この記事はGoodpatch Advent Calendar 2017 20日目のはずだった記事の遅延評価 投稿です。
なぜプロトタイピングは重要なのか?
GoodpatchではProttというプロトタイピングツールを提供しています。
キャッチコピーにある「1000の会議より、1つのプロトタイプ。」という言葉が表すとおり、
プロトタイピングという手法はアイデアを素早く形にし、プロダクトの完成イメージをステークホルダー間でブレなく共有するための有効な手段となります。
目に見えるようにして実際に動かして触れる形にすることで、曖昧だった仕様を検証したりプロダクトに対して具体的なディスカッションをすることができるようになります。
また、プロダクトを実装するよりもプロトタイプの作成はトライ&エラーを高速に繰り返すことが可能なため、より多くのアイデアを試してプロダクトの有り得る可能性を探れるでしょう。
データモデルも早い段階で検証すべき
現在の多くのプロトタイピングツールはアプリケーションのUIやインタラクションの設計にフォーカスしています。それらはユーザーが直接触れるインターフェースであり、開発が進んでから手戻りがあった場合に作り直しが高コストとなるため重要視されるのでしょう。
しかし、手戻りが高コストになるのはUIだけでしょうか?私はデータモデルの設計もそれに該当すると考えます。
プログラムのデータ構造はアルゴリズムと密接に結びつき、データベースのテーブル構造についてもデータが投入されてからのリレーションの変更は影響も大きくコストがかかります。要求仕様や基本設計の早い段階で認識の齟齬を無いか/仕様バグが含まれていないか検証すべきです。
データモデルのプロトタイピングでよく行われているのはRailsのScaffoldで実際に動くアプリケーションを作ってしまうことでしょうか。半自動生成でやってくれるとはいえ、モデルごとにファイルを作成したりデータの物理的な置き場所を考えたり、実際に動作確認できる状態まで持っていくのは意外に面倒です。スキーマの変更時にはマイグレーションが必要でこれまたいちいちファイル作ったり面倒です。
また、Railsを使ったとしてもプログラマーでないと実際のところプロトタイプを作るのは難しいです。UIのプロトタイピングツールはプロダクトマネージャーやサービスデザイナーも触れることを思うと対照的です。
Alloy Analyzer とは
MITで開発されたオープンソースの仕様記述・検証ツールであるAlloy Analyzerを使うとデータモデルのプロトタイピングがお手軽にできるようになります。
それほど名前を知られてないツールですが最新ツールとかでなくむしろとても枯れたツールで、最初のバージョンは1997年にまで遡ります。代表的なテキストの翻訳である『抽象によるソフトウェア設計 ―Alloyではじめる形式手法』が2011年に出版された際に日本でも一般に知られるようになったと記憶しています。
難しいことはさておき、これを使うと何が嬉しいか?というのを列挙します。
- オブジェクト指向風の簡単なスクリプトでデータモデルと制約を記述できる
- 宣言したモデルと制約に対して網羅的に全数探索を行い、低い検証コストで制約を満たす例/満たさない例を発見することができる
- モデルの関係を直感的に見通せるように、発見した具体例を可視化してくれる
- GUIツール内で完結していて、データベースなど外部環境を用意しなくていい
- 汎用的なプログラミング言語と比べるとIOなど(あえて)できないことが多く、言語の意味論が明確(1階関係論理+推移閉包)で学習コストが低い
