SPSS Modelerの基本ノードをPythonで書き換えます。
1.はじめに
本稿で扱うノード
- 条件抽出ノード
- ソートノード
使用データ
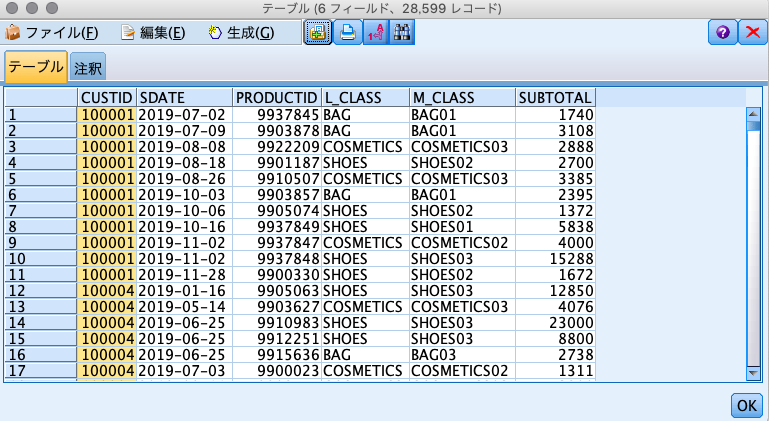
以下のようなID付きPOSデータを使用します。
- Who: CUSTID
- When: SDATE
- What: PRODUCTID, L_CLASS, M_CLASS
- How much: SUBTOTAL
- イメージ
2.SPSS Modelerのストリーム
サンプルデータから2019年4Qのデータのみを抽出します。
2-1.ノードの準備、データの確認
下記のようなノードを作成します。
- ノード全体像
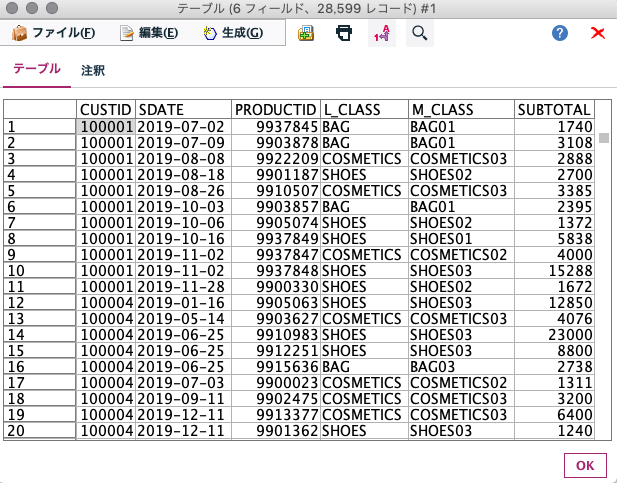
CSVファイルから直接接続されているテーブルノードを実行して、データを確認します。
- 結果
2-2.条件抽出ノード
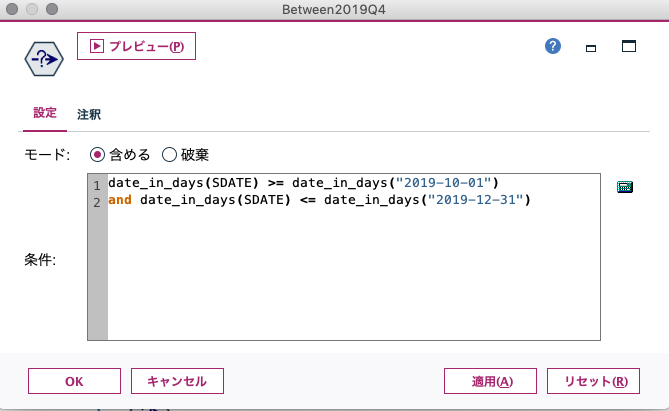
2-1で確認したデータから、SDATEが2019年4期(2019/10/1-2019/12/31)のデータを抽出します。
ストリーム全体像の該当箇所は赤枠で囲った部分です。
- 条件抽出ノード
ノードを配置した後、該当のノードを右クリックして編集を選択し、設定タブの条件に抽出条件を記載します。
- 条件抽出ノード編集画面
上記設定後、条件抽出ノードから接続されているテーブルノードを実行します。
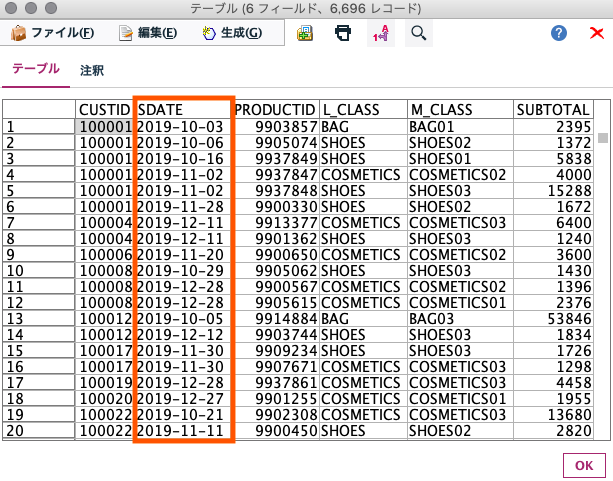
- 結果
SDATEに表示される日付が指定の日付の範囲内のものに絞られました。
2-3.ソートノード
2-3-1.単列指定
2-2で抽出した2019年4期のデータをSUBTOTALの大きい順(降順)に並べ替えます。
ストリーム全体像の該当箇所は赤枠で囲った部分です。
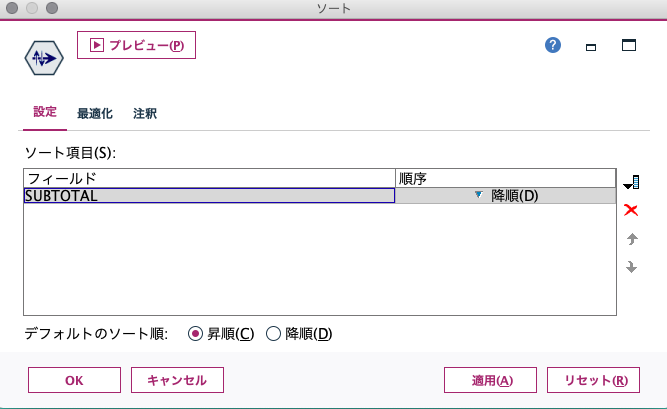
ソートノードを右クリックして編集を選択し、フィールドを"SUBTOTAL"、順序を"降順"に設定します。
ソートノードの後にあるテーブルノードを実行します。
- 結果
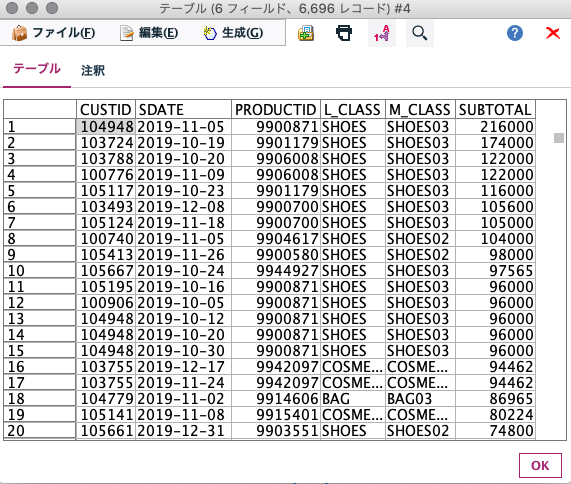
