概要
グラフィックボード搭載のWindowsPCに Stable Diffusion web UI(AUTOMATIC) を導入する手順とその他をざっくり書きます。
※ 細かい流れでいうと、WindowsOS上のWSL2上に用意したOracleLinux8の中にpythonで仮想環境を用意して、PC環境に合わせたPyTorch(GPU版)、CUDAをぶち込んで、Stable Diffusionをgit cloneしてくるイメージです。
環境





導入
WSL2上のOS内に仮想環境を作る
以下を参照してやってみる
![]() 仮想環境は /path じゃなくて一般ユーザーディレクトリ内の
仮想環境は /path じゃなくて一般ユーザーディレクトリ内の ./path に作る($HOME/path)
# ホームディレクトリに path ディレクトリを作成 & 移動
cd $HOME
mkdir path && cd path; pwd
# 仮想環境(my_venv)を作成
python3 -m venv my_venv
# 初期ファイルが表示されればOK
ls my_venv
# bin include lib lib64 pyvenv.cfg
ホームディレクトリから仮想環境を起動しておく
$ source $HOME/path/my_venv/bin/activate
(my_venv) $
(my_venv) $ deactivate
$
PyTorch(GPU版)を導入(WSL2OS内で Linux版を入れる)
※GPU版なので、グラフィックボード搭載のPCでないと使えない
↓まずここでローカル環境を選択してコマンドページへ遷移する
https://pytorch.org/get-started/locally/
↓今回の場合の遷移先
※ここは若干コマンドが怪しい。
root(sudo)でコマンドは実行しないように。導入作業が進まなくなる。
(my_venv) $
### ※仮想環境(my_venv)上で実施
# CUDA 11.6
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116
path/my_venv/bin/python3 -m pip install --upgrade pip
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
CUDAを導入(WSL2OS内で Linuxコマンドで入れる)
※ 前項でインストールした参照バージョン(CUDA 11.6)に合わせたコマンドを実施する
sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
sudo dnf clean all
sudo dnf -y module install nvidia-driver:latest-dkms
sudo dnf -y install cuda
Gitを導入
sudo dnf install git
AUTOMATIC1111版web UIのインストール
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cp -r stable-diffusion-webui/ my_venv/
cd my_venv/stable-diffusion-webui
AUTOMATIC1111版web UIの実行
### ※仮想環境(my_venv)上で実施
python3 launch.py
モデルファイルがない場合、初回起動時はモデルファイルのダウンロード処理が入る。
ダウンロードが成功すると勝手に起動する。
※2回目からはダウンロードなしでそのまま起動する
Downloading (…)olve/main/vocab.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 961k/961k [00:01<00:00, 956kB/s]
Downloading (…)olve/main/merges.txt: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 525k/525k [00:00<00:00, 622kB/s]
Downloading (…)cial_tokens_map.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 389/389 [00:00<00:00, 336kB/s]
Downloading (…)okenizer_config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 905/905 [00:00<00:00, 651kB/s]
Downloading (…)lve/main/config.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.52k/4.52k [00:00<00:00, 1.82MB/s]
Applying cross attention optimization (Doggettx).
Textual inversion embeddings loaded(0):
Model loaded in 16.9s (calculate hash: 2.9s, create model: 9.3s, apply weights to model: 1.5s, apply half(): 0.4s, load VAE: 2.0s, move model to device: 0.7s).
