「K&R プログラミング言語C」の 「6.5 自己参照的構造体」で紹介されていた関数をまとめて、入力された文章の単語の出現頻度を数えるプログラムを動かしてみました。
ソースコードは 4 項に載せましたので、以下のようにコンパイルして実行ファイルを作成してください。
$ gcc -Wall -o wcount wcount.c
引数なしで実行して、"now is the time for all good men to come to the aid of their party" と入力後に行頭で Ctrl-d ( EOF ) を入力します。
$ ./wcount
now is the time for all good men to come to the aid of their party
<Ctrl-d>
実行結果は以下のようになり、入力した文章の中の単語の出現回数が辞書順に表示されます。
1 aid
1 all
1 come
1 for
1 good
1 is
1 men
1 now
1 of
1 party
2 the
1 their
1 time
2 to
単語を整理するのに、ここでは二分木と呼ばれるデータ構造を採用しています。二分木の詳しい説明は以下のサイトをご参照ください。今回のプログラムでは、二分木のノード追加 ( addtree 関数 ) には行きがけ順の探索、辞書順の印字 ( treeprint 関数 ) には通りがけ順の探索、メモリ領域の解放 ( treefree 関数 ) には帰りがけ順の探索を使用しています。
二分探索木については、下記のサイトの説明をご参照ください。
うさぎでもわかる2分探索木 前編
うさぎでもわかる2分探索木 後編
まず二分木のノードを次のような構造体で表現します。
struct tnode { /* 木のノード */
char *word; /* テキストへのポインタ */
int count; /* 出現回数 */
struct tnode *left; /* 左の子ノード */
struct tnode *right; /* 右の子ノード */
};
このノードには tnode 同じ構造体の子ノード ( ポインタ ) が二つ含まれています。左の子ノードにはそのノードの単語より辞書順で小さい単語、右の子ノードにはそのノードの単語より辞書順で大きい単語が保持されます。
" now is the time for all good men to come to the aid of their party " という文章の各単語が出てくるたびに単語順の大小を比較しながら、適当に挿入をおこなって作った二分木は次のようになります。
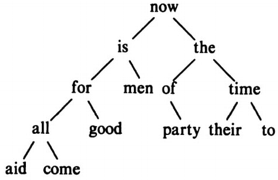
1. main 関数
main 関数の概要は以下の通りです。
getword( ) :
$\quad$ 入力から単語を抽出して word[ ] に格納する。
$\quad$ 入力が英数字 ( 空白はスキップ ) 以外の場合はその文字、
$\quad$ 英数字からなる単語の場合は先頭文字を返す。
addtree( ) :
$\quad$ root を根元として単語をノードに挿入する。
$\quad$ノードの単語と新しい単語が一致する場合は、count を 1 増やす。
$\quad$ while ( getword( ) の戻り値が EOF でない ) {
$\quad\quad$ if ( 単語の先頭文字が英字である )
$\quad\quad\quad$ addtree( root, word ) : ノードの追加
$\quad$ }
$\quad$ treeprint( root ) : 全ノード ( 単語と出現回数 ) を辞書順に印字する
1 #include <stdio.h>
2 #include <ctype.h>
3 #include <string.h>
4
5 #define MAXWORD 100
6
7 struct tnode { /* 木のノード */
8 char *word; /* テキストへのポインタ */
9 int count; /* 出現回数 */
10 struct tnode *left; /* 左の子ノード */
11 struct tnode *right; /* 右の子ノード */
12 };
13
14 struct tnode *addtree(struct tnode *, char *);
15 void treeprint(struct tnode *);
16 struct tnode *talloc(void);
17 char *kr_strdup(char *);
18 int getword(char *, int);
19
20 /* 単語の頻度カウント */
21 int main(void)
22 {
23 struct tnode *root;
24 char word[MAXWORD];
25
26 root = NULL;
27 while (getword(word, MAXWORD) != EOF)
28 if (isalpha(word[0]))
29 root = addtree(root, word);
b+ 30 treeprint(root);
31 return 0;
32 }
33
gdb で各ノードのメモリ配置を調べてみます。以下のように、-g オプションを付けてコンパイルし、実行ファイルにデバッグ情報を付加します。
$ gcc -g -Wall -o wcount wcount.c
gdb を起動して、addtree( ) の処理が終了した 30 行にブレークポイントを設定して、r コマンドでプログラムをスタートさせます。
$ gdb wcount
....
(gdb) b 30
(gdb) r
....