SUBTOTALが降順に並びました。
上位3データは大きい順に216000,174000,122000です。
2-3-2.複数列指定
2-2で抽出した2019年4期のデータをSDATEの小さい順(昇順)にした後、SUBTOTALの大きい順(降順)に並べ替えます。
ストリームに下図の赤枠部分ようなノードを追加しました。
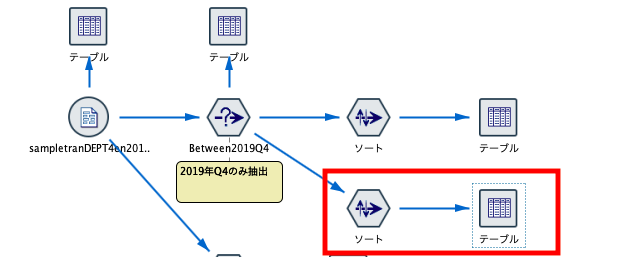
ソートノードを右クリックして編集を選択し、フィールド選択の画面で"SUBTOTAL"と"SDATE"を選択します。適用したら、"SDATE"は順序を"昇順"、"SUBTOTAL"は順序を"降順"に設定します。
ソートノードの後にあるテーブルノードを実行します。
- 結果
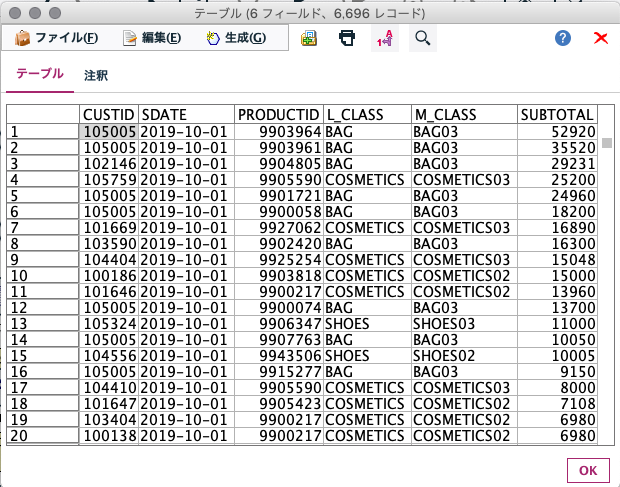
SDATEの昇順、SUBTOTALの降順にデータが並びました。
2019年10月1日のSUBTOTAL上位3位は52920,35520,29231です。
3.pythonでの同処理の記述方法
3-1. データの確認
まずはcsvを取り込んだ状態でデータを見てみます。
- pandasを使用してcsvを読み込むコード
import pandas as pd
sample_df = pd.read_csv('sampletranDEPT4en2019S.csv')
- 結果
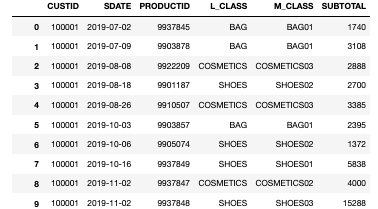
2019年の1年分の範囲のデータがあることが確認できました。
3-2. 条件抽出
pandasではquery()で文字列として条件を記載することができます。
- 条件抽出コード
sample4q_df = sample_df.query('"2019-10-01" <= SDATE <= "2019-12-31"')
sample4q_df.head(10)
- 結果
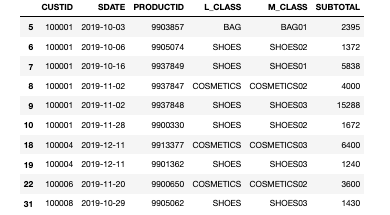
3-3. ソート
レコードをソートする方法は複数ありますが、ここではpandasのsort_values()を使用したソート方法を記載します。
3-3-1. 単列ソート
- ソートコード
