この記事は、Microsoft Power BI Advent Calendar 2020 の8日目の記事です。
0. まえがき
Power BI でレポートを作るようになって、「スタースキーマでのモデリング」を初めて知りました。
少しずつ自分なりにモデリングできるようになってきて、必要性もある程度理解しているつもりでいるのですが、
人から「どうしてスタースキーマにする必要があるのか?」と聞かれると、今もうまく説明できません。
ので、整理してみます!という記事です。
内容は、公式Docの「スター スキーマと Power BI での重要性を理解する」 ページの前半に少し足した程度のものです。
初歩的なところから、1年前の自分に説明するとしたら、と想定して書いています。
ご指摘ありましたら是非コメントで教えていただけるとうれしいです。
また、記事中の画像や引用は、上記の公式Docからのものです。
1. スタースキーマについて説明する
1-1. スタースキーマっていったい何者…?
スタースキーマは、 リレーショナル データ ウェアハウスで広く採用されている成熟したモデリング手法 です。
① どこで使われる概念か
任意のデータを、何かしらの目的で溜めておきたいときに必要な工程を__ETL__と呼びます。
- Extract :抽出… 外部データソースに接続
- Transform :変換・加工… データを目的に合わせ整える
- Load:書き出し… 変換・加工したデータを保管場所に置く
データを取ってきても(Extract)、そもそもファイル形式もばらばらかもしれませんし、
多くの場合そのままでは使いたいことに使えないので、整備(Transform)をしてから溜めましょう(Load)ということです。
分析を目的とするとき、このTransformの工程の中でスタースキーマによるモデリングを行います。
ちなみにLoad先は、ETLの定義ではデータウェアハウスと書かれますが、
Power BI では単独でETL全部を実施できるので、その場合はレポート内のデータセットかなと思います。
② 何が目的か
ではRDB の業務データしか溜めないのならば、整備済みだからそのままでいいのか?というとそうではなくて、
データ分析するぞ!というときに、__検索や集計処理をできるだけシンプルに実行__できる形になっているのが大切です。
__スタースキーマはそれらに特化させたモデル__と言っていいのかなと考えています。
(例えばRDBの業務データと異なり、レコードの更新や削除については重要ではない)
より大量のデータ分析に向いたスノーフレークスキーマというモデルもありますが、根本的な考え方とか目的は同じ。
1-2. 具体的にどんなつくり?
① 2種のテーブル
分析したい対象、例えば累積する数値やイベント値の項目をもたせる__ファクトテーブル__と、
分析の切り口としての項目をもたせる__ディメンションテーブル__で構成されるモデルです。
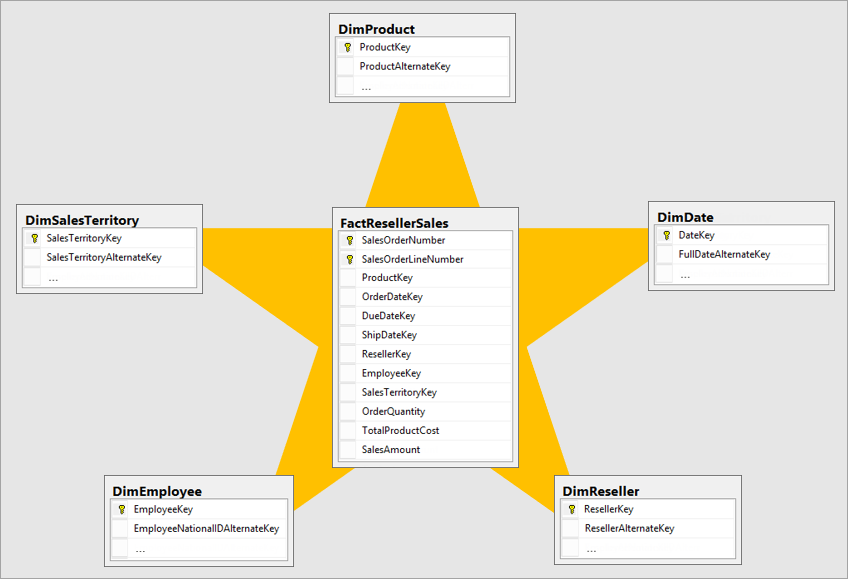