入力待ちの状態になるので、
now is the time for all good men to come to the aid of their party <Enter>
と入力後に行頭で <Ctrl-d> ( EOF )を入力します。
now is the time for all good men to come to the aid of their party <Enter>
<Ctrl-d>
Breakpoint 1, main () at wcount.c:30
30 treeprint(root);
ブレークポイントで停止するので、上で作成した二分木を参照しながら、以下の手順でノードのメモリ上の配置を p コマンドで調べていきます。
(gdb) p root
$1 = (struct tnode *) 0x5555555596b0
(gdb) p *root
$2 = {word = 0x5555555596e0 "now", count = 1, left = 0x555555559700, right = 0x555555559750}
(gdb) p root->left
$3 = (struct tnode *) 0x555555559700
(gdb) p *(root->left)
$4 = {word = 0x555555559730 "is", count = 1, left = 0x5555555597f0, right = 0x5555555598e0}
(gdb) p root->right
$5 = (struct tnode *) 0x555555559750
(gdb) p *(root->right)
$6 = {word = 0x555555559780 "the", count = 2, left = 0x555555559a20, right = 0x5555555597a0}
(gdb) p root->right->right
$7 = (struct tnode *) 0x5555555597a0
(gdb) p *(root->right->right)
$8 = {word = 0x5555555597d0 "time", count = 1, left = 0x555555559a70, right = 0x555555559930}
(gdb) p root->left->left
$9 = (struct tnode *) 0x5555555597f0
(gdb) p *(root->left->left)
$10 = {word = 0x555555559820 "for", count = 1, left = 0x555555559840, right = 0x555555559890}
(gdb) p root->left->left->left
$11 = (struct tnode *) 0x555555559840
(gdb) p *(root->left->left->left)
$12 = {word = 0x555555559870 "all", count = 1, left = 0x5555555599d0, right = 0x555555559980}
(gdb) p root->left->left->right
$13 = (struct tnode *) 0x555555559890
(gdb) p *(root->left->left->right)
$14 = {word = 0x5555555598c0 "good", count = 1, left = 0x0, right = 0x0}
(gdb) p root->left->right
$15 = (struct tnode *) 0x5555555598e0
(gdb) p *(root->left->right)
$16 = {word = 0x555555559910 "men", count = 1, left = 0x0, right = 0x0}
(gdb) p root->right->right->right
$17 = (struct tnode *) 0x555555559930
(gdb) p *(root->right->right->right)
$18 = {word = 0x555555559960 "to", count = 2, left = 0x0, right = 0x0}
(gdb) p root->left->left->left->right
$19 = (struct tnode *) 0x555555559980
(gdb) p *(root->left->left->left->right)
$20 = {word = 0x5555555599b0 "come", count = 1, left = 0x0, right = 0x0}
(gdb) p root->left->left->left->left
$21 = (struct tnode *) 0x5555555599d0
(gdb) p *(root->left->left->left->left)
$22 = {word = 0x555555559a00 "aid", count = 1, left = 0x0, right = 0x0}
(gdb) p root->right->left
$23 = (struct tnode *) 0x555555559a20
(gdb) p *(root->right->left)
$24 = {word = 0x555555559a50 "of", count = 1, left = 0x0, right = 0x555555559ac0}
(gdb) p root->right->right->left
$25 = (struct tnode *) 0x555555559a70
(gdb) p *(root->right->right->left)
$26 = {word = 0x555555559aa0 "their", count = 1, left = 0x0, right = 0x0}
(gdb) p root->right->left->right
$27 = (struct tnode *) 0x555555559ac0
(gdb) p *(root->right->left->right)
$28 = {word = 0x555555559af0 "party", count = 1, left = 0x0, right = 0x0}
また、p コマンドで struct tnode のサイズを表示させると、32 バイトになります。( word : 8 バイト count : 4 + 4 ( パディング ) バイト left : 8 バイト right : 8 バイト )
(gdb) p sizeof(struct tnode)
$29 = 32
これらを整理すると以下のようになります。
| ノード (word) |
カウント (count) |
ノードを指す ポインタ |
root から ノードへの経路 |
|---|---|---|---|
| now | 1 | 0x5555555596b0 | root |
| is | 1 | 0x555555559700 | root->left |
| the | 2 | 0x555555559750 | root->right |
| time | 1 | 0x5555555597a0 | root->right->right |
| for | 1 | 0x5555555597f0 | root->left->left |
| all | 1 | 0x555555559840 | root->left->left->left |
| good | 1 | 0x555555559890 | root->left->left->right |
| men | 1 | 0x5555555598e0 | root->left->right |
| to | 2 | 0x555555559930 | root->right->right->right |
| come | 1 | 0x555555559980 | root->left->left->left->right |
| aid | 1 | 0x5555555599d0 | root->left->left->left->left |
| of | 1 | 0x555555559a20 | root->right->left |
| their | 1 | 0x555555559a70 | root->right->right->left |
| party | 1 | 0x555555559ac0 | root->right->left->right |
