こんちは。今日はポインタ使うのかい、どうなんだいという話をしちゃいます。お母さんには内緒だゾ。
本記事では、Python Tutor (https://pythontutor.com/) を使用して生成されたメモリ状態の可視化画像を使用しています。これらの画像はCreative Commons CC BYライセンスの下で使用されています。Python Tutorは、コードの実行過程とメモリの状態を視覚化するための優れたツールです。
また、この記事は@fujitanozomuさんに、コメント欄で指摘していただき全体的に書き直しました。fujitaさんご指摘ありがとうございました🙏
多分マシな内容になっているはず...1
Goのメソッド
Go では名前付きの型にメソッドを定義できます。このときメソッドが定義される型をレシーバと呼んだりします。
レシーバはポインタ型にすることもできます。
type Person struct {
Name string
Age int
}
// ポインタレシーバを使用したメソッド
func (p *Person) HaveBirthdayUsingPointerMethod() {
p.Age++
}
ポインタレシーバと対比して、こっちを値レシーバと呼びます
// 値レシーバを使用したメソッド
func (p Person) HaveBirthdayUsingValueMethod() {
p.Age++
}
へー...で、なにが違いますのん?
お本を読みましょうね。
とりあえず、100 Go Mistakes 見とけばええねん。
要約
値レシーバーとポインタレシーバーのどちらを使用するかは、どの型なのか、変化させる必要があるかどうか、コピーできないフィールドが含まれているかどうか、オブジェクトはどれくらい大きいのか、などの要素に基づいて決定する必要があります。分からない場合は、ポインタレシーバを使用してください。
なるほどな。ぼく、よく分からんからポインタレシーバ使っとくわ!(完)
分からない場合ポインタレシーバーを使うのはなぜ?
とりあえずさっきのコードを使ってみますか。
package main
import (
"fmt"
)
type Person struct {
Name string
Age int
}
// ポインタレシーバを使用したメソッド
func (p *Person) HaveBirthdayUsingPointerMethod() {
p.Age++
}
// 値レシーバを使用したメソッド
func (p Person) HaveBirthdayUsingValueMethod() {
p.Age++
}
func NewPerson(name string, age int) *Person {
p := &Person{
Name: name,
Age: age,
}
return p
}
func main() {
ichiro := Person{"一郎", 0}
fmt.Printf("Before Birthday: %+v\n", ichiro)
ichiro.HaveBirthdayUsingPointerMethod()
fmt.Printf("After Birthday: %+v\n", ichiro)
jiro := Person{"二郎", 0}
fmt.Printf("Before Birthday: %+v\n", jiro)
jiro.HaveBirthdayUsingValueMethod()
fmt.Printf("After Birthday%+v\n", jiro)
saburo := NewPerson("三郎", 0)
fmt.Printf("Before Birthday: %+v\n", saburo)
saburo.HaveBirthdayUsingPointerMethod()
fmt.Printf("After Birthday%+v\n", saburo)
}
Before Birthday: {Name:一郎 Age:0}
After Birthday: {Name:一郎 Age:1}
Before Birthday: {Name:二郎 Age:0}
After Birthday{Name:二郎 Age:0}
Before Birthday: &{Name:三郎 Age:0}
After Birthday&{Name:三郎 Age:1}
ちょっと見た感じ、ポインタメソッドを使えばインスタンス化した構造体の状態を変えることができるみたいですね。なので、構造体の状態を変えたいときはポインタメソッド使っとけばええねんってことやね!(完)
なんで状態を変えたい時はポインタメソッド使うのか?
