はじめに
はじめまして。 NTTデータ ソリューション事業本部 デジタルサクセスソリューション事業部 の @nttd-nagano です。
Informatica(インフォマティカ) (※1)のクラウドデータマネジメントプラットフォームとして、「Intelligent Data Management Cloud」(※2。以下IDMCと記載)というものがあります。
今回は、そのIDMCのデータ取り込みサービス「 Cloud Data Ingestion and Replication 」(略称「CDIR」、旧称「Mass Ingestion」)(※3)の機能「SuperPipe」を使って、SQL Serverからクラウドデータウェアハウス(※4)Snowflake にリアルタイムで増分ロード(※6)してみた ので、ご報告します。
なお、記事執筆後に、当該記事で使用しているデータ取り込みサービスの名称が変更されました。本文は修正しましたが、スクリーンショットは旧名称でのものとなっております。ご了承ください。
- 旧名称:「Mass Ingestion」(「一括取り込み」)
- 新名称:「Data Ingestion and Replication」(略称CDIR。「データ取り込みおよびレプリケーション」)
※. 余談ですが、 弊社はSnowflakeも取り扱っており、「Snowflake Data Superheroes」(※7)が在籍しているほか、多数の受賞歴がございます。
※1. Informatica(インフォマティカ)
Informaticaは1993年に米国カリフォルニア州で設立され、2004年に日本法人を設立したデータマネジメント市場のパイオニア。Fortune100のうち86社を含む、100ヶ国以上の5000を超える企業がInformaticaのソリューションを採用しており、同社のクラウドは月間86兆件ものトランザクションを処理している。
※2. Intelligent Data Management Cloud
略称はIDMC。旧称はIICS。クラウドデータマネジメントプラットフォーム。以下IDMCと記載する。
※3. Cloud Data Ingestion and Replication(略称「CDIR」、旧称「Mass Ingestion」)
略称はCDIR。旧略称はCMI。データベースやSnowflakeなどのクラウドデータウェアハウス(※4)などへのデータ取り込みサービス。取り込み元は、データベースはもちろん、SAPやSalesforceなどのアプリケーション、ファイル、ストリーミングソースにも対応している。以下ではCDIRと記載する。
※4. クラウドデータウェアハウス
Snowflakeは当初同社のサービスを「クラウドデータウェアハウス」と位置づけていたが、その後、機能追加や適用範囲の拡大を踏まえて、現在は「データクラウド」と位置づけている。ここでは分かりやすさの観点から、当初の「クラウドデータウェアハウス」という表現を使用している。「クラウドデータウェアハウス」とは、クラウド版の「データウェアハウス」(※4)を指す。
※5. データウェアハウス
Data Warehouse、DWHとも表記される。「ウェアハウス」とは倉庫を表す英単語。「データウェアハウス」は、データ分析に必要な集計、結合、大量スキャン等の処理に特化したデータベースを指す。
※6. 増分ロード
ここでは「増分ロード」という言葉を、「差分ロード」という言葉と使い分けている。差分ロードの場合、毎回初回の全量連携から変更のあったレコードをロードする処理になる。一方、増分連携の場合、前回の連携から変更のあったレコードをロードする処理になる。
