こちらの記事は投稿時点の情報です。
最新情報は公式ドキュメントMicrosoft Learnでご確認お願いいたします。
Microsoft Japan - Azure Developer Platform Team の D̷ELL と申します。
本日は Azure OpenAI Service に関して触れてみます。
Azure OpenAI Service は、GPT-4o、GPT-4 Turbo with Vision、GPT-4、GPT-3.5-Turbo、Embeddings モデル シリーズなど、OpenAI の強力な言語モデルへの REST API アクセスを提供します。 これらのモデルは、特定のタスクに合わせて簡単に調整できます。たとえば、コンテンツの生成、要約、画像の解釈、セマンティック検索、自然言語からコードへの翻訳などです。 ユーザーは、REST API、Python SDK、または Azure OpenAI Studio の Web ベースのインターフェイスを介してサービスにアクセスできます。
Azure OpenAI Service は、生成AI関係のアプリ開発におけるデファクトスタンダードになりつつあります。今回は、サービス利用開始直後に躓きがちな「クォータ制限」と「クォータ管理」に関する、自分用の備忘録です。
0. リファレンス
公式ドキュメント
1. クォータ制限とクォータ管理の違い
私が一番躓いたポイントですが、クォータ制限とクォータ管理は別物です。以下に、調べた結果を記載します。本稿ではクォータ管理については触れませんが、MS Learnをご参照頂ければ幸いです。
-
クォータ制限:
クォータ制限は、Azure OpenAIサービスが提供する各種リソースや機能に対する使用量の上限を指します。これには、Tokens-per-Minute (TPM) の制限や、各Azureサブスクリプションのリージョンあたりの OpenAI リソース数などが含まれます。 -
クォータ管理:
クォータ管理を使うと、ユーザーのサブスクリプション・リージョンごとに与えられた Tokens Per Minute (TPM) のクォータを、各デプロイに対してユーザー任意の値 (1K 単位) で割り当てることができます。
つまり、クォータ制限は「各リソースに設定された利用上限」を、クォータ管理は「制限をデプロイごとに設定できる」ということですね。
