はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 の nttd-saitouyun です。
先日、以下の記事を書きました。今回はこの単価表を作るために作成したデータパイプラインについてご紹介します。
- Databricks on AWS クラスター利用料金単価の早見表(Enterpriseプラン・2024年7月)
- Databricks on AWS クラスター利用料金単価の早見表(Premiumプラン・2024年7月)
- Databricks on AWS クラスター利用料金単価の早見表(Standardプラン・2024年7月)
データパイプラインの全体像
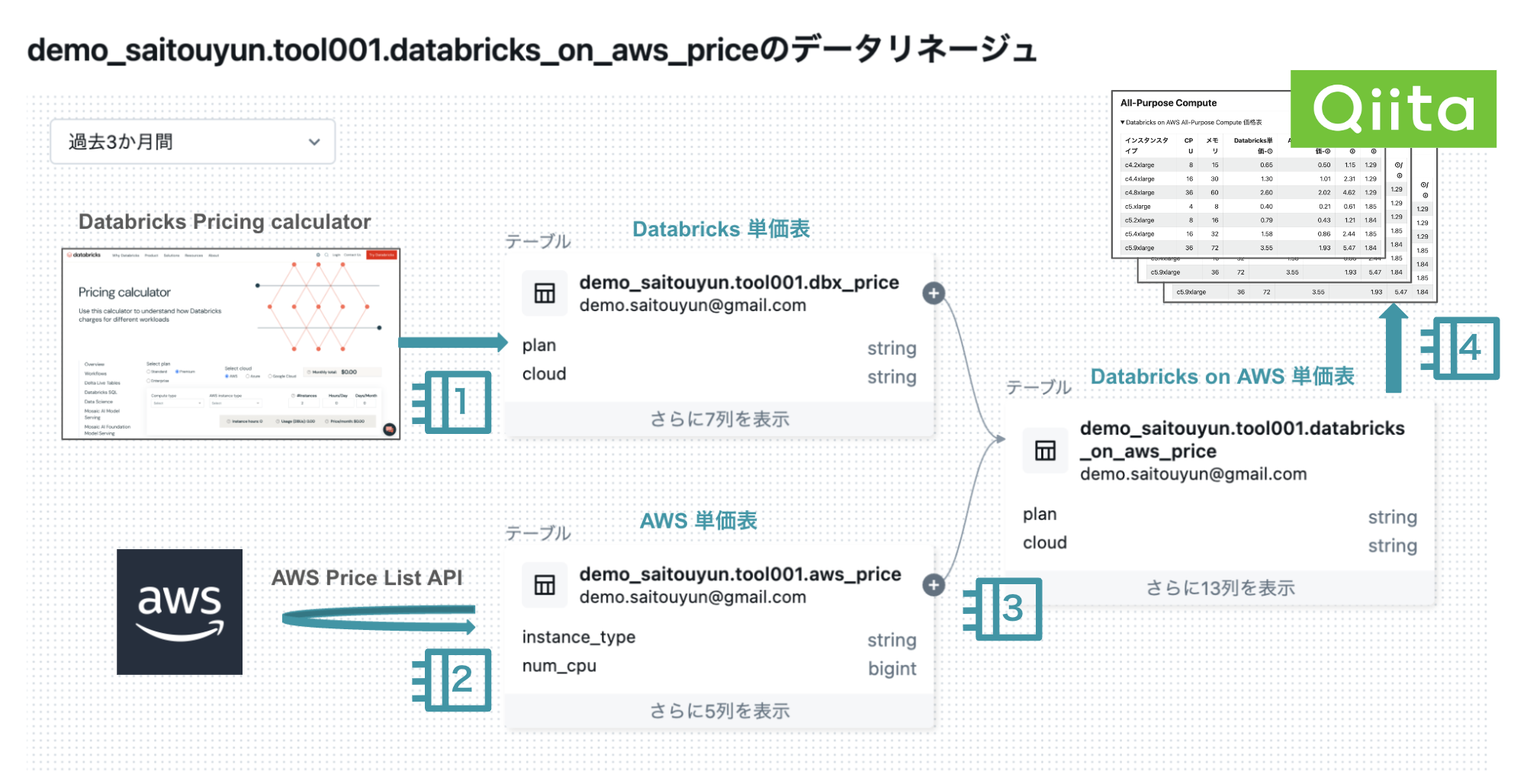
データパイプラインの全体像は上の図のようになります。4つのノートブックで構成されています。
1. Databricks 単価表の作成
Databricks Pricing calculator の情報をまとめ、以下のような表を作成します。
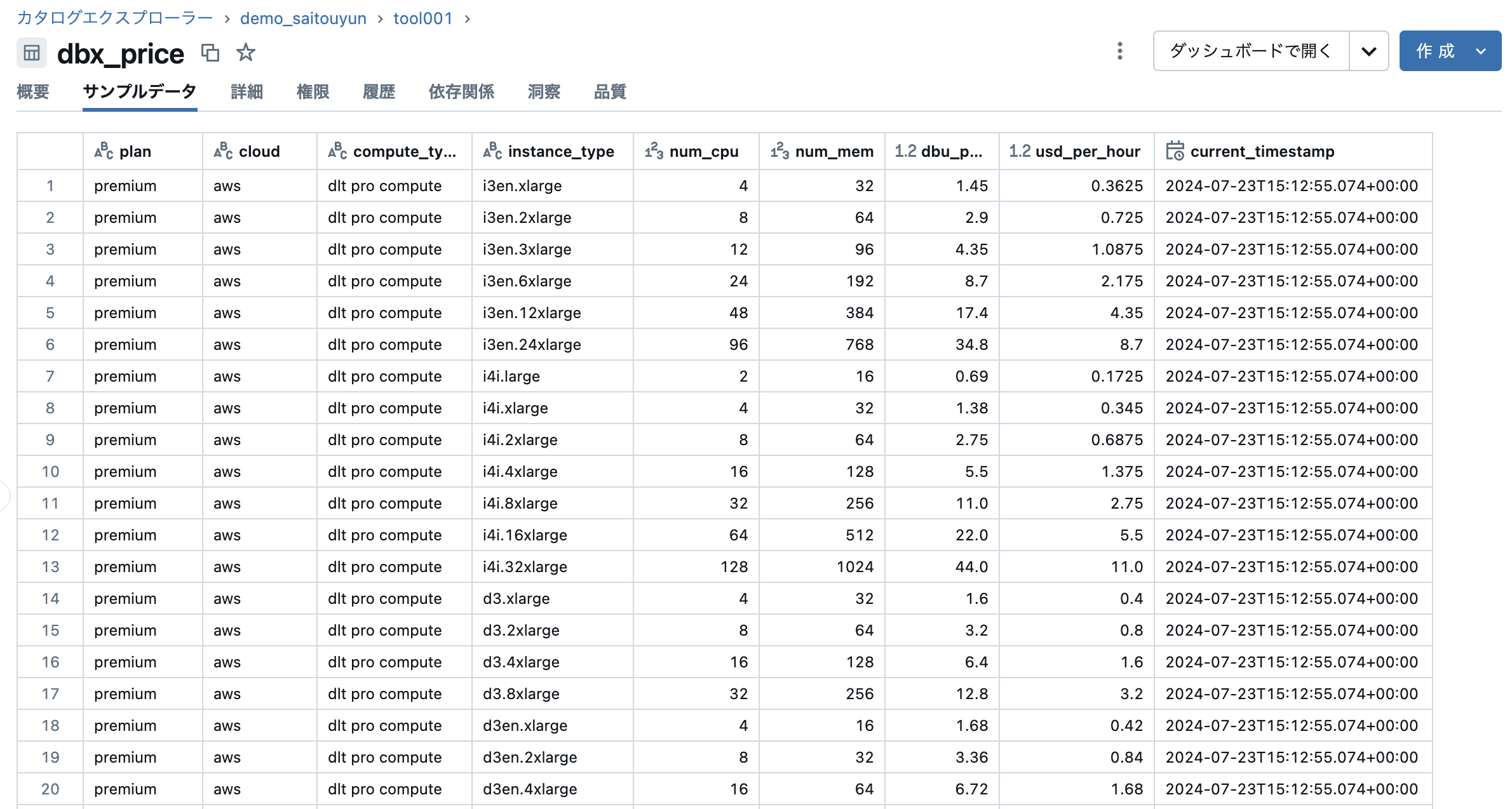
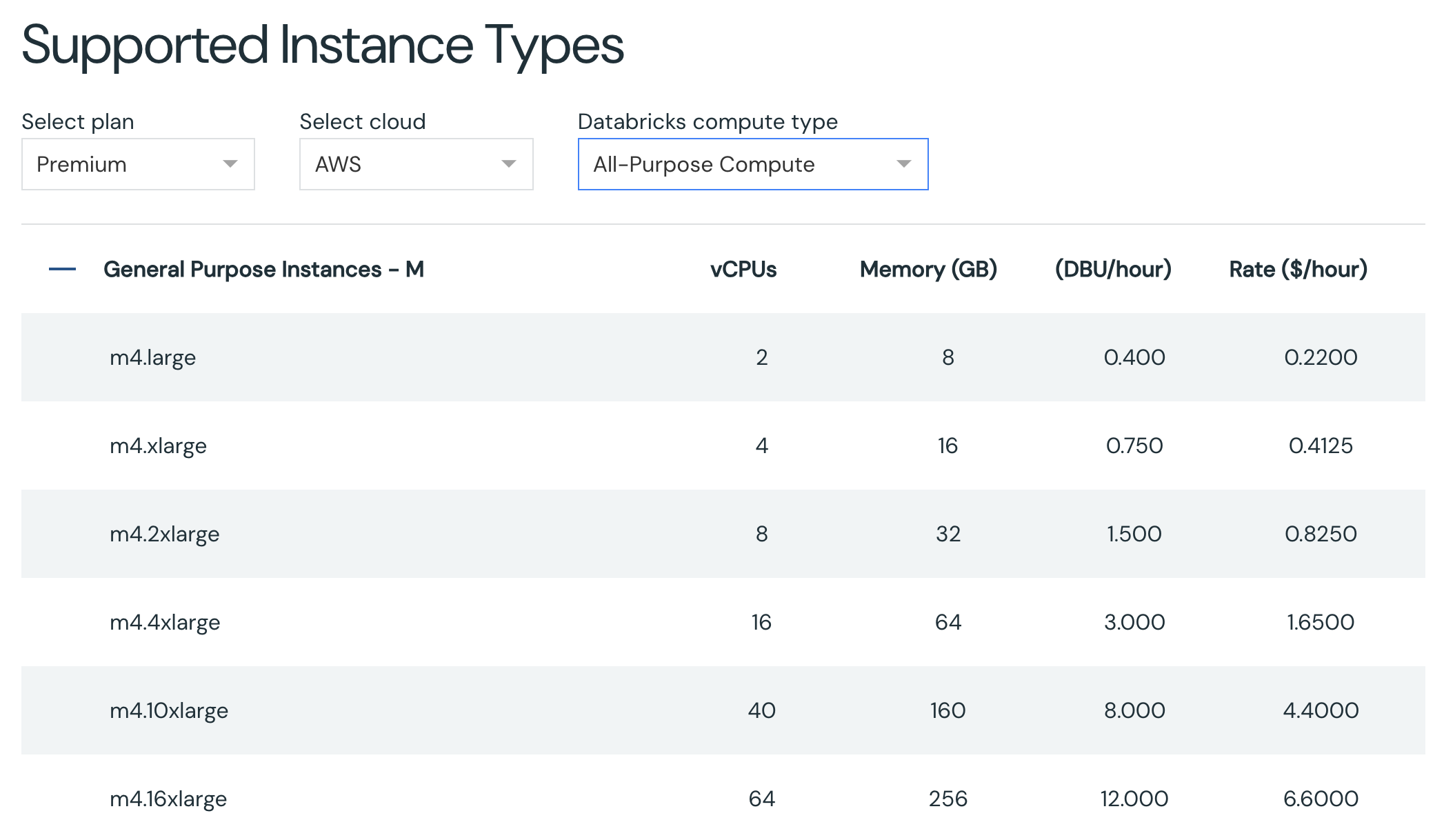
Databricks Pricing calculator のWebページにはインスタンスタイプ、vCPU数、メモリ、1時間あたりのDBU消費量、1時間あたりの価格が表示されています。
この表をプランとコンピュートタイプを変えながら(クラウドはAWSで固定)読み取りデータフレーム化し、テーブルへ書き出します。テーブルのスキーマは以下の通りとなります。レコード数は669です。
※Databricksにはシステムテーブルで、system.billing.list_prices という価格情報を保持するテーブルがあります。このテーブルの利用も考えましたが、コンピュートタイプごとの「$/DBU」の情報は載っているものの、インスタンスタイプごとにどのように価格が決まっているかは不明であったため、Webサイトから情報を取得する方式としました。