ノードを指すポインタ ( アドレス ) を見ると、0x50 ( 80 ) バイト間隔で並んでいることがわかります。実際のメモリの様子を見るために、x コマンドで、root ( 0x5555555596b0 ) の 16 バイト手前からメモリダンプ ( 42 ( 回繰り返し ) g : 8バイト単位 x : 16進数 ) してみます。
(gdb) x/42gx 0x5555555596a0
0x5555555596a0: 0x0000000000000000 0x0000000000000031 -> size: 0x30(48)バイト, 1: 直前の chunk が使用中
0x5555555596b0: 0x00005555555596e0 0x0000000000000001 -> word, count=1
0x5555555596c0: 0x0000555555559700 0x0000555555559750 -> left, right
0x5555555596d0: 0x0000000000000000 0x0000000000000021 -> size: 0x20(32)バイト, 1: 直前の chunk が使用中
0x5555555596e0: 0x0000000000776f6e 0x0000000000000000 -> "now": 0x6e = 'n', 0x6f = 'o', 0x77 = 'w'
0x5555555596f0: 0x0000000000000000 0x0000000000000031 -> size: 0x30(48)バイト, 1: 直前の chunk が使用中
0x555555559700: 0x0000555555559730 0x0000000000000001 -> word, count=1
0x555555559710: 0x00005555555597f0 0x00005555555598e0 -> left, rihgt
0x555555559720: 0x0000000000000000 0x0000000000000021 -> size: 0x20(32)バイト, 1: 直前の chunk が使用中
0x555555559730: 0x0000000000007369 0x0000000000000000 -> "is": 0x69 = 'i', 0x73 = 's'
0x555555559740: 0x0000000000000000 0x0000000000000031 -> size: 0x30(48)バイト, 1: 直前の chunk が使用中
0x555555559750: 0x0000555555559780 0x0000000000000002 -> word, count=2
0x555555559760: 0x0000555555559a20 0x00005555555597a0 -> left, right
0x555555559770: 0x0000000000000000 0x0000000000000021 -> size: 0x20(32)バイト, 1: 直前の chumk が使用中
0x555555559780: 0x0000000000656874 0x0000000000000000 -> "the": 0x74 = 't', 0x68 = 'h', 0x65 = 'e'
0x555555559790: 0x0000000000000000 0x0000000000000031 -> size: 0x30(48)バイト, 1: 直前の chunk が使用中
0x5555555597a0: 0x00005555555597d0 0x0000000000000001 -> word, count=1
0x5555555597b0: 0x0000555555559a70 0x0000555555559930 -> left, right
0x5555555597c0: 0x0000000000000000 0x0000000000000021 -> size: 0x20(32)バイト, 1: 直前の chumk が使用中
0x5555555597d0: 0x00000000656d6974 0x0000000000000000 -> "time": 0x74 = 't', 0x69 = 'i', 0x6d = 'm', 0x65 = 'e'
0x5555555597e0: 0x0000000000000000 0x0000000000000031 -> size: 0x30(48)バイト, 1: 直前の chunk が使用中
新しくメモリ領域が確保されるのは、下記の二つの場合です。
$\boxed 1$ 40 行のノードの追加時 ( talloc 関数 )
- 68 行の malloc( ) の引数で要求した領域 ( 32 バイト ) にヘッダとして size を先頭に付けたものが、chunk ( メモリの管理単位 ) として確保されます。
- size = 0x30 ( 48 ) バイトは、ヘッダ :16 バイトとユーザ領域 :32 バイトを足したものです。
- size の末尾の 1 ビットは直前の chunk の使用状態を表します。( 1: 使用中 0: 未使用 )
- malloc( ) が返すポインタ ( struct tnode * ) はユーザ領域の先頭を指して、それぞれ 0x5555555596b0, 0x555555559700, 0x555555559750, 0x5555555597a0 になります。
- そして、これらのアドレスには最初のメンバーの char *word が格納されています。
- それらのポインタの指すアドレス ( 0x5555555596e0, 0x555555559730, 0x555555559780, 0x5555555597d0 ) を参照すると、それぞれ "now", "is", "the", "time" の文字列が格納されていることがわかります。
40 p = talloc(); /* 新しいノードを作る */
41 p->word = kr_strdup(w);
42 p->count = 1;
43 p->left = p->right = NULL;
66 struct tnode *talloc(void)
67 {
68 return (struct tnode *) malloc(sizeof(struct tnode));
69 }
$\boxed 2$ 41 行の単語のコピー時 ( kr_strdup 関数 )
- 76 行の malloc( ) の引数で要求した領域 ( 単語の長さ + 1 バイト ただし、16 の倍数でアラインメント ) にヘッダとして size を先頭に付けたものが、上で述べた chunk に続いて追加されています。
- size = 0x20 ( 32 ) バイトは、ヘッダ :16 バイトとユーザ領域 :16 バイトを足したものです。
- size の末尾の 1 ビットは直前の chunk の使用状態を表します。( 1: 使用中 0: 未使用 )
- malloc( ) が返すポインタ ( char * ) はユーザ領域の先頭を指して、それぞれ 0x5555555596e0, 0x555555559730, 0x555555559780, 0x5555555597d0 になっています。
71 /* kr_strdup: s の複製を作る */
72 char *kr_strdup(char *s)
73 {
74 char *p;
75
76 p = (char *) malloc(strlen(s) + 1); /* +1 for '\0' */
77 if (p != NULL)
78 strcpy(p, s);
79 return p;
80 }
2. ノードの挿入 ( addtree 関数 )
K&R の本文に書かれている新たなノード ( 単語 ) を追加するやり方を、紹介されている addtree 関数のコードに沿ってまとめると以下のようになります。
- root ( 根元 ) から出発して、そのノードに格納されている単語と新しい単語を比較する <--1
- 二つが一致したら、count を 1 増やす <--2
- 新しい単語がノードの単語より辞書順で小さいときは、探索は左の子ノードに対して続けられ <--3、そうでなければ右の子ノードが調べられる <--4
- 求める方向に子ノードがない ( NULL ) ときには、新しい単語はそのノードの中にないということであり、そこが単語を置く場所である <--5
- 単語を置いたノードへのポインタが返される <--6
addtree 関数のコード中の該当するところに、説明文中の番号を記入ました。addtree 関数では、NULL のノードに出会うまで addtree が再帰的に呼ばれます。
34 /* addtree: p の位置にあるいはその下に w のノードを加える */
35 struct tnode *addtree(struct tnode *p, char *w)