2. クォータ制限とは
Azure OpenAI Service には、モデルごとの1分あたりの要求数やトークン数、モデルデプロイの最大数など、クォータによる制限があります。クォータは容量の保証ではなく、Azure リソースのクレジット制限です。大規模な容量が必要な場合は、Azure サポートに連絡してクォータを引き上げることができます。
例えば、以下のドキュメントを見てみましょう。
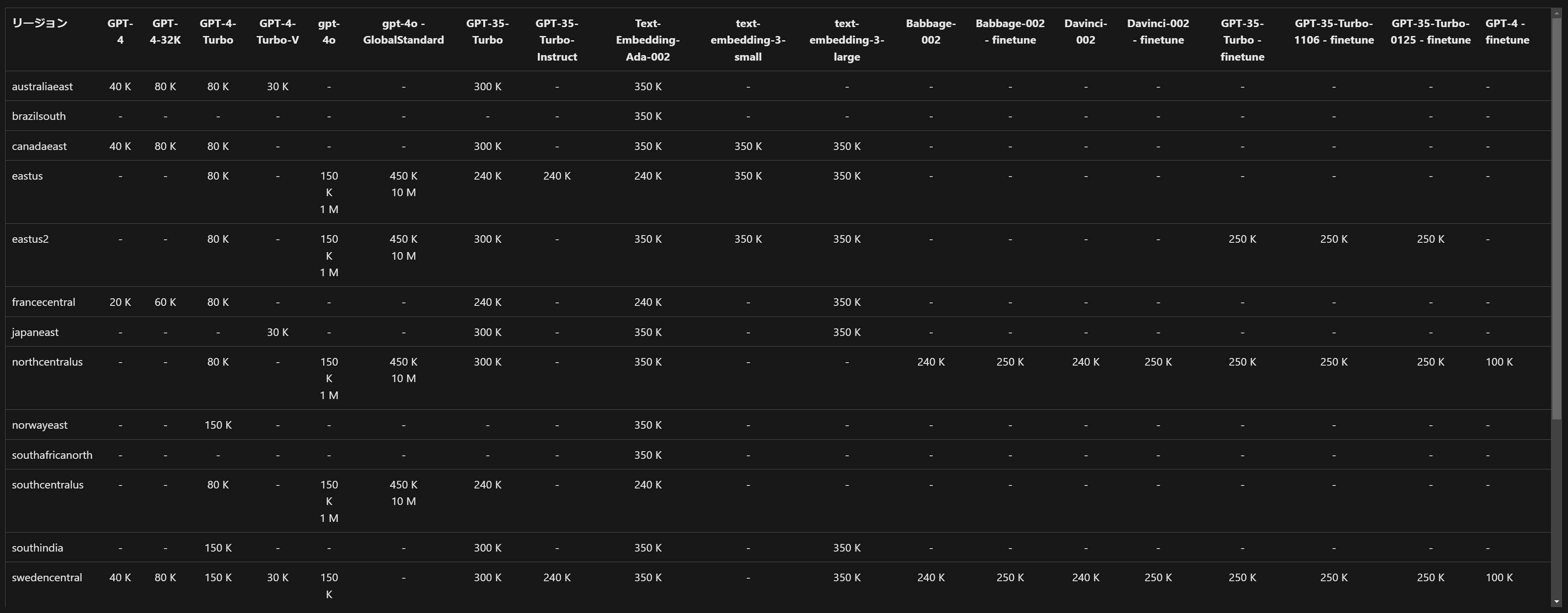
Azure Open AI の japaneast リージョンの GPT-35-Turbo における「300 K」という記載は、通常、1 分間あたりのトークン制限を示しています。具体的には、これは東日本リージョンの GPT-3.5-Turbo モデルにおいて、1 分間あたり最大 300,000 トークンまでのリクエストが可能であることを意味します。
つまり、「あなたは このリージョンのこのモデル において、1 分間 に 最大 {n} token まで、サービスを利用するように制限できるよ」というものですね。