それはねメモリを見ればわかるよ。
冒頭でも紹介していますが、Python Tutorは、コードの実行過程とメモリの状態を視覚化するための優れたツールです。これを使ってメモリを眺めて、「なんで状態を変えたい時はポインタを使うのか?」を探ってみましょう。
Python Tutor では Go ではなくて C を使うことができるので、とりあえず以下にC言語で書かれた同様のコードを使ってメモリについて考えてみたいと思います。
typedef struct {
char* Name;
int Age;
} Person;
void HaveBirthday(Person* p) {
p->Age++;
}
int main(void)
{
Person p = {.Name = "一郎", .Age = 1};
HaveBirthday(&p);
return 0;
}
動かしてみる
早速、Python Tutorで動かしてみます。以下が変数pを初期化したところまで実行したメモリの状態です。
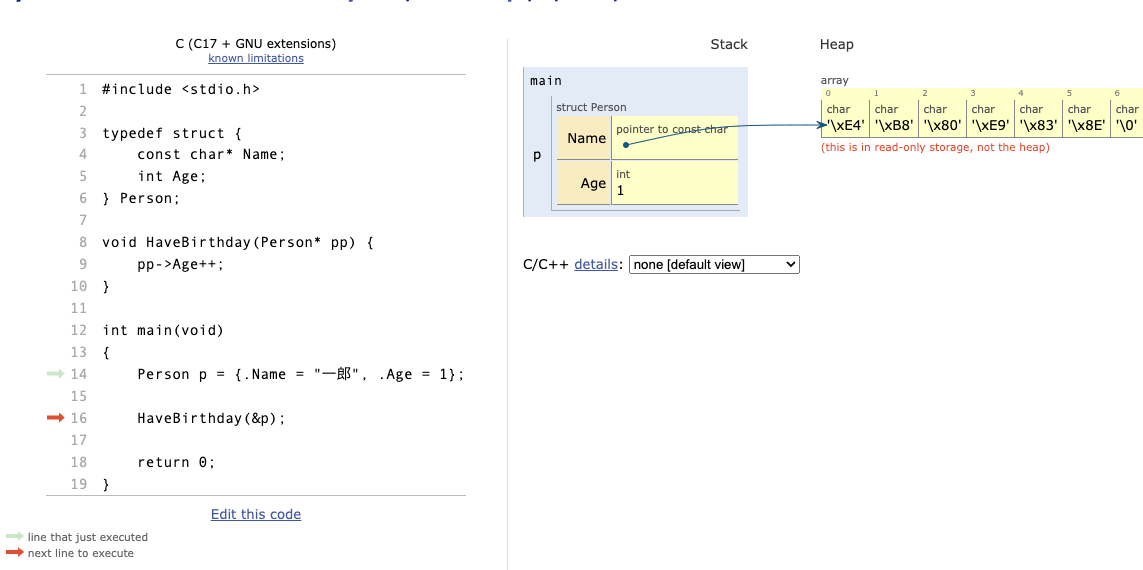
pのメンバ変数のNameからビヨーンと矢印が伸びているね。文字列は遠い国にあるということなんですね (this is read only storage, not the heap)。2
Next > ボタンを押して HaveBirthday(&p) が実行されたメモリを見てみましょう。
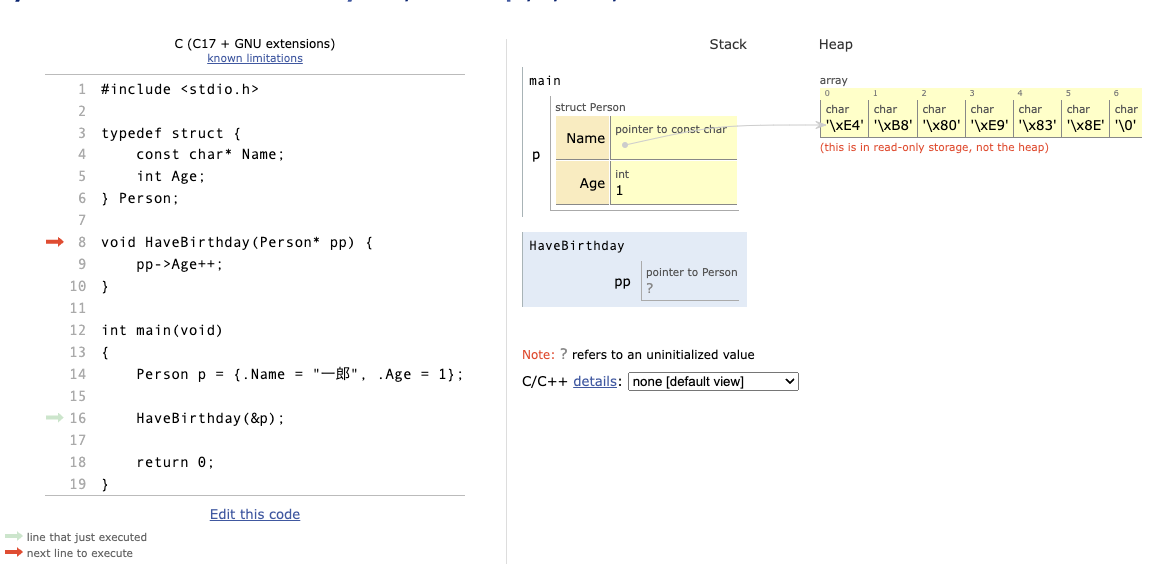
はい注目!!!
