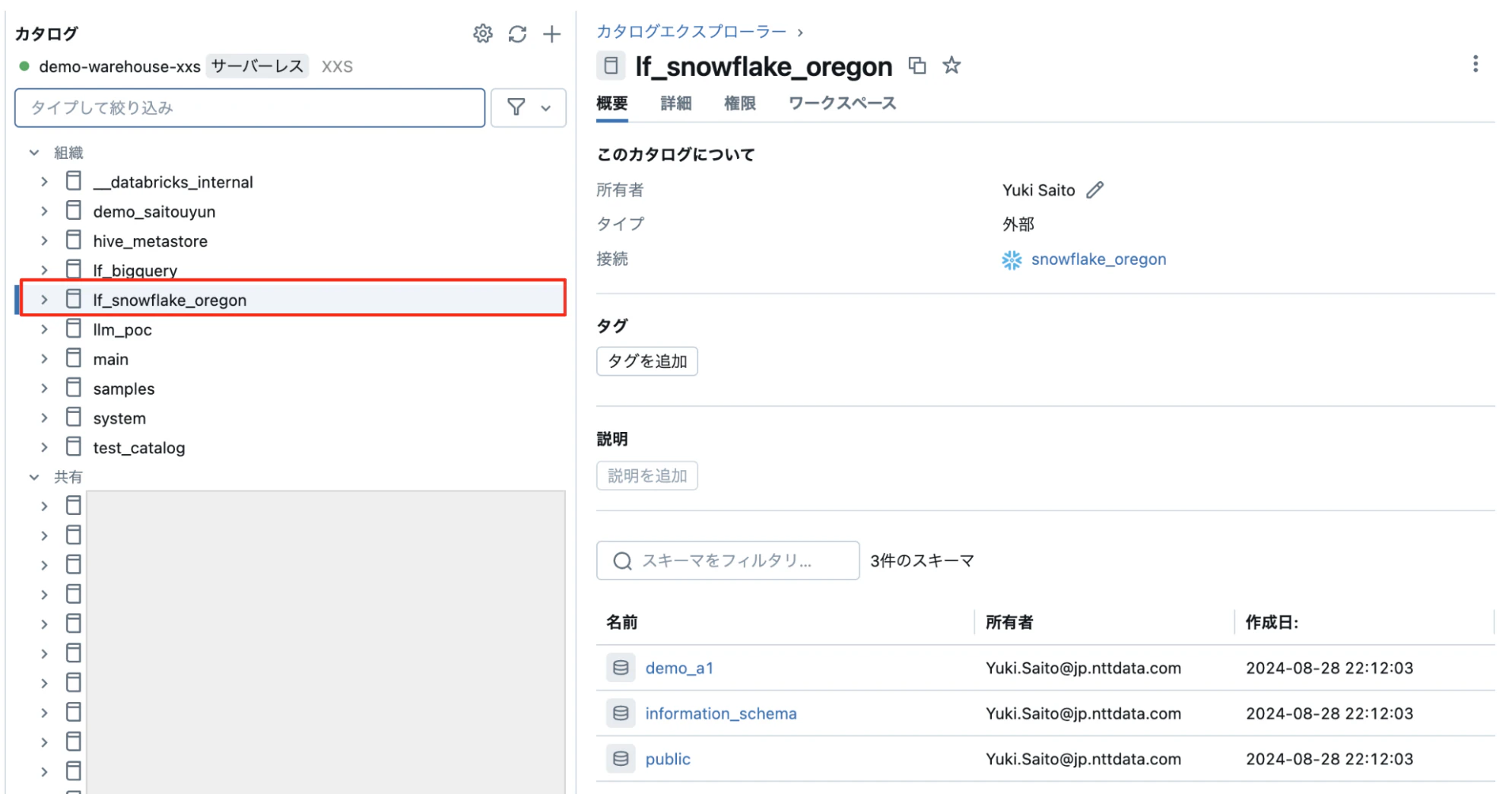
カタログ(Snowflakeのデータベース)を開くと、データベース(Snowflakeのスキーマ)やテーブルを見ることができます。このタイミングで Snowflake へ desc tableなどのクエリが発行されるので Databricks 側のコンピューティングの起動が必要です。
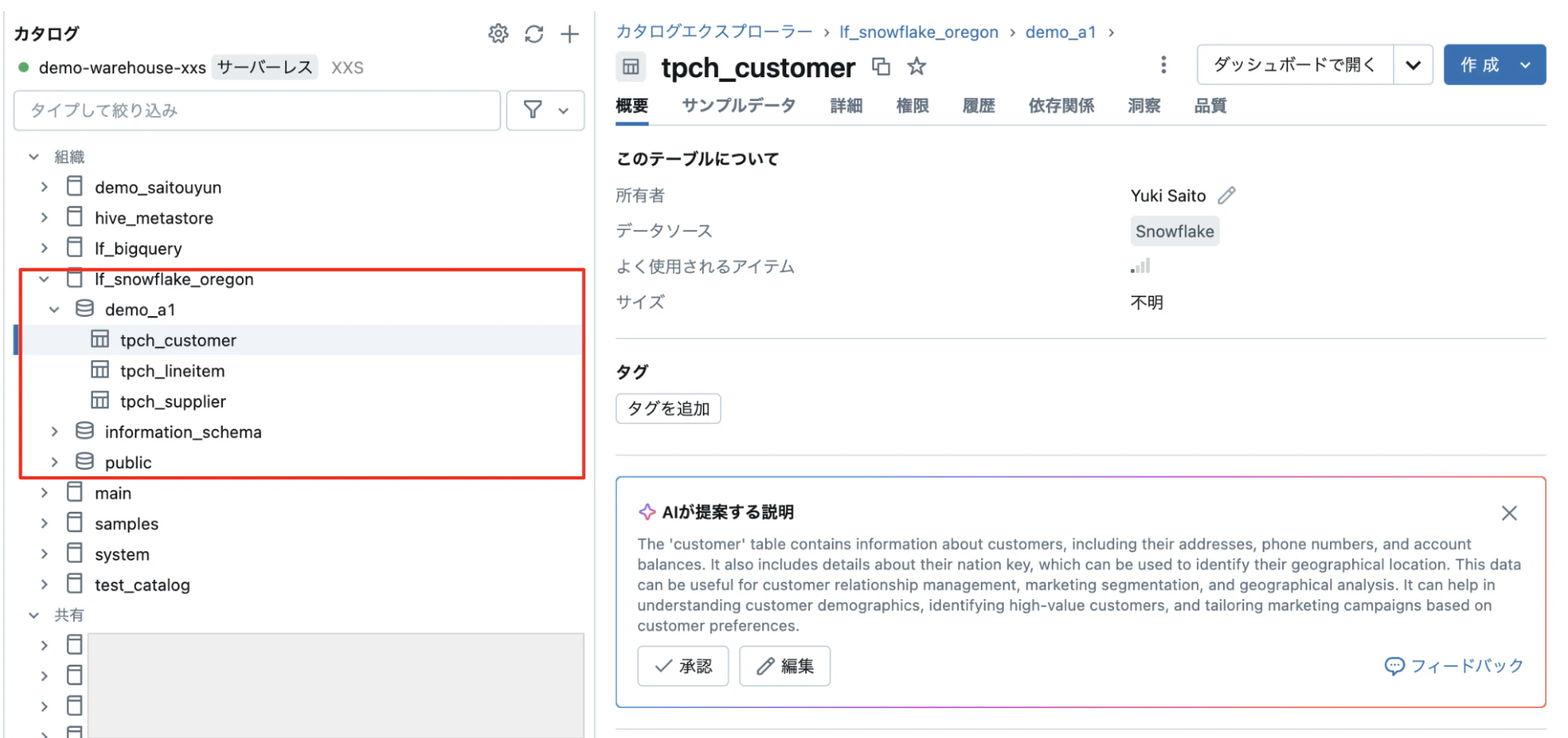
カラムの情報も表示されています。テーブル同様にコメントやタグをつけることができます。
