前編では、3層ニューラルネットワークをPythonで手作りするところまでやりました。
引き続き後編では、 Kaggle の Titanic データセットを用いたモデル構築から説明します!!
前編はサカナ本の写経が中心でしたが、後編はもう少しオリジナリティを出していきます。
もくじ
[前編]
・はじめに
・ニューラルネットワークの実装
- 必要な関数の実装
- 全結合3層ニューラルネットワークの実装
[後編]
・[Kaggle Titanic 学習用データでモデル構築](#Kaggle Titanic 学習用データでモデル構築)
- Kaggleとは?
- データセットの取得
- 学習用アルゴリズムの実装
- 学習用データの前処理
- モデル構築
・[Kaggle Titanic テスト用データで未知のデータを予測](#Kaggle Titanic テスト用データで未知のデータを予測)
- モデルへの訓練用データの投入
- 予測結果をSubmit
Kaggle Titanic 学習用データでモデル構築
Kaggleとは?
Kaggleとは、予測モデリングやデータ分析のコンペティションに関するプラットフォームサイトです。
様々な企業や研究者がコンペ主催者となって自身のデータセットを公開し、世界中のデータ分析者に対して良い分析モデルの提供を募ります。提供される分析モデルには順位が付けられ、コンペ主催者から賞金が提供されます。
Kaggleはこの主催者と参加者に場を提供しているプラットフォームです。"Kaggle"というのは、このプラットフォームを運営する会社の名前でもあります。
Kaggle公式サイト
wikipedia
参加者は、アクティブとなっているコンペに参加してデータセットを取得し、コンペの目的に適合する精度の良い分析モデルの構築を目指します。
コンペでは、回答つきの学習用のデータとSubmissionに使うテストデータが提供されています。
分析モデルが作れたら、テストデータをそれに適用して結果をSubmissionします。すると、即座に予測精度と順位の結果が表示されるという流れです。
今回の記事では、Kaggleのチュートリアル的位置付けである Titanic コンペに参加して分析モデルをSubmissionしてみます。
コンペの目的は、1912年に大西洋で沈没した豪華客船タイタニック号の乗客の生死を予測するモデルを構築することです。与えられた既知の乗客データを元にして、未知の乗客に関する生死予測モデルを作成します。
本記事では、ニューラルネットワーク学習のアウトプットと、Kaggle 参加の流れを掴むことが目的ですので、分析手法やモデル構築過程には突っ込みどころが多々あると思いますが、どうぞ広い心でご覧ください。。。
データセットの取得
Kaggle の Top ページから Competitions タブを選択すると、次のようなTitanicのコンペが見えると思います。
(初参加の場合は、"Active Competitions" の下のほうにあると思います)
これをクリックすると、コンペのページに移動します。ここでData タブをクリックすると、提供されているデータを確認することができます。
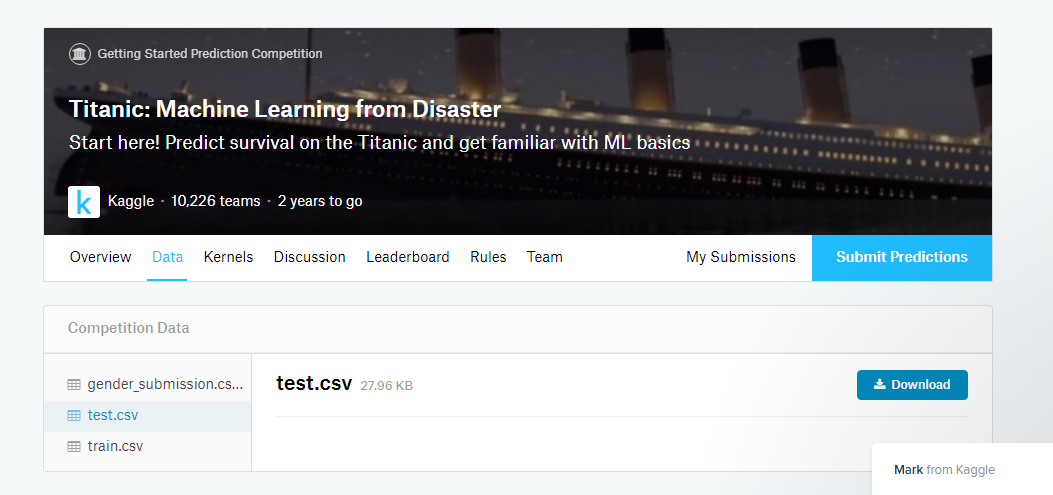
Titanic コンペで提供されているデータは下記の3つです。
・train.csv : 学習用に使う「正解」付きのデータです
・test.csv : Submissionに使う「正解」の付いてないデータです
・gender_submission.csv : Submissionする際のファイル形式のサンプルです
主に利用するのは train.csv と test.csv の2つのデータです。
それぞれ下記のようなVariableを持っています。
・PassengerId : 乗客のID
・Survived : 沈没事故による乗客の生死結果。これを予測するモデルを作る(train.csvにのみ存在)
・Pclass : チケットのクラス
・Name : 名前
・Sex : 性別
・Age : 年齢
・SibSp : 兄弟又は配偶者の人数
・Parch : 両親又は子供の人数
・Ticket : チケット番号
・Fare : 搭乗料金
・Cabin : 搭乗キャビン種別
・Embarked : 乗客が船に搭乗した地名
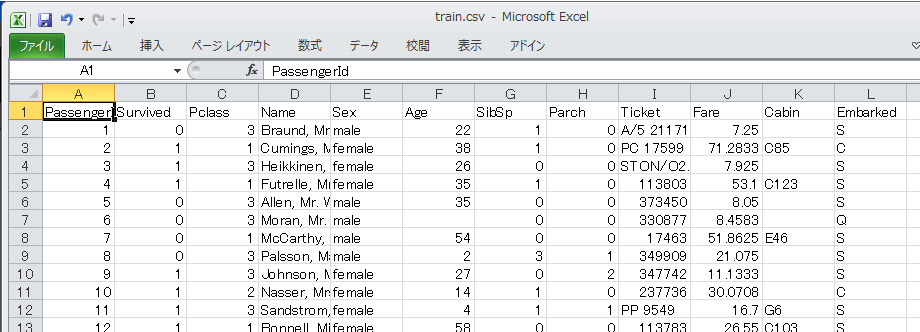
Excel で開いてみると、次のような感じのデータが並んでいます。セルに値が無いのは欠損しているデータです。
学習用アルゴリズムの実装
先に実装した three_layer_neural_net を利用して、学習をまわすためのスクリプトを次のように作成します。
# !/usr/bin/env python
import numpy as np
import pandas as pd