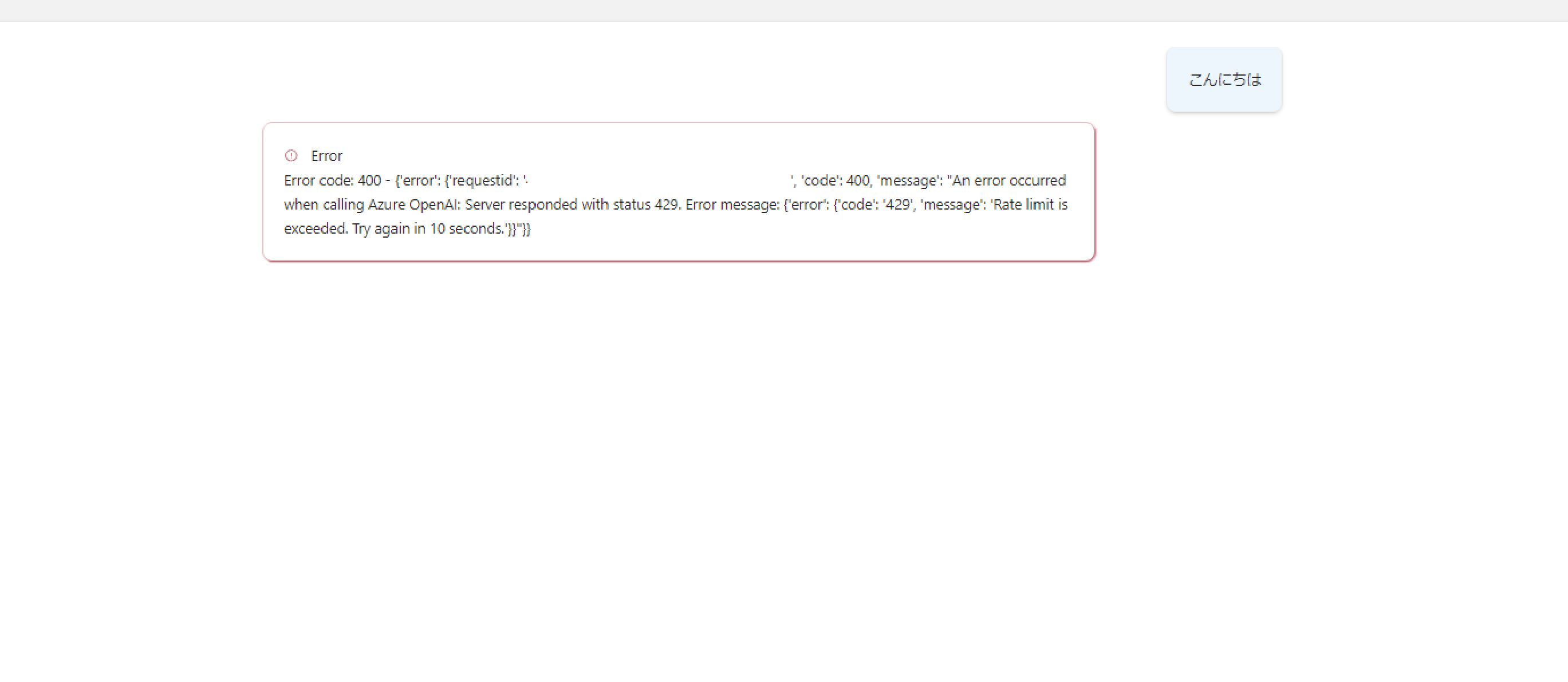
なお、クォータ制限にかかると、以下のようなエラーが表示されます。

3. トークンとは
トークンとは、入力テキストや生成されたテキストの一部を指します。
たとえば、「Hello, world!」という文章は、一般的なトークナイザー(例えば、OpenAI の GPT-4 で使われるもの)では 5 つのトークン(「Hello」「,」「 」「world」「!」)としてカウントされます。
トークン数の計測
なお、トークン数は以下のリポジトリを用いることで、計測が可能です。
このリポジトリには、OpenAI LLM 用のバイト ペア エンコーディング (BPE) トークナイザーの Typescript および C# 実装が含まれています。これは、OpenAI tiktokenのオープン ソースの rust 実装に基づいています。
このリポジトリを利用することで、プロンプトを LLM に送る前に、Nodejs および .NET 環境でプロンプト トークン化を実行できます。これにより、トークン数を計測できるということですね。
トークンの計測に関する詳しい解説は、以下の当社社員による Zenn ブログをご覧ください。
