この記事について
Protocol Buffers(以下、protobuf) はデータをシリアライズする際に、JSON や XML のようなテキスト形式ではなくバイナリ形式にシリアライズします。 この記事ではこのバイナリの形式、いわゆる Wire Format についてまとめます。
protobuf の Wire Format の概要
Wire Format には、*.proto ファイルで定義されたメッセージ内の各フィールドごとに次の情報が格納されます。
- フィールドの番号
- 型情報(Wire Type)
- データ長、または、データの終了マーク
- データの値
以下、各項目の説明。
フィールドの番号
ドキュメントによってフィールド番号(field number)やタグ(tag)と書かれているが、要はフィールドの識別子。 int32 a = 1; と定義した際の 1 のこと。Wire Format に変数名が含まれてないことから分かるように、各フィールドはこの番号によって識別されるという大事なもの。
型情報(Wire Type)
protobu で定義されている int32、string、bool などのデータ型ではなく、Wire Format にデータを格納するために用いられる際の型であり、Wire Type と呼ばれる。
データ長、または、データの終了マーク
Wire Type によって変わるが、データ長そのものか、データの継続・終了を示すビットが付けられる。
データの値
各フィールドにセットされた値。コードで書いた値そのままの場合もあるし、特殊なエンコードをしてから格納される場合もある。
例
*.proto ファイルで以下のメッセージが定義されており、プログラムコードで a = 200, b = "hello" という値をセットしたとする。
message Data {
int32 a = 1;
string b = 2;
}
これを protobuf の Wire Format にシリアライズすると 08 c8 01 12 05 68 65 6c 6c 6f というバイナリになる。見方は後述するが、このバイナリには以下のように各フィールド(この例の a, b)の情報が格納されている。
-
08 c8 01- フィールド番号: 1 (つまり
a) - Wire Type: 0 (Varint)
- データの値: 200
- フィールド番号: 1 (つまり
-
12 05 68 65 6c 6c 6f- フィールド番号: 2 (つまり
b) - Wire Type: 2 (Length-delimited)
- 長さ: 5バイト
- データの値: "hello"
- フィールド番号: 2 (つまり
Wire Format に含まれない情報
すでに記載したが、.proto ファイルで定義した「変数名」や「変数の型」は含まれない。これらは、デシリアライズする側が Wire Format のフィールド番号とメッセージの定義(.protoファイルによる定義)を参照しながら決定する。
原文の方が分かりやすいので、以下に引用。
As you know, a protocol buffer message is a series of key-value pairs. The binary version of a message just uses the field's number as the key – the name and declared type for each field can only be determined on the decoding end by referencing the message type's definition (i.e. the .proto file).
Wire Format の詳細
メッセージの形式
メッセージの各フィールドは、次のいずれかの形式にシリアライズされる。
| フィールド番号、Wire Type | データ(バイト列) |
|---|
| フィールド番号、Wire Type | データ長 | データ(バイト列) |
|---|
- データ長の有無は Wire Type によって変わる
- フィールドが複数ある場合はこれらの構造が連続して現れる。
Wire Type、特に Varint が分からないと話が進まないので、まずそれから説明する。
Wire Type
Wire Format で利用可能な型(Wire Type)には以下のものがある(Encoding から引用)。
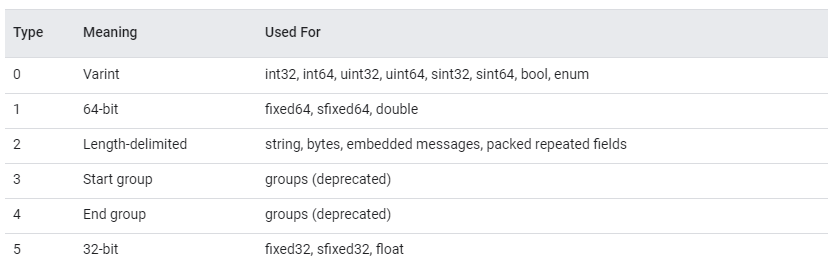
この中で Wire Format の土台になっているのが Varint。
Wire Type 0 : Varint
Varintは Wire Format の土台となる型であり、基本的には1バイト以上の整数を格納できる。あるルールに従って整数を格納するので、型でもあり、エンコーディング方式ともいえる。
この Varint はもちろんデータ値を格納するのに使うが、それだけでなく、Wire Format に「フィールドの番号」「Wire Type」「データ長」を格納する際、それら自体が Varint の形式で格納される、という特別なもの。
次の特徴がある。
- 各バイトの最上位ビット(MSB)は、後続のバイトの有無を示すフラグになっている
- 各バイトの下位7bitにデータが入れられる