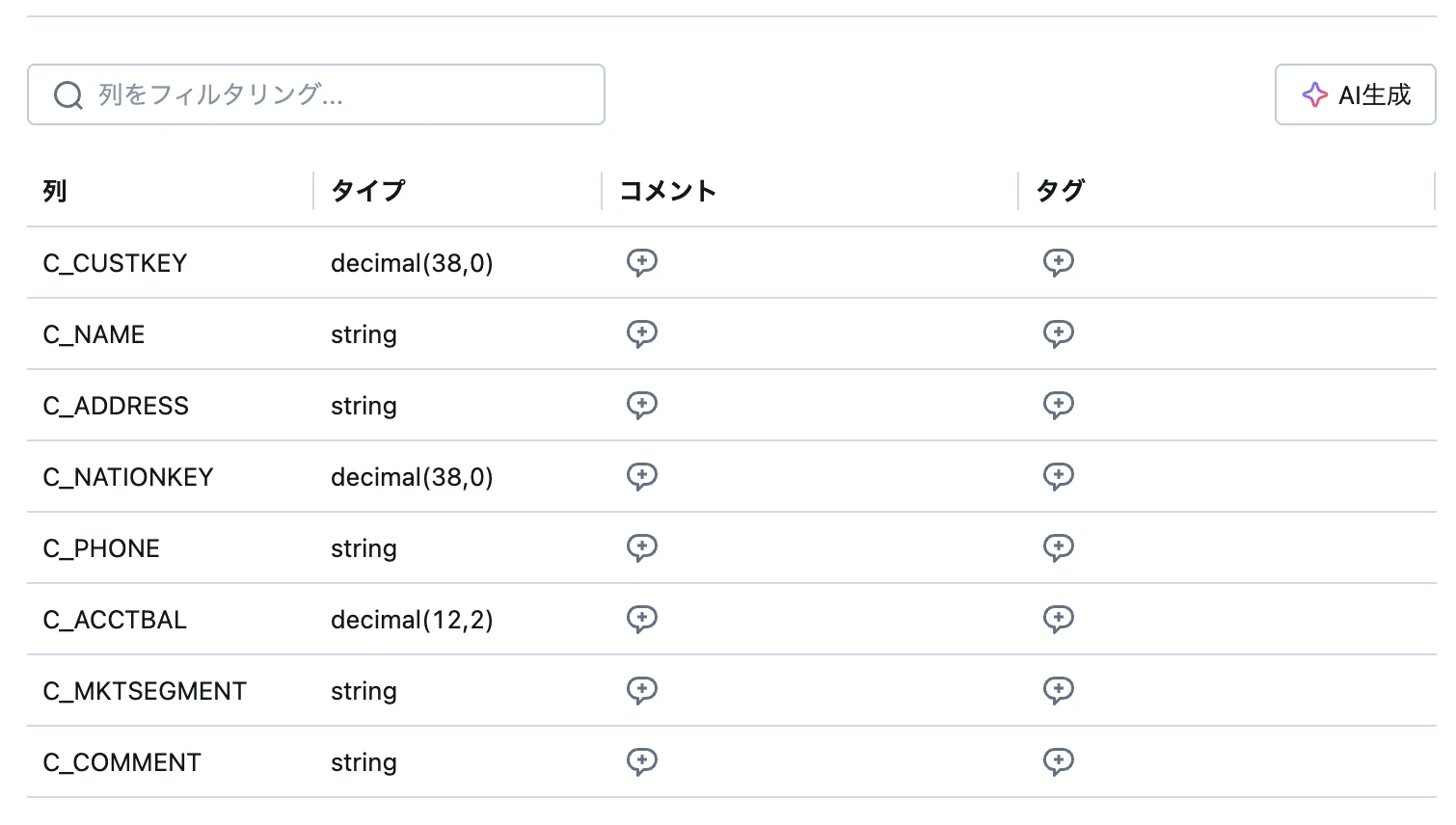
以下は、Snowflake から出力したテーブルの定義です。VARCHAR が STRING になっているなど、型桁は完全に一致はしていないので注意が必要です。データ型の対応関係はマニュアルのこのページに記載されています。
create or replace TABLE DEMO_SAITOUYUN.DEMO_A1.TPCH_CUSTOMER (
C_CUSTKEY NUMBER(38,0),
C_NAME VARCHAR(25),
C_ADDRESS VARCHAR(40),
C_NATIONKEY NUMBER(38,0),
C_PHONE VARCHAR(15),
C_ACCTBAL NUMBER(12,2),
C_MKTSEGMENT VARCHAR(10),
C_COMMENT VARCHAR(117)
);
必要に応じて桁の方法はメタデータとして保存しておくと分かりやすいのではないでしょうか。
Databricks、Snowflake などの様々なデータソースのメタデータを一元管理することができ、横断的にデータを見つけることができるようになりました!