2. AWS 単価表の作成
AWS Pricing List API を活用して、東京リージョンのEC2のオンデマンド料金を取得し、テーブル化します。Amazon EC2 オンデマンド料金のWebページの内容と同様の値を取得することを目的とします。
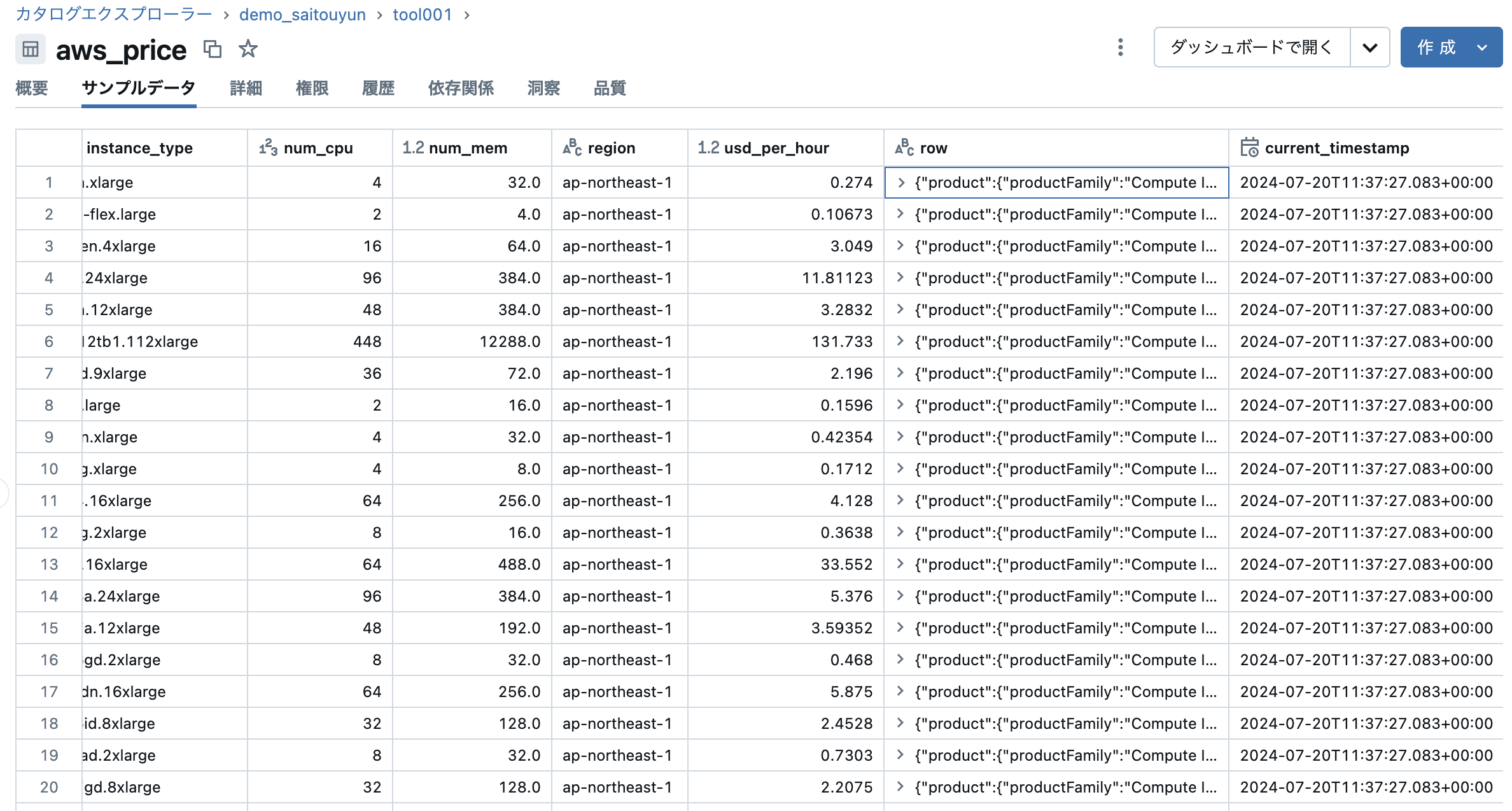
Databricks のクラスタには boto3 がデフォルトで入っています。 boto3 client を使って Pricing List API をコールします。
client = boto3.client('pricing',
# price data is only available in us-east-1 and ap-south-1
region_name='us-east-1',
)
ここで早速ですが、一つ罠がありました。Pricing List API は「us-east-1」リージョンと「ap-south-1」リージョンでしか使えないため、リージョンに注意してください。「ap-northeast-1」を指定するとAPIを実行したタイミングで「エンドポイントが見つからない」といった旨のエラーが出ます。
次に、API をコールします。APIの仕様はこちらです。
response = client.get_products(**request_parameters)
ただ、ここからキツいです。レスポンスとして返ってくるJSONは以下のように複雑なものでした・・・

このJSONの構造をじっくりじっくり理解していくと、EC2にはテナンシーやOSの種類などによって細かく価格が変わってきます。事前に条件をつけてAPIをコールしないと関係ない情報が含まれて後続の処理が難しいことがわかりました。
そこで、以下のようなフィルターをかけることで、オンデマンドの利用料金のWebページと同じ値が取得できることが、試行錯誤を通して見えてきました。(正直ここが一番しんどかった・・・)
