はじめに
今回は機械学習プラットフォーム「DataRobot」の機能紹介記事として、「高度なオプション」のうちの一つであるパーティション機能を紹介したいと思います。
DataRobotについて
DataRobot社は、人工知能(AI)に対するユニークなコラボレーション型のアプローチであるバリュー・ドリブン AIのリーダーです。
DataRobot社の製品であるDataRobotは、自動機械学習(AutoML)プラットフォームであり、機械学習モデルの構築、トレーニング、評価、デプロイメントを自動化することができます。複雑なデータ分析を迅速かつ簡単に実行し、優れた予測モデルの作成をサポートすることが可能です。
本記事の主な想定読者
- 機械学習を学び始めの方
- DataRobotを導入していて、パーティション機能の使い方を知りたい方
- DataRobotを導入していないが、データ分割に関連するDataRobotの機能を手軽に知りたい方
「パーティション」機能の理解のための前段知識
この記事を読む方の多くは既にご存じかもしれないですが、機械学習では、持っているデータ全てを使ってモデルを学習するのではなく、データをモデルの学習用と精度検証用に分割することが一般的です。このとき、どのように分割するかを適切に設定できていないと、モデルの性能を見誤る等の問題が発生する場合があります。
DataRobotのパーティション機能を使えば、簡単な画面操作で適切なデータ分割を行うよう設定することができますが、ここではまずその前段として知っておく必要があることについて説明します。
前段知識① 「教師-検定-ホールドアウト」と「交差検定」
