こんにちは。
この記事はand factory.inc Advent Calendar 2023の9日目の記事です。
今年は社内外でエンジニアと色々な本の輪読会をしました。
今回はその中で特によかった本の簡単な紹介と、自分の中では鉄板になったおすすめの輪読会の進め方を紹介しようと思います。
輪読会した本は以下です(実施順)。
- ちょうぜつソフトウェア設計入門
- ソフトウェアアーキテクチャの基礎
- Webアプリ開発で学ぶRust言語入門
- マスタリングTCP/IP入門編
- 実践Redis入門
- 良いコード/悪いコードで学ぶ設計入門
- システム設計の面接試験
- 初めての設計をやり抜くための本
- 実用Go言語
- データ指向アプリケーションデザイン
おすすめの本
どれも良い本でしたが個人的にお勧め度の高い本をピックアップすると、
システム設計の面接試験
この本は「キーバリューストア」「通知システム」「URL短縮サービス」「分散システムにおけるユニークIDジェネレータ」「YouTube」などテーマに沿ってどう設計するか出題し、回答を解説する本です。
- キーバリューストア
- 複数サーバに分散させた分散型キーバリューストアとして、データ分割時の均一性・データの複製・データの一貫性・障害発生時の可用性 などの技術的な問題にどう対応するか、データを取得/登録を早くするにはどういう構造が必要か、といったことが書かれています。
- URL短縮サービス
- 元のURLからいかに短く・かつ衝突しないようにURLを発行するか、そのデータはどう持つかという仕組みについて書かれています。ハッシュ関数+衝突チェックによる手法とBASE62変換(64ではなく62です!)による手法が比較されています。
- YouTube
- 動画のアップロードを並行して実行できる仕組み(*)、ストリーミングの流れ、動画変換サーバのアーキテクチャ(有向非巡回グラフモデルというモデルを用いた設計で柔軟性と並列性を実現している)などについて書かれています。
(*) 大まかには以下のような流れです
- ユーザーがストレージにアップロード
- 動画変換サーバで変換
- メタデータ登録
- 変換後動画をストレージにアップロード
- CDNに登録
総じてどの章もかなり興味深い内容で読んでいてとてもおもしろかったのでおすすめです。
図解が多く理解しやすかった点も良かったです。
レビューに日本語訳がひどいという内容がありましたが思ったほどでなく個人的には普通に読めるレベルでした。
「面接試験」とタイトルにありますが面接試験を受ける予定がなくても大いに学びになる本です。
データ指向アプリケーションデザイン
この本は分散データシステムの設計について詳しく書かれた本なのですが、
その前提としてKVSのデータがメモリ・ストレージ内でどのように保持されているか(SSTable)、インデックス(BTree, LSMTree)がどのような仕組みで動いていてどのようなメリデメがあるか、集計用途のOLAT(Online Analytic Processing)では大量レコードをどうやって効率的に圧縮して保持するか(列指向ストレージ)、など専門的な話がたくさん出てきて難しおもしろいでかなり良いです。
↑は3章の話でこの先はまだ輪読会途中で読めていないのですが、代わりにおもしろそうであることがよく伝わる目次を貼っておきます。
3章以降の目次
4章 エンコーディングと進化
4.1 データエンコードのフォーマット
4.1.1 言語固有のフォーマット
4.1.2 JSON、XML、様々なバイナリフォーマット
4.1.3 ThriftとProtocol Buffers
4.1.4 Avro
4.1.5 スキーマのメリット
4.2 データフローの形態
4.2.1 データベース経由でのデータフロー
4.2.2 サービス経由でのデータフロー:RESTとRPC
4.2.3 メッセージパッシングによるデータフロー
まとめ
第II部分散データ
II.1 高負荷に対応するスケーリング
II.1.1 シェアードナッシングアーキテクチャ
II.2 レプリケーションとパーティショニング
5章 レプリケーション
5.1 リーダーとフォロワー
5.1.1 同期と非同期のレプリケーション
5.1.2 新しいフォロワーのセットアップ
5.1.3 ノード障害への対処