※7. Snowflake Data Superheroes
Snowflake Data Superheroは、Snowflakeが認定するSnowflakeのエキスパート集団。Snowflakeコミュニティーにおいて積極的に発信、情報交換を行い、Snowflake人材育成に貢献した功績が認められた人に与えられる。
ビジネスのアジリティを高めるためにはリアルタイム性のあるデータ活用基盤が重要になってくる
昨今、データドリブン経営を目指し、 日次あるいは数時間ごとに業務システムからデータ分析・活用基盤へデータを取り込んでいる例は多い と思います。
こうした中で、 ビジネスのアジリティをさらに高めていくためには、リアルタイム性のあるデータ活用基盤を実現することが重要になってくるのではないでしょうか。
このようなデータ活用基盤を持つことで、様々な変化に迅速に対応し、顧客のニーズを先読みすることなどで、競争力を強化していくことができます。また、鮮度の落ちたデータによる誤った判断を防ぐこともできます。
- 例
- 小売業におけるリアルタイムのマーケティングキャンペーン
- 製造業における機器トラブルのリアルタイムの予兆検知
- 金融業におけるリアルタイムの不正検出
リアルタイム性のあるデータ活用基盤をSnowflakeを中心として実現する場合の要素技術:継続的ロードとCDC
さて、こうしたリアルタイム性のあるデータ活用基盤を、最近注目されている クラウドデータウェアハウス Snowflake を中心として実現する場合を考えてみましょう。
一般的に、Snowflakeへデータをロードしたい場合、次のいずれかを使うことになります。
- COPYコマンドを使用したバルクロード
-
Snowpipeを使用した継続的ロード
- 以前からある仕組み。
- ステージングファイルが追加されたことを検知してロードする。
- クラウドストレージからの読み込みステップによりネットワーク的な遅延が数分加わる(高レイテンシ)。
- ステージング領域によりストレージコストがかかる。
-
Snowpipe Streamingを使用した継続的ロード
- 2023年7月に一般提供を開始した仕組み。
- ステージングファイルを必要とせずに、データ行をテーブルに直接書き込む。
- Snowpipeにはあったクラウドストレージからの読み込みステップがないため、遅延が短縮される(低レイテンシ)。
- 高スループット(GB/秒)。
- ストレージコストが不要で低コスト(取り込みの大小によらない)。
このうち「COPYコマンドを使用したバルクロード」は文字通りバルクでのロードを目的としていますので、リアルタイム性は期待できません。そのため、それ以外の「継続的ロード」系を検討することになります。
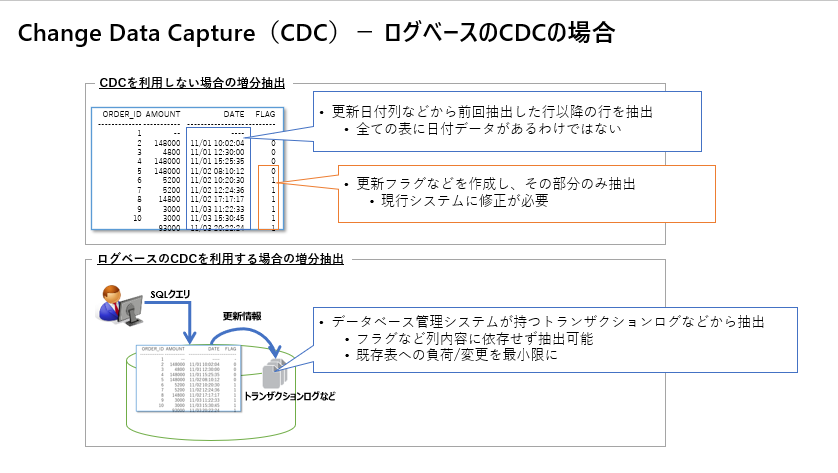
「継続的ロード」を使う場合、取り込み元がデータベースである場合は、「Change Data Capture」(以下「CDC」と記載します)というソフトウェアデザインパターンと組み合わせると、その利点を活かせると思います。
このデザインパターンの実現方法は様々ですが、たとえば、ほとんどのデータベース管理システムはすべての変更を記録する「トランザクションログ」や類似の仕組みを持っています。「CDC」の実現方法として、この トランザクションログなどをスキャンし、データベースに加えられた変更を捉えるという方法があります。これが、ログベースのCDCです。 その他にも様々な手法があります。
- CDCの手法