Running on local URL: http://127.0.0.1:7860
表示されたローカルIPにアクセスするとWebUIが起動しているはず。
http://127.0.0.1:7860
※ UI表示されるまで少し時間がかかるので、下記のように表示されない場合は少し待ってからブラウザを再読み込みする
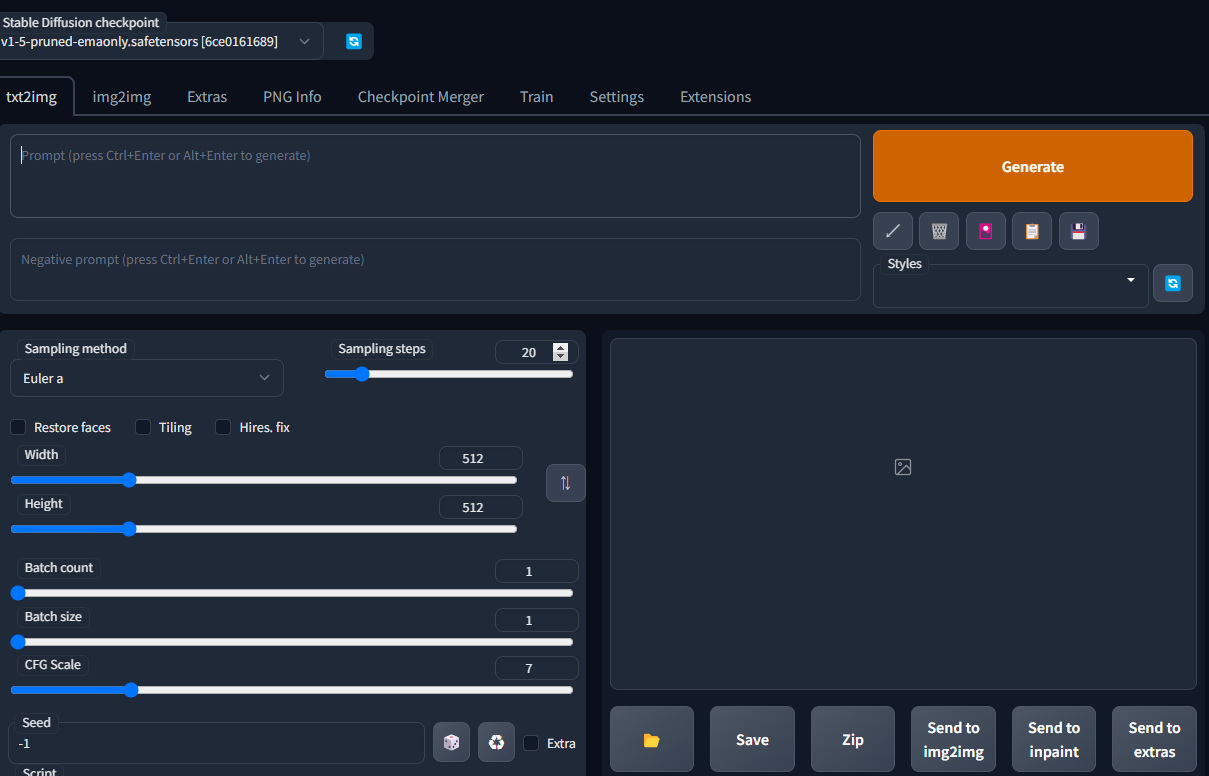
txt2Img で Prompt に a cat を入力して Generate したもの
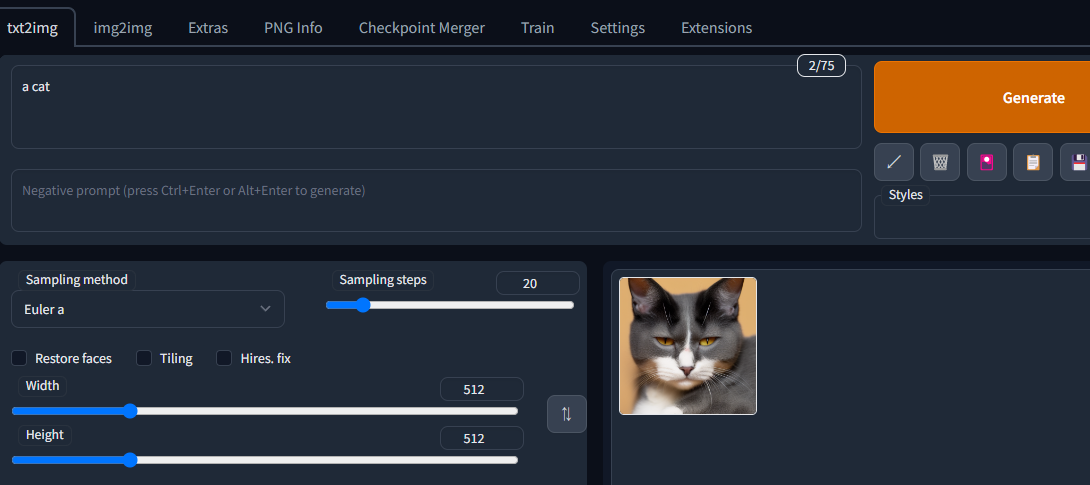
Saveをクリックして画像を保存。
my_venv/stable-diffusion-webui/log/images の中に保存されてるはず
※生成した画像はSaveを押さなくても履歴としてすべて保存されてます。
終了時はコンソール側で Ctrl + c
もう一度起動する場合は
python3 launch.py
コンソールに再ログインした際は
source my_venv/bin/activate
cd path/my_venv/stable-diffusion-webui
python3 launch.py
で起動できる。
別のモデルファイルを配置する
ダウンロードと配置
Counterfeit-V2.5.safetensorsをダウンロードする
Counterfeit-V2.5.vae.ptもダウンロードしておく(必須ではない)
ダウンロードしたファイルはそれぞれ以下のディレクトリ配下に置く
~.safetensorsファイルは:
my_venv/stable-diffusion-webui/models/Stable-diffusion/
~.vae.ptファイルは:
my_venv/stable-diffusion-webui/models/VAE/
起動中の場合は
スクリプトを再起動してください
※ コンソール側で Ctrl + c で終了してから再度python3 launch.py
モデル入れ替え時にエラーが出る場合でも
何回かスクリプト再起動とともにモデル変更を繰り返すと最終的に変更が成功する場合が多いです。
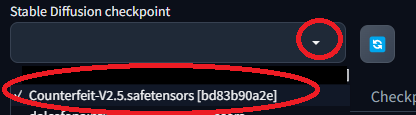
モデルの選択
WebUI上で、別のチェックポイント(モデル)が選択できるようになっているので、そこで導入したモデルを選択すればよい。
実行テスト
txt2Img a cat → Generate
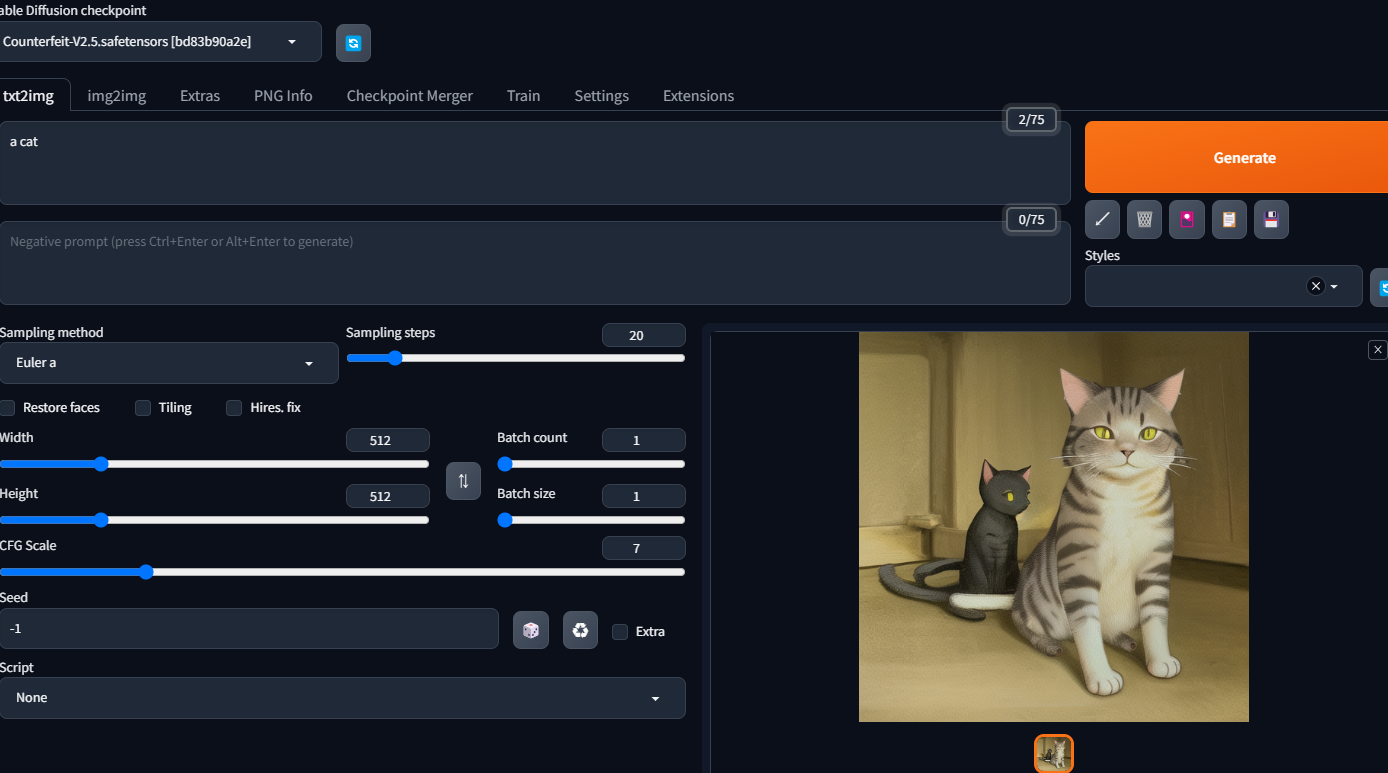
あー、まぁこんなもんかな(2匹。。)