36 {
37 int cond;
38
39 if (p == NULL) { <--5
40 p = talloc();
41 p->word = kr_strdup(w);
42 p->count = 1;
43 p->left = p->right = NULL;
44 } else if ((cond = strcmp(w, p->word)) == 0) <--1
45 p->count++; <--2
46 else if (cond < 0)
47 p->left = addtree(p->left, w); <--3
48 else
49 p->right = addtree(p->right, w); <--4
50 return p; <--6
51 }
52
それでは、ソースコードに従って addtree 関数の動作を追いかけてみます。
20 /* 単語の頻度カウント */
21 int main(void)
22 {
23 struct tnode *root;
24 char word[MAXWORD];
25
26 root = NULL;
27 while (getword(word, MAXWORD) != EOF)
28 if (isalpha(word[0]))
29 root = addtree(root, word);
30 treeprint(root);
31 return 0;
32 }
33
34 /* addtree: p の位置にあるいはその下に w のノードを加える */
35 struct tnode *addtree(struct tnode *p, char *w)
36 {
37 int cond;
38
39 if (p == NULL) { /* 新しい単語が来た */
40 p = talloc(); /* 新しいノードを作る */
41 p->word = kr_strdup(w);
42 p->count = 1;
43 p->left = p->right = NULL;
44 } else if ((cond = strcmp(w, p->word)) == 0)
45 p->count++; /* 繰り返された言語 */
46 else if (cond < 0) /* より小さければ、左子ノードへ */
47 p->left = addtree(p->left, w);
48 else /* 大きければ、右ノードへ */
49 p->right = addtree(p->right, w);
50 return p;
51 }
52
63 #include <stdlib.h>
64
65 /* talloc: tnode を作る */
66 struct tnode *talloc(void)
67 {
68 return (struct tnode *) malloc(sizeof(struct tnode));
69 }
70
71 /* kr_strdup: s の複製を作る */
72 char *kr_strdup(char *s)
73 {
74 char *p;
75
76 p = (char *) malloc(strlen(s) + 1); /* +1 for '\0' */
77 if (p != NULL)
78 strcpy(p, s);
79 return p;
80 }
81
$\boxed 1$ 最初の単語 "now" の読み込みとノードの作成
26 root = NULL
27 while(getword() != EOF) --> while('n' != EOF) --> while(True), char *word = "now"
28 if(isalpha(word[0])) --> if(isalpha('n')) --> if(True)
29 root = addtree(root, word)
| p = root = NULL, w = word
39 | if(p == NULL) --> if(0x0 == NULL) --> if(True) {
40 | p = talloc()
68 | | return (struct tnode *)malloc(sizeof tnode)
| | --> return malloc(32) --> return 0x~96b0
40 | p = 0x~96b0
41 | p->word = kr_strdup(w), s = w
76 | | p = (char *)malloc(strlen(s)+1) --> p = malloc(4)
| | --> p = 0x~96e0
77 | | if(p != NULL) --> if(0x~96e0 != NULL) --> if(True)
78 | | strcpy(p, s) --> char *p = "now"
79 | | return p --> return 0x~96e0
41 | p->word = 0x~96e0
42 | p->count = 1
43 | p->left = p->right = NULL
| }
50 | return p --> return 0x~96b0
29 root = 0x~96b0
以下のような、二分木ができたことになります。

$\boxed 2$ 2 番目の単語 "is" の読み込みとノード作成
27 while(getword() != EOF) --> while('i' != EOF) --> while(True), char *word = "is"
28 if(isalpha(word[0])) --> if(isalpha('i') --> if(True)
29 root = addtree(root, word)
| p = root = 0x~96b0, w = word
39 | if(p == NULL) --> if(0x~96b0 == NULL) --> if(False)
44 | else if((cond = strcmp(w, p->word)) == 0), (char *)p->word = "now"
| --> else if((cond = strcmp("is", "now")) == 0)
| --> else if((cond = -5) == 0) --> else if(False)
46 | else if(cond < 0) --> else if(-5 < 0) --> else if(True)
47 | p->left = addtree(p->left, w)
| | p = NULL
39 | | if(p == NULL) --> if(0x0 == NULL) --> if(True) {
40 | | p = talloc()
68 | | | return (struct tnode *)malloc(sizeof tnode)
| | | --> return malloc(32) --> return 0x~9700
40 | | p = 0x~9700
41 | | p->word = kr_strdup(w), s = w
76 | | | p = (char *)malloc(strlen(s)+1) --> p = malloc(3)
| | | --> p = 0x~9730
77 | | | if(p != NULL) --> if(0x~9730 != NULL) --> if(True)
78 | | | strcpy(p, s) --> char *p = "is"
79 | | | return p --> return 0x~9730
41 | | p->word = 0x~9730
42 | | p->count = 1
43 | | p->left = p->right = NULL
| | }
50 | | return p --> return 0x~9700
47 | p->left = 0x~9700
50 | return p --> return 0x~96b0
29 root = 0x~96b0
以下のような、二分木ができたことになります。

$\boxed 3$ 3 番目の単語 "the" の読み込みとノード作成
27 while(getword() != EOF) --> while('t' != EOF) --> while(True), char *word = "the"
28 if(isalpha(word[0])) --> if(isalpha('t') --> if(True)
29 root = addtree(root, word)
| p = root = 0x~96b0, w = word
39 | if(p == NULL) --> if(0x~96b0 == NULL) --> if(False)