from three_layer_neural_net import ThreeLayerNet
import time
from random_generator import *
### ①データ前処理 ###
df = pd.read_csv("input/train.csv")
del df["Name"]
del df["Ticket"]
del df["Cabin"]
df["Sex"].replace("male", 0, inplace=True)
df["Sex"].replace("female", 1, inplace=True)
df["Embarked"].replace("Q", 0, inplace=True)
df["Embarked"].replace("S", 1, inplace=True)
df["Embarked"].replace("C", 2, inplace=True)
df["Embarked"].fillna(1, inplace=True)
nan_list = np.array(df[["PassengerId","Age"]][df.isnull().any(axis=1)]) # NaN を含むカラムを抽出
for i in range(len(nan_list)):
df.loc[nan_list[i][0]-1:nan_list[i][0]-1]["Age"].fillna(genrandom(piecewise_uniform, [0, 80], [0, 1]), inplace=True)
del df["PassengerId"]
x_train = np.array(df.drop("Survived", axis=1))[:800]
x_test = np.array(df.drop("Survived", axis=1))[800:]
array_train_label = np.empty((0,2), int)
for i in np.array(df["Survived"]):
if i == 0: array_train_label = np.append(array_train_label, np.array([[1,0]]), axis=0)
elif i == 1: array_train_label = np.append(array_train_label, np.array([[0,1]]), axis=0)
t_train = array_train_label[:800]
t_test = array_train_label[800:]
# ②ハイパーパラメタ
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 50
learning_rate = 0.005
# ③正解率表示用の空配列
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(round(train_size / batch_size), 1)
# ④ニューラルネット学習の実装
network = ThreeLayerNet(input_size = 7, hidden_size = 120, output_size = 2)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grad = network.numerical_gradient(x_batch, t_batch)
for key in ("W1", "b1", "W2", "b2"):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# ⑤1エポック毎に、学習用データとテストデータでの正解率を表示
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(time.ctime() + "train acc : " + str(train_acc) + " || test acc : " + str(test_acc))
コメント部分を簡単に説明します。
①Kaggleから取得したデータセット(train.csv, データ数891)を前処理しています。
(前処理の方針については次節に書きます)
ここでデータ加工した結果として、学習用データを x_train、学習用ラベルを t_train、テスト用データを x_test、テスト用ラベルを t_test としてnumpy配列に変換しています。
入力データは7次元Numpy配列、出力データは2次元Numpy配列です。
②ハイパーパラメタの指定をしています。
適当に色々といじって試したところ、学習率0.005 で、中間層のニューロンが120個の時がそこそこマシな結果となりました。