手法 詳細 ログベース データベースのすべての変更を記録するログ(トランザクションログなど)を読み取ることによりデータ変更をニアリアルタイムでキャプチャする。後述のInformaticaの実装では、Oracleの場合 REDOログ を読み込む、SQL Serverの場合は トランザクションログ と CDCテーブル を読み込む。 CDCテーブル CDCテーブル から直接データ変更をキャプチャする。 クエリベース CDCの対象カラムを指すWHERE句を使用してキャプチャする。 トリガーベース テーブルにトリガー(データベースでイベントが発生したときに自動的に実行される特殊なタイプのストアドプロシージャ)を仕掛け、データが変更されたときにトリガーを実行してキャプチャする。
リアルタイム性のあるデータ活用基盤をSnowflakeを中心として実現する方法を検討してみる
では、以上の要素技術(「CDC」および「継続的ロード」)に基づいたリアルタイム性のあるデータ活用基盤の実現方法を考えてみます。次の3点はどうでしょうか。
AWS DMS + SnowpipeでSnowflakeにロードする
まず考えられるのは、CDCを利用できる レプリケーションサービス AWS Database Migration Service(AWS DMS) と Snowpipe を使う方法です。
この方法を使うと、Snowflakeへの継続的な取り込みを実現できますが、継続的ロードの手段がSnowpipeであり、Snowpipe Streaming ではないため、Snowpipe Streamingの場合より遅延(およびコスト)は大きくなります。
なお、本筋から逸れますが、取り込み元はデータベースに限られます。 SAP や Salesforce などのアプリケーションのデータを取り込みたい場合は別の手段になります。

Debezium + Apache Kafka + Snowflake Sink Connector + SnowpipeでSnowflakeにロードする
次に考えられるのは、 CDCのためのオープンソースプラットフォーム Debezium と 分散イベントストリーミングプラットフォーム Apache Kafka と Snowflake Sink Connector を通じて Snowpipe を使う方法です。
こちらの方法も、Snowflakeへの継続的な取り込みを実現できますが、同様に継続的ロードの手段がSnowpipeであり、 Snowpipe Streaming ではないため、Snowpipe Streamingの場合より遅延(およびコスト)は大きくなります。
また、Debeziumの環境とKafkaの環境を構築するための手間が必要になります(これは環境を自分たちの手でコントロールできることと表裏一体ですが)。
なお、再び本筋から逸れますが、こちらも取り込み元はデータベースに限られます。 SAP や Salesforce などのアプリケーションのデータを取り込みたい場合は別の手段になります。

Debezium + Apache Kafka + Snowflake Connector for Kafka + Snowpipe StreamingでSnowflakeにロードする
次に考えられるのは、 Debezium と Apache Kafka と Snowflake Connector for Kafka を通じて Snowpipe Streaming を使う方法です。
この方法は前述の2例とは異なり、継続的ロードの手段がSnowpipe Streamingであるため、低遅延(および低コスト)でロードできます。