request_parameters = {
'ServiceCode': 'AmazonEC2',
'Filters': [
{'Type': 'TERM_MATCH', 'Field': 'regionCode', 'Value': 'ap-northeast-1'},
{'Type': 'TERM_MATCH', 'Field': 'productFamily', 'Value': 'Compute Instance'},
{'Type': 'TERM_MATCH', 'Field': 'operatingSystem', 'Value': 'Linux'},
{'Type': 'TERM_MATCH', 'Field': 'operation', 'Value': 'RunInstances'},
{'Type': 'TERM_MATCH', 'Field': 'tenancy', 'Value': 'Shared'},
{'Type': 'TERM_MATCH', 'Field': 'OfferingClass', 'Value': 'standard'},
],
'FormatVersion': 'aws_v1',
'MaxResults': 100
}
あとは、JSONから必要な情報を抜き出してデータフレームとし、テーブルとして保存します。
price_per_unit はJSONのかなり深い階層にあって取得の仕方がかなり複雑でしたが、Databricks Assistant(LLMによるコード生成機能)に助けてもらい実装できました。JSONのサンプルをいくつか提示し、取得したい値を指定したら一発で意図したコードが出ました。すごい!
for price_str in response['PriceList']:
price = json.loads(price_str)
num_vcpu = int(price["product"]["attributes"]["vcpu"])