Real Worldな利用事例としては最近だとEthereumのProof of Stake「Casper」を証明する前段階で、Alloyを使ってモデル検証の当たりをつけるというアプローチを取っています。
また、インフラ設計への応用としてはチェシャ猫さんによるKubernetesのコンテナオーケストレーションの検証がとても参考になります。
セットアップ
まずは使えるようにしてみましょう。公式サイトからStable Releasesのalloy4.2.jar、もしくはLatest buildのAlloy 4.2_2015-02-22(執筆時点)をダウンロードしてください。また、Mac向けにはdmgファイルも提供されていてアプリケーションバンドルとしてインストールすることもできます。
jarファイルを落とした場合は以下を実行するとGUIが起動します。
$ java -jar alloy4.2.jar
サンプル: 「プロジェクトごとのドキュメント管理」をモデリング
プロジェクト単位でドキュメントやアセットを管理するシステムを考えます。
エディターに以下のコードを記述し、ツールバーのExecuteをクリックしてコンパイル、Showをクリックしてグラフを表示します。
sig Document {}
sig Project {
contains: set Document
}
run {}
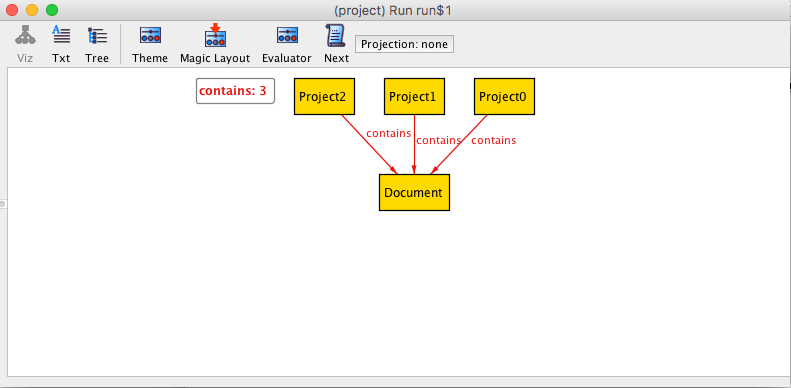
3つのプロジェクトが1つのドキュメントを保持している具体例が表示されています。
ドキュメントが複数のプロジェクトに属するという要求仕様がある場合もありますが、ここでは1つのドキュメントは必ず1つのプロジェクトに属する仕様に決めます。以下のように制約(fact)を追加してください。
sig Document {}
sig Project {
contains: set Document
}
fact {
all d : Document | one p : Project |
d in p.contains
}
run {}
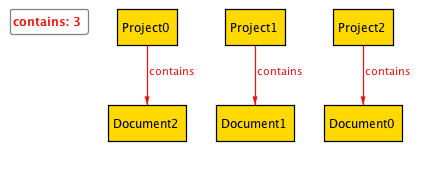
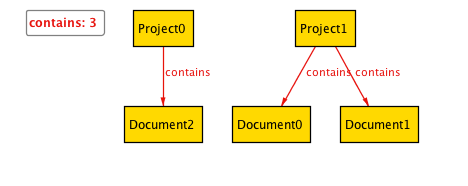
グラフが表示されているウインドウのNextをクリックしていくと具体例が次々と表示されます。問題なく仕様を満たしているようです。
次にドキュメント以外にもアセットを保持できるようにします。また、プロジェクト配下にサブプロジェクトのように再帰的にプロジェクトを持てるように仕様を変更します。
abstract sig Object {}
sig Document, Asset extends Object {}
sig Project extends Object {
contains: set Object
}
fact {
all o : Object - Project | one p : Project |
o in p.contains
}
run {}
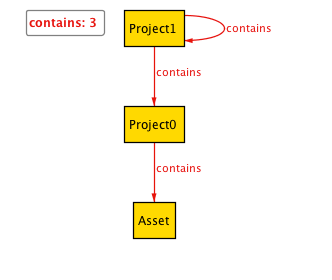
一見上手くいってるように見えますが、ProjectのインスタンスであるProject1が自身にcontainsしていて自己参照してしまっています。矛盾しているので、仕様として制約を追加します。また、探索範囲をデフォルトの3個から9個まで拡張します。
abstract sig Object {}
sig Document, Asset extends Object {}
sig Project extends Object {
contains: set Object
}
fact {