ただし、同様にDebeziumの環境とKafkaの環境を構築するための手間が必要になります(これは環境を自分たちの手でコントロールできることと表裏一体ですが)。
なお、再び本筋から逸れますが、こちらも取り込み元はデータベースに限られます。 SAP や Salesforce などのアプリケーションのデータを取り込みたい場合は別の手段になります。

ここまでのまとめ
ここまでの検討結果を整理すると、次のようになります。
-
Snowpipe 系を使う場合、 Snowpipe Streaming を使う場合より遅延が大きくなる。
リアルタイム性を重視するなら、できればSnowpipe Streamingを使いたい。また、そうすればコスト削減も期待できる。 -
Debezium + Apache Kafka 系の場合、Snowpipeだけでなく、Snowpipe Streamingを使う環境を構築することもできる。
ただし、環境を構築するための手間が必要になる(これは環境を自分たちの手でコントロールできることと表裏一体)。 - (本題ではないが)上記はすべて取り込み元がデータベースに限られる。
そのため、 SAP や Salesforce などのアプリケーションのデータを取り込みたい場合は別の手段を用意する必要があり、データベースからの取り込みと統合的に運用できない。
これらの課題に対して、 この記事では、Informaticaのクラウドの「 CDIR 」(※3)の「SuperPipe」をご紹介します。
後述する通り、 「SuperPipe」を使えば、GUIをポチポチ操作するだけで、CDCとSnowpipe Streamingを使ったリアルタイム性のある継続的ロードを実現できます。
また、 SAPやSalesforceなどのアプリケーションのデータの取り込みにも利用でき、さらにアプリケーションのデータの取り込みでも Snowpipe Streamingでの継続的ロードに対応しています。
なお、言うまでもないことですが、この「SuperPipe」を含め、どんな条件・状況にも効くようなソリューションというのはありません。実際上は個別の条件・状況に合わせたソリューションを選択することになります。
データ取り込みサービス「CDIR」とは
さて、Informaticaのクラウドサービス「IDMC」には、データ統合サービスとして「 Cloud Data Integration 」(※8)がありますが、それとは別に、 大量のデータを取り込むことに特化したデータ取り込みサービス「CDIR」(旧称「Mass Ingestion」)(※3)もあります。
※8. Cloud Data Integration
略称はCDI。データ統合サービス。ETL処理(※9)やELT処理(※10)を担う。以下CDIと記載。
※9. ETL処理
データベースなどに蓄積されたデータから必要なものを抽出(Extract)し、目的に応じて変換(Transform)し、データを必要とするシステムに格納(Load)すること。
※10. ELT処理
ETL処理(※9)と対比して使われることが多い言葉。データ統合処理の順序を従来型のE→T→Lの順ではなく、E→L→Tの順でおこなう。近年ではDBMSの性能が爆発的に向上したことから、その性能を有効活用するために使われる手法。
この「CDIR」を使えば、大量のデータを各種データベースやSnowflakeなどに簡単に取り込むことができます。
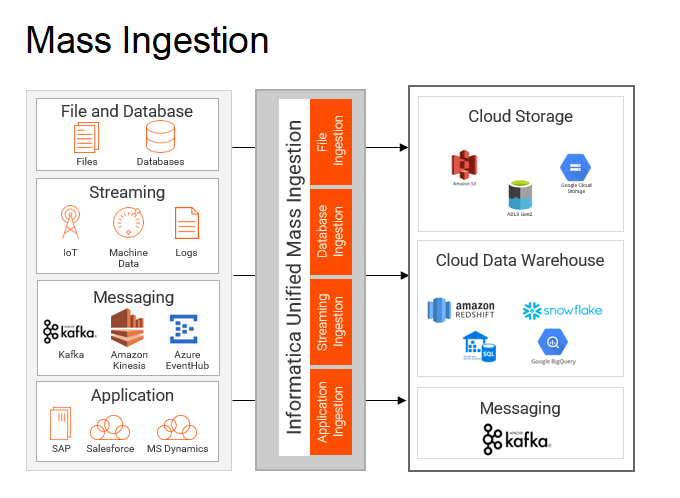
CDIRの取り込み元は次の4種です(※11)。
※11. 取り込み元について