売上のデータを持ったファクトテーブルと、商品、日付などのディメンションテーブルはそれぞれ直接キーで紐づいていて、
例えば商品ごとの売り上げ、日付ごとの売り上げ…という切り口でのフィルタリングや集計が行いやすい形です。
②リレーションシップの基本
スタースキーマモデルでは、ファクトテーブルとそれぞれのディメンションテーブルのリレーションシップにおいて、
__ファクトテーブルがカーディナリティ"多"側、
ディメンションテーブルが"1"側__になることが基本です。
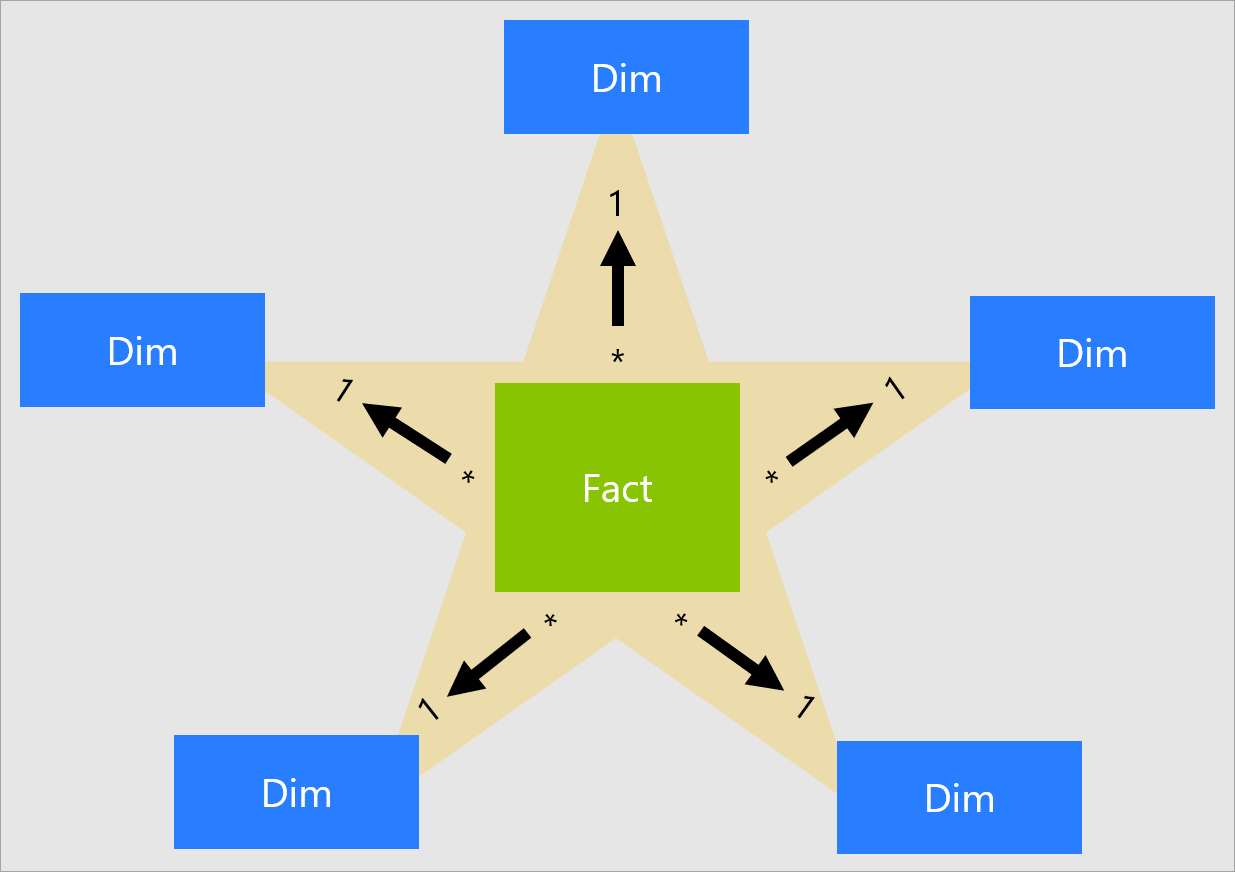
ディメンションテーブルでは、主とする項目は重複しません。
語弊を恐れずに言うと、マスタテーブルっぽいイメージです。
それに対してファクトテーブルはトランザクションテーブルっぽい感じだと考えると、"多"側になることがわかりやすい…かもしれないです。
ただし、少ない結合の回数で、なるべく早く目的のデータをひっぱりだすために、
RDBに格納される業務データほどには正規化を行いませんので、それぞれイコールにはなりません。
2. なんでPower BI に必要なのか?を説明する
結論から言うと、__Power BI の内部エンジンは、スタースキーマを想定したつくり__になっています。
公式Docにも、以下の記述があります。
この記事で紹介するスター スキーマの設計と関連する多くの概念は、パフォーマンスと使いやすさのために最適化された Power BI モデルの開発と非常に関連性があります。
適切に設計されたモデルは、フィルター処理とグループ化用のテーブルと、集計用のテーブルを提供するモデルです。
__Power BI を思う通りに動かすためには、スタースキーマに従ったモデリングが必要__なのです。
2-1. 問題が発生する具体例
2020年2月29日(土)に開催された、Power Platform Day Summer '20で、
Kagataさん(@PowerBIxyz)が__ひとつのテーブルの中で行われるフィルター処理は、人間が思った通りに動かず、集計が合わなくなる__様子をデモしてくれています。
-
セッションの実況tweetをまとめてくださってるtogetter
Power Platform Day Summer '20 トラック4 Power BI まとめ
言葉でまとめると、1テーブルだけをデータソースとして作成したレポートで、
メジャーの集計結果がフィルターのかけ方によって期待した結果にならない、という内容です。
モデリングを行い、ディメンションテーブルを分割させることで、期待した結果が表示されるようになります。
(デモを再現しようとしましたが、それはまた別記事にします…)
2-2. こわい理由
行数の少ないデータならばおかしいなと気付けるかもしれないですが、
大量のデータを扱うレポートだったら、__集計結果が間違っていてもなかなか見つけられなさそう__です。
さらに気付けたとしても、__Power BI の内部での処理が原因だと特定することはかなり困難__でしょう。