HaveBirthday(&p) が呼ばれると、右側の Stack にHaveBirthdayというものが追加されています。これが関数呼び出しです。プログラムでは関数が呼ばれるたびにその関数のスコープが Stack というメモリ領域に積まれていくのです。
もう一点注目すべきなのが、HaveBirthdayの中にppという変数のメモリ領域があることです、pointer to PersonとあるようにこれはPerson型のポインタ変数です。
もっかいNext >
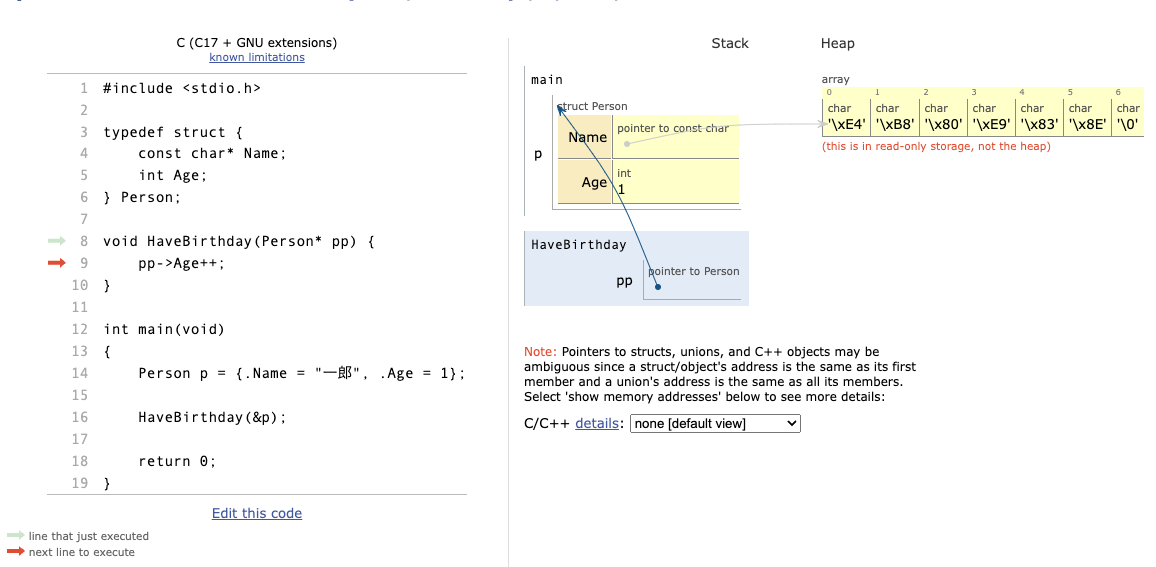
HaveBirthdayに渡した変数pのアドレスがppに入りましたね!
こりずにNext >

ppを使うことで、HaveBirthday関数の中から、mainのp構造体のAgeを操作することができましたね!
