はじめに
こちらの記事はGoogleが実施していた「ML Study Jams」という学習プログラムで私が学んだことを備忘録として記したものです。
機械学習の概要を知りたい方やこれから学習しようとしている人向けの記事になります。
何を学べる?
この記事では以下の内容について触れます。
- ML(Machine Learning)はどのような問題の解決に役立つか
- 候補となるユースケースをMLで学習できる形に変換する5つの段階について
- 機械学習が助長する可能性がある偏見の認識と、それを識別する方法について
MLはどの様な課題を解決できるか
機械学習は「あなたがルールを作成している全ての問題」を解決することが可能です。
適切なデータを入手できるなら、今コードを書いているヒューリスティックルールを全て機械学習を使って解決できます。
ルールをコード化するのではなく、データに基づきモデルを訓練します。
バグを修正する代わりに、新しいデータでモデルを継続的に訓練します。
具体的には
Googleの検索エンジンで考えてみましょう。
例えば「ジャイアンツ」という単語で検索が行われたとしましょう。
従来の検索エンジンの仕組みでは
- ユーザはどこに住んでいる?
- サンフランシスコ?→サンフランシスコジャイアンツを上位に表示
- ニューヨーク?→ニューヨークジャイアンツを上位に表示
- 他の地域?→ジャイアンツ(でっかい人、巨人)を上位に表示
の様に全てのルールをコード化し、検索上位に出す結果を導き出していました。
この様にコードで管理していると「新しい地域に○○ジャイアンツという野球チームができた時」などに新たに条件を追加しなければいけません。また、本当にサンフランシスコに住んでいる人がサンフランシスコジャイアンツという結果を望んでいるかもわかりません。
この課題を解決するのが機械学習です。
機械学習を用いることで、ユーザの居住地・性別・年齢など様々な要素から実際にどの結果がクリックされるか学習し、ユーザの特性に応じて検索結果を変えることが可能です。
つまり
- 検索条件やクリックした情報、ユーザ情報をもとにモデルをトレーニングして検索ランキングを作成
- 機械学習なので自動スケーリング
- ユーザの実際の好みに基づいて改善を続ける
が可能となります。
MLへの道のり
機械学習を用いて業務を改善するとなった場合、以下の5つの段階があると言われています。
- 一人の貢献者(Individual contributor)
- 委譲(Delegation)
- デジタル化(Digitization)
- ビッグデータと分析(Big Data and Analytics)
- 機械学習(Analytics Machine Learning)
それぞれの段階についてみていきます。
一人の貢献者
- ほぼすべての製品やプロセスがここから始まる
- 低コストで柔軟性がありたくさんのアイデアを試せる
- 早い段階で失敗して教訓を学べる
このステップを飛ばすことにはリスクがあります。
それはより大きな取り組みに拡大するための組織的投資が得られません。
誰も試したことがないのに、上司に「100人の人が必要です」 「巨大ソフトウェアシステムを作る必要があります」と提案できるでしょうか?
