はじめに
前回の続きです。
マルチスレッドとパフォーマンス
前回は一つのプログラムで色々なことをするためにマルチスレッドを使うと記載しましたが、
それ以外にもマルチスレッドにすることでパフォーマンスの向上も期待できます。
UINT_MAX回のループを複数個のスレッドに分散させる以下のコードで計測してみましょう。
(2018/8/21 ご指摘をいただいたので修正して再計測)
# include <assert.h>
# include <chrono>
# include <cstdio>
# include <iostream>
# include <limits.h>
# include <mutex>
# include <thread>
# include <vector>
std::mutex mtx_;
size_t count_ = 0;
void add_count(size_t num)
{
std::lock_guard<std::mutex> lock(mtx_);
count_ += num;
}
void worker(size_t num_thread)
{
const size_t loop = UINT_MAX / num_thread;
size_t sum = 0;
for(size_t i=0; i<loop; ++i){
++sum;
}
add_count(sum);
}
int main(int argc, char *argv[])
{
// スレッド数 デフォルトは1
size_t num_thread = 1;
// コマンドラインからスレッドの本数を読み込む
if(argc >= 2){
size_t val = strtoul(argv[1], NULL, 10);
if(val == 0){
// 変換失敗時はスレッド数1で計測
}else{
num_thread = val;
std::cout << "Number of threads " << num_thread << " : ";
}
}
// 余りを求めておく
size_t mod = UINT_MAX % num_thread;
// 計測開始
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
// スレッドを生成して実行開始
for(size_t i=0; i<num_thread; ++i){
threads.emplace_back(std::thread(worker,num_thread));
}
for(auto& thread : threads){
thread.join();
}
// 余りを足しておく
add_count(mod);
// 計測完了
auto end = std::chrono::high_resolution_clock::now();
auto dur = end - start;
auto msec = std::chrono::duration_cast<std::chrono::milliseconds>(dur).count();
assert(count_ == UINT_MAX);
std::cout << msec << "msec\n";
return 0;
}
| スレッド数 | Windows | Mac |
|---|---|---|
| 1 | 6323.8 | 8341.2 |
| 2 | 3232.4 | 4177.8 |
| 3 | 2209.8 | 3860.3 |
| 4 | 1679.4 | 3562.5 |
| 5 | 1722 | 3554.9 |
| 6 | 1705.5 | 3573.7 |
| 7 | 1742.3 | 3596.2 |
| 8 | 1724.6 | 3548.5 |
| 9 | 1730.4 | 3540.3 |
| 10 | 1734.7 | 3539.4 |
| 11 | 1738 | 3539 |
| 12 | 1740.8 | 3538.7 |
| 13 | 1757.9 | 3552 |
| 14 | 1765.8 | 3541.2 |
| 15 | 1753.5 | 3540.8 |
単位はmsec、各スレッド本数ごとに10回計測した平均値になります。
参考までに以下実行したPCのスペック。
〇Mac
・コンパイラ:gcc 4.2.1
・Intel Core i5 2.7GHz
・メモリ8GB
・コア数2
〇Windows
・コンパイラ?:Visual Studio 2017
・Intel Core i5-6500 3.20GHz
・メモリ16GB
・コア数4
CPUのコア数くらいまでのスレッド数ならほぼ安定してパフォーマンスの向上が期待できます。
パフォーマンスを上げるためには排他制御を最小限に抑えることも重要だと考えられます。
同期

上記のようにスレッドとスレッドの間で待ち合わせを行うことを同期と言います。

特殊な同期機構を使わずとも上記の様にフラグを監視して同期させることも可能ですが、
whileループでポーリングするようなやり方はCPUを消費し続けるため好ましくありません。
例え数ミリ秒の停止でもCPU負荷の低減になります。
CPUを消費させず同期するためには以下の様な機能を使います。
・スレッドのjoin
・条件変数
スレッドのjoin
スレッドを生成するような関数には大体セットでjoinという関数が用意されています。
C++11のstd::thread::joinやpthreadのpthread_joinがそれにあたります。
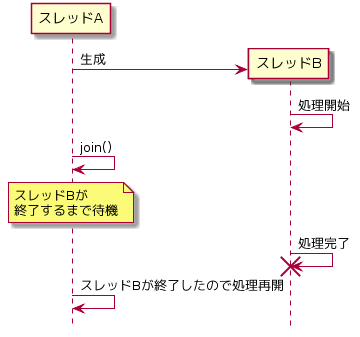
スレッドをその場で生成する場合は、joinするだけで同期できるため楽です。
既に生成済みのスレッドに処理を任せたりする場合は利用できませんのでその場合は条件変数を使います。
条件変数
条件変数はミューテックスとセットで使います。
pthreadの場合はpthread_mutexとpthread_cond、C++11の場合はstd::mutexとstd::condition_variableを組み合わせて使います。
(2018/8/22 ご指摘をいただいたので修正)
(2018/11/18 ご指摘をいただいたのでさらに修正)
# include <condition_variable>
# include <iostream>
# include <mutex>
# include <thread>
std::mutex mtx_;
std::condition_variable cv_;
bool wake_ = false; // spurious wakeup防止用
void ThreadA(void)
{
// cv_.notify_allが呼ばれるまで待機
std::cout << "ThreadA待機\n";
std::unique_lock<std::mutex> lock(mtx_);
cv_.wait(lock, []{return wake_;});
std::cout << "ThreadA待機解除\n";
}
void ThreadB(void)
{
// Aが待機するまで待つ
std::this_thread::sleep_for(std::chrono::seconds(3));
std::unique_lock<std::mutex> lock(mtx_);
std::cout << "ThreadB待機解除\n";
wake_ = true;
cv_.notify_all();
std::cout << "ThreadB終了\n";
}
int main()
{
std::thread th_a(ThreadA);
std::thread th_b(ThreadB);
th_b.detach();
th_a.join();
return 0;
}
C++11の場合だと上記のコードのようなやり方で待ち合わせが可能です。
waitで待機状態に入り、別のスレッドがnotify_all/notify_oneを呼ぶことで待機状態を解除するといった感じです。
パフォーマンス面ではnotify_oneに軍配が上がりますが、正しい使い方をしないと不具合を生む可能性があるので、
最初のうちはnotify_allを使用することを推奨します。
条件変数を使う上で注意すべきこととしては、簡単にロックを引き起こすことです。

上記シーケンスのように待機に入る前に通知関数が呼ばれてしまった場合、待機状態が解除されなくなってしまいます。
C++11の場合はこちらの「条件変数と状態」という項目にあるようステート変数を使うことで回避が可能です。
条件変数を用いて同期する場合は待機状態に入った後、確実に解除されることを保証する設計を心掛けることが重要です。
条件変数は同期における自由度が高いので色んな使い方ができますが、その分問題も生みやすいので乱用は避けた方が無難です。
まとめ
・マルチスレッドはパフォーマンスの向上にも有効。
・スレッド間の待ち合わせを同期という。
・条件変数を用いて同期を行う場合は確実に待ち状態を解除できる設計が大切。