HaveBirthdayの呼び出しが終わると、Havebirthdayは Stack から pop されます。
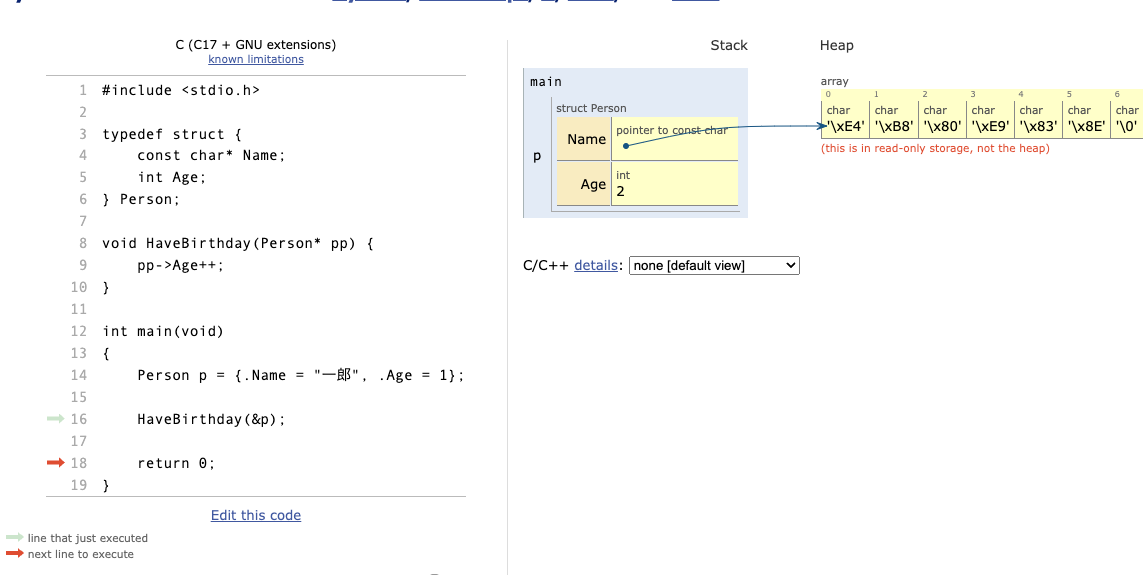
こんなふうにして、構造体の状態を変えることができるんですね。では、なぜポインタを使わないと関数の中から状態を変えられないかも眺めてみよっ!❤️
使うのは以下のコードです。
typedef struct {
char* Name;
int Age;
} Person;
void HaveBirthday(Person pc) { // person の copy だからpcでいいっしょ
pc->Age++;
}
int main(void)
{
Person p = {.Name = "一郎", .Age = 1};
HaveBirthday(&p);
return 0;
}
HaveBirthdayの引数をPerson型のポインタ変数ではなくて、ただのPerson型の変数にしただけですね
コピーはこう見える
HaveBirthdayが呼ばれる時のメモリを見てみましょう。
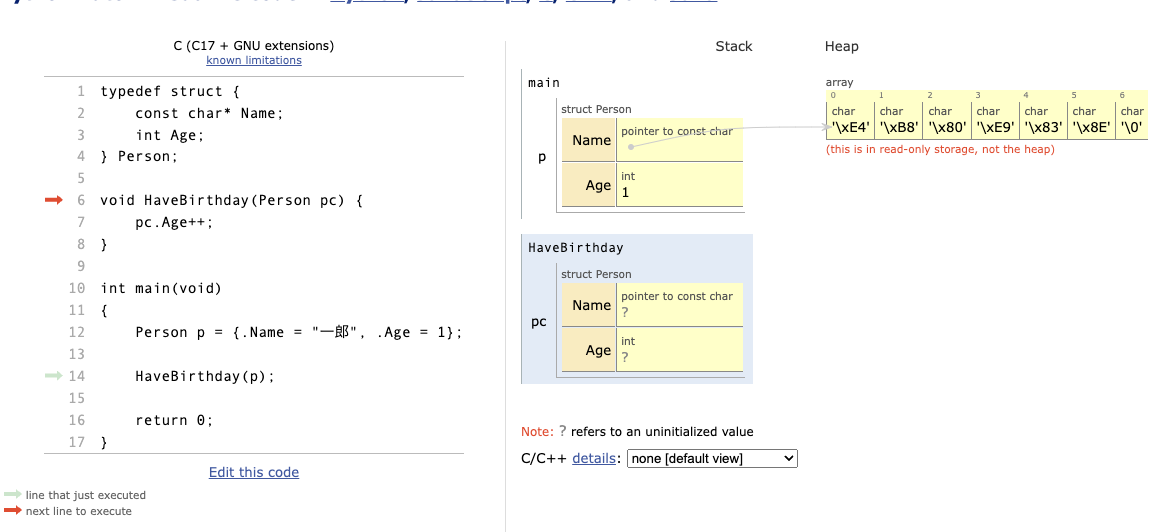
はい、さっきと違うのは、HaveBirthdayの中に用意された領域が、ポインタ変数ではなくPerson型の変数になっているというところです。mainからpが渡されるとどうなるでしょうか。