データを分割する上ではまず「どのように精度検証をするか」を決める必要があります。「教師-検定-ホールドアウト」と「交差検定」は、どちらも精度検証の手法の1つです。
ともに有名な手法で、既に世の中に様々な解説がありますが、多少言葉が異なる場合もあるので、本記事ではDataRobotにおける定義を以下の図で簡単に説明しておきます。
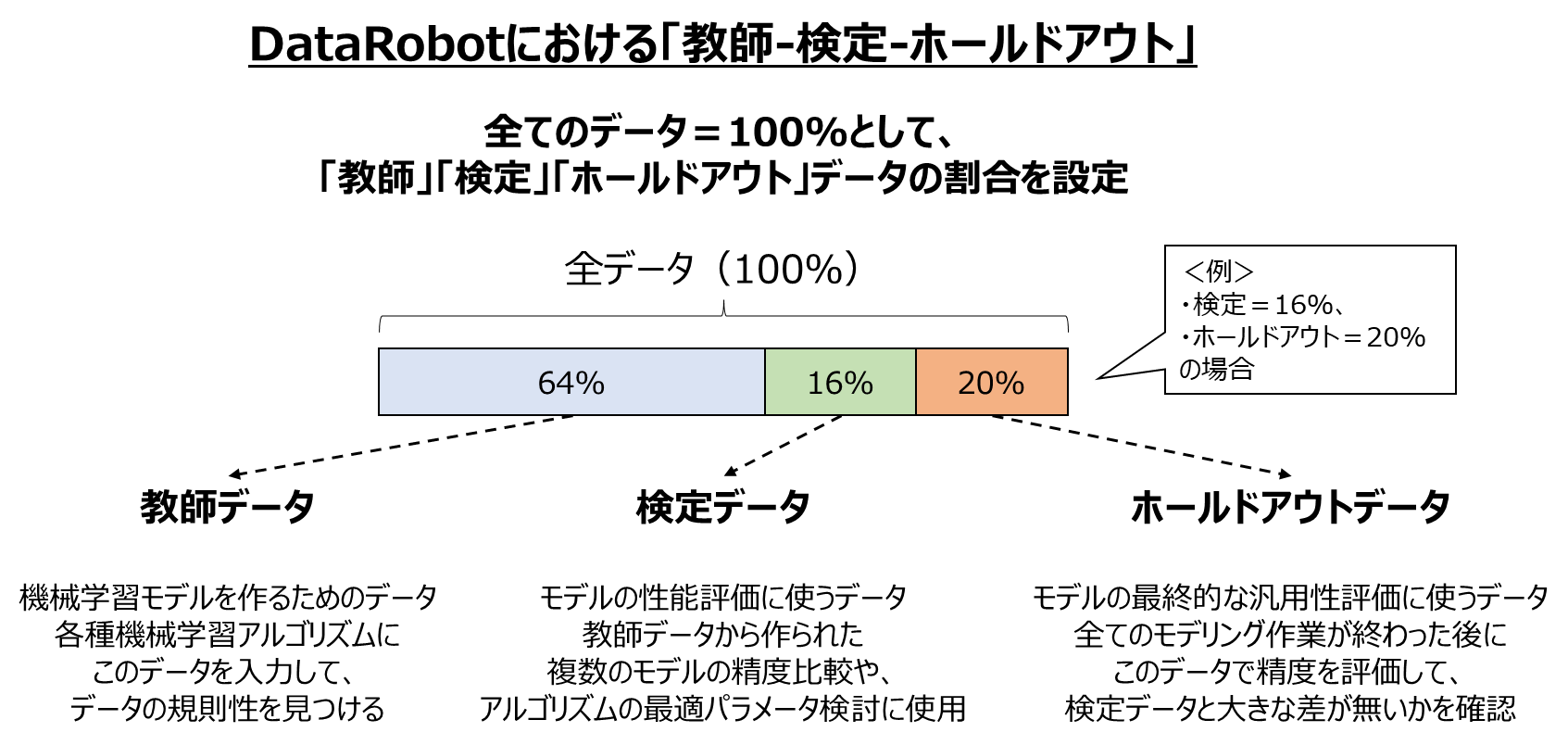

また、それぞれの手法の一般的なメリット・デメリットと、DataRobotにおける仕様を以下にまとめました。

前段知識② 「パーティション手法」
上で説明した「データを精度検証用にどう分割するか」という話に加えて「1つ1つのデータを、分割したうちのどれに割り振るか」(教師データに割り振るか、検定データか・・等)という話も重要です。
例えば、異常あり/なしのデータを教師データにして機械の異常判定モデルを作っても、検定データに異常ありのデータが1つも無ければ精度を適切に確認できません。
DataRobotでは適切にデータを割り振るための「パーティション手法」を揃えており、画面上で設定するだけで、自動でデータの割り振りを行ってくれます。(実際の画面はこの後お見せします)
以下が、DataRobotで選択できるパーティション手法の一覧になります。
なお、以降の説明では「教師-検定-ホールドアウト」を前提にしていますが、「交差検定」の場合も同様です(交差検定で分割した1つ1つのブロック(=fold)+ ホールドアウトデータ で同様の考え方をします)
| 手法名 | 説明 |