CDCに対応している取り込み元と、対応していない取り込み元があります。-
データベース
- 機能名はDatabase Ingestion and Replication(旧称Mass Ingestion Databases)。
- 一部の取り込み元はCDCに対応 。
- 具体的な取り込み元(抜粋)
- Oracle
- PostgreSQL(Amazon RDS for PostgreSQL、Microsoft Azure Database for PostgreSQLを含む)
- Microsoft SQL Server
- Microsoft Azure SQL Database
-
SaaSアプリケーションおよびオンプレミスアプリケーション
- 機能名はApplication Ingestion and Replication(旧称Mass Ingestion Applications)。
- 具体的な取り込み元(抜粋)
-
ファイル
- 機能名はFile Ingestion and Replication(旧称Mass Ingestion Files)。
- 具体的な取り込み元(抜粋)
- FTP/SFTP
- Amazon S3
- Microsoft Azure Blob Storage
-
ストリーミングソース
- 機能名はStreaming Ingestion and Replication(旧称Mass Ingestion Streaming)。
- 具体的な取り込み元(抜粋)
- Apache Kafka
- Amazon Kinesis Data Streams
- AMQP
- MQTT
CDIRの取り込み先は次の通りです(※12)。
※12. 取り込み先について
後述のSuperPipeに対応している取り込み先はもちろんSnowflakeのみです。- 共通
- 具体的な取り込み先(抜粋)
- Oracle(Database Ingestion and Replication、Application Ingestion and Replicationのみ対応)
- Microsoft SQL Server(Database Ingestion and Replication、Application Ingestion and Replicationのみ対応)
-
Snowflake
※. 余談ですが 弊社はSnowflakeも取り扱っており多数の受賞歴がございます。 -
Databricks
※. 余談ですが 弊社はDatabricksも取り扱っており多数の受賞歴がございます。 - Amazon Redshift
- Microsoft Azure Synapse Analytics
- Google BigQuery
- Amazon S3
- Microsoft Azure Data Lake Storage
- Kafka(Streaming Ingestion and Replicationのみ対応)
- Amazon Kinesis Data Firehose(Streaming Ingestion and Replicationのみ対応)
- Microsoft Azure Event Hubs(Streaming Ingestion and Replicationのみ対応)
- 具体的な取り込み先(抜粋)
「CDIR」の「SuperPipe」とは
さて、昨年2023年12月、このうち、 「Database Ingestion and Replication」と「Application Ingestion and Replication」が前述の Snowpipe Streaming に対応しました。