num_mem = price["product"]["attributes"]["memory"]
num_mem = num_mem.replace("GiB", "")
num_mem = float(num_mem)
region = price["product"]["attributes"]["regionCode"]
instance_type = price["product"]["attributes"]["instanceType"]
dict = price["terms"]["OnDemand"]
price_per_unit = next(iter(dict.values()))['priceDimensions'].popitem()[1]['pricePerUnit']['USD']
price_per_unit = float(price_per_unit)
余談ですが、テーブルを作ってデータを見てみると、u-12tb1.112xlarge(vCPU数448、メモリ12288GiB)などのとんでもなくハイスペックなインスタンスなど、あまり目にしないインスタンスタイプを見つけ、あらためてAWSのコンピューティングリソースの種類の多さに驚きました。
たくさんフィルタをかけたつもりですが、レコード数は4384にもなりました。
3. Databricks on AWS 単価表の作成
ここまでに作ってきた2つのテーブルを結合し、合計単価などの計算を行います。
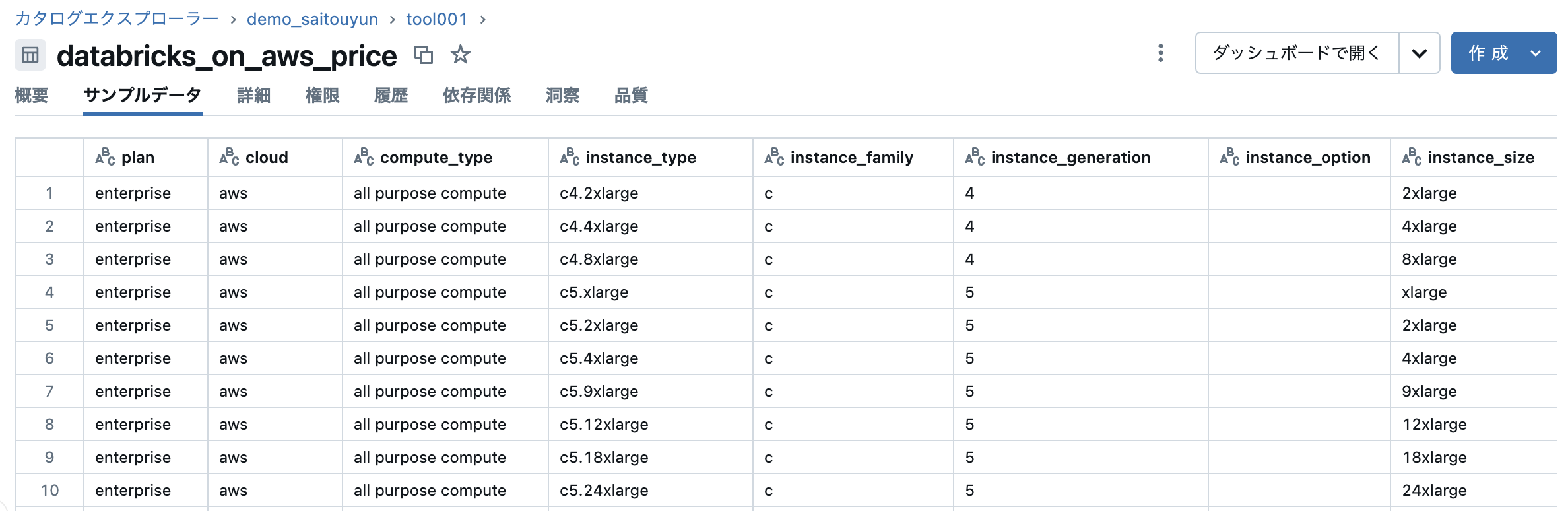
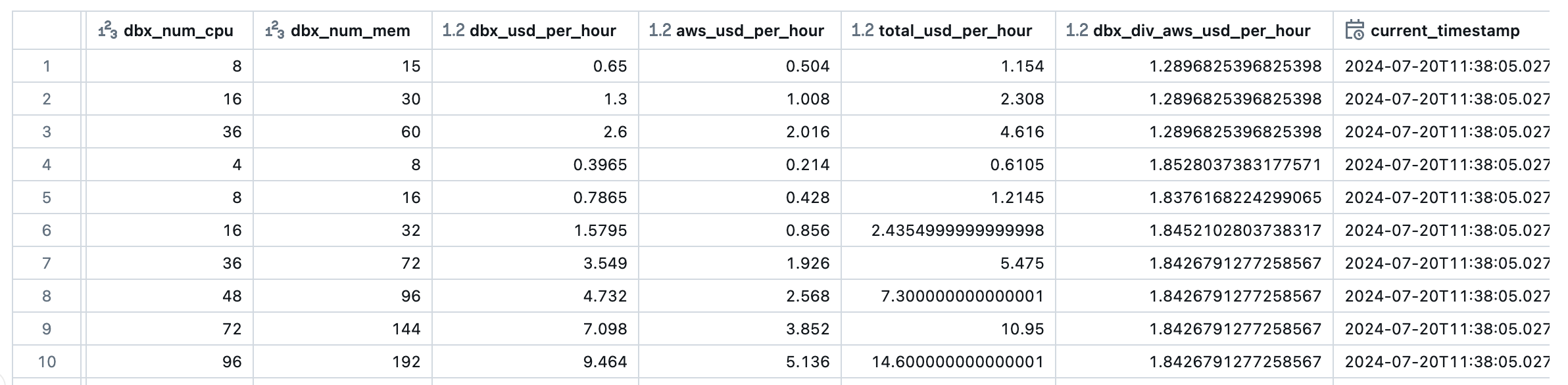
結合処理
Databricks 単価表と AWS 単価表 を インスタンスタイプをキーに結合します。Databricksの単価表にはすでに価格情報を取得できない古いAWSインスタンスが含まれていることに注意が必要でした。