44 | else if((cond = strcmp(w, p->word)) == 0), (char *)p->word = "now"
| --> else if((cond = strcmp("the", "now")) == 0)
| --> else if((cond = 6) == 0) --> else if(False)
46 | else if(cond < 0) --> else if(6 < 0) --> else if(False)
48 | else
49 | p->right = addtree(p->right, w)
| | p = NULL
39 | | if(p == NULL) --> if(0x0 == NULL) --> if(True) {
40 | | p = talloc()
68 | | | return (struct tnode *)malloc(sizeof tnode)
| | | --> return malloc(32) --> return 0x~9750
40 | | p = 0x~9750
41 | | p->word = kr_strdup(w), s = w
76 | | | p = (char *)malloc(strlen(s)+1) --> p = malloc(4)
| | | --> p = 0x~9780
77 | | | if(p != NULL) --> if(0x~9780 != NULL) --> if(True)
78 | | | strcpy(p, s) --> char *p = "the"
79 | | | return p --> return 0x~9780
41 | | p->word = 0x~9780
42 | | p->count = 1
43 | | p->left = p->right = NULL
| | }
50 | | return p --> return 0x~9750
47 | p->right = 0x~9750
50 | return p --> return 0x~96b0
29 root = 0x~96b0
以下のような、二分木ができたことになります。

$\boxed 4$ 4 番目の単語 "time" の読み込みとノード作成
27 while(getword() != EOF) --> while('t' != EOF) --> while(True), char *word = "time"
28 if(isalpha(word[0])) --> if(isalpha('t') --> if(True)
29 root = addtree(root, word)
| p = root = 0x~96b0, w = word
39 | if(p == NULL) --> if(0x~96b0 == NULL) --> if(False)
44 | else if((cond = strcmp(w, p->word)) == 0), (char *)p->word = "now"
| --> else if((cond = strcmp("time", "now")) == 0)
| --> else if((cond = 1) == 0) --> else if(False)
46 | else if(cond < 0) --> else if(6 < 0) --> else if(False)
48 | else
49 | p->right = addtree(p->right, w)
| | p = 0x~9750
39 | | if(p == NULL) --> if(0x~9750 == NULL) --> if(False)
44 | | else if((cond = strcmp(w, p->word)) == 0), (char *)p->word = "the"
| | --> else if((cond = strcmp("time", "the")) == 0)
| | --> else if((cond = 1) == 0) --> else if(False)
46 | | else if(cond < 0) --> else if(1 < 0) --> else if(False)
48 | | else
49 | | p->right = addtree(p->right, w)
| | | p = NULL
39 | | | if(p == NULL) --> if(0x0 == NULL) --> if(True) {
40 | | | p = talloc()
68 | | | | return (struct tnode *)malloc(sizeof tnode)
| | | | --> return malloc(32) --> return 0x~97a0
40 | | | p = 0x~97a0
41 | | | p->word = kr_strdup(w), s = w
76 | | | | p = (char *)malloc(strlen(s)+1) --> p = malloc(5)
| | | | --> p = 0x~97d0
77 | | | | if(p != NULL) --> if(0x~97d0 != NULL) --> if(True)
78 | | | | strcpy(p, s) --> char *p = "time"
79 | | | | return p --> return 0x~97d0
41 | | | p->word = 0x~97d0
42 | | | p->count = 1
43 | | | p->left = p->right = NULL
| | | }
50 | | | return p --> return 0x~97a0
49 | | p->right = 0x~97a0
49 | p->right = 0x~9750
50 | return p --> return 0x~96b0
29 root = 0x~96b0
以下のような、二分木ができたことになります。

$\boxed 5$ 12 番目の単語の "the" が読み込まれた時の処理
27 while(getword() != EOF) --> while('t' != EOF) --> while(True), char *word = "the"
28 if(isalpha(word[0])) --> if(isalpha('t') --> if(True)
29 root = addtree(root, word)
| p = root = 0x~96b0, w = word
39 | if(p == NULL) --> if(0x~96b0 == NULL) --> if(False)
44 | else if((cond = strcmp(w, p->word)) == 0), (char *)p->word = "now"
| --> else if((cond = strcmp("the", "now")) == 0)
| --> else if((cond = 1) == 0) --> else if(False)
46 | else if(cond < 0) --> else if(6 < 0) --> else if(False)
48 | else
49 | p->right = addtree(p->right, w)
| | p = 0x~9750
39 | | if(p == NULL) --> if(0x~9750 == NULL) --> if(False)
44 | | else if((cond = strcmp(w, p->word)) == 0), (char *)p->word = "the"
| | --> else if((cond = strcmp("the", "the")) == 0)
| | --> else if((cond = 0) == 0) --> else if(True)
45 | | p->count++
49 | p->right = 0x~9750
50 | return p --> return 0x~96b0
29 root = 0x~96b0
45 行で、既に存在する "the" の count が 1 増やされます。
3. 全ノードを辞書順に印字 ( treeprint 関数 )
treeprint(root) として動作を検証してみます。通りがけ順に出力されます。
53 /* treeprint; ノード p を順序だてて印字 */
54 void treeprint(struct tnode *p)
55 {
56 if (p != NULL) {
57 treeprint(p->left);
58 printf("%4d %s\n", p->count, p->word);
59 treeprint(p->right);
60 }
61 }