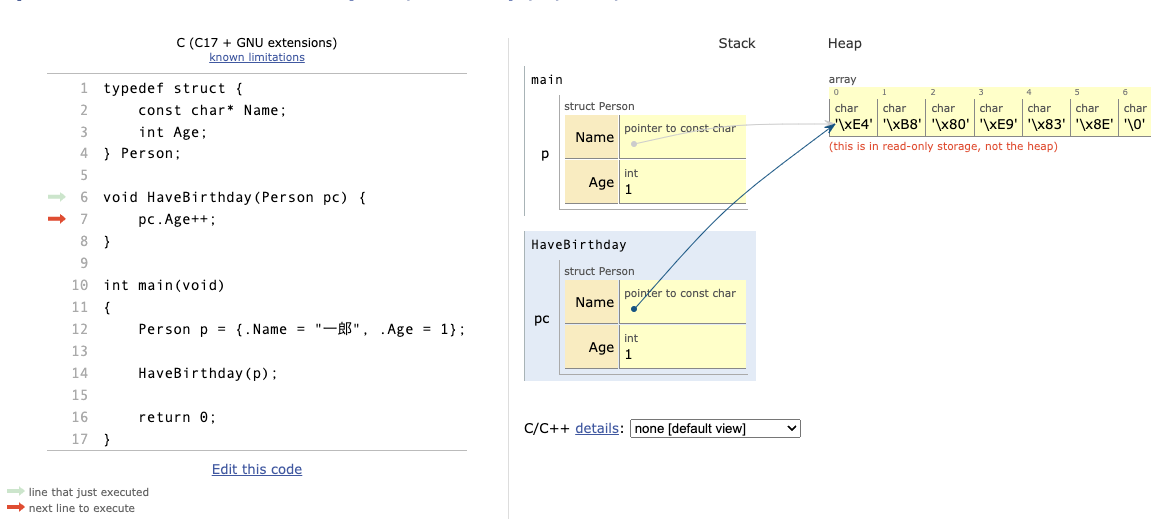
注目すべきは、HaveBirthdayの中の変数pcが、mainの中の変数pのコピーになっているといことです。では、Next >
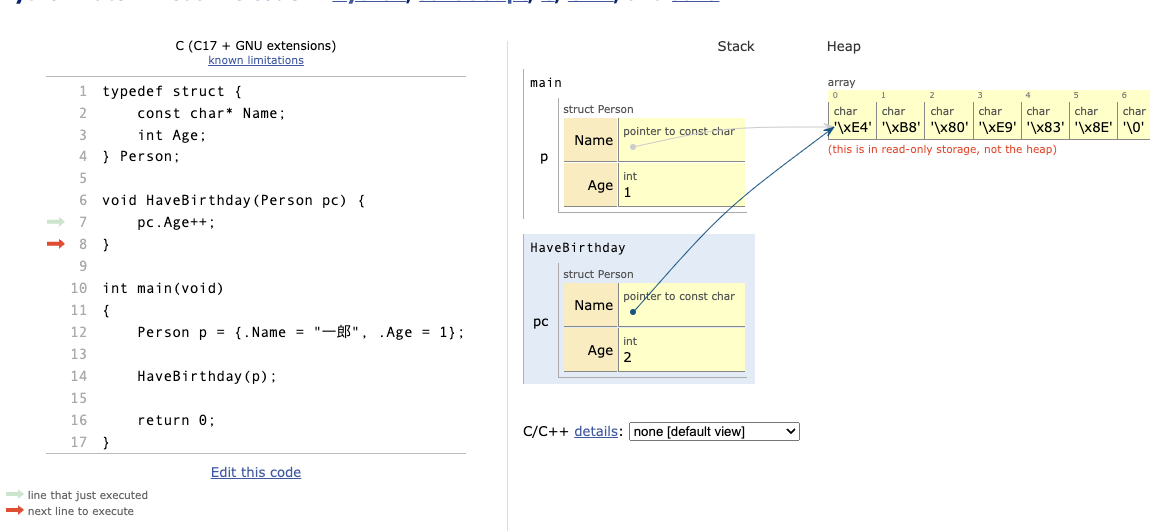
はい、pc.Age++がインクリメントするのは、コピーのpcのAgeです。従ってmainのp変数のAgeは変わりません。これが、元のインスタンスの状態を変えるためにポインタが必要になる理由です。
一般に、関数を呼び出す際に、メモリ上のオブジェクトのアドレスを関数内のポインタ変数に代入して渡すことを参照渡し、オブジェクトの値を関数内の変数に代入して渡すことを値渡しと呼びます。
つまり、ポインタメソッドが構造体の状態を変えるために使われるのは、関数呼び出しを用いてインスタンスの状態を変えるには、参照渡しする必要があるからです。
住所がわかればどこでも行ける
ポインタがあれば、関数からそれをたどって、たどり着いた先のメモリの値を変更できたわけですが、ポインタの嬉しいところは住所(メモリアドレス)がわかれば、それがどこであってもそこまで辿り着けるというところです。
次に以下のようなコードを Python Tutor で動かしてみましょう。
#include <stdlib.h>
typedef struct {
const char* Name;