|---|---|
| ランダム | 1つ1つのデータを教師・検定・ホールドアウトデータにランダムに割り振る |
| 層化抽出 | 教師・検定・ホールドアウトデータの間で教師ラベルの割合が一定になるようデータを割り振る(2値分類でのみ使用可能) |
| グループ | 同じグループIDを持つデータが全て、教師・検定・ホールドアウトデータのいずれか1つに入るようデータを割り振る(グループID定義用の列が別途元データに必要) |
| パーティション特徴量 | 同じパーティションIDを持つデータが全て、教師・検定・ホールドアウトデータのいずれか1つに入るようデータを割り振る(パーティションID定義用の列が別途元データに必要) |
| 日付/時刻 | DataRobot上で「時間認識モデル」の設定を行った際に選択可能な手法。他の4つとは別で後述 |
補足ですが「グループ」手法は、例えば、ロットIDで管理された製品のデータや、同じ人から複数回答されたアンケートデータを扱うときに活用します。
このような似た傾向を持つデータを扱う場合、仮に同じ人のデータが学習・検証データの両方に分散すると「同じ人のデータを学習しているので検証データの精度は高いが、学習データにいない新しい人の予測精度は低い」ということが起きてしまいます。
DataRobotでは、データに「ロットID」「被験者ID」といった列がある場合に、これをグループID定義用の列として設定することで、同じロットや被験者のデータが教師・検定・ホールドアウトデータの複数に分散することを防ぎ、教師データに無いロットや被験者のデータで精度を検証するように自動で設定してくれます。