トークンのカウント方法
Azure OpenAIのクォータ制限におけるトークン数は、送信されたプロンプトと受信したレスポンスの両方を含む総トークン数としてカウントされます。つまり、API リクエスト時に送信されたプロンプトのトークン数と、それに対する生成されたレスポンスのトークン数の合計 で計算されます。
- プロンプトのトークン数: ユーザーが送信するテキスト(プロンプト)が100 トークン
- レスポンスのトークン数: AI が生成するレスポンスが 150 トークン
この場合、クォータにカウントされるトークン数は、プロンプトの100トークンとレスポンスの150トークンを合わせた250トークンとなります。
4. クォータ制限の解除申請
さて、実際のクォータ制限が表示されている画面を見てみましょう。
Azure AI | Azure OpenAI Studio にアクセスし、[管理] セクションの [クォータ] ブレードにアクセスしてください。
[リージョン] に [JAPANEAST] を選択し、表示します。
すると、 [Tokens Per Minute (thousands) - GPT-35-Turbo] - [使用量/制限] に [0 of 1] と表示されています。現在(デフォルト)の設定では、1 分間に 1,000 token しか扱えないことがわかります。
なお、右の 0% は、現在のトークンの使用量です。
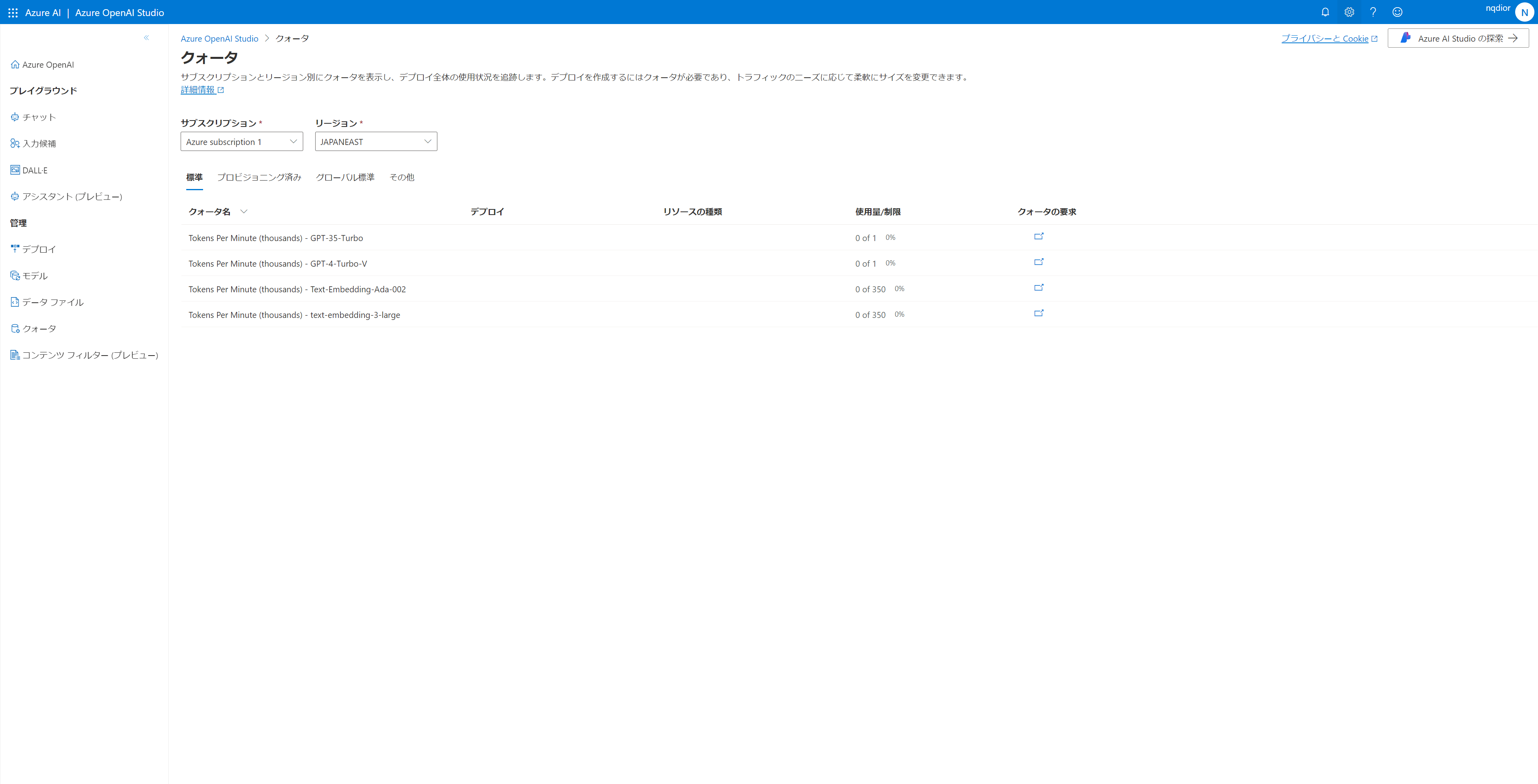
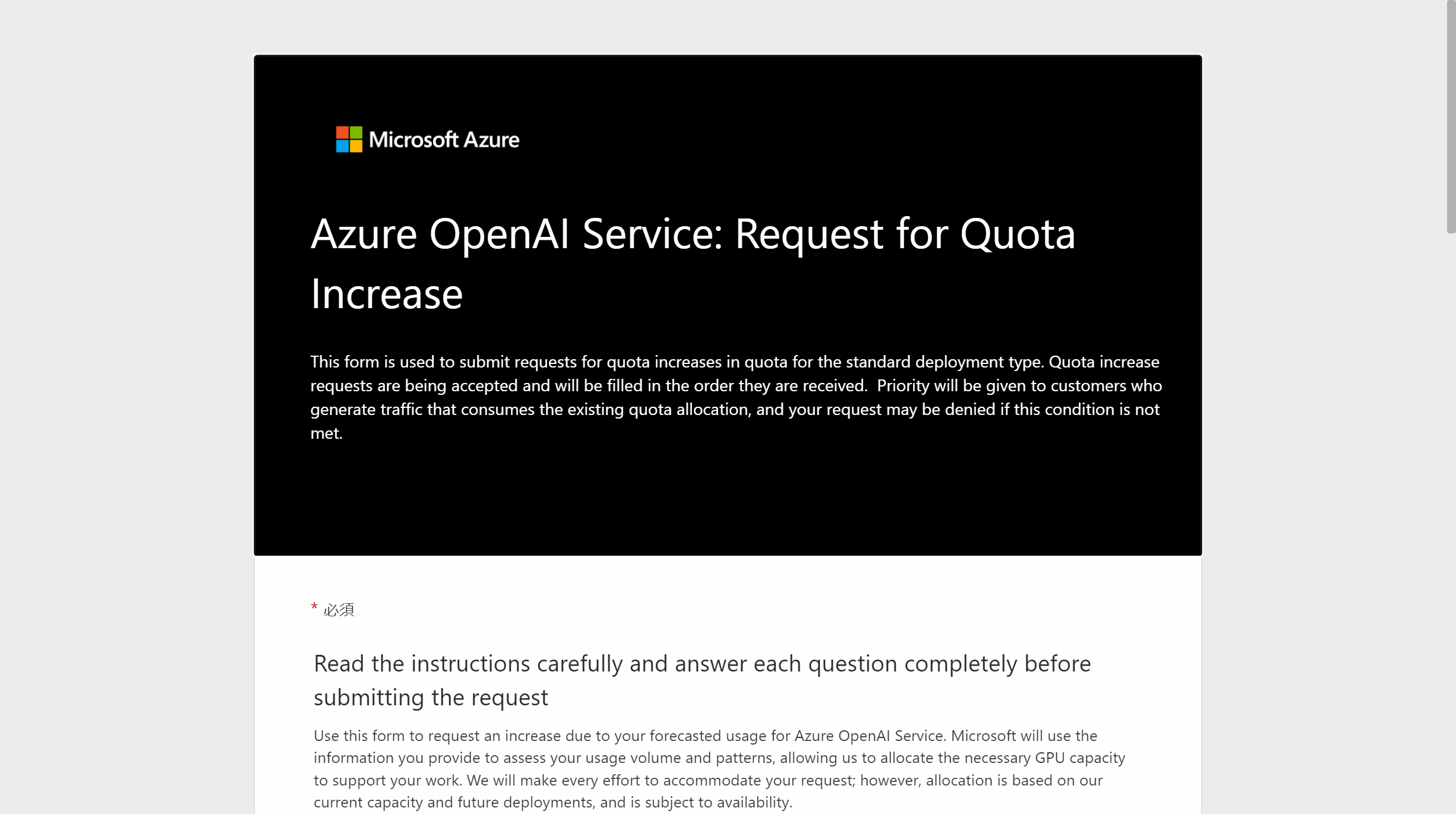
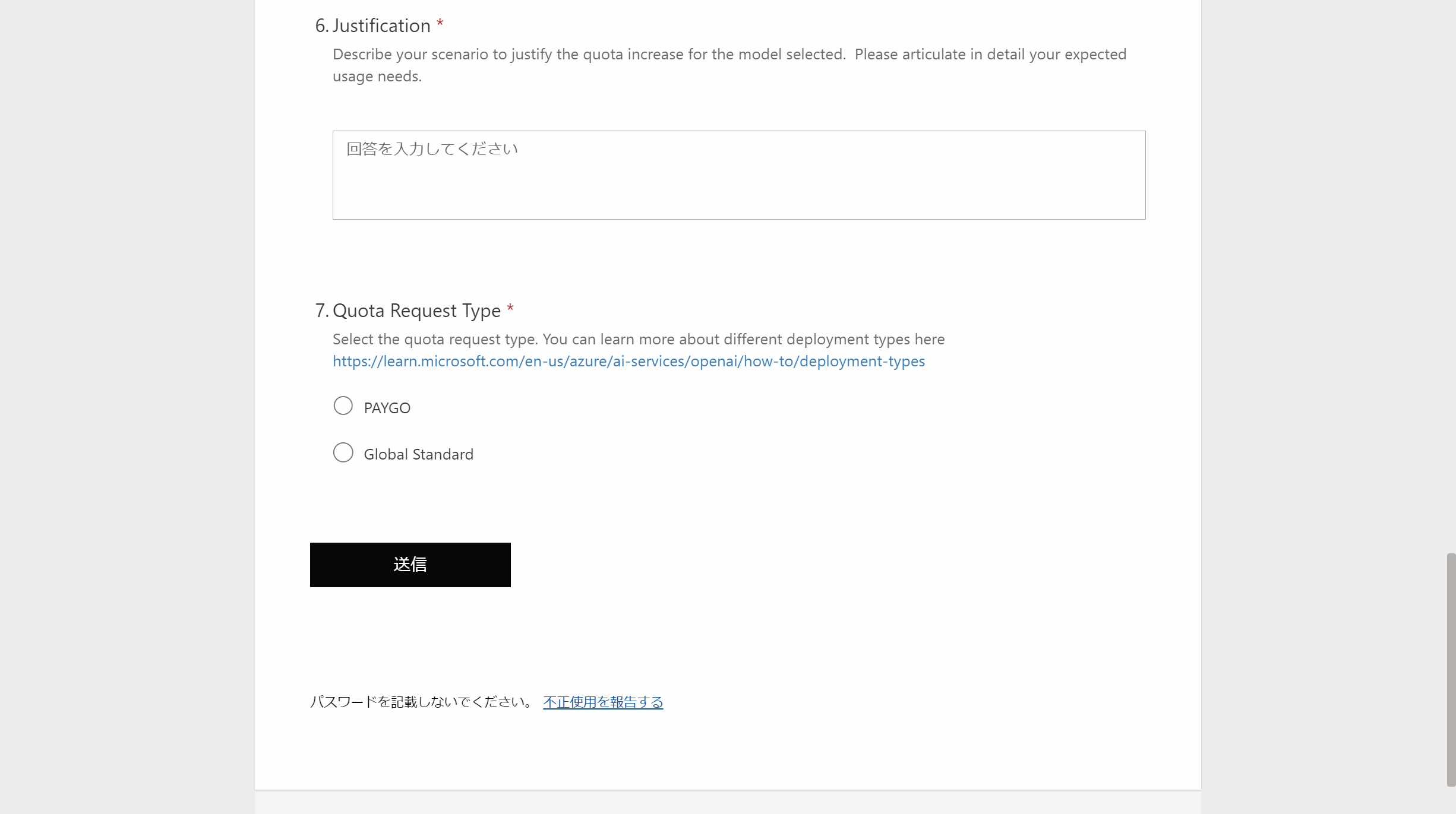
[クォータの要求]という欄から、リンクをクリックします。すると、クォータ制限の解除を申請するための Form が表示されます。内容を確認して申請を行うことで、クォータのトークン制限を引き上げることができます。
5. まとめ
ざっくりとAzure OpenAIのクォータ制限についてまとめてみました。
自分の理解がまだ浅いところもありますが、参考にして頂けると幸いです。
最後に
*本稿は、個人の見解に基づいた内容であり、所属する会社の公式見解ではありません。また、いかなる保証を与えるものでもありません。正式な情報は、各製品の販売元にご確認ください。