int Age;
} Person;
void HaveBirthday(Person* p) {
p->Age++;
}
int main(void)
{
// mallocを使用してPerson構造体のためのメモリを動的に割り当てる
Person* p = (Person*)malloc(sizeof(Person));
if (p == NULL) {
return 1;
}
p->Name = "一郎";
p->Age = 1;
HaveBirthday(p);
free(p);
return 0;
}
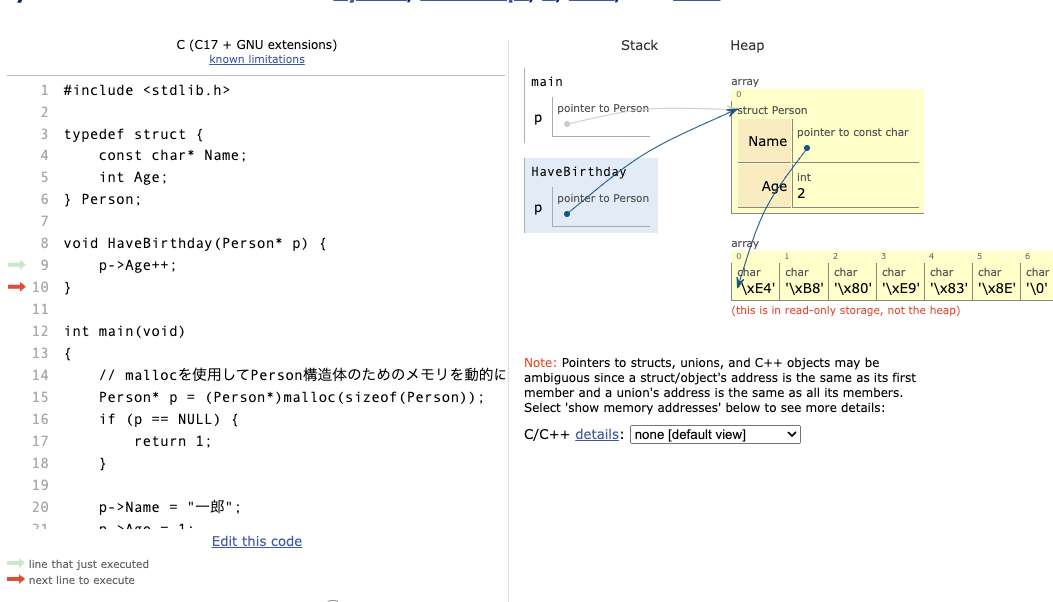
p に代入した部分まで進めるとメモリは以下のようになっています。
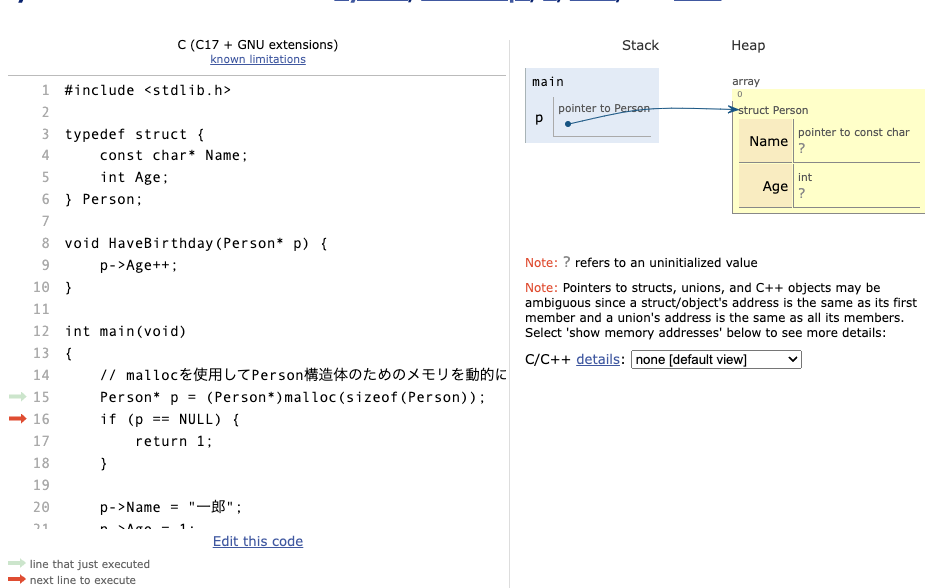
今度はPerson構造体が Heap というところにできていますね。mallocとは、ヒープというメモリ領域にメモリを確保して、そのアドレスを返すプログラムです。3
先ほど見たように、スタックは関数呼び出しが終わると確保されたメモリ領域が解放されてしまうのに対してmallocでヒープに確保したメモリ領域はプログラム中で解放するまで残ります。コンパイル時にはサイズが分からないメモリを動的に確保するときなどに使えます。
ヒープにもアドレスを介してアクセスできるので参照渡しで、HaveBirthdayを呼ぶことで、ヒープ上のオブジェクトの値を変更することもできますね。
Goプログラマはスタックとヒープを意識しない
さて、ここまでで、関数の参照渡しを使うことで、関数内から参照する構造体のインスタンスがスタックにあってもヒープだとしても、同様に操作することができることを確認しました。最後にここで確認するのは、Goプログラマはスタックとヒープを区別する必要がないということです。
GoはCのような言語と異なり、メモリの動的確保と解放をランタイムが管理する言語です。Cにおいてはmallocで確保したメモリ領域は、freeで明示的に解放しないと、確保したメモリが解放されずに残ってしまいます4。しかし、Goにおいては言語のランタイムがメモリ上のオブジェクトをスタックに割り当てるか、ヒープに割り当てるか決定してくれるため、Goのプログラマはその状態を操作するかしないかのみを気にしたらいい、ということになります。
よって、Goのプログラマは大雑把に、構造体のインスタンスの状態を変えたいときはポインタメソッドを使う、ということだけを意識するので十分であるということです。例えば、冒頭で以下のようなコードが含まれていました。
...
func NewPerson(name string, age int) *Person {
p := &Person{
Name: name,
Age: age,
}
return p
}
func main() {
...