また「パーティション特徴量」手法は、説明文からも分かるように「グループ」手法と似ています。この2つの大きな違いは、教師・検定・ホールドアウトデータのそれぞれに割り当てられるID数です。(以下画像はイメージ)
- 「グループ」手法は、教師・検定・ホールドアウトデータのそれぞれに複数のIDが割り当てられる
(それぞれに最低3つのIDが割り当てできないとエラー発生) - 「パーティション特徴量」手法は、教師・検定・ホールドアウトデータそれぞれに1つのIDが対応
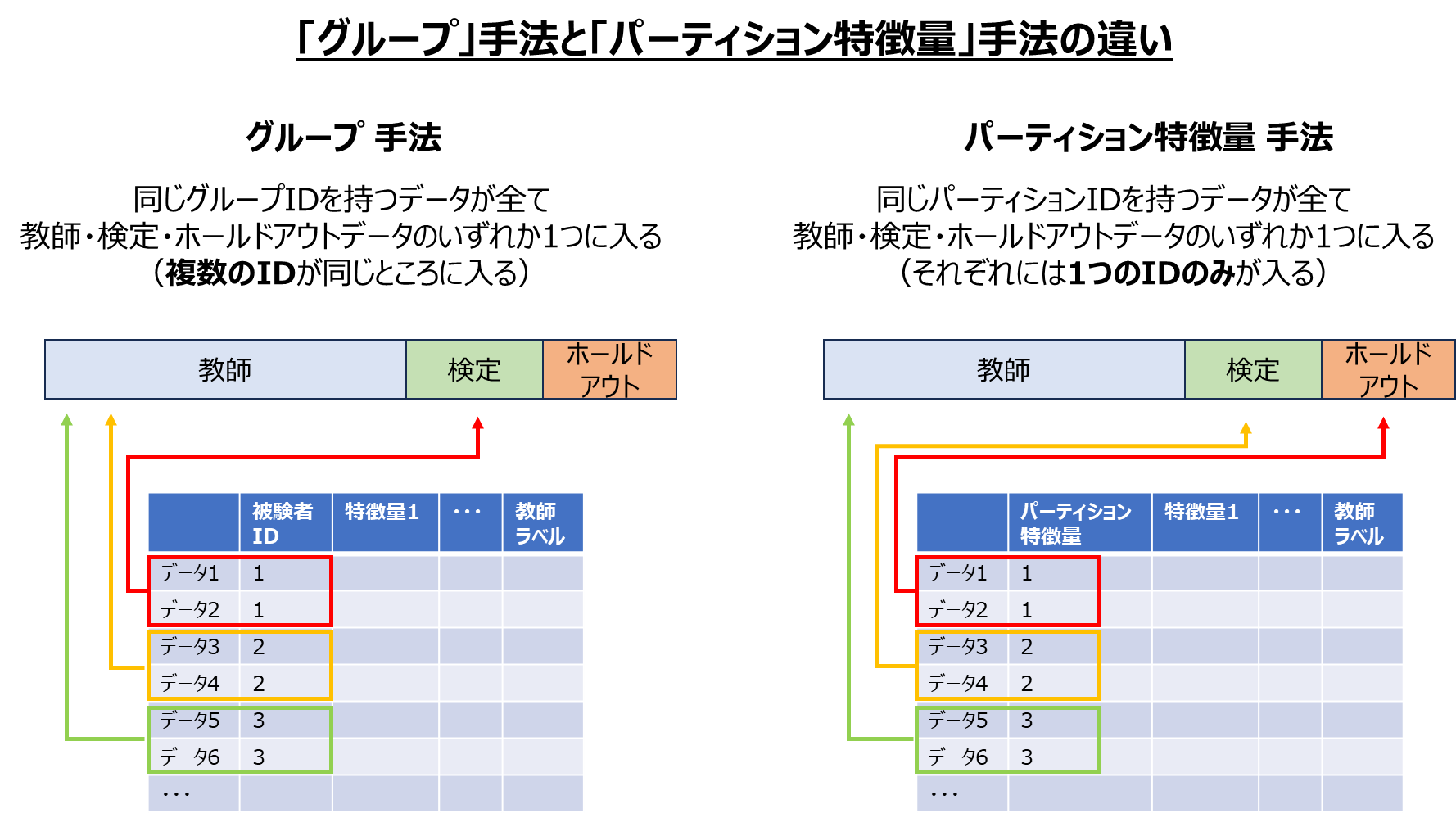
「パーティション特徴量」手法は、例えば以下のような場合に活用することができます。
- 「グループ」手法を使うにはIDが少ない場合(例:工場、年代等の大規模な単位での設定)
- 多値分類において層化抽出を実現したい場合(参考記事)
パーティション機能の設定画面
ここからは、上記の前段知識をもとに、DataRobotの「パーティション」機能をどう使うかを実際の画面とともに説明します。
以下画像は、DataRobotにデータをアップロードし、ターゲットを設定した後の画面です。アップロードやターゲットの設定方法は、他の記事を参考にしてください。
画面下側の「高度なオプションを表示」をクリックし、さらに左側の「パーティション」タブを開くと、以下のような画面になり、この画面で設定を行うことができます。
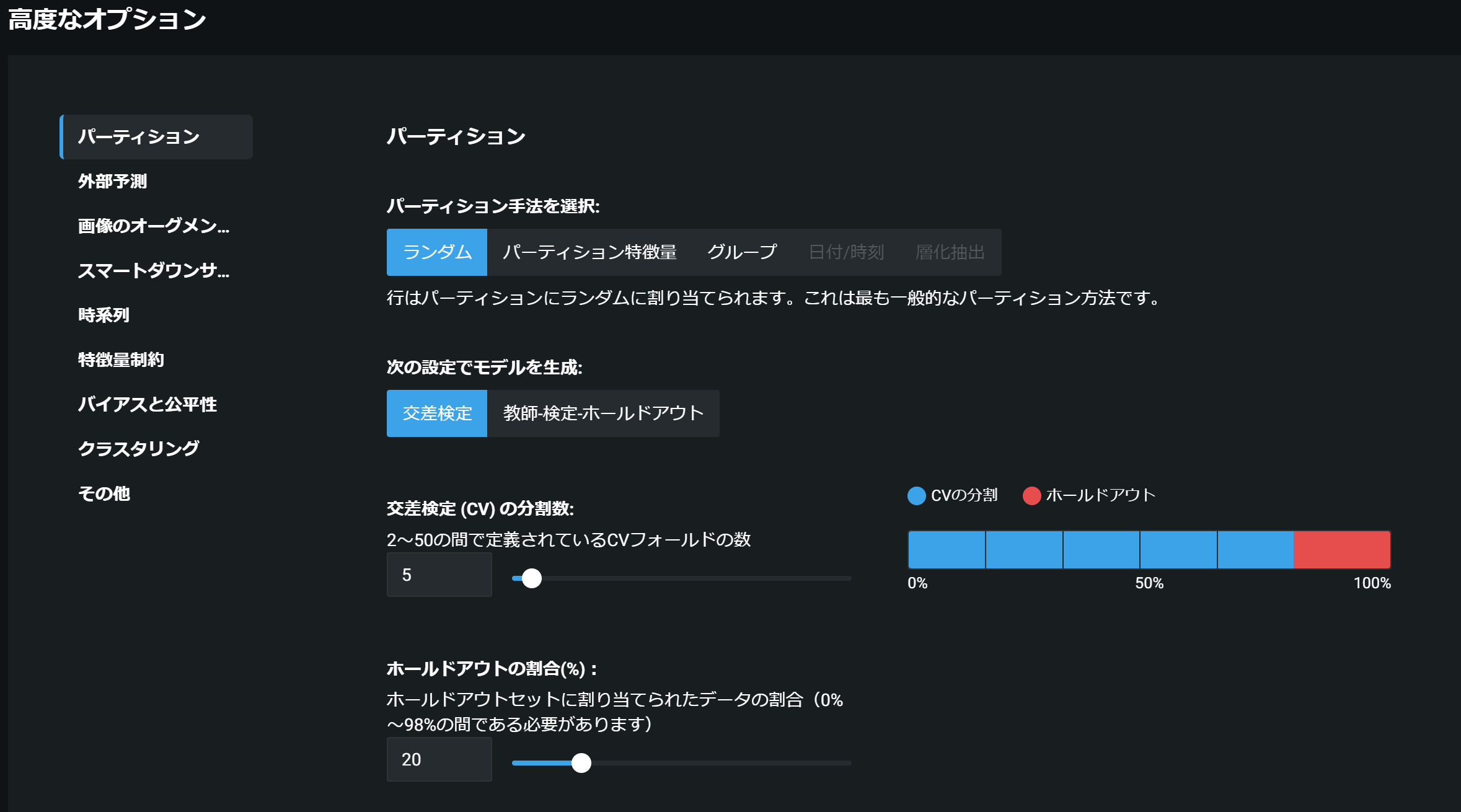
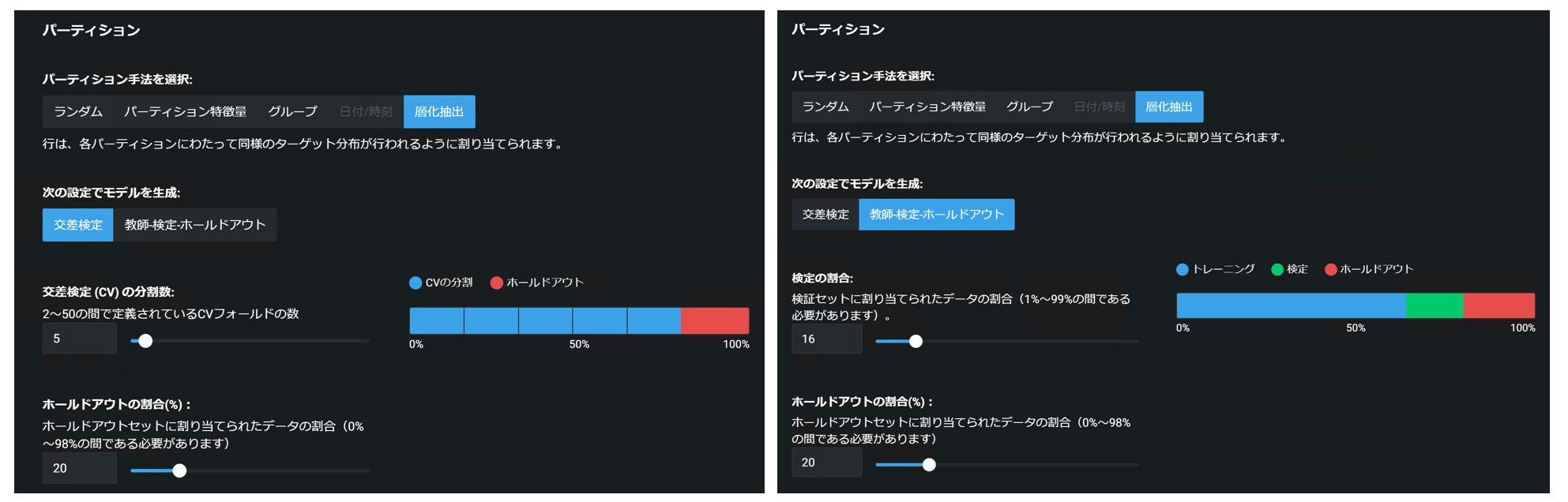