Informaticaはこれに 「SuperPipe」という名称をつけてリリースしています。
この「SuperPipe」を使えば、GUIをポチポチ操作するだけで、Snowpipe Streamingでのリアルタイム性のある継続的ロードを実現できます。

参考:「SuperPipe」のための準備方法・実行方法のドキュメント
「SuperPipe」のための準備方法と実行方法は、次の公式ドキュメントに記載されています。
- 今回の取り込み元であるSQL Server接続(※13)の設定値の詳細は、 公式ドキュメント「Microsoft SQL Serverコネクタ」 をご覧ください。その他の取り込み元の設定方法も隣接部にあります。
- 取り込み先であるSnowflake接続(※13)の設定値の詳細は、 公式ドキュメント「Snowflake Data Cloud Connector」 をご覧ください。
なお、SuperPipeを使う場合は「Authentication」欄の設定値を「Standard」ではなく、「KeyPair」にする必要があります。秘密鍵と公開鍵の生成方法は、 公式ドキュメント「Snowflake Data Cloud Connector」 をご覧ください。 - データベース取り込みタスクの作成方法の詳細は、 公式ドキュメント「Database Ingestion and Replication」 をご覧ください。
※13. 接続
認証情報などを管理するIDMC上の定義体。
実際に「SuperPipe」を使ってみる
では、実際に「SuperPipe」を使ってみます。今回の取り込み元はSQL Serverとします。
なお、ここではAmazon RDS for SQL Serverを使っていますが、オンプレミスのSQL Serverの場合も同一の手順で実現できます。
手順は次の通りです。
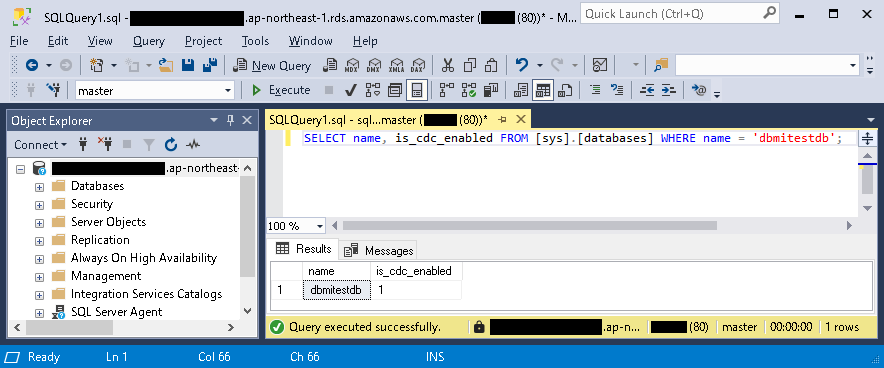
- CDCが有効になっているかを確認する。
- SQL Serverにテーブルを作成する。
- 作成したテーブルにデータを投入する。今回は下図のようなダミーデータを10000件投入しました。
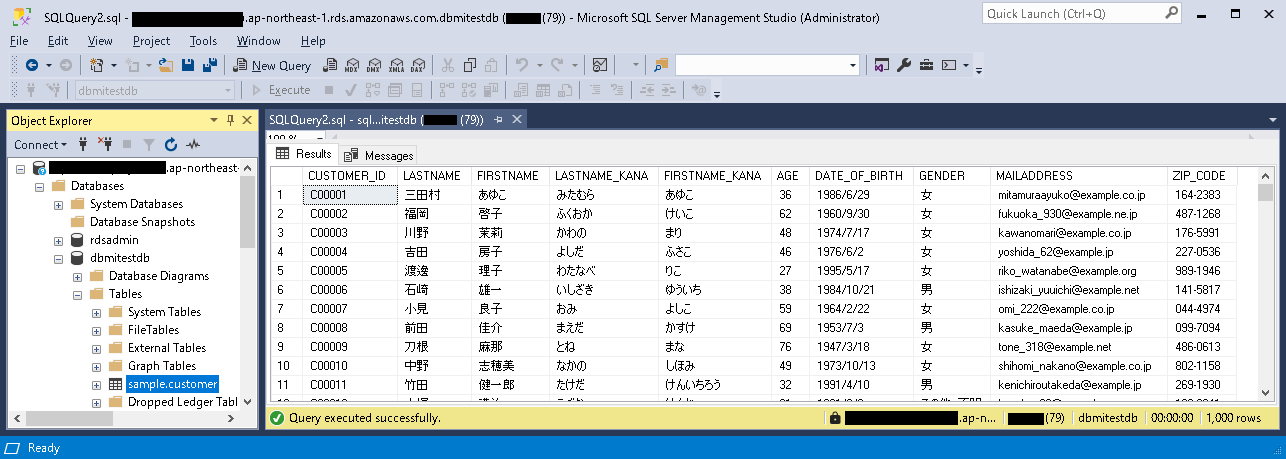
- IDMCにログインする。
- 「マイサービス」ダイアログにて「管理者」(Administrator)をクリックする。
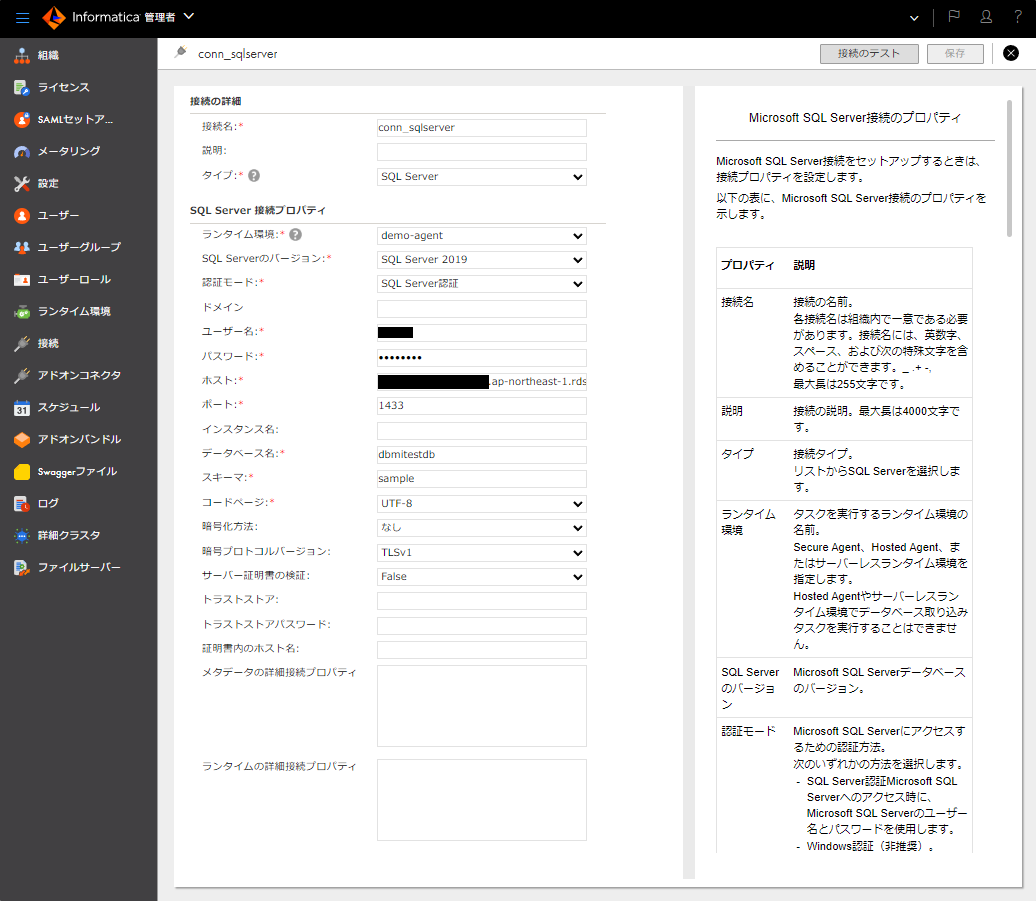
- サイドバーの「接続」をクリックする。
- 「新しい接続」ボタンをクリックする。
- 取り込み元として下図のようなSQL Server接続を作成する。
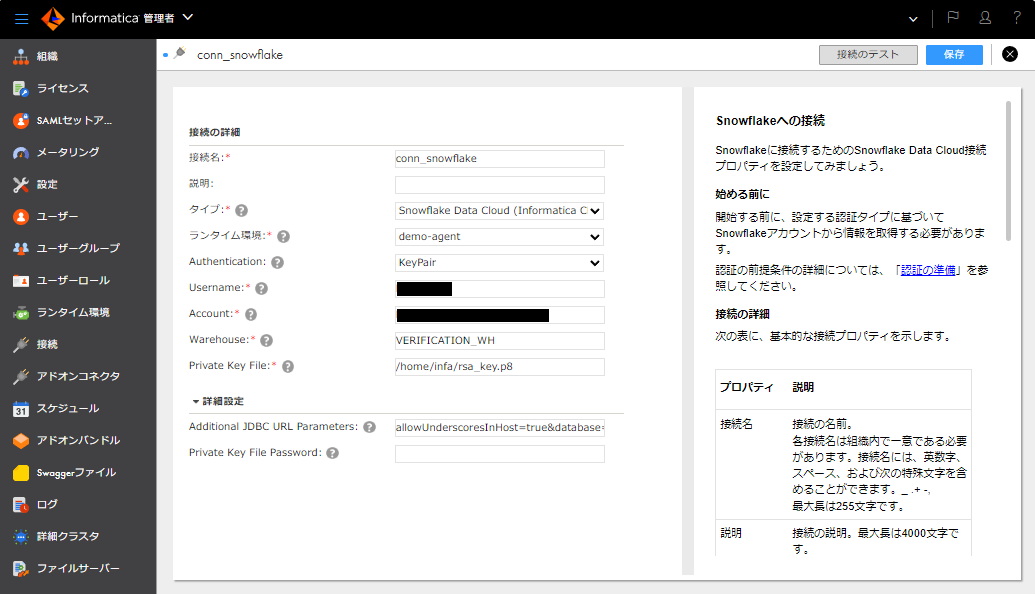
- 「新しい接続」ボタンをクリックする。
- 取り込み先として下図のようなSnowflake接続を作成する。
- 左上の「>」部をクリックする。
- 「マイサービス」ダイアログにて「データ取り込みおよびレプリケーション」(Cloud Data Ingestion and Replication)をクリックする。
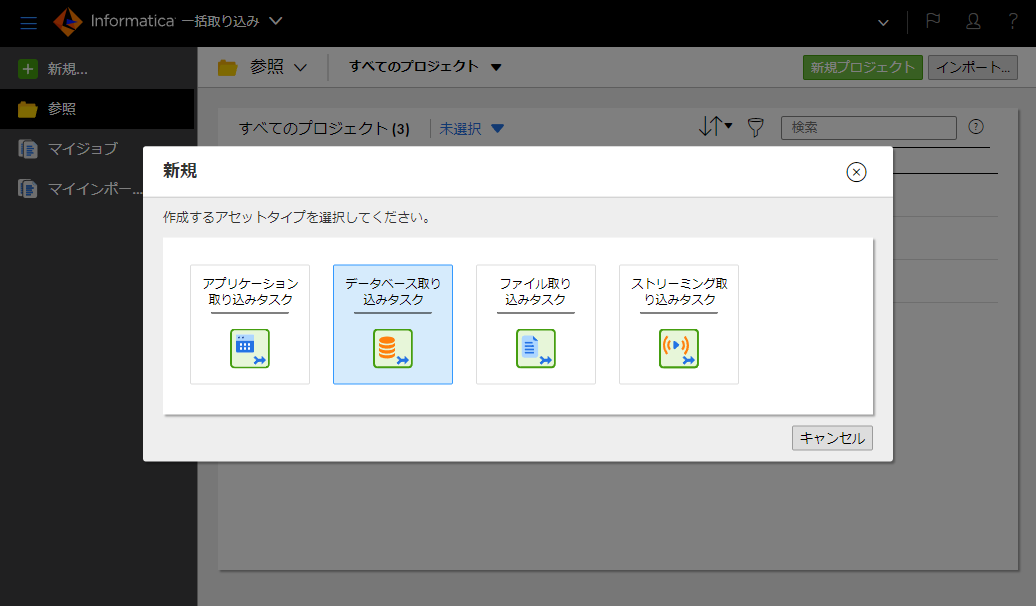
- 「データベース取り込みタスク」をクリックする。
- 「名前」欄に任意の名称を入力する。(例:「dbmi_sqlserver_snowflake_cdc_streaming」)
- 「ランタイム環境」欄にてSecure Agentをインストール済みの環境を選択する。