saburo := NewPerson("三郎", 0)
fmt.Printf("Before Birthday: %+v\n", saburo)
saburo.HaveBirthdayUsingPointerMethod()
fmt.Printf("After Birthday%+v\n", saburo)
}
このコードと同様のコードはC言語では未定義動作になります。なぜならば、関数内で宣言した変数のアドレスを返しても、その関数がreturnしてスタックからpopされた後、そのメモリ領域は解放されてしまうからです。
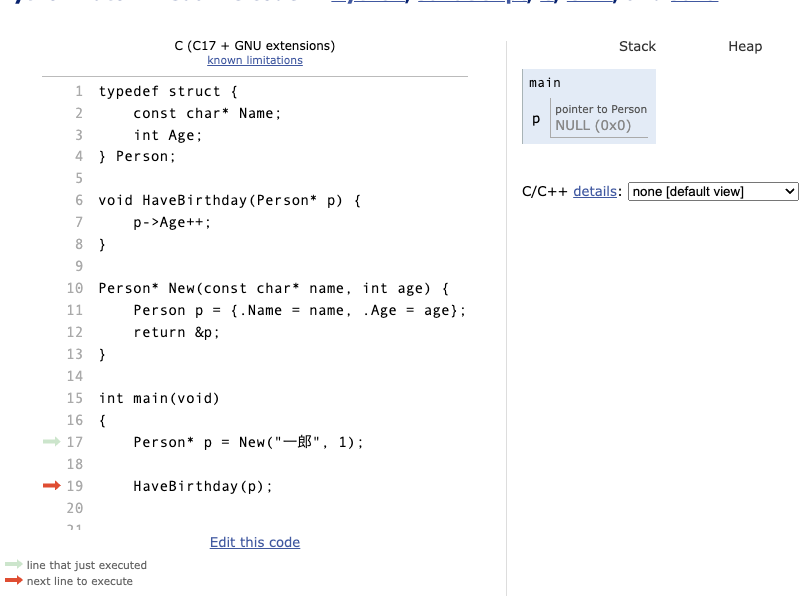
Go ではビルドフラグに-mをつけることで詳細な情報をみることができるので、以下のコードをビルドしてみましょう。
package main
import (
"fmt"
)
type Person struct {
Name string
Age int
}
func (p *Person) HaveBirthdayUsingPointerMethod() {
p.Age++
}
func NewPerson(name string, age int) *Person {
p := &Person{
Name: name,
Age: age,
}
return p
}
func main() {
saburo := NewPerson("三郎", 0)
fmt.Printf("Before Birthday: %+v\n", saburo)
saburo.HaveBirthdayUsingPointerMethod()
fmt.Printf("After Birthday%+v\n", saburo)
}
/tmp $ go build -gcflags '-m' hello.go
# command-line-arguments
./hello.go:12:6: can inline (*Person).HaveBirthdayUsingPointerMethod
./hello.go:16:6: can inline NewPerson
./hello.go:25:25: inlining call to NewPerson
./hello.go:26:16: inlining call to fmt.Printf
./hello.go:27:39: inlining call to (*Person).HaveBirthdayUsingPointerMethod
./hello.go:28:12: inlining call to fmt.Printf
./hello.go:12:7: p does not escape
./hello.go:16:16: leaking param: name
./hello.go:17:7: &Person{...} escapes to heap
./hello.go:25:25: &Person{...} escapes to heap
./hello.go:26:16: ... argument does not escape
./hello.go:28:12: ... argument does not escape
Go ではコンパイラが局所変数をヒープに移動させていることを確認することができますね。他にもインライン化とか色々やってる。
このようにCとGoはメモリ管理の仕方が違います。Goではランタイムがメモリ管理をしてくれるので、プログラマはメモリの解放し忘れなどを怖がらずにいい感じにバンバンポインタメソッド使いまくれるんやな。5
最後に
ポインタってかっこいいね。
-
なってなかったらすまん ↩
-
Cでは静的なメモリ領域に置かれる文字列を、文字列リテラルと呼ぶようで、これは文字列リテラルの例になっているっぽいです(間違ってたらすまん) C ストレージ クラス, C 文字列リテラル ↩
-
https://learn.microsoft.com/ja-jp/cpp/c-runtime-library/reference/malloc?view=msvc-170 ↩
-
これをメモリリークと呼びます ↩
-
nil pointer の dereference はするんじゃねえぞ ↩