あとは基本としてはPromptとNegative promptの文言を追加していくなり、Sampling method や Sampling steps や CFG Scale をいじるなりで完成度を上げていきましょう。(ほかにも設定要素は無数にあるので、がんばって調べてください)
あと、モデルによって "イラスト風が得意" 、 "実写風が得意" とかあるので、いろんなモデルで試してみましょう
VAEファイルについて
生成画像の完成度を向上してくれるファイルらしいです。
いい感じになる調整を自動でやってくれるらしい。
※画像生成処理に必須ではないので、あった方がいいけど無くてもよい
と思ったが、精度の高い画像を生成するならVAEは必須らしいので
↑上記サイトで紹介されている汎用VAEを使ってみることをお勧めします
vae-ft-mse-840000-ema-pruned.safetensorsファイルを
ダウンロード後に
my_venv/stable-diffusion-webui/models/VAE/に配置する
Settings-stable diffusion-SD VAEから設定

右側の青色の更新マークを押してからvae-ft-mse-840000-ema-pruned.safetensorsを選択してApply Settingsで設定を反映する


2回目以降の起動
source my_venv/bin/activate
cd path/my_venv/stable-diffusion-webui
python3 launch.py --xformers
xformersオプションで起動すると
VRAMの使用効率を改善してくれて、画像の生成速度も速くなるらしいのでおすすめ
※ そのかわり、パラメータ値を合わせてまったく同じ画像を出力させる用途には向いてないらしい。
画像の生成操作(Generate)
Generateボタンを押すよりCtrl + Enterで実行した方が早くて楽です。これ豆な
アップデート
Stable Diffusion本体のアップデート
cd $HOME/path/my_venv/stable-diffusion-webui/
git pull
torchのアップデート
※必要に応じて、バージョン上げないと動かなくなる場合あり
python -m pip install torch==2.8.0 torchvision==0.23.0
エラー時、不具合時
※動かなくなったりした場合は消して入れ直しが無難。(自分でも体験済み![]() )
)
※削除する前に生成した画像などはバックアップしておきましょう
cd $HOME/path/