データプレビュー
「サンプルデータ」タブからデータのプレビューも実施できます。
こちらはデータ処理(SELECT)になるので、Snowflake 側のコンピュートも稼働します。
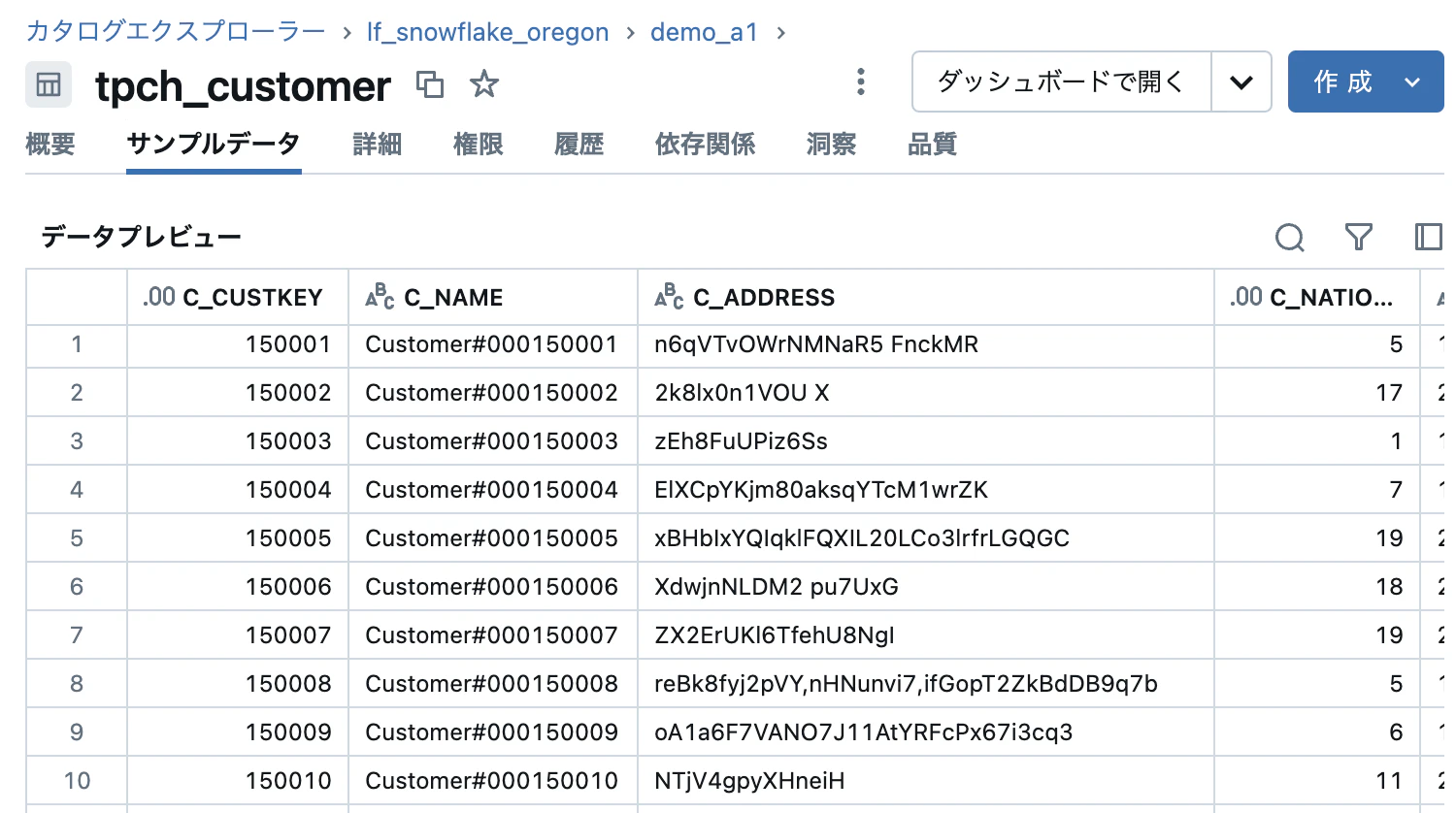
いちいち、データソースごとに複数のUIを開いてデータを確認する必要もなくなりますね。
権限管理
「権限」タブから Snowflake 上のテーブルを Unity Catalog で権限管理を一元化できます。
データソースごとに、同じような権限を設計し、同じようなユーザ・グループを作成し、権限を割り当て、利用部門に払い出し、・・・のような煩雑な管理から解放されます。
データリネージュ
「依存関係」タブからは外部カタログのテーブルを参照するノートブックやジョブなどの依存関係を見ることができます。外部カタログ上のデータを使ってデータパイプラインを作成した場合は以下のようなリネージュも表示することができます。