- 「ロードタイプ」欄にて「初期ロードと増分ロード」を選択する。
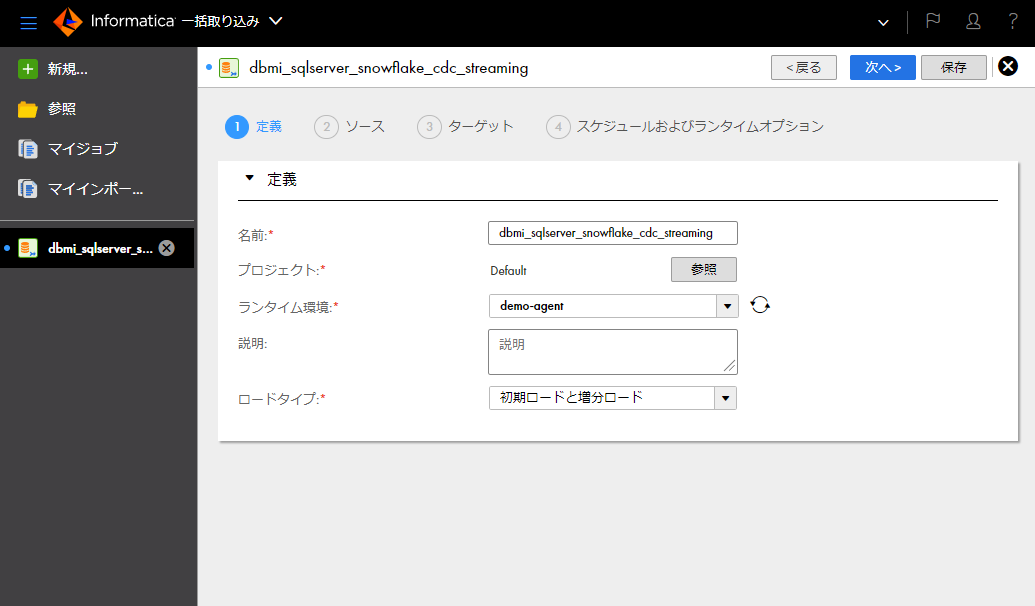
- 「次へ」ボタンをクリックする。
- 「ソース」パートの「接続」欄にて、取り込み元であるSQL Server接続を選択する。
- 「ソース」パートの「スキーマ」欄にて取り込み元とするスキーマを選択する。
- 「データキャプチャメソッドの変更」パートの「CDCメソッド」欄にて「ログベース」を選択する。
- 「テーブルの選択」パートの「ルール」パートに「テーブルルール」欄の設定値が「含む」で条件欄の設定値が「*」の行があることを確認する(必要に応じて変更する)。
- 「テーブルの選択」パートの更新アイコンをクリックして、「影響を受けるテーブル」欄に対象テーブル数を表示させる。
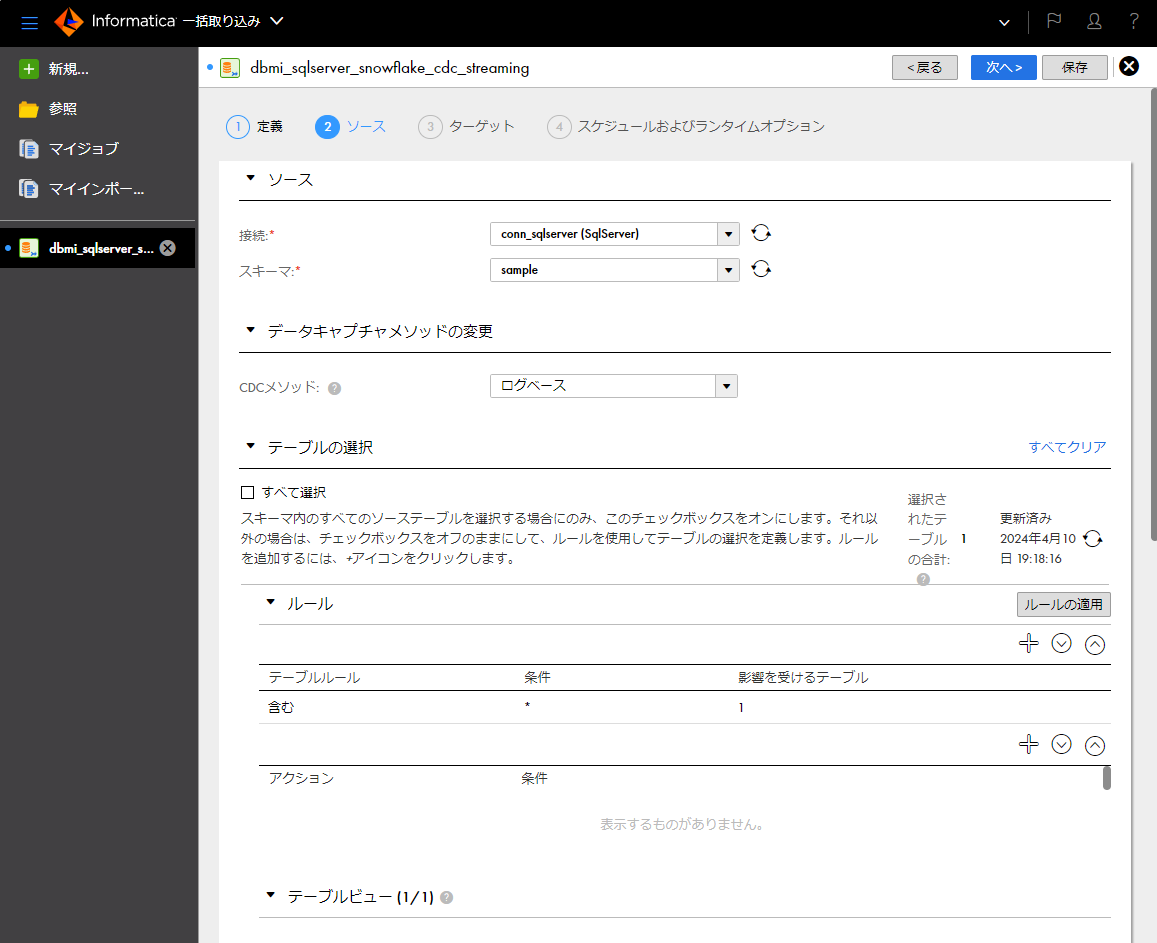
- 「テーブルの選択」パートの「テーブルビュー」パートに対象テーブルが表示されていることを確認する。
- 「テーブルの選択」パートの「テーブルビュー」パートの「CDCスクリプト」欄にて「すべてのカラムのCDCを有効化」が選択されていることを確認する(必要に応じて変更する)。
- 「テーブルの選択」パートの「テーブルビュー」パートの「CDCスクリプト」欄の右の「実行」ボタンをクリックする。
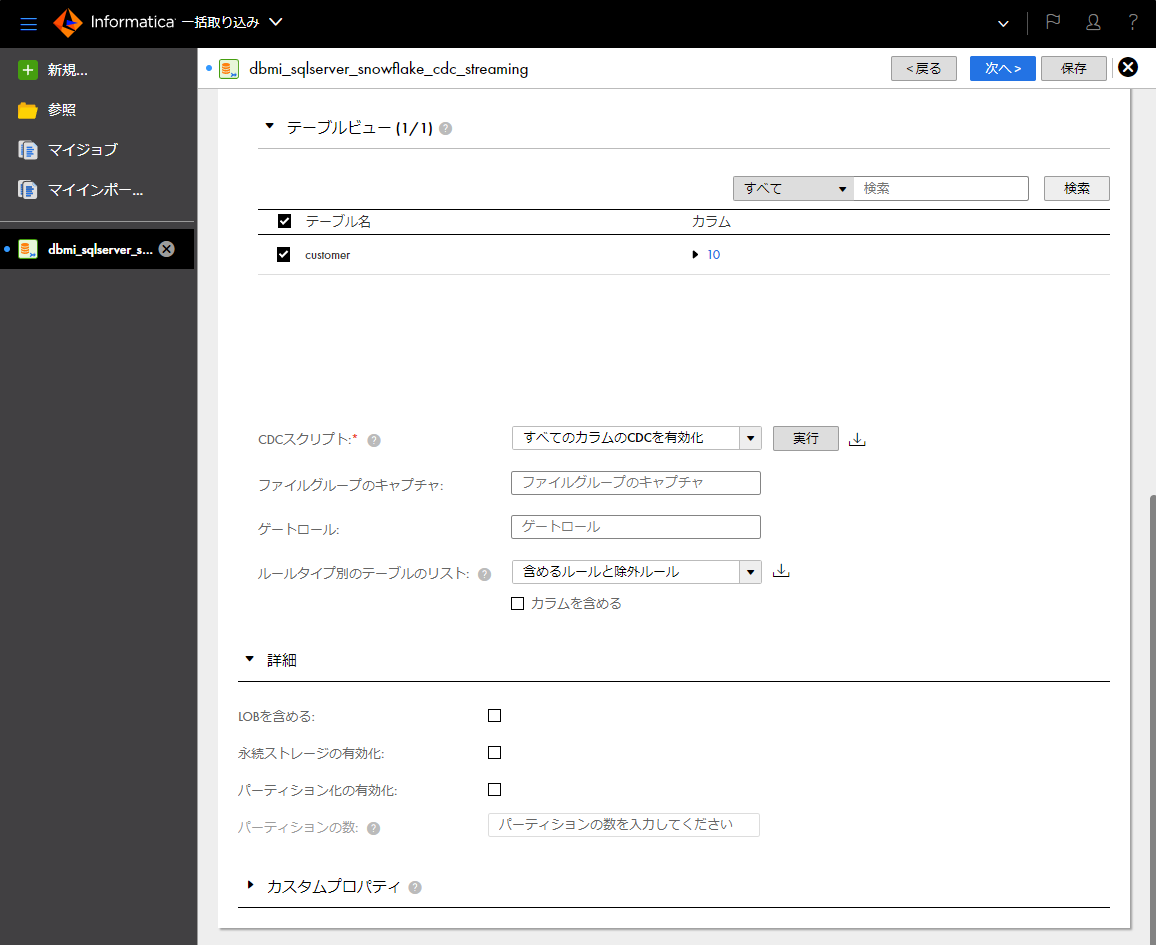
- 「CDCスクリプトは正常に完了しました。」と表示されることを確認する。
- 「次へ」ボタンをクリックする。
- 「ターゲット」パートの「接続」欄にて、取り込み先であるSnowflake接続を選択する。
- 「ターゲット」パートの「スキーマ」欄にて取り込み先とするスキーマを選択する。
- 「ターゲット」パートの「適用モード」欄にて「標準」を選択する(1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前により少ないSQL文になるようにそれらをインテリジェントにマージするという設定値です)。
- 「詳細」パートの「SuperPipe」欄を有効にする。
- 「詳細」パートの「マージ頻度」欄に「300」と入力する。これは300秒=5分を示す(Superpipeの場合、変更データ行がマージされターゲットテーブルに適用される頻度を秒単位で設定できます。有効な値は300~604800)。
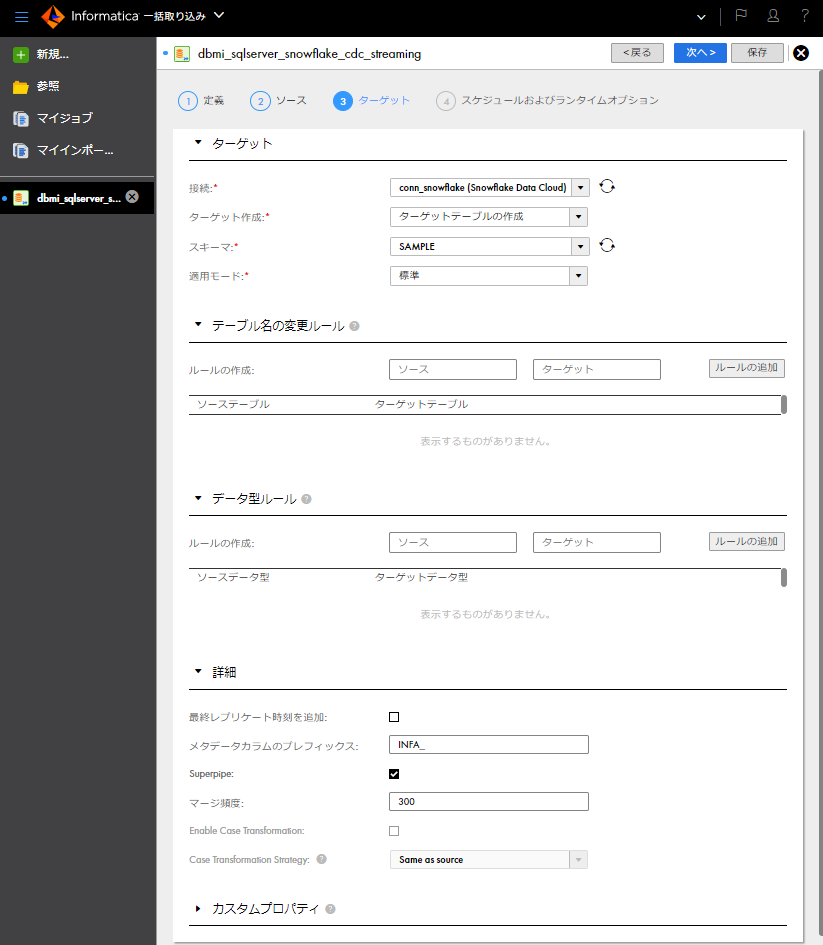
- 「次へ」ボタンをクリックする。
- 「保存」ボタンをクリックする。
- 「デプロイ」ボタンをクリックする。
- サイドバーの「マイジョブ」をクリックする。

- デプロイしたデータ取り込みタスクを探し、右端の「…」をクリックし、ドロップダウンリストにて「実行」をクリックする。

- デプロイしたデータ取り込みタスクをクリックする。
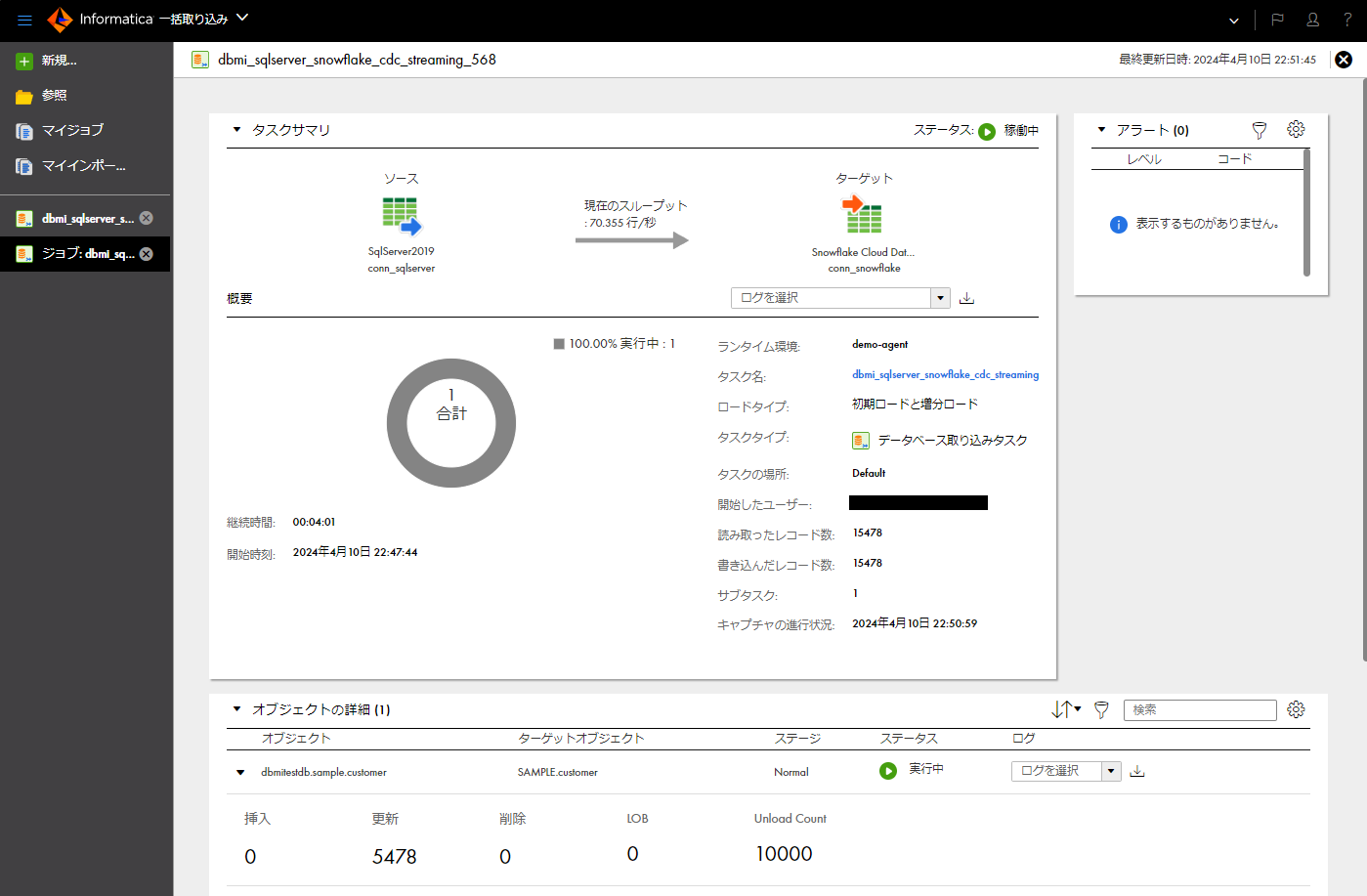
- 「概要」パートにて、データ取り込みタスクの最初の実行の結果(読み取られたレコード数、書き込まれたレコード数などの情報)を確認する。
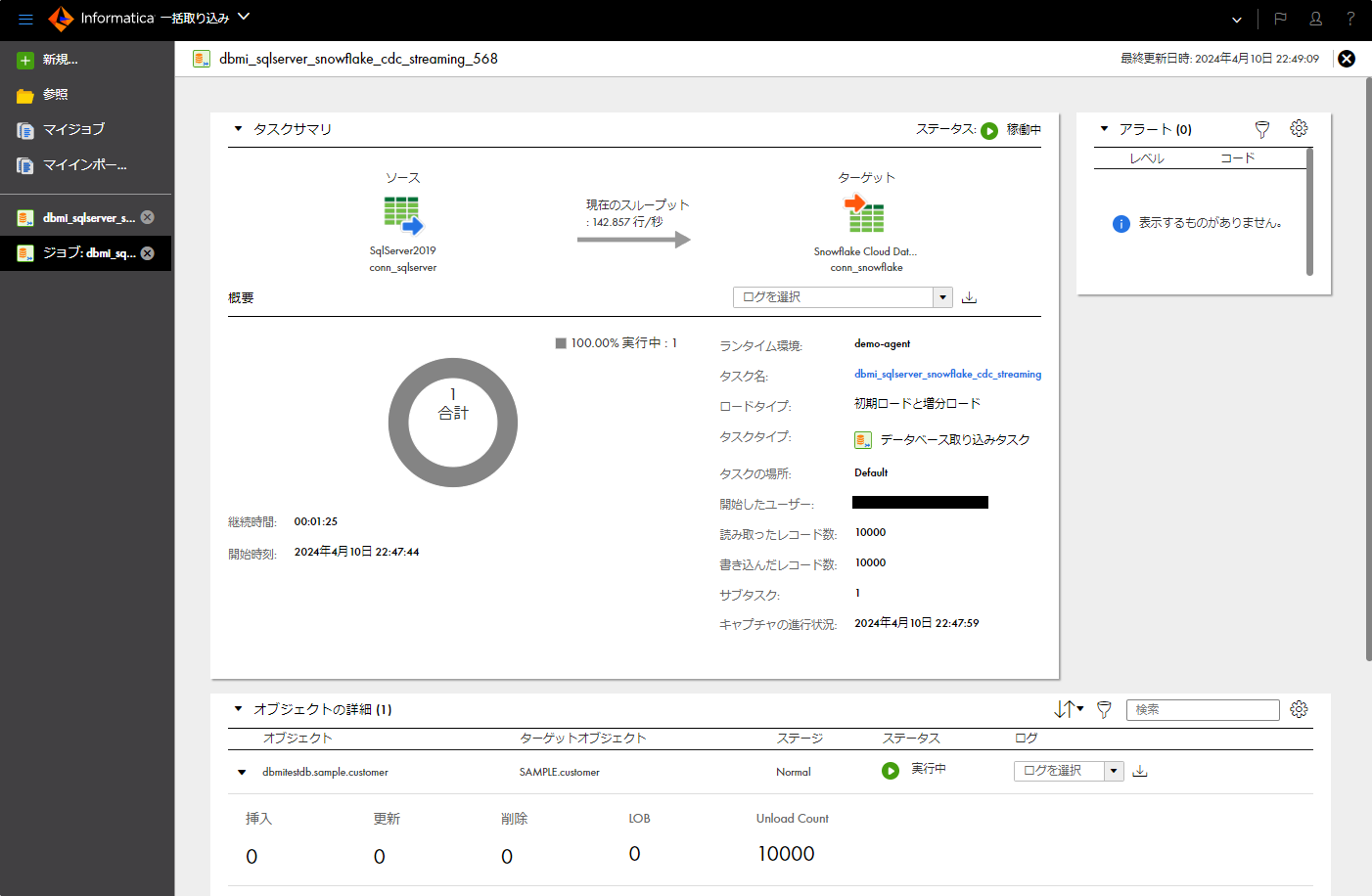
- 動作確認のため、取り込み元テーブルのレコードを更新してみる。
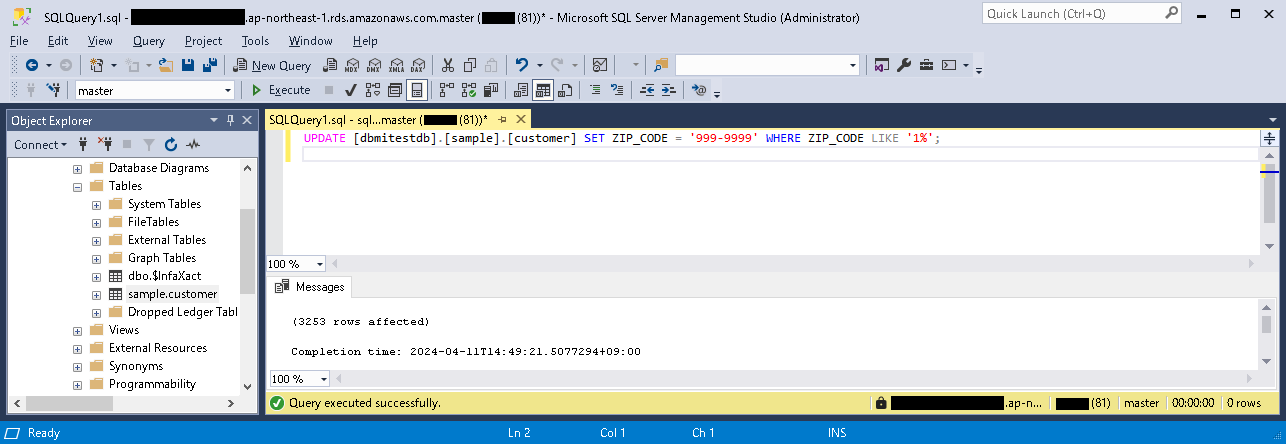
- 「概要」パートにて、タスクの実行の結果を確認する(更新レコード数などの情報)。
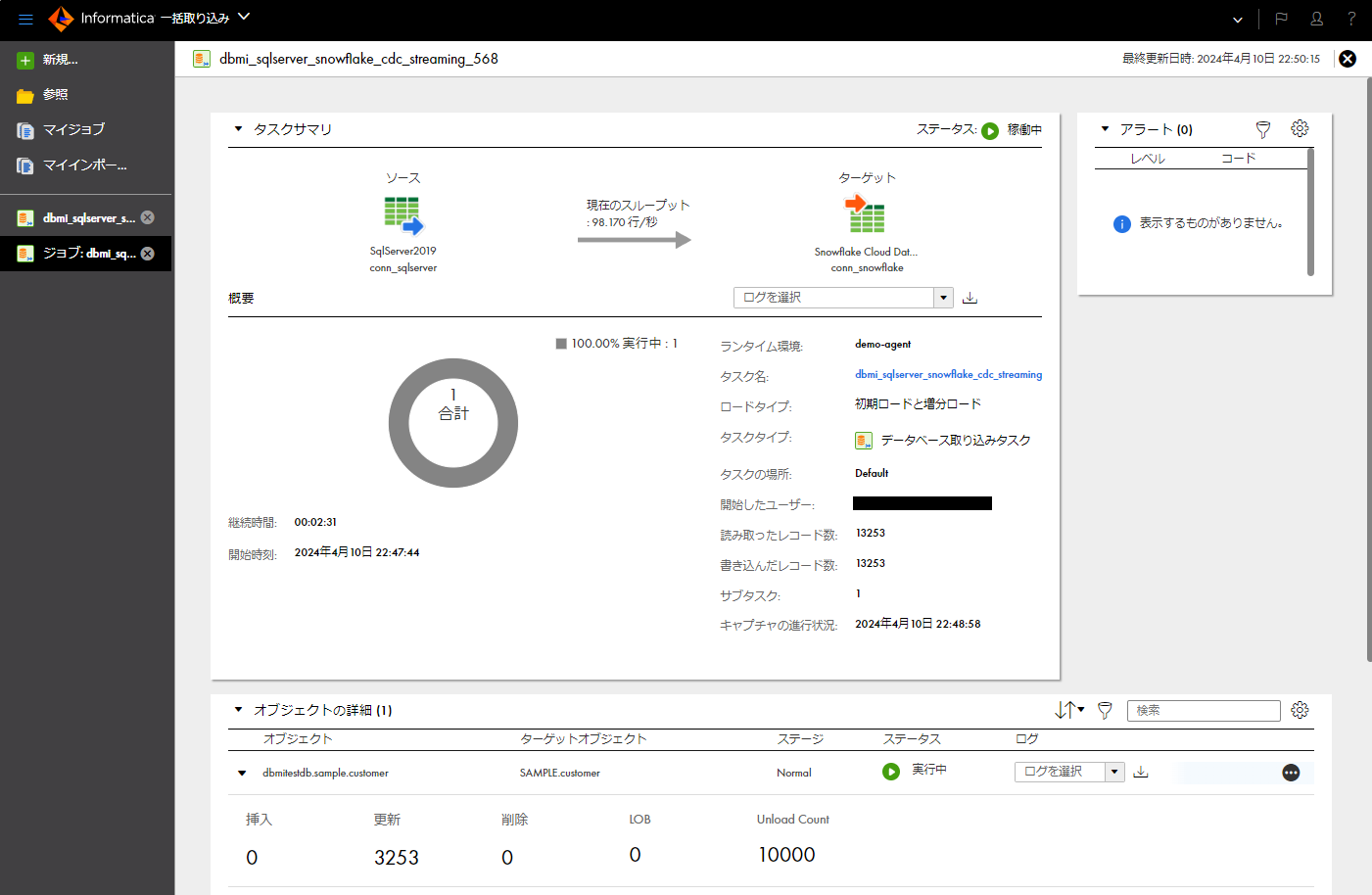