sample4q_top10_df = sample4q_df.sort_values('SUBTOTAL', ascending=False)
sample4q_df.head(10)
sort_values(ソートしたいカラム名, ascending=[True:昇順, False:降順])というように使用します。
- 結果
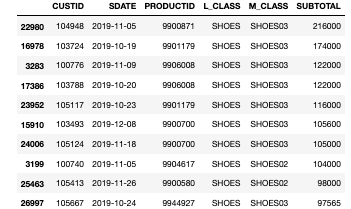
SUBTOTALが降順に並び、数値が大きい上位10番目までのレコードが出力できました。
上位3データは大きい順に216000,174000,122000です。
SPSSでの処理とPythonでの処理の結果が一致しました。
3-3-2. 複数列ソート
- ソートコード
sample4q_multisort_top10_df = sample4q_df.sort_values(['SDATE', 'SUBTOTAL'], ascending=[True, False])
sample4q_multisort_top10_df.head(10)
sort_values([ソートしたいカラム名1, ソートしたいカラム名2], ascending=[カラム1のソート方法, カラム2のソート方法])というように記述します。
- 結果
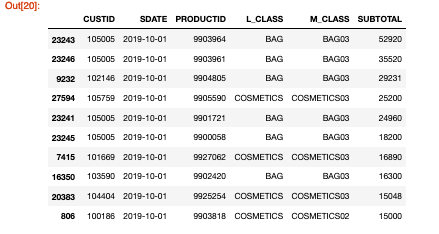
SDATEの昇順、SUBTOTALの降順にデータが並びました。
2019年10月1日のSUBTOTAL上位3位は52920,35520,29231です。
SPSSでの処理とPythonでの処理の結果が一致しました。
4. まとめ
条件抽出ノードの書き換えはquery() で条件を記載することで簡単にpythonでの書き換えができました。
一方で、sort_values()を利用したソートノードの書き換えは、1つの列を指定してソートする際にはさほど不便を感じませんでしたが、複数列を指定してソートする際はカラムの指定とソート方法の指定を別のリストでカラム順に記載しなければならず、わかりづらいと感じます。
5. 本稿で使用したデータ
6. テスト環境
Modeler 18.2.1
MacBook Air 10.14.6
Python3.6.1