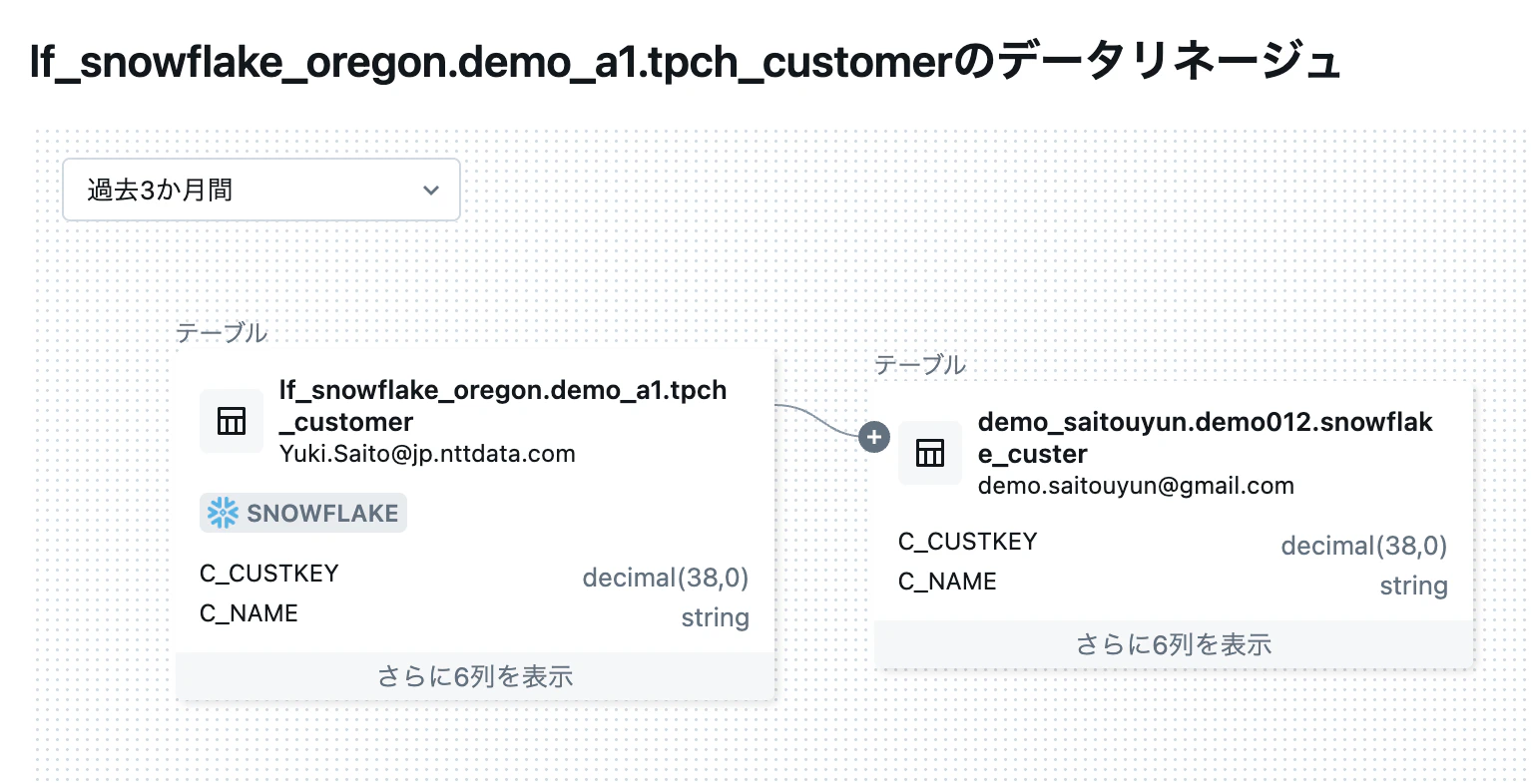
複数データソースをまたがったデータパイプラインのエラーの原因や修正時の影響範囲を迅速に特定することができます。
テーブルの利用状況
「洞察」タブから Databricks を通じたテーブルの利用状況を確認することができます。
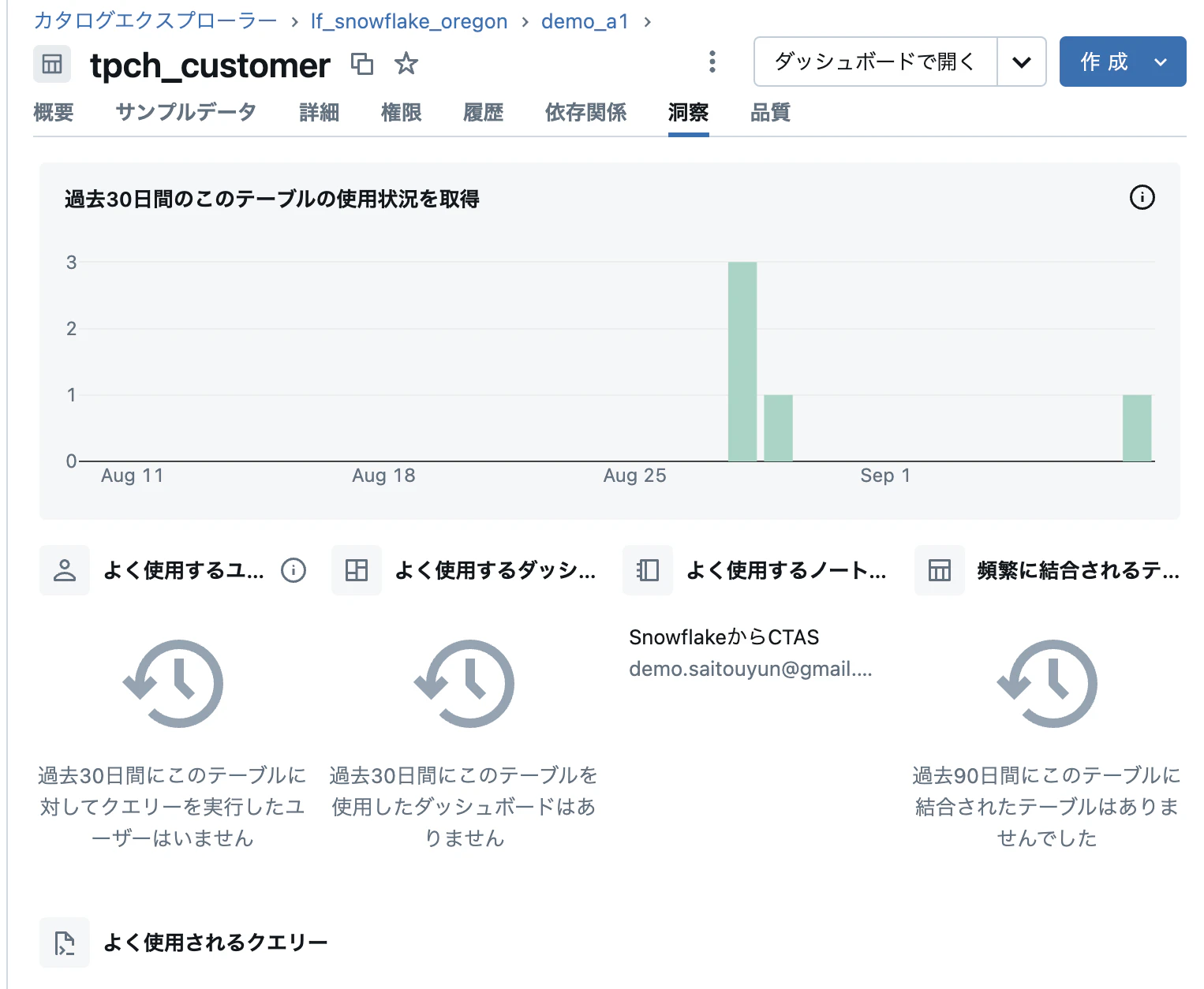
Lakehouse Federation は複数データソースにまたがるデータを管理しやすくする機能で、コストや性能についてはトレードオフになるケースがあります。 このダッシュボードにより、頻度高くクエリされるテーブルをデータパイプラインを作成して、 Databricks 上に配置することでコストを削減したり、性能を向上させたりするための判断材料にすることができます。
ノートブックから Snowflake のテーブルを操作する
あえて書く必要もないかもしれませんが、Snowflake であることは特に意識せず他のテーブルと同様に処理を記述することができます。
おわりに
Snowflake、Databricks ともに人気のあるデータプラットフォームです。
両プラットフォームを使うケースも少なくはないと思います。
本書が Lakehouse Federation によって2つのプラットフォームを効果的に活用するヒントになれば幸いです。
他にも Databricks の記事を書いていますので、ぜひご覧ください!!
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。