「ランダム」「層化抽出」手法の設定
この二つはほぼ同じ設定方法なので、一緒に説明します。大きくは、以下の手順です。
・ 「パーティション手法を選択」でランダムか層化抽出を選択
・ 「次の設定でモデルを生成」で、交差検定 or 教師-検定-ホールドアウトを選択
・ 交差検定の場合、「交差検定(CV)の分割数」「ホールドアウトの割合(%)」を設定
・ 教師-検定-ホールドアウトの場合、「検定の割合」「ホールドアウトの割合(%)」を設定
下は層化抽出の場合の設定画面ですが、ランダムでも同じ操作です。右側に、データがどう分割されているかが色で可視化されています。
「グループ」手法の設定
・ 「パーティション手法を選択」でグループを選択
・ 「グループID特徴量」に、グループIDを定義する列名を設定
・ 「次の設定でモデルを生成」で、交差検定 or 教師-検定-ホールドアウトを選択
・ 交差検定の場合、「交差検定(CV)の分割数」「ホールドアウトの割合(%)」を設定
・ 教師-検定-ホールドアウトの場合、「検定の割合」「ホールドアウトの割合(%)」を設定
以下は設定画面の一例です。ここでは「市区群町村」という特徴量(全23グループ)をグループIDに設定しています。また、ホールドアウト20%+5分割の交差検定(1分割あたり16%)を設定していますが、設定した割合になるべく近くなるよう各グループのデータを割り当てます。

「パーティション特徴量」手法の設定
・ 「パーティション手法を選択」でパーティション特徴量を選択
・ 「パーティション特徴量」に、パーティションIDを定義する列名を設定