③,⑤学習中に進捗が見えないと精神衛生上好ましくないので、1エポック毎に正解率を表示します。
④肝心のニューラルネット学習の実装部分です。
学習用データからバッチサイズ分をランダムに選んで、まとめて勾配法を適用しています。
指定したイテレーション回数分これを実行します。
このスクリプトをまわすことで、重みパラメータの値がいい感じに調整され、良い分類器ができあがることを期待するわけです。
学習用データの前処理
今回実施した学習用データの前処理の方針について説明します。
このあたり本来は最も頭を使うべきところですが、、、一旦今回は下記のような方針でデータ加工を施しました。
※余談ですが、Pandasの操作に慣れていないためか、この部分が一番苦労しました。。。
・前半800個を学習用データに、後半91個を過学習していないかのテスト用データとして利用
・もともと数値データとなっている部分はそのまま使う
・"PassengerId","Name","Ticket","Cabin" のカラムは削除
・"Sex" では male=0, female=1 に置換
・"Embarked" では Q=0, S=1, C=2 に置換
・"Age", "Embarked" の欠損値を補完(補完方法は後述)
恐らく NameとかSibSp, Parchとかとの関係を元に色々頑張って良い特徴量を作るのがベターなのでしょうが、そこまでの知識はないので今回はコレでいきます。
欠損値の補完方法についてですが、"Embarked" は欠損数が少なく(2個)、未欠損データのほとんどの値が ”S" なので、"1" で補完することにします。
”Age”は欠損数が170個以上とかなり高い割合になっています。欠損値へのデータ補完方法は、例えば0や平均値や最頻値で埋めるとか、データそのものを削るとかがあるようですが、今回のようなケースにそれを適用するのは望ましくないような気がします。例えば、欠損していないデータの年齢の平均は約27歳ですが、全ての欠損値を27で埋めると乗客全体の20%以上が27歳ということになってしまいます。
ここでは、未欠損データの年齢の分布に(近似的に)従う乱数を生成して、それでもって欠損値を埋めることにします。
まずは未欠損データの分布をみるためにヒストグラムにプロットしてみます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("input/train.csv")
df.dropna(subset=["Age"], inplace=True)
y = np.append(np.array(df["Age"]), 0.0)
plt.hist(y, bins=16)
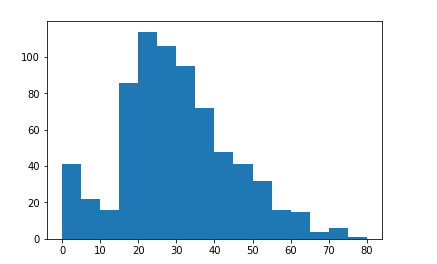
結構いびつな分布の形をしています。全体的に右に裾が長い2つ山の分布をしているようです。
これを連続的な確率密度関数でうまいこと近似する方法を検討しましたが、私の実装力が足りないためそれは諦めました。
代わりに、定義域を年齢層ごとに分けて、区分的に一様分布に従う乱数生成器を実装してみます。この乱数生成器で作られた乱数で欠損値を埋めようと思います。
具体的には、定義域を16個の区間に分割し、各区間上では区間内のデータ数の合計を返す定数関数(を正規化したもの)を分布関数として使います。最高齢の乗客は80歳なので、定義域は5歳毎に分割することになります。
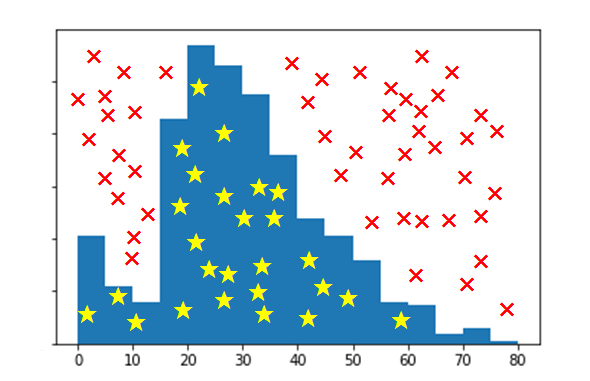
イメージ的には下記の図のように、まず一様乱数を生成して、それが★マークにあたるなら採用、×マークにあたるなら不採用としてもう一回一様乱数生成から繰り返すような感じです。
例えば、0~5歳の乗客は41人で、未欠損データ数が715なので、41/715 ≒ 5.7% となります。
この考え方で、求める乱数生成器を次のように実装します。
import numpy as np
# 区分的に一様な確率密度関数
def piecewise_uniform(x):
sections = [[i, i+5] for i in range(0, 80, 5)] # [0,80]を16個の区間に分割
nums = [ 41., 22., 16., 86., 114., 106., 95., 72., 48., 41., 32., 16., 15., 4., 6., 1.] # この区間における実データ(train.csv)の度数分布
for i in range(len(sections)):
if sections[i][0] <= x and x <= sections[i][1]:
return (nums[i] / (5 * np.sum(nums)))
# 乱数生成器を作成
def genrandom(func, domain, value_range):
while(1):