- 再度、動作確認のため、取り込み元テーブルのレコードを更新してみる。
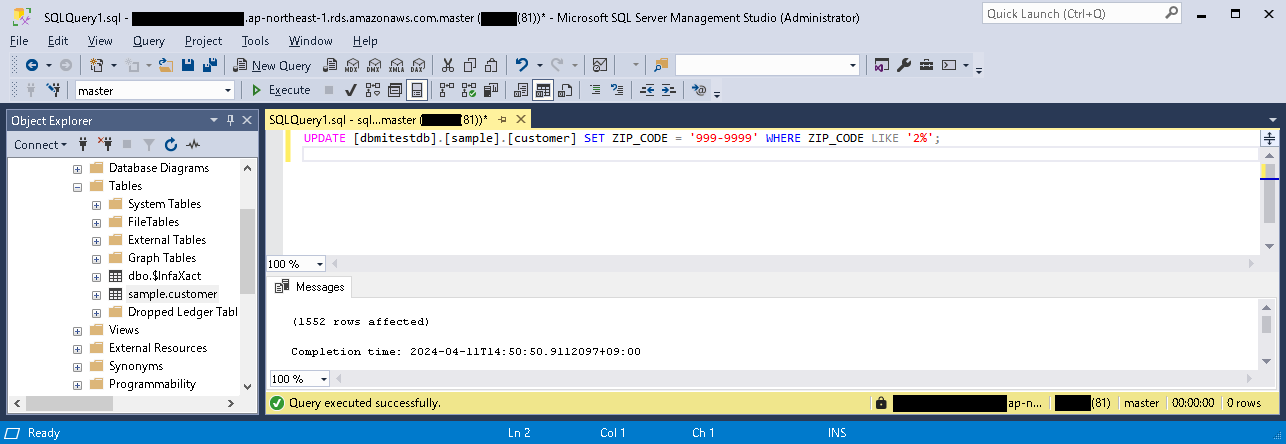
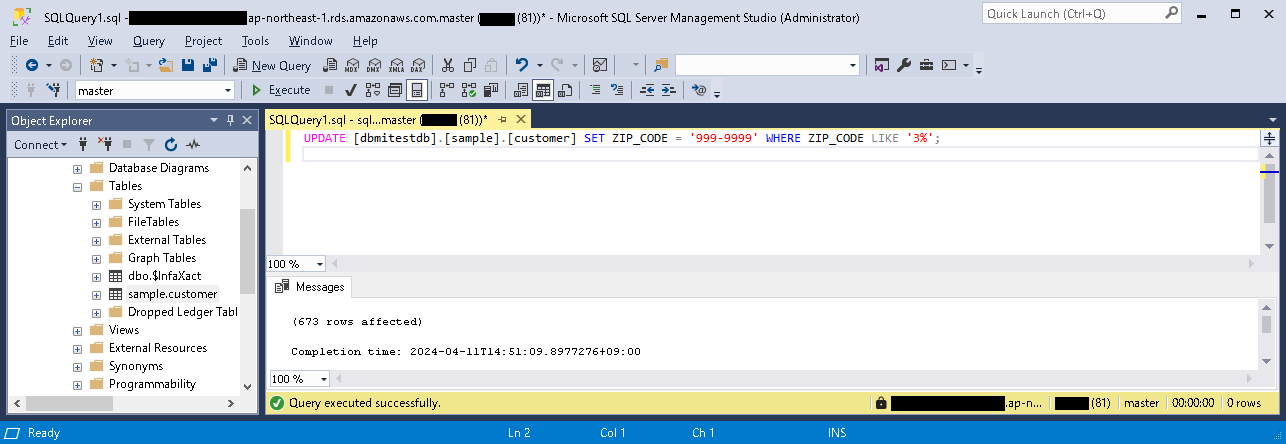
- 「概要」パートにて、タスクの実行の結果を確認する(更新レコード数などの情報)。
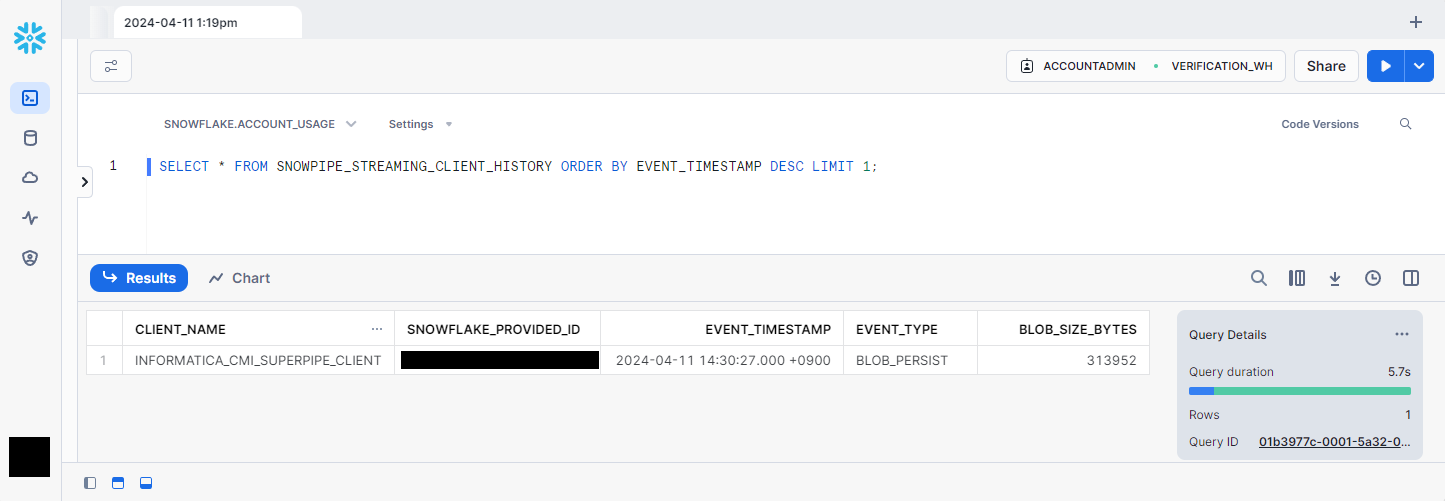
- 最後に、Snowpipeではなく、Snowpipe Streamingを使っていることを確認するために、Snowflakeにログインし、
ACCOUNT_USAGEスキーマのSNOWPIPE_STREAMING_CLIENT_HISTORYビューをSELECTしてみる。
以上で実際に「SuperPipe」を使ってみることができました。
そして確かにSnowpipe Streamingを使ってロードされたようですね!
参考:CDIRのソース/ターゲットの対応バージョン・組み合わせ、CDCの可否などの詳細
- ソース/ターゲットの対応バージョン・組み合わせなど
- 各データベースごとのCDCの可否、可能な場合そのメカニズムなど
- 公式ドキュメント データベース取り込みとレプリケーションソース - 準備と使用
おわりに
以上、「Informaticaのクラウドを使ってSQL ServerからSnowflakeにリアルタイムで増分ロードしてみた」でした。
Snowflakeへのリアルタイム性のあるロードが、ほぼGUIだけで実現できるのは手軽ですね。
必要なテーブルのみを対象にできるのも利便性が高いと思います。
IDMCをご契約中の方はぜひ試していただければと思います。
未契約の方は弊社までお声掛けください。
IDMCのデータ統合サービス「CDI」は30日間の無料体験ができる ので、この機会に試してみてはいかがでしょうか。
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata-career.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。https://nttdata-career.jposting.net/u/job.phtml?job_code=898
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://www.nttdata.com/jp/ja/lineup/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://www.nttdata.com/jp/ja/lineup/tdf_am/
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://www.nttdata.com/jp/ja/lineup/informatica/
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://www.nttdata.com/jp/ja/lineup/tableau/
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとDatabricksについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Databricksは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。