joined_df = dbx_price_df.join(aws_price_df, "instance_type", "inner")
ソート
後にマークダウンの表にするため、以下のようにわかりやすく並べ替えておきます。
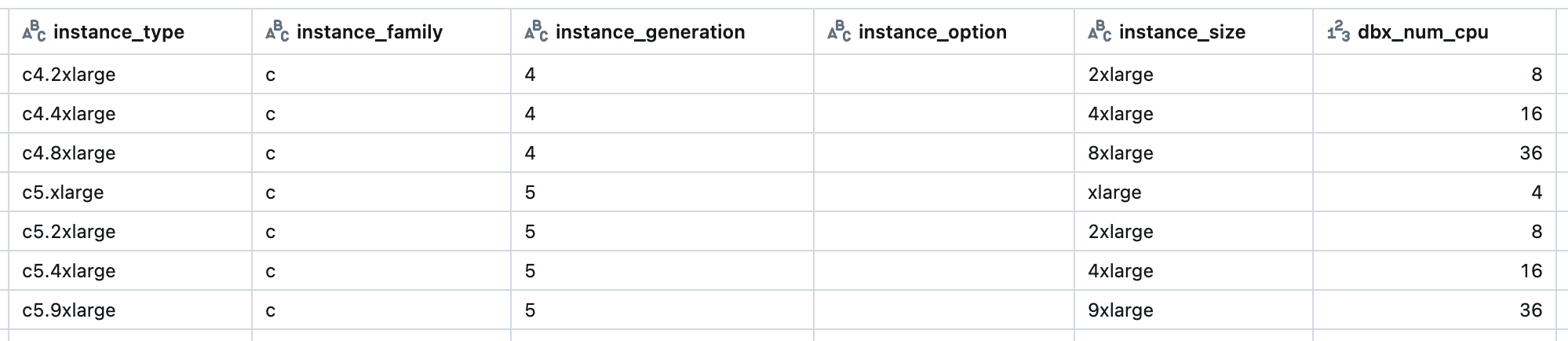
インスタンスタイプを分解し、それぞれをカラム定義ソートキーに使います。
例:c5a.xlarge → 「c」「5」「a」「xlarge」
一見すると難しい処理に見えますが、こちらも Databricks Assistant のおかげでサクッと実装できました。
from pyspark.sql.functions import col, substring, expr
silver_df = joined_df.select(
"plan",
"cloud",
"compute_type",
"instance_type",
(substring("instance_type", 1, 1)).alias("instance_family"),
(substring("instance_type", 2, 1)).alias("instance_generation"),
(expr("substring(instance_type, 3, instr(instance_type, '.') - 3)")).alias("instance_option"),
(expr("substring(instance_type, instr(instance_type, '.') + 1, length(instance_type))")).alias("instance_size"),
"dbx_num_cpu",
"dbx_num_mem",
"dbx_usd_per_hour",
"aws_usd_per_hour",
(col("dbx_usd_per_hour") + col("aws_usd_per_hour")).alias("total_usd_per_hour"),