# 乱数ペア(x_candidate, y_candidate) を生成
x_candidate = domain[-1] * np.random.uniform(0,1)
y_candidate = value_range[-1] * np.random.uniform(0,1)
# y_candidate が上の確率密度関数の値より小さかったら採用
if y_candidate <= func(x_candidate):
return x_candidate
この乱数生成器を用いて欠損値を補完し、補完後の年齢データの分布を確認してみます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from random_generator import *
df = pd.read_csv("input/train.csv")
nan_list = np.array(df[["PassengerId","Age"]][df.isnull().any(axis=1)]) # NaN を含むカラムを抽出
for i in range(len(nan_list)):
df.loc[nan_list[i][0]-1:nan_list[i][0]-1]["Age"].fillna(genrandom(piecewise_uniform, [0, 80], [0, 1]), inplace=True)
plt.hist(df["Age"], bins=16)
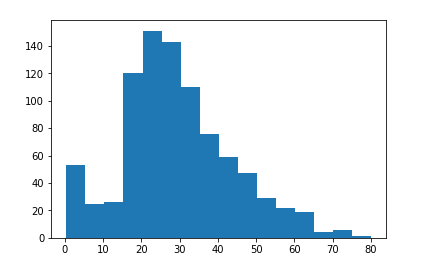
元の分布と似たような形状になり、いい感じにできました。
モデル構築
ではいよいよ分類モデルを作ります。
先ほどの train_neuralnet.py をまわしてデータを学習させます。
1エポック毎に時刻と学習率を表示しているので、学習中の学習状況がなんとなくみえます。
import train_neuralnet
Thu Mar 8 06:55:49 2018train acc : 0.615 || test acc : 0.6263736263736264
Thu Mar 8 06:55:58 2018train acc : 0.67625 || test acc : 0.6703296703296703
Thu Mar 8 06:56:08 2018train acc : 0.65875 || test acc : 0.7252747252747253
Thu Mar 8 06:56:18 2018train acc : 0.66875 || test acc : 0.6813186813186813
Thu Mar 8 06:56:27 2018train acc : 0.69375 || test acc : 0.6923076923076923
### ・・・中略・・・ ###
Thu Mar 8 07:05:32 2018train acc : 0.72875 || test acc : 0.7472527472527473
Thu Mar 8 07:05:41 2018train acc : 0.70375 || test acc : 0.7252747252747253
時間にして10分ほどで学習が終わりました。ちなみに利用したマシンはCPU 8コア / メモリ 30GB のGCPインスタンスです。GCPは初回登録時に利用制限無しの300$クーポンが付いてくるので助かります。
正解率の推移をみると、なんか70%くらいで割とすぐに頭打ちになってますね。。イテレーション数を上げてみても、あまり傾向に変化はありませんでした。
正解率の推移グラフも見てみます。
import matplotlib.pyplot as plt
import numpy as np
train_y = train_neuralnet.train_acc_list
train_x = range(len(train_y))
test_y = train_neuralnet.test_acc_list
test_x = range(len(test_y))
plt.plot(train_x,train_y)
plt.plot(test_x,test_y)
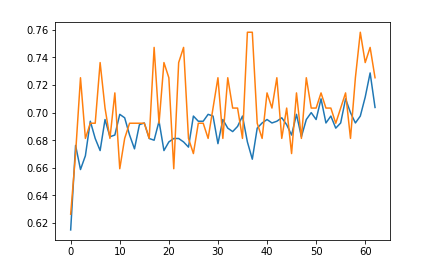
※青線が学習用データのもの、オレンジがテストデータのもの
学習後すぐは正解率が急上昇してますが、その後はなんか70%付近で暴れてますね。。
まぁ色々と妥協してココまできているので、その部分が出ているのでしょう。今後の課題です。
あとは、このモデルに、Submission用のテストデータを喰わせて結果を出します。
Kaggle Titanic テスト用データで未知のデータを予測
モデルへのテスト用データの投入
もうモデルは出来上がっているので、これにテスト用データを投入するだけです!
