はじめに
Yahoo!知恵袋でWebスクレイビングのプログラムを参考元のソースコードより作成しました。
参考にしたのは以下のURLのコードです。
修正箇所は以下の2点です。
・最新版Seleniumで廃止済のメソッドを現行用に書き換え
・ソードがデフォルトだったものを「質問日時が新しい順」でソートするように機能追加
Seleniumは全く存じ上げてないのですが、今だとChatGPTに「最新のSeleniumで動くようにして。」とお願いするだけでマイグレーションしてくれます。すごいです!
ソースコード
chiebukuro.py
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
import urllib
import re
import pandas as pd
sleep(2)
PAGE_LIMIT = 20 #ページ遷移の最大の回数
SEARCH_QUERY = "原神"
SQRAPING_URL = "https://chiebukuro.yahoo.co.jp/"
#出力結果を格納数csvファイル
csv_file_name = SEARCH_QUERY + ".csv"
#ドライバーを設定する
#linuxなどGUIがない環境で動かす場合は、ヘッドレスモードを入れておく
#options = webdriver.ChromeOptions()
#options.add_argument('--headless')
#driver = webdriver.Chrome('./chromedriver', options)
driver = webdriver.Chrome('./chromedriver')
#知恵袋ページを読み込む
driver.get(SQRAPING_URL)
#該当ページを解析する
def analysis_action():
elems = driver.find_elements(By.XPATH, "//*[@id='sr']/ul/li[*]")
# 取得した要素を1つずつ表示
out_puts = []
if(len(elems) == 0):
print("ページは存在しないよ〜")
else:
for elem in elems:
out_dic ={}
out_dic['query_key'] = SEARCH_QUERY
out_dic['rs_title'] = elem.find_elements(By.XPATH, 'h3/a')[0].text
out_dic['rs_link'] = elem.find_elements(By.XPATH, 'h3/a')[0].get_attribute('href')
out_dic['rs_summary'] = elem.find_elements(By.XPATH, 'p[1]')[0].text
#print(out_dic)
out_puts.append(out_dic)
#print("*" * 60)
return out_puts
def next_page_action():
"""
現在のページから次のページを読み込むアクションを実行する
"""
rtn = False
#次へボタンのクリック
elems = driver.find_elements(By.XPATH, '//*[@id="pg_low"]/div/a[*]')
#現在のページ
print("ページ遷移前のurl:")