all o : Object - Project | one p : Project |
o in p.contains
//no (contains & iden)でもOK
no p : Project | p in p.contains
}
pred show(p: Project) {
#p.contains > 2
}
run show for 9 but 3 Project
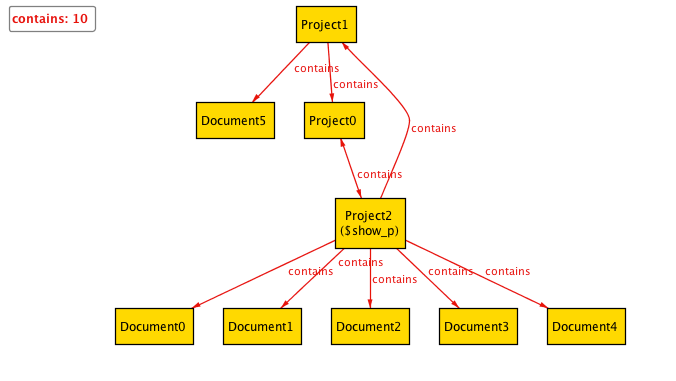
自己参照は解決しましたが、今度はProject1 -> Project0 -> Project2 -> Project1への親子関係の循環が発生しています。これも矛盾なので仕様として制約を入れます。
fact {
all o : Object - Project | one p : Project |
o in p.contains
//推移閉包で子孫にも自分が含まれないことを宣言
no p : Project | p in p.^contains
}
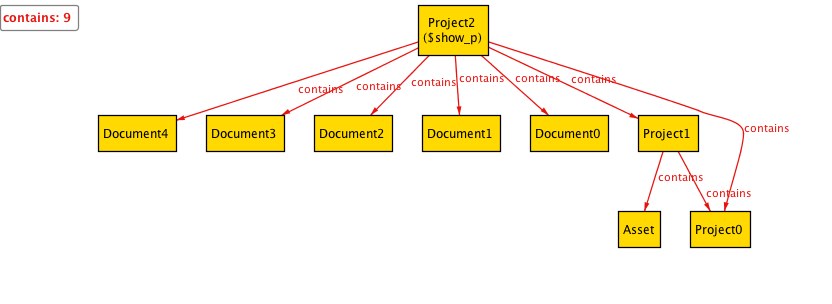
何度かNextをクリックしても自己参照や循環の具体例は見つかりません。曖昧性を排除し、無事仕様記述できたようです。
たまたまランダムにいくつか生成した例で問題が見つから無いからといってどれほど仕様に問題が無いと言えるのでしょうか?
Alloyはバグを産むようなパターンは大きさに依存せず、有界のスコープの探索でも仕様を十分にチェックできるという仮説に基いています。
これを**小スコープ仮説(ほとんどのバグは小さな反例を持つ)**と呼びます。
サンプル: 「カウンターの状態遷移」をモデリング
ドキュメント管理の例は静的な関係のモデリングでしたが、Alloyは状態遷移などの動的な関係のモデリングも表現できます。
トリビアルな例ですが、カウンターの値の増減を状態遷移として扱ってみます。
具体的には、デフォルトで用意されているutil/orderingモジュールを使うと順序構造をモデルに導入できます。
open util/ordering[State]
open util/integer
sig State {
counter: Int,
nxt: lone State
}
pred increment (s, s' : State) {
s'.counter = add[s.counter, 1]
s.nxt = s'
}
pred decrement (s, s': State) {
s'.counter = sub[s.counter, 1]
s.nxt = s'
}
//初期値は0
pred init (s: State) {
s.counter = 0
}
//増減の範囲は必ず0以上
pred lowerLimit (s: State) {
s.counter > 0
}
fact {
init [first]
all s: State - last | let s' = next[s] |
lowerLimit[s'] and (increment[s, s'] or decrement[s, s'])
}
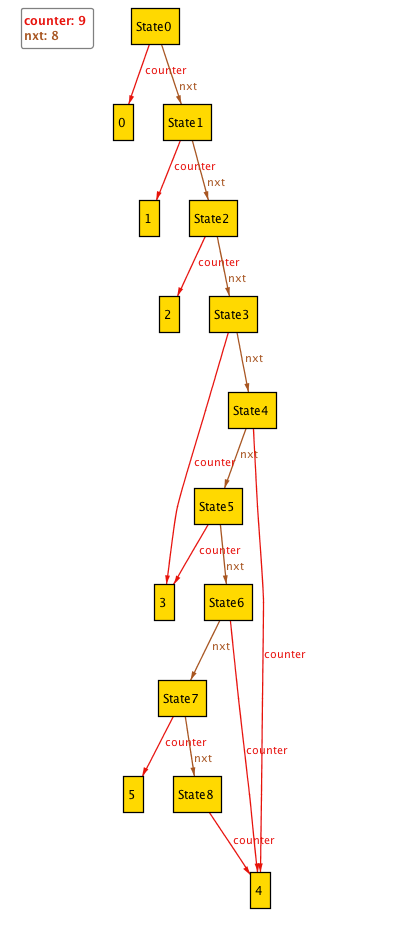
run {} for 9
まとめ
- データモデルの設計も実装の詳細を考える前にプロトタイピングしてアイデアを素早く検証しよう
- 目に見える具体例を作ることは仕様に対する理解を深め、コラボラティブに議論することを可能にする
- プロトタイピングのコツとしてはリレーションに着目して検証を優先すること
- 属性の追加/削除は関連の変更と比べ影響が少ないため、詳細設計で考えても問題ない