ちなみに先に言ってしまうと、あまり良い結果は得られませんでした!笑
まぁそれは置いといて、とりあえずテスト用データを整形してモデルに突っ込みます!
import pandas as pd
# テストデータ(test.csv)をモデルに投入できるように加工
# 学習用データのときと同じ方針で7次元の配列に整形する
df_sub = pd.read_csv("input/test.csv")
del df_sub["PassengerId"]
del df_sub["Name"]
del df_sub["Ticket"]
del df_sub["Cabin"]
df_sub["Sex"].replace("male", 0, inplace=True)
df_sub["Sex"].replace("female", 1, inplace=True)
df_sub["Embarked"].replace("Q", 0, inplace=True)
df_sub["Embarked"].replace("S", 1, inplace=True)
df_sub["Embarked"].replace("C", 2, inplace=True)
df_sub["Fare"].fillna(8.000, inplace=True) #1個だけある欠損値を適当な値で埋めた
test_array = np.array(df_sub) # DataFrame をNumpy配列に変換
# テストデータをモデルに投入
result_raw = train_neuralnet.network.predict(test_array)
result_raw の中身は下記のように float の2次元リストになっているので、これをSubmission用に整形します。
array([[0.83904342, 0.16095658],
[0.84114569, 0.15885431],
[0.80675882, 0.19324118],
[0.81586437, 0.18413563],
[0.6969788 , 0.3030212 ],
### ・・・・(後略)
具体的には、0番目の数字の方が大きい場合は死亡を表すとして "Survived : 0" に、1番目の数字のほうが大きい場合は生還を表すとして "Survived : 1" に、という風に整形します。このようにして作ったSubmission用のCSVファイルを predict_result_data.csv として保存します。(手順は省略)
ちなみに作成した predict_result_data.csv の中身は下記のようになっています。
PassengerId,Survived
892,0
893,0
894,0
895,0
896,0
897,0
898,0
899,0
900,0
901,0
902,0
903,0
904,1
905,0
906,1
### ・・・・(後略)
予測結果をSubmit
いよいよ結果をSubmitします!テンション上がってきました!!
ちなみに実は以前、試しに何も考えず適当に作ったCSVファイルでSubmitしてみたら順位が10000位ぐらいだったので、さすがにそれは超えたいところです。
コンペトップページ右にある、"Submit Prediction" をクリックするとアップロードページに飛ぶので、ここにCSVファイルをドラッグ&ドロップします。
アップロードが完了したら、"Make Submission" をクリック!
すると、即座に予測精度と順位が表示されます。
アップロード画面
アップロードの説明を記入して "Make Submission" をクリック
結果はどうかというと・・・・

精度64.593% で9,713位でした。低!!
しかしまぁ、仮にランダムに 0 or 1 を選んだとしたらこの精度に達成するのは統計的にほぼ不可能だし、試しに全てのデータを 0 にすると正解率は 0.62679 だったので、少しは意味のある分類器を作れたということで笑
今回はニューラルネットワークの理解を深めたかったのと、Kaggleの一連の流れを把握したかったことが動機なので、一通りやりきれたので結果はこれで良しとします。
終りに
今回は、途中で色々と妥協した部分もあったので、今後はそのあたりを詰めてモデルを改良したり、ニューラルネットとは違う手法を使ったりして知識を広げたいと思います。
冒頭書いたように、Titanicコンペはチュートリアル的位置付けですが、用意されたデータはとても良くできていたのではと思います。(素人意見ですが)
手を動かして一通りこなすことで、データ分析という行為の流れと悩みどころがなんとな~く理解できました。
また、ゲーム的な感覚で結構達成感もあって面白いので(結果は残念でしたが笑)、今後もがんばってやっていきます!