5.1.4 レプリケーションログの実装
5.2 レプリケーションラグにまつわる問題
5.2.1 自分が書いた内容の読み取り
5.2.2 モノトニックな読み取り
5.2.3 一貫性のあるプレフィックス読み取り
5.2.4 レプリケーションラグへの対処方法
5.3 マルチリーダーレプリケーション
5.3.1 マルチリーダーレプリケーションのユースケース
5.3.2 書き込みの衝突の処理
5.3.3 マルチリーダーレプリケーションのトポロジー
5.4 リーダーレスレプリケーション
5.4.1 ノードがダウンしている状態でのデータベースへの書き込み
5.4.2 クオラムの一貫性の限界
5.4.3 いい加減なクオラム(sloppy quorum)とヒント付きのハンドオフ
5.4.4 並行書き込みの検出
まとめ
6章 パーティショニング
6.1 パーティショニングとレプリケーション
6.2 キー‐バリューデータのパーティショニング
6.2.1 キーの範囲に基づくパーティショニング
6.2.2 キーのハッシュに基づくパーティショニング
6.2.3 ワークロードのスキューとホットスポットの軽減
6.3 パーティショニングとセカンダリインデックス
6.3.1 ドキュメントによるセカンダリインデックスでのパーティショニング
6.3.2 語によるセカンダリインデックスでのパーティショニング
6.4 パーティションのリバランシング
6.4.1 リバランスの戦略
6.4.2 運用:自動のリバランスと手動のリバランス
6.5 リクエストのルーティング
6.5.1 パラレルクエリの実行
まとめ
7章 トランザクション
7.1 トランザクションというとらえどころのない概念
7.1.1 ACIDの意味
7.1.2 単一オブジェクトと複数オブジェクトの操作
7.2 弱い分離レベル
7.2.1 Read Committed
7.2.2 スナップショット分離とリピータブルリード
7.2.3 更新のロストの回避
7.2.4 書き込みスキューとファントム
7.3 直列化可能性
7.3.1 完全な順次実行
7.3.2 ツーフェーズ(2相)ロック(2PL)
7.3.3 直列化可能なスナップショット分離(SSI)
まとめ
8章 分散システムの問題
8.1 フォールトと部分障害
8.1.1 クラウドコンピューティングとスーパーコンピューティング
8.2 信頼性の低いネットワーク
8.2.1 ネットワークのフォールトの実際
8.2.2 フォールトの検出
8.2.3 タイムアウトと限度のない遅延
8.2.4 同期ネットワークと非同期ネットワーク
8.3 信頼性の低いクロック
8.3.1 単調増加のクロックと時刻のクロック
8.3.2 クロックの同期と正確性
8.3.3 同期クロックへの依存
8.3.4 プロセスの一時停止
8.4 知識、真実、虚偽
8.4.1 真実は多数決で決定される
8.4.2 ビザンチン障害
8.4.3 システムモデルと現実
まとめ
9章 一貫性と合意
9.1 一貫性の保証
9.2 線形化可能性
9.2.1 システムを線形化可能にする条件は?
9.2.2 線形化可能性への依存
9.2.3 線形化可能なシステムの実装
9.2.4 線形化可能にすることによるコスト
9.3 順序の保証
9.3.1 順序と因果関係
9.3.2 シーケンス番号の順序
9.3.3 全順序のブロードキャスト
9.4 分散トランザクションと合意
9.4.1 アトミックなコミットと2相コミット(2PC)
9.4.2 分散トランザクションの実際
9.4.3 耐障害性を持つ合意
9.4.4 メンバーシップと協調サービス
まとめ
第III部導出データ
III.1 記録のシステム(Systems of Record)と導出データ
III.2 各章の概要
10章 バッチ処理
10.1 Unixのツールによるバッチ処理
10.1.1 単純なログの分析
10.1.2 Unixの哲学
10.2 MapReduceと分散ファイルシステム
10.2.1 MapReduceジョブの実行
10.2.2 Reduce側での結合とグループ化
10.2.3 map側での結合(map-side join)
10.2.4 バッチワークフローの出力
10.2.5 Hadoopと分散データベースとの比較
10.3 MapReduceを超えて