(col("dbx_usd_per_hour") / col("aws_usd_per_hour")).alias("dbx_div_aws_usd_per_hour",)
).orderBy("plan", "compute_type", "instance_family", "instance_generation", "instance_option", "dbx_num_cpu")
あとはテーブルとして保存するだけです。
4. マークダウンの作成
Spark データフレームを Pandas データフレームに変換し、Pandas データフレームの to_markdown() でマークダウンに変換します。
to_markdown() を使うために tabulate をインストールします。
!pip install tabulate
dbutils.library.restartPython()
必要なカラムを抽出し、カラム名を日本語に変更します。
formatted_price_df = price_df.select(
"plan",
"compute_type",
"instance_type",
"dbx_num_cpu",
"dbx_num_mem",
"dbx_usd_per_hour",
"aws_usd_per_hour",
"total_usd_per_hour",
"dbx_div_aws_usd_per_hour"
)
formatted_price_df = formatted_price_df \
.withColumnRenamed("instance_type", "インスタンスタイプ") \
.withColumnRenamed("dbx_num_cpu", "CPU") \
.withColumnRenamed("dbx_num_mem", "メモリ") \
.withColumnRenamed("dbx_usd_per_hour", "Databricks単価-①") \
.withColumnRenamed("aws_usd_per_hour", "AmazonEC2単価-②") \
.withColumnRenamed("total_usd_per_hour", "①+②") \
.withColumnRenamed("dbx_div_aws_usd_per_hour", "①/②")
データフレームからマークダウンを生成するメソッドを作成します。
to_markdown では数値の表示桁数の指定もしています。
import os
def create_markdown_text(・・・):
・・・・
pandas_df = df.toPandas()
markdown_table = pandas_df.to_markdown(index=False, floatfmt='.2f')
markdown = f"## {compute_type_str}" + os.linesep *2
markdown += f"<details><summary>Databricks on AWS {compute_type_str} 価格表</summary>" + os.linesep *2
markdown += f"{markdown_table}" + os.linesep *2
markdown += f"</details>" + os.linesep *2
return markdown
上記で作成したメソッドをマークダウンの表ごとに呼び出して全体的なマークダウンを作成します。
def create_markdown(plan, cloud, price_df):
markdwon = ""
# normarl cluster
markdwon += create_markdown_text(formatted_price_df, plan, "all purpose compute", "All-Purpose Compute")
markdwon += os.linesep *2
・・・・
・・・・