最も基本的な原型さえありません。
さらに悪いのは組織がその案に飛びつき採用してしまい、製品の責任者がひどく不正確な予測を立ててしまうことです。
また、時間をかけすぎた時の危険もあります。
仕事に熟練した人が会社を辞めるか退職すると組織のノウハウはすべてその人と一緒に会社から出て行きます。
委譲
- ビジネスプロセスに従事する人数を増やす
- 同時に 前の段階で 1人だけで 作業していたときの柔軟性もほぼ維持できる
このステップはビジネスプロセスを定型化したり組織での成功を定義したりするのに役立つ中間ステップです。機械学習の優れた実験台となります。
たとえばコールセンターの人員を考えてみます。
人はそれぞれ少し違った仕方で電話に応答します。
顧客の結果も異なります。次に組織内でそのデータを確認します。
何が上手くいったか 何が上手くいかなかったか学習できます。
デジタル化
- コンピュータシステムに プロセスの単純作業や反復作業を実行させる
- 自動化することで作業のランニングコスト等を下げることができる
- 大きな先行投資を行うことになるのでリスクもある
このプロセスを飛ばすにもリスクがあります
ソフトウェアに付随するインフラや環境などがMLでも必要になります。
MLを導入する場合は膨大なソフトウェアスタックのほんの一部だけを入れ替えるだけになります。
ソフトウェア(ITプロジェクト)をMLプロジェクトを切り離して考えてしまうとどちらかが機能しなくなることでプロジェクト全体が失敗します。
何が起きたか把握しにくくなります。
ITプロジェクトを試して成果と経過を確かめてその上にMLを乗せることが大切です。
ビッグデータと分析
- 社内業務や外部ユーザなどすべてのものを測る。
- デジタル化の段階のソフトウェアのアルゴリズムを調整する。
- データから成功を再定義する。
デジタル化で得た大量のデータから、最初に定めたの定義を再評価できます。
「ユーザはAを好むと思っていたが本当だろうか?」「Aを適切に提供しているだろうか?」などです。このステップを飛ばすことで
- 人間による洞察段階を経ずにソフトウェアからMLに移行した場合、クリーンで整理されたデータがないのでMLのアルゴリズムをトレーニングできない
- 成功の尺度がわからない
- アルゴリズムが役立っているか判断しにくい
といったリスクが生まれます。
機械学習
- 前のステップで得られたすべてのデータを使用しコンピュータプロセスを自動的に改善し始めます。
上記の4つの段階を踏むことで初めて適切な状態で機械学習を行うことができる様になると言われています。
MLとバイアス
人の認識や考え方にはバイアス(偏り)が存在します。
機械学習の学習データとして、偏りがあるデータを取り込んだ場合、どうなるでしょう?
そうです機械学習で導き出した結果が偏ったり、誤った結果になります。
このバイアスについて、Googleが大変わかりやすい動画を出していますので以下の動画をご視聴ください。。
Machine Learning and Human Bias