10.3.1 中間的な状態の実体化
10.3.2 グラフとイテレーティブな処理
10.3.3 高レベルAPIと様々な言語
まとめ
11章 ストリーム処理
11.1 イベントストリームの転送
11.1.1 メッセージングシステム
11.1.2 パーティション化されたログ
11.2 データベースとストリーム
11.2.1 システムの同期の保持
11.2.2 変更データのキャプチャ
11.2.3 イベントソーシング
11.2.4 状態、ストリーム、イミュータビリティ
11.3 ストリームの処理
11.3.1 ストリーム処理の利用
11.3.2 時間に関する考察
11.3.3 ストリームの結合
11.3.4 耐障害性
まとめ
12章 データシステムの将来
12.1 データのインテグレーション
12.1.1 データの導出による特化したツールの組み合わせ
12.1.2 バッチ処理とストリーム処理
12.2 データベースを解きほぐす
12.2.1 データストレージ技術の組み合わせ
12.2.2 データフロー中心のアプリケーション設計
12.2.3 導出された状態の監視
12.3 正確性を求めて
12.3.1 データベースのエンドツーエンド論
12.3.2 制約の強制
12.3.3 適時性と整合性
12.3.4 信頼しつつも検証を
12.4 正しいことを行う
12.4.1 予測分析
12.4.2 プライバシーと追跡
まとめ
30分で完全に理解できそうなスライドもあったので載せておきます
30分でわかるデータ指向アプリケーションデザイン - Data Engineering Study #18
輪読会の進め方
おすすめの進め方
回ごとに担当を決めてその人がまとめを作る進め方だと担当回がしんどくて気が重くなってしまいます。
なので事前準備がそれほど必要なく、かつ完走まで時間をかけすぎない方法がおすすめです。
- 事前に対象のページを読んでおく
- 輪読会前に感想や疑問などのコメントをNotionに記載する
- 輪読会の場でそれらについて読み合わせ、話し合う
こうすると事前準備が重くなく大体ちゃんと読んで来れて、必要とする期間も長すぎず実施できて良かったです。
コメントを書く媒体は何でも良いですがNotionのテンプレートを使うと準備が楽でした。
他にもMiroなどのコラボレーションツールを使って付箋に感想などを書いてみんなで見ていくやり方でもやりましたが、そちらも良かったです。
Notionの場合章ごとにページを作り、その中にコメントなど書くボードを用意しています。
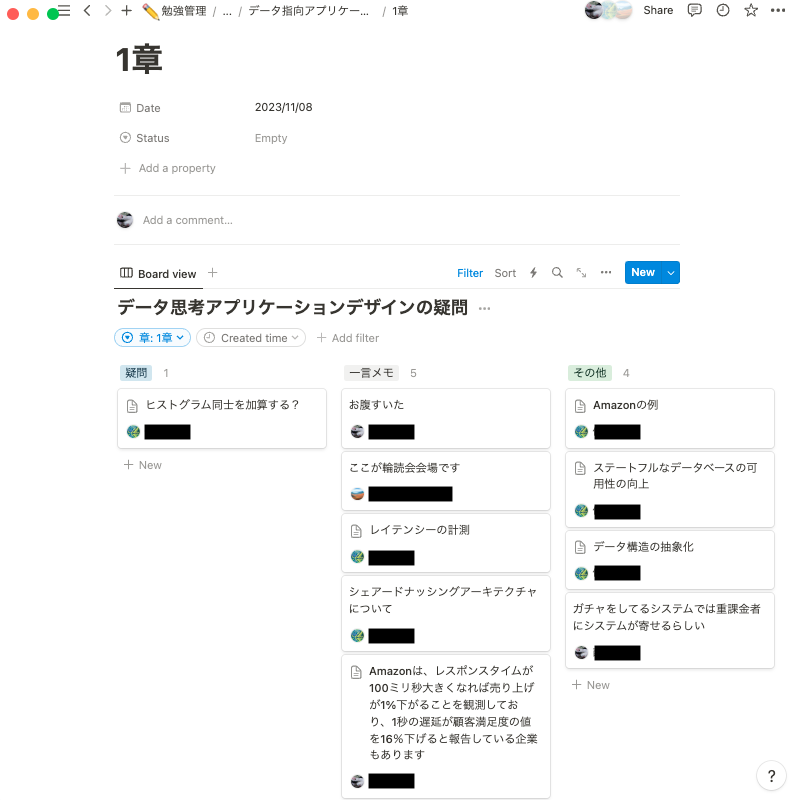
※ゆるめにやっているので適当なコメントも含まれます
使っているテンプレートを公開していますのでもし同じ形で輪読会したい方がいたら参考にしてください。
https://nsym-m.notion.site/d613b289f3614de59e776e21698072f2
途中離脱しない為には
輪読会をすると離脱が発生してしまいがちだと思います。
離脱しない為にはどうすれば良いのか、自分の考えを共有します。
- 自分で主催する
- 主催者が離脱はさすがにできませんよねw
- 少人数の内輪でやる
- 人数が多かったりよく知らない人とだったりすると簡単に休めてしまえるので離脱しやすいです
- Connpassとかにも輪読会ありますがあれは離脱してしまいそうで参加したことないです(あとコミュ障なので...)
- 業務時間中にやる
- 業務として人を募ってやると自分主催じゃなくても休みづらいので有効です
- ※忙しくならない限りは
- 業務として人を募ってやると自分主催じゃなくても休みづらいので有効です
自分のやった輪読会は以下のようなグループで、話の流れでじゃあ輪読会でもしますかって始めたものが多かった気がします
- 会社のサーバエンジニア
- 所属コミュニティでの任意出席者(主催自分)
- 仲良いエンジニアと3人で
- 同2人で
- 直近では2人と3人のグループで継続しています(余談ですが2人の方では今は本ではなくOSSを読む会をしているのですが、これもおもしろいのでおすすめです)
こんなところでしょうか。
来年も輪読会などで積読消化に励みたいと思います(消化速度よりも積む速度の方が早いのをなんとかしたい)。
読んでいただきありがとうございました。