# photon cluster
markdwon += create_markdown_text(formatted_price_df, plan, "all purpose compute photon", "All-Purpose Compute Photon")
markdwon += os.linesep *2
markdwon += create_markdown_text(formatted_price_df, plan, "jobs compute photon", "Jobs Compute Photon")
markdwon += os.linesep *2
・・・・
・・・・
write_markdown_file(plan, cloud, markdwon)
ワークスペースのフォルダに書き出されたファイルを確認します。
Databricks には、マークダウンテキストのプレビュー機能があります。(知らなかった・・・)
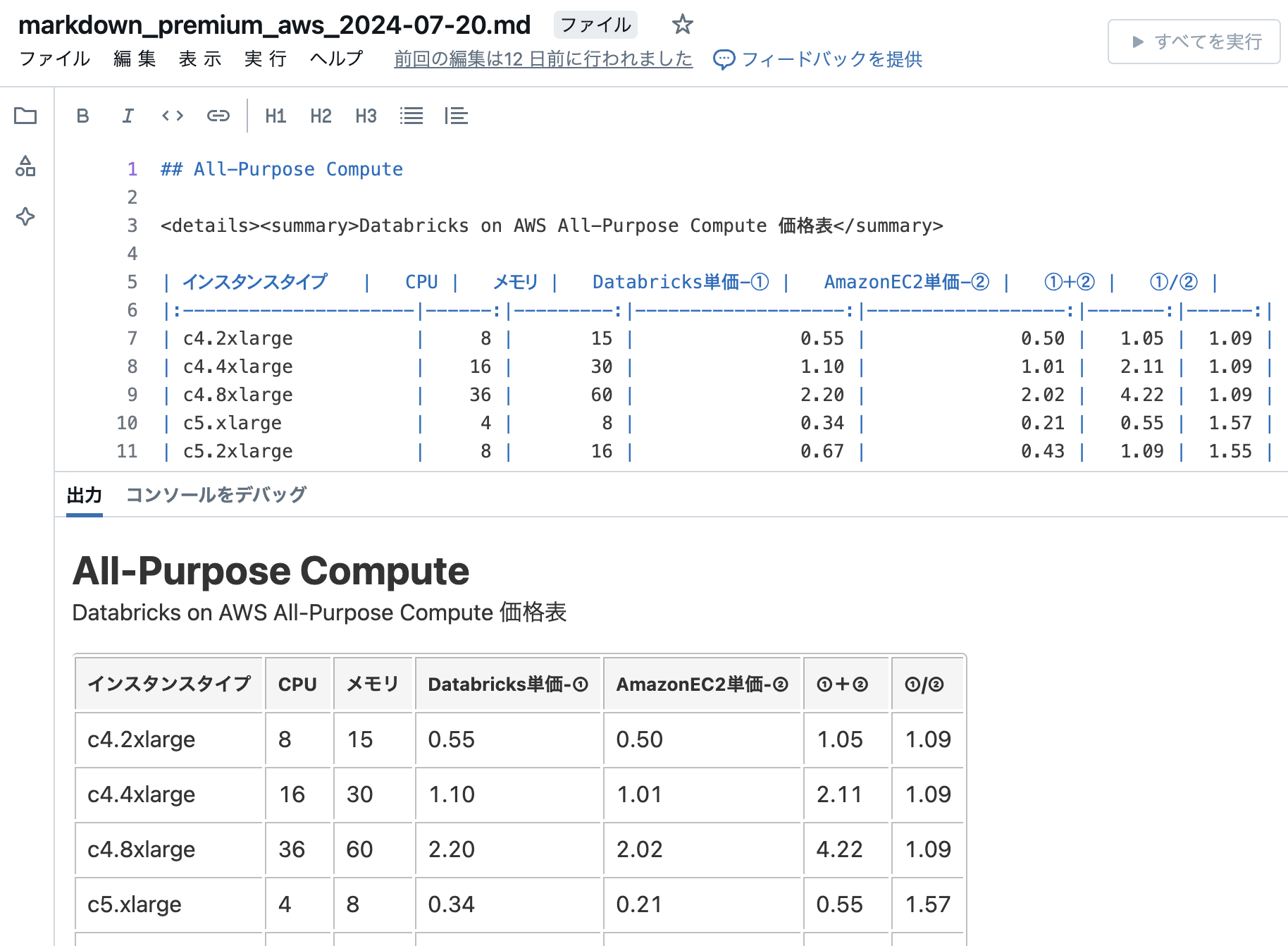
あとは、このテキストを Qiita の記事に貼り付けるだけです!
おわりに
本書では以下のデータパイプラインの作り方についてご紹介しました。
テーブル/ファイルのベーシックなデータパイプラインではありませんでしたが、APIコールした内容を取り込んだり、マークダウンで加工したデータを出力したりなど、データ処理の幅の広さを感じていただければ幸いです。
また、複雑なJSON処理や文字列の加工も、Databricks Assistant(生成AI)の力を借りることで簡単に実装できることもポイントでした。(このような加工はやればできるとは思いますが、地味に時間が取られてしまうのでとても助かりました。)
(一番苦労した、AWS Pricing List API の使用上の注意点などもご参考にいただければと思います。)
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。