以下画像は、0,1,2,3,4の5種類の数字のうちいずれかの値が記載された「partition」という列を使ってパーティション特徴量手法を使った場合の例です。(例として、5つの別々の工場のデータを扱っている状況を想定してください)
この場合、データを5つに分割する必要があるため「次の設定でモデルを生成」の部分では教師-検定-ホールドアウトが選択不可になっていて、自動で交差検定が選択されています。画面上にも黄色文字で注意書きが出ていますね。
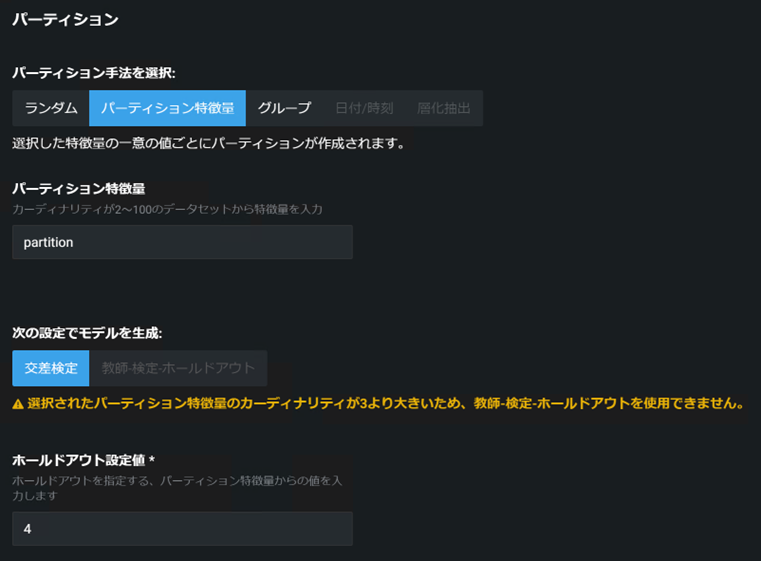
この状態で、「ホールドアウト設定値」に、ホールドアウトに設定する値を設定します。画像の例では、partition列が4になっているデータをホールドアウトに設定します。後は、残りの値である0,1,2,3のデータを使って4分割交差検定をするよう自動でDataRobotが設定してくれます。
このように、DataRobotでは本来複雑なパーティションの設定も、画面上で簡単に行えるようになっています。
「日付/時刻」手法の設定
本記事の最後になります。この手法はDataRobot上で事前に「時間認識モデル」を設定した際に選択可能な手法ですが、記事が長くなるので今回は時間認識モデルそのものと関連用語の説明はせず、DataRobot画面での設定方法のみ説明します。
(時間認識モデルについての詳細は、今後別記事で詳しく解説するかもしれません)
DataRobot上で各種設定を行った後に「高度なオプション」画面を開くと、以下のようにデフォルトで「日付/時刻」がパーティション手法として選択されます。