デバッガの s, n コマンドで、root から作業が始まって辞書順に出現回数と単語が印字される様子を整理してみました。

30 treeprint(root)
p = 0x~96b0 ("now")
56 if(p != NULL) --> if(0x~96b0 != NULL) --> if(True)
{
57 | treeprint(p->left)
| p = 0x~9700 ("is")
56 | if(p != NULL) --> if(0x~9700 != NULL) --> if(True)
| {
57 | | treeprint(p->left)
| | p = 0x~97f0 ("for")
56 | | if(p != NULL) --> if(0x~97f0 != NULL) --> if(True)
| | {
57 | | | treeprint(p->left)
| | | p = 0x~9840 ("all")
56 | | | if(p != NULL) --> if(0x~9840 != NULL) --> if(True)
| | | {
57 | | | | treeprint(p->left)
| | | | p = 0x~99d0 ("aid")
56 | | | | if(p != NULL) --> if( != NULL) --> if(True)
| | | | {
57 | | | | | treeprint(p->left)
| | | | | p = NULL
56 | | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | | | printf("%4d %s\n", p->count, p->word)
| | | | | 1 aid
59 | | | | | treeprint(p-right)
| | | | | p = NULL
56 | | | | | if(p != NULL) --> if(NUll != NULL) --> if(False)
| | | | }
58 | | | | printf("%4d %s\n", p->count, p->word)
| | | | 1 all
59 | | | | treeprint(p->right)
| | | | p = 0x~9980 ("come")
56 | | | | if(p != NULL) --> if(0x~9980 != NULL) --> if(True)
| | | | {
57 | | | | | treeprint(p->left)
| | | | | p = NULL
56 | | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | | | printf("%4d %s\n", p->count, p->word)
| | | | | 1 come
59 | | | | | treeprint(p->right)
| | | | | p = NULL
56 | | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | }
| | | }
58 | | | printf("%4d %s\n", p->count, p->word)
| | | 1 for
59 | | | treeprint(p->right)
| | | p = 0x~9890 ("good")
56 | | | if(p != NULL) --> if(0x~9890 != NULL) --> if(True)
| | | {
57 | | | | treeprint(p->left)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | | printf("%4d %s\n", p->count, p->word)
| | | | 1 good
59 | | | | treeprint(p->right)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | }
| | }
58 | | printf("%4d %s\n", p->count, p->word)
| | 1 is
59 | | treeprint(p->right)
| | p = 0x~98e0 ("men")
56 | | if(p != NULL) --> if(0x~98e0 != NULL) --> if(True)
| | {
57 | | | treeprint(p->left)
| | | p = NULL
56 | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | printf("%4d %s\n", p->count, p->word)
| | | 1 men
59 | | | treeprint(p->right)
| | | p = NULL
56 | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | }
| }
58 | printf("%4d %s\n", p->count, p->word)
| 1 now
59 | treeprint(p->right)
| p = 0x~9750 ("the")
56 | if(p != NULL) --> if(0x~9750 != NULL) --> if(True)
| {
57 | | treeprint(p->left)
| | p = 0x~9a20 ("of")
56 | | if(p != NULL) --> if(0x~9a20 != NULL) --> if(True)
| | {
57 | | | treeprint(p->left)
| | | p = NULL
56 | | | if(p != NULL) -->if(NULL !- NULL) --> if(False)
58 | | | printf("%4d %s\n", p->count, p->word)
| | | 1 of
59 | | | treeprint(p->right)
| | | p = 0x~9ac0 ("party")
56 | | | if(p != NULL) -->if(0x~9ac0 != NULL) --> if(True)
| | | {
57 | | | | treeprint(p->left)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | | printf("%4d %s\n", p->count, p->word)
| | | | 1 party
59 | | | | treeprint(p->right)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | }
| | }
58 | | printf("%4d %s\n", p->count, p->word)
| | 2 the
59 | | treeprint(p->right)
| | p = 0x~97a0 ("time")
56 | | if(p != NULL) --> if(0x~97a0 != NULL) --> if(True)
| | {
57 | | | treeprint(p-left)
| | | p = 0x~9a70 ("their")
56 | | | if(p != NULL) --> if(0x~9a70 != NULL) --> if(True)
| | | {
57 | | | | treeprint(p->left)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | | printf("%4d %s\n", p->count, p->word)
| | | | 1 their
59 | | | | treeprint(p-right)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | }
58 | | | printf("%4d %s\n", p->count, p->word)
| | | 1 time
59 | | | treeprint(p-right)
| | | p=0x~9930 ("to")
56 | | | if(p != NULL) --> if(0x~9930 != NULL) --> if(True)
| | | {
57 | | | | treeprint(p-left)
| | | | p = NULL
56 | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
58 | | | | printf("%4d %s\n", p->count, p->word)
| | | | 2 to