- 各バイトは little endian の順で並ぶ
これだけだと分からないので、以下に具体例を記載する。
-
例1) データ値が1の場合、Varint での表現は
0000 0001- 最上位ビットは立っていないでの後続のバイトは無い(1バイトのみ)
- 最上位ビットを落とした
000 0001が値になる → つまり 1
-
例2) データ値が200の場合、Varint での表現は
1100 10000000 0001- 1バイト(最上位ビットを省く7ビット)には収まらないので2バイトになる
- 1バイト目の最上位ビットは後続データがあるので立っているが、2バイト目は立ってない(最終バイトであることを示す)
- 以下のように解釈する
- 各バイトの最上位ビットを落とす :
100 1000000 0001 - バイトの並び順を逆にする :
000 0001100 1000 - そのまま2進数
1100 1000として解釈する → つまり 200
- 各バイトの最上位ビットを落とす :
フィールド番号、Wire Type
「フィールド番号」と「Wire Type」はひとまとめにして1つの Varint として Wire Format に格納されるため、Varint が分かるとこれらを解釈できるようになる。
- 下位3bit が Wire Type
- その上位4ビットがフィールド番号
具体例:
-
0000 1000の場合- 最上位ビットが立ってないので後続のバイトは無し
- Wire Type(下位3bit) は
000、つまり0。これは Type 0 の Varint を表す。 - フィールド番号(最上位ビットは省く4ビット)は
000 1、つまり 1。
-
0001 0010の場合- 最上位ビットが立ってないので後続のバイトは無し
- Wire Type(下位3bit) は
010、つまり 2。これは Type 2 の Length-delimited を表す。 - フィールド番号(最上位ビットは省く)は
001 0、つまり 2。
その他の Wire Type
Wire Type 2 : Length-delimited
Wire Type 2 は、varint 形式でデータ長と、それに続いて実データが格納される形式。
- 例) string のフィールドに
helloをセットしたら12 05 68 65 6c 6c 6fとシリアライズされた場合- 先頭1バイト
12は varint 形式の「フィールド番号、Wire Type」- フィールド番号: 2
- Wire Type: 2 (Length-delimited)
- 次の1バイト
05は varint 形式の「データ長」- データ長: 5バイト
- 最後の5バイト
68 65 6c 6c 6fが値- 値: "hello" の UTF-8 表現
- 先頭1バイト
その他の補足
-
Wire Format には変数名は含まれておらずフィールド番号で識別するので、例えばクライアントとサーバーが参照する *.proto に差異がありフィールド番号が異なっていると、誤った解釈をする場合がある。
-
デシリアライズする側は、自分の知らないフィールド番号が渡された場合にそれをスキップする。これにより、既存のプログラムに影響を与えずに新しいフィールドを追加できる。以下原文。
When the message is being decoded, the parser needs to be able to skip fields that it doesn't recognize. This way, new fields can be added to a message without breaking old programs that do not know about them.
- Go言語の場合、
*.protoファイルを Protocol Buffers コンパイラ(protoc) でコンパイルすると以下のような*.pb.goファイルが生成される。struct のタグに埋め込まれてる数値、例えばprotobuf:"bytes,1,opt...の1がフィールド番号を表している。
type Person struct {
// 中略
Name string `protobuf:"bytes,1,opt,name=name,proto3" json:"name,omitempty"`
Id int32 `protobuf:"varint,2,opt,name=id,proto3" json:"id,omitempty"`
Email string `protobuf:"bytes,3,opt,name=email,proto3" json:"email,omitempty"`
Phones []*Person_PhoneNumber `protobuf:"bytes,4,rep,name=phones,proto3" json:"phones,omitempty"`
LastUpdated *timestamp.Timestamp `protobuf:"bytes,5,opt,name=last_updated,json=lastUpdated,proto3" json:"last_updated,omitempty"`
}
- Wire Format には、フィールド番号順に格納されるとは限らない。フィールド番号順であると想定しないこと。