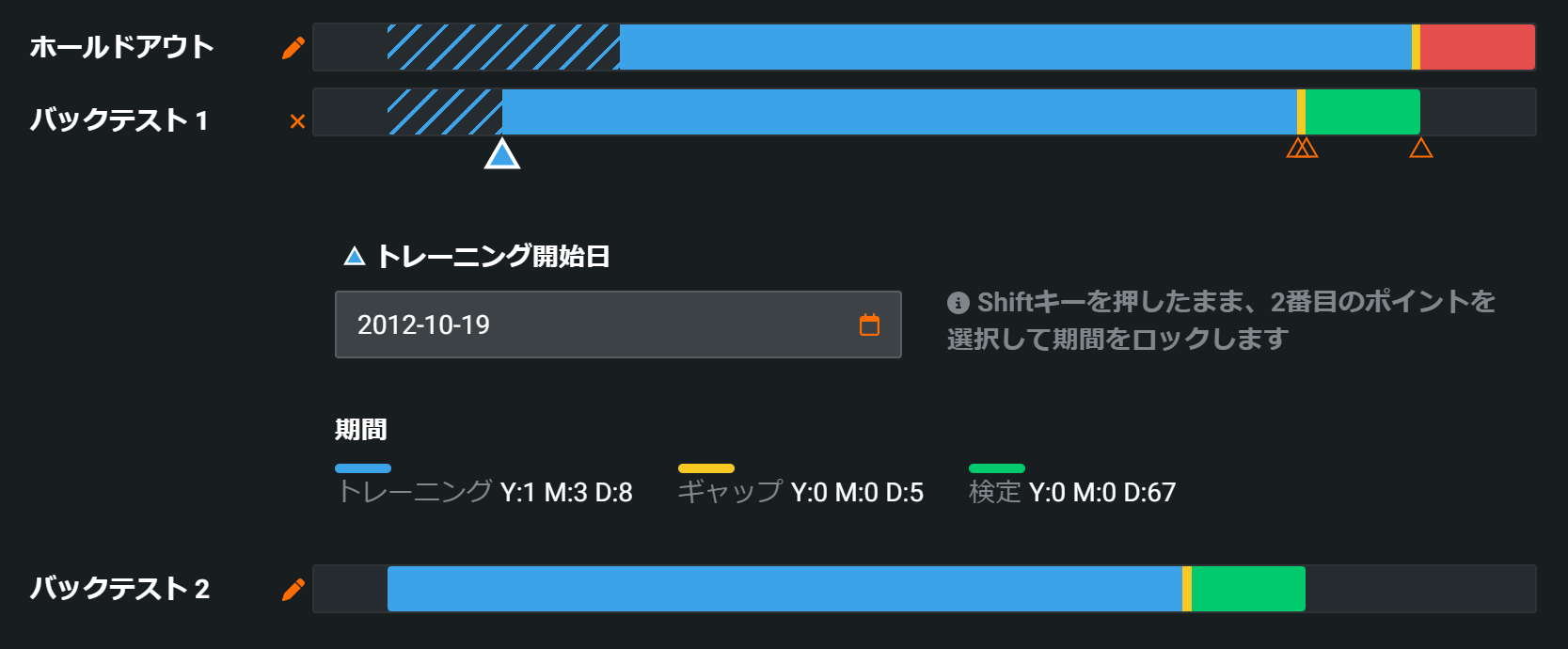
画面をスクロールすると、以下のような画面があり、ここでバックテストの設定を行うことができます。
まず、「バックテストを設定」のすぐ下で以下3つを設定することができます。
- バックテストの数
- 検定の長さ(期間で設定)
- ギャップの長さ(期間で設定)
それぞれの設定値については、画像のように、予測対象のデータやデータ数の分布のグラフとともに視覚的に確認することもできます。

ホールドアウトの長さや学習データの長さをより詳細に設定したい場合は、以下のように鉛筆マークをクリックすることで設定することもできます。このような時間軸を意識した分析設定も、DataRobotでは簡単に行うことができます。
まとめ
今回は、DataRobotのパーティション機能について説明しました。
ここまで説明をしておいてなのですが、DataRobotはデータを読み込んでターゲットを選択した段階で、自動でパーティションの設定もしてくれるので、何も設定しなくてもモデリング自体は進められます。
ただ、間違った設定のままモデリングを進めてしまうと、モデルの性能を見誤る大きな要因となるので、どんな設定でモデリングをしているかというのは毎回確認すると良いと思います!
DataRobotのパーティショニングについてもっと知りたいという方は、以下のページも参考にしてください。
今後も他の機能紹介記事や、デモ記事を紹介していきたいと思います!!
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。