| | | | treeprint(p-right)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | }
| | }
| }
}
4. ソースコード
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
struct tnode { /* 木のノード */
char *word; /* テキストへのポインタ */
int count; /* 出現回数 */
struct tnode *left; /* 左の子ノード */
struct tnode *right; /* 右の子ノード */
};
struct tnode *addtree(struct tnode *, char *);
void treeprint(struct tnode *);
struct tnode *talloc(void);
char *kr_strdup(char *);
int getword(char *, int);
/* 単語の頻度カウント */
int main(void)
{
struct tnode *root;
char word[MAXWORD] = {}; /* '\0' で初期化 */
root = NULL;
while (getword(word, MAXWORD) != EOF)
if (isalpha(word[0]))
root = addtree(root, word);
treeprint(root);
return 0;
}
/* addtree: p の位置にあるいはその下に w のノードを加える */
struct tnode *addtree(struct tnode *p, char *w)
{
int cond;
if (p == NULL) { /* 新しい単語が来た */
p = talloc(); /* 新しいノードを作る */
p->word = kr_strdup(w);
p->count = 1;
p->left = p->right = NULL;
} else if ((cond = strcmp(w, p->word)) == 0)
p->count++; /* 繰り返された単語 */
else if (cond < 0) /* より小さければ、左子ノードへ */
p->left = addtree(p->left, w);
else /* 大きければ、右子ノードへ */
p->right = addtree(p->right, w);
return p;
}
/* treeprint; ノード p を順序だてて印字 */
void treeprint(struct tnode *p)
{
if (p != NULL) {
treeprint(p->left);
printf("%4d %s\n", p->count, p->word);
treeprint(p->right);
}
}
#include <stdlib.h>
/* talloc: tnode を作る */
struct tnode *talloc(void)
{
return (struct tnode *) malloc(sizeof(struct tnode));
}
/* kr_strdup: s の複製を作る */
char *kr_strdup(char *s)
{
char *p;
p = (char *) malloc(strlen(s) + 1); /* +1 for '\0' */
if (p != NULL)
strcpy(p, s);
return p;
}
/* getword: 入力から次の語、または文字を求める */
int getword(char *word, int lim)
{
int c, getch(void);
void ungetch(int);
char *w = word;
while (isspace(c = getch()))
;
if (c != EOF)
*w++ = c;
if (!isalpha(c)) {
*w = '\0';
return c;
}
for ( ; --lim > 0; w++)
if (!isalnum(*w = getch())) {
ungetch(*w);
break;
}
*w = '\0';
return word[0];
}
#define BUFSIZE 100
char buf[BUFSIZE]; /* ungetch 用のバッファ */
int bufp = 0; /* buf 中の次の空き位置 */
int getch(void) /* (押し戻された可能性もある) 1 文字を取って来る */
{
return (bufp > 0) ? buf[--bufp] : getchar();
}
void ungetch(int c) /* 文字を入力に戻す */
{
if (bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}
5. メモリ領域の解放 ( free 関数 )
K&R のプログラムでは確保したメモリ領域の解放をしていませんが、「プログラミング言語Cを読む」小林健一郎著 講談社 では、free で解放する関数が紹介されていました。
void treefree(struct tonode *p)
{
if (p != NULL) {
treefree(p->left);
treefree(p->right);
free(p->word);
free(p);
}
}
これをソースコードの最後に追加し、以下の 3 箇所を変更します。
- 63 行の
#include <stdlib.h>を 4 行に移動します -
void treefree(struct tnode *)という関数のプロトタイプを追加します - main 関数の
return 0;の前にtreefree(root);を置きます
treefree(root) の動作を検証してみますが、treeprint(root) と似たような動作になります。帰りがけ順に探索されます。
treefree(root)
p = root = 0x~96b0 ("now")
if(p != NULL) --> if(0x~96b0 != NULL) --> if(True)
{
| treefree(p->left)
| p = 0x~9700 ("is")
| if(p != NULL) --> if(0x~9700 != NULL) --> if(True)
| {
| | treefree(p->left)
| | p = 0x~97f0 ("for")
| | if(p != NULL) --> if(0x~97f0 != NULL) --> if(True)
| | {
| | | treefree(p->left)
| | | p = 0x~9840 ("all")
| | | if(p != NULL) --> if(0x~9840 != NULL) --> if(Ture)
| | | {
| | | | treefree(p->left)
| | | | p = 0x~99d0 ("aid")
| | | | if(p != NULL) --> if(0x~99d0 != NULL) --> if(True)
| | | | {
| | | | | treefree(p->left)
| | | | | p = NULL
| | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | | treefree(p->right)
| | | | | p = NULL
| | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | | free(p->word) .....[1]
| | | | | free(p) .....[2]
| | | | }
| | | | treefree(p->right)
| | | | p = 0x~9980 ("come")
| | | | if(p != NULL) --> if(0x~9980 != NULL) --> if(True)
| | | | {
| | | | | treefree(p->left)
| | | | | p = NULL
| | | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | | treefree(p->right)
| | | | | p = NULL
| | | | | if(P != NULL) --> if(NULL != NULL) --> if(False)
| | | | | free(p->word)
| | | | | free(p)
| | | | }
| | | | free(p->word)
| | | | free(p)