https://www.youtube.com/watch?v=59bMh59JQDo
英語音声なので、英語が苦手な方は自動翻訳(日本語)でご視聴ください。
MLの評価指標
機械学習システムはミスを犯します。重要なのはどんなエラーかまたMLモデルの出力がユーザエクスペリエンスにどう影響するかを理解することです。
例えば人の顔を認識するMLモデルを作成するとします。
以下の表の横軸の「ラベル」というのは人間が定義した結果、「モデル出力」というのが機械学習で導き出された結果となります。
- 真陽性・・・人間も機械学習も人と判定
- 偽陽性・・・人間は人ではない、機械学習は人と判定
- 偽陰性・・・人間は人、機械学習は人ではないと判定
- 真陰性・・・人間も機械学習も人ではないと判定
(人と人間がわかりづらいですね、、、)

機械学習で導き出される結果の判定の調整を行うことが大切になってきます。
例えば画像の中から個人情報が含まれる箇所にモザイクをかけるモデルを作成する場合は以下の様に調整する必要があります。
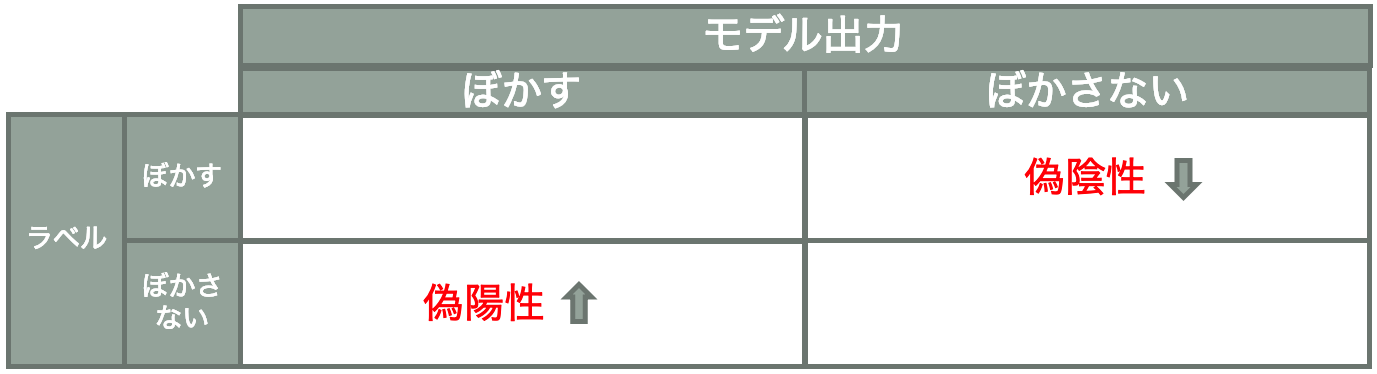
この場合は偽陰性率が高くなると、本来ぼかさないといけないものがぼかされず、プライバシーが公にさらされ個人情報が漏えいする可能性が高くなります。
なので偽陰性率を低くするべきでしょう。
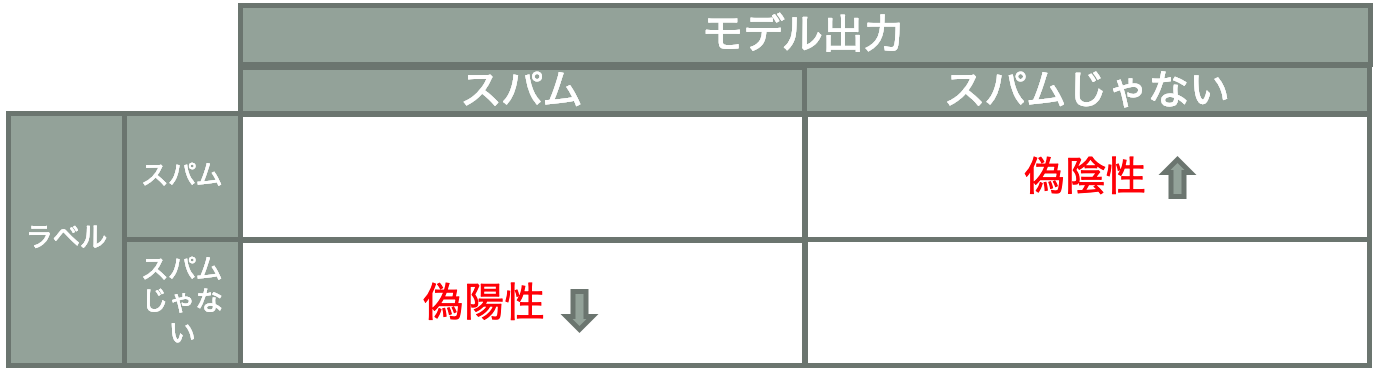
逆にスパムメッセージフィルタのモデルを考えた場合、偽陽性率が高いと家族や友達からのメッセージ等重要なメッセージが受信トレイから削除されてしまう可能性が高くなるため、偽陰性率を高める必要があります。
(参考)機械学習とAI(人工知能)の違い
まず機械学習を学ぼうと思った時にぶち当たるのが、「AIと機械学習って違うの?」「ディープラーニングってよく聞くけど何?」みたいな全体像の把握だと思います。
こちらについてはML Study Jamsでは教えてくれない内容ですが、知っておく必要があると思い調べました。以下のサイトではこの様に定義されていました。
https://markezine.jp/article/detail/29471
- 人工知能
- 機械学習
- ディープラーニング
- 機械学習
人工知能が機械学習を、機械学習がディープラーニングを内包する形になっています。
また、それぞれの言葉の定義は以下の様になっています。
・人工知能
人間と同様の知識を実現させようという取り組みやその技術
・機械学習
特定のタスクをトレーニングにより実行できるようになるAI。人が特徴を定義する
・ディープラーニング
マシンが特徴を自動で定義
この言葉の定義には正解はないと思いますが、自分が一番しくっり来たので紹介いたしました。
最後に
機械学習は面白いですが、自分でモデルを作成するのは少々ハードルが高い様に感じます。
世の中にはすでに学習済みのモデルがたくさんあります。まずはそれらを使ってみるのがいいかもしれません。
初投稿、読む辛い記事だと思いますがご容赦ください。。。