rm -rf my_venv/stable-diffusion-webui/
# 以前の stable-diffusion-webui が存在する場合はそれも先に消しておく
# rm -rf stable-diffusion-webui
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cp -r stable-diffusion-webui/ my_venv/
cd my_venv/stable-diffusion-webui
※初回ダウンロードおよび起動後に画像生成して問題なく動くようであれば
任意のモデルを入れなおす(以下のディレクトリ内に配置)
my_venv/stable-diffusion-webui/models/Stable-diffusion
VAEはこちらに配置
my_venv/stable-diffusion-webui/models/VAE
ソフト、ツールの更新(再インストール)(torch, xformers)
適切な最新バージョンのソフトを再インストールしてくれる
![]() ※pipの依存性問題等でうまく起動しなくなる可能性あり
※pipの依存性問題等でうまく起動しなくなる可能性あり
source my_venv/bin/activate
cd path/my_venv/stable-diffusion-webui
python launch.py --xformers --reinstall-torch --reinstall-xformers
pip install --upgrade pip
画像の出力先例
$HOME/path/my_venv/stable-diffusion-webui/log/images
$HOME/path/my_venv/stable-diffusion-webui/outputs/
# ユーザ名 部分は自分のホームディレクトリユーザ名に置き換えてください
\\wsl.localhost\OracleLinux_8_6\home\ユーザ名\path\my_venv\stable-diffusion-webui\log\images
\\wsl.localhost\OracleLinux_8_6\home\ユーザ名\path\my_venv\stable-diffusion-webui\outputs\
※ OracleLinux は 8.6 から 8.7 にアップデートした場合はディレクトリ名が 8.6 のまま...?![]()
他モデルとか
絵画アート系をやりたい人はdalcefoPaintingシリーズのモデルがおすすめ
リアル系はchilloutmixがおすすめ
モデル参照サイト
他参考