なので、これらのリスクをあらかじめ回避するために、モデリングをちゃんとやりましょう、という旨を話してくださっています。
3. Power BIでの作業で具体的に必要なことを説明する
実際のところ、Power BI ではファクトテーブルとディメンションテーブルをそれぞれ明示的に指定することはできません。
・ディメンション テーブルでは、"フィルター処理" と "グループ化" がサポートされます ・ファクト テーブルでは "集計" がサポートされます テーブルの種類をディメンションまたはファクトとして構成するためにモデラーによって設定されるテーブル プロパティはありません。 実際には、これはモデル リレーションシップによって決定されます。
ではどうするのかというと、テーブル(クエリ)の整備と、リレーションシップの設定によって、
スタースキーマに準ずるようにモデリングをします。
__かならずしもきれいな星形にしなければならない、
絶対に"1"と"多"のリレーションシップでなければならないということではなく(できないことも多い)、
上記で紹介したリスクを理解して、ファクトテーブルとディメンションテーブルの考え方をなるべく守る__のが大事なのかなと思っています。
テーブルを整備しておくと、ビジュアルも作りやすいし、
列がたくさんあるテーブルをそのまま使うとパフォーマンス低下の原因にもなるので、
習慣づけておくべき工程であることは間違いないです。
以下は、実際の作業で参考になるかもしれない補足です。
①テーブル(クエリ)の整備
とにかく1枚データをそのまま使うのはよくないということで、
ディメンションテーブル、場合によってはファクトテーブルを切り出しをします。
この作業をPower Query側でやる場合は、Guy in a Cubeのこの動画がわかりやすかったです。
Create custom keys for your Power BI relationships
空港のデータから、”AirPlainName”という列を分離して別テーブルにしています。
( SQL DB などから正規化済みのデータを持ってくる場合は、分離ではなく逆に結合させるパターンもあると思うのですが、まだ自分ではやったことがありません… )
あとは当たり前といえば当たり前ですが、ディメンションテーブル、ファクトテーブルにはそれとわかるように名前をつけます。
Power Queryの中でしか有効じゃないけれど、クエリのグループも活用しています。
②リレーションシップの管理
テーブルがだいたいいい感じに整備出来たら、次はリレーションシップです。
スタースキーマで重要なのは紐づけ自体とカーディナリティですが、
フィルターやスライサーによる絞り込みの方向を設定する「クロスフィルターの方向」も、
ビジュアルを触った時の連動具合に関連してきますので大事です。
このあたりは、手前味噌ですがこっちの記事でがんばって説明してみています。
4. あとがき
荒い部分ばかりになってしまい、無謀なテーマではありましたが、
1年前の自分もなんとかわかってくれそうな説明になったと思います…
目を通してくださってありがとうございました!