print(driver.current_url)
if(len(elems) == 0):
print("次のページは存在しないよ〜")
else:
for elem in elems:
#print(elem.text)
if(elem.text != "次へ"):
continue
url = elem.get_attribute('href')
driver.get(url)
rtn = True
break
return rtn
# 最初の検索を実行する
driver.find_element(By.CSS_SELECTOR, '.SearchBox_searchBox__inputBoxInput__nf3fq').send_keys(SEARCH_QUERY)
search_button = driver.find_element(By.CSS_SELECTOR, '.SearchBox_searchBox__inputButton__2OXXW > .util-icon')
search_button.click()
sleep(2)
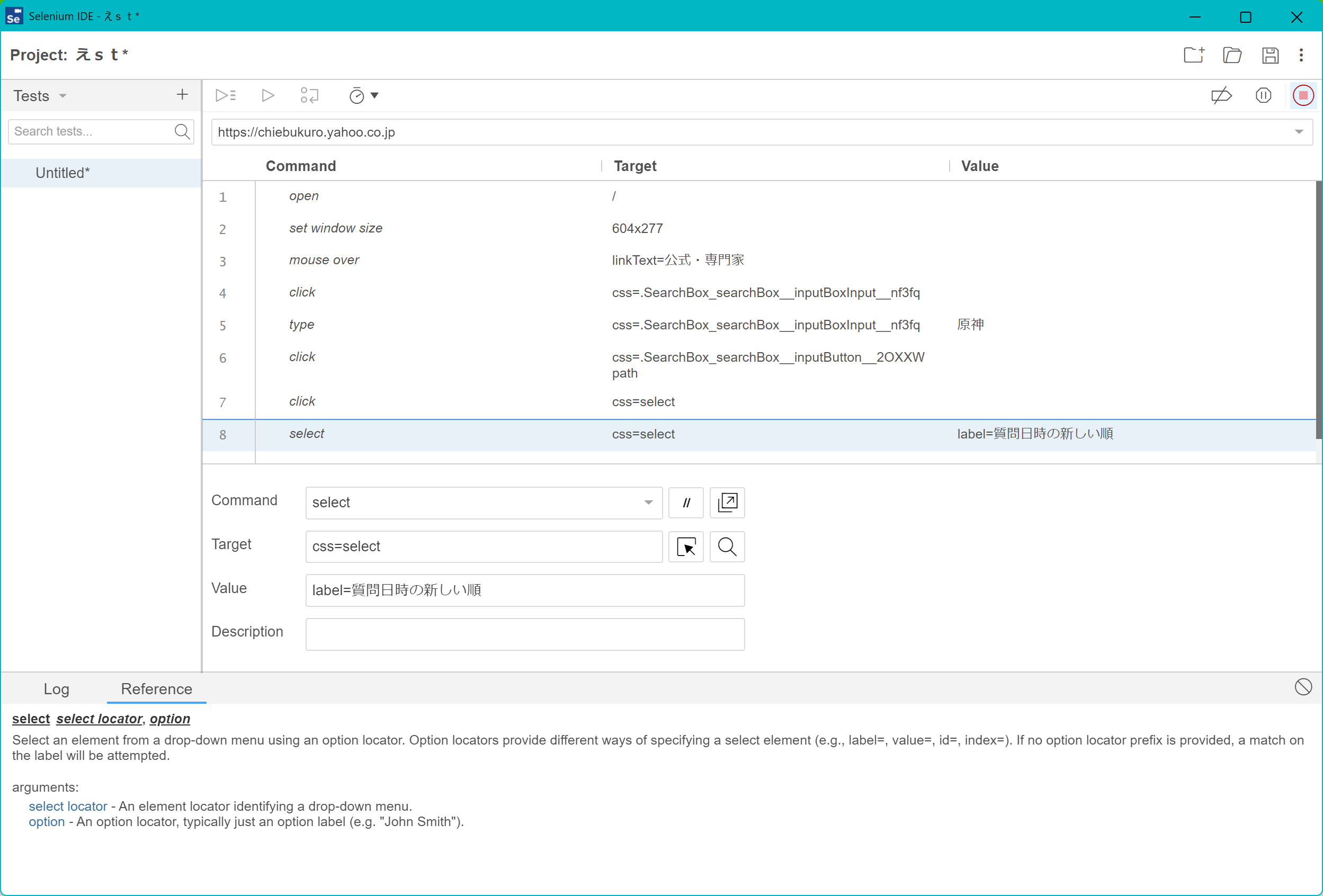
dropdown = driver.find_element(By.CSS_SELECTOR, 'select')
select = Select(dropdown)
select.select_by_visible_text('質問日時の新しい順')
sleep(3)
#知恵袋の検索結果の一覧をpandasに格納してcsvに書き出す
#csvには、途中で止まっても良いように、1ページ終わったら書き出すようにしている
d = analysis_action()
df=pd.DataFrame(d)
df.to_csv(csv_file_name, encoding="utf_8_sig")
analysis_list = []
analysis_list.extend(d)
for page in range(PAGE_LIMIT):
print("ページ %dを実行中" % page)
sleep(5)
#次のページに遷移する
rtn = next_page_action()
if(rtn == False):
break
#知恵袋の質問リストを格納する
d = analysis_action()
if(len(d) > 0):
analysis_list.extend(d)
df=pd.DataFrame(analysis_list)
df.to_csv(csv_file_name, encoding="utf_8_sig")
driver.close()
driver.quit()
つまづいたところ
Seleniumだけじゃなくて、HTMLもCSSも何にもわからずCSSの要素名が何なのか確認するのに苦労したのですが、ChromeのSelenium拡張機能を利用して、動作を記録することで対象の要素名がなんなのか確認できました。
課題
こちらは検索ページから情報を抽出しているため、完全な質問内容が省略されており完全に取得しきれていません。なので、質問内容についてしっかり取得しきれるように修正する必要があります。
おわりに
読んでいただきありがとうございました。本来であれば対象のGitHubにプルリクをしたほうが良いのかな。という気もするんですが、残念ながらGitHubの覚えも無いためできませんでした。