| | | }
| | | treefree(p->right)
| | | p = 0x~9890 ("good")
| | | if(p != NULL) --> if(0x~9890 != NULL) --> if(True),
| | | {
| | | | treefree(p->left)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | treefree(p->right)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(Fqlse)
| | | | free(p->word)
| | | | free(p)
| | | }
| | | free(p->word)
| | | free(p)
| | }
| | treefree(p->right)
| | p = 0x~98e0 ("men")
| | if(p != NULL) --> if(0x~98e0 != NULL) --> if(True)
| | {
| | | treefree(p->lef t)
| | | p = NULL
| | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | treefree(p->right)
| | | p = NULL
| | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | free(p->word)
| | | free(p)
| | }
| | free(p->word)
| | free(p)
| }
| treefree(p->right)
| p = 0x~9750 ("the")
| if(p != NULL) --> if(0x~9750 != NULL) --> if(True)
| {
| | treefree(p->left)
| | p= 0x~9a20 ("of")
| | if(p != NULL) --> if(0x~9a20 != NULL) --> if(True)
| | {
| | | treefree(p->left)
| | | p = NULL
| | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | treerfree(p->right)
| | | p = 0x~9ac0 ("party")
| | | if(p != NULL) --> if(0x~9ac0 != NULL) --> if(True)
| | | {
| | | | treefree(p->left)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | treefree(p->right)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | free(p->word)
| | | | free(p)
| | | }
| | | free(p->word)
| | | free(p)
| | }
| | treefree(p->riight)
| | p = 0x~97a0 ("time")
| | if(p != NULL) --> if(0x~97a0 != NULL) --> if(True)
| | {
| | | treefree(p->left)
| | | p = 0x~9a70 ("their")
| | | if(p != NULL) --> if(0x~9a70 != NULL) --> if(True)
| | | {
| | | | treefree(p->left)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | trefree(p->right)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False),
| | | | free(p->word)
| | | | free(p)
| | | }
| | | treefree(p->right)
| | | p = 0x~9930 ("to")
| | | if(p != NULL) --> if(0x~9930 != NULL) --> if(True),
| | | {
| | | | treefree(p->left)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | treefree(p->right)
| | | | p = NULL
| | | | if(p != NULL) --> if(NULL != NULL) --> if(False)
| | | | free(p->word)
| | | | free(p)
| | | }
| | | free(p->word)
| | | free(p)
| | }
| | free(p->word)
| | free(p)
| }
| free(p->word)
| free(p)
}
ここで、x コマンドで、[1] と [2] の free をする前の 0x~99c0 から 12 ワード分をメモリダンプします。
(gdb) x/12gx 0x5555555599c0
0x5555555599c0: 0x0000000000000000 0x0000000000000031
0x5555555599d0: 0x0000555555559a00 0x0000000000000001 -> p->word, p->count
0x5555555599e0: 0x0000000000000000 0x0000000000000000
0x5555555599f0: 0x0000000000000000 0x0000000000000021
0x555555559a00: 0x0000000000646961 0x0000000000000000 -> "aid" : 0x61 = 'a', 0x69='i', 0x64='d'
0x555555559a10: 0x0000000000000000 0x0000000000000031
[1] の free(p->word) 後の 0x~99c0 から 12 ワード分メモリダンプしてみます。p->word が指す 0x~9a00 の内容が書き換わってメモリが解放されているようです。
(gdb) x/12gx 0x5555555599c0
0x5555555599c0: 0x0000000000000000 0x0000000000000031
0x5555555599d0: 0x0000555555559a00 0x0000000000000001
0x5555555599e0: 0x0000000000000000 0x0000000000000000
0x5555555599f0: 0x0000000000000000 0x0000000000000021
0x555555559a00: 0x0000000555555559 0x25233b458cf39d9b -> p->word(0x~9a00) の内容が書き換えられた
0x555555559a10: 0x0000000000000000 0x0000000000000031
free(p) 後の 0x~99c0 から 12 ワード分メモリダンプしてみます。p が指す 0x~99d0 の内容が書き換わってメモリが解放されているようです。
(gdb) x/12gx 0x5555555599c0
0x5555555599c0: 0x0000000000000000 0x0000000000000031
0x5555555599d0: 0x0000000555555559 0x25233b458cf39d9b -> p(0x~99d0) の内容が書き換えられた
0x5555555599e0: 0x0000000000000000 0x0000000000000000
0x5555555599f0: 0x0000000000000000 0x0000000000000021
0x555555559a00: 0x0000000555555559 0x25233b458cf39d9b
0x555555559a10: 0x0000000000000000 0x0000000000000031
メモリが解放されているのに、size の末尾の 1 ビットがクリア ( 未使用 ) されていないのが不思議でしたが、こちらの説明によれば malloc で確保された領域がキャッシュ上に置かれる場合には、あえて使用中のままにしているようです。
malloc/free のソースコードは、高速化、メモリの断片化防止、マルチスレッド対応のために約 6000 行もあるそうですから深入りしません。