APIを使うために
e-StatのAPIを使うための準備として、アプリケーションIDの取得とAPI仕様の概要について確認しておきます。
アプリケーションIDの取得
APIを使うためにはアプリケーションIDを取得する必要があります。取得してください。
政府統計の総合窓口(e-Stat)−API機能に手順が説明されているので、詳細は割愛します。
アプリケーションIDの管理
APIの利用そのものと直接関係はありませんが、アプリケーションIDのような情報をスクリプト中に直接書くのは嫌ではないでしょうか。私は嫌です。
そこで今回はkeyringパッケージを利用してアプリケーションIDを管理することにします。パッケージをインストールした上で、次の関数を実行するとパスワード入力欄が表示されます。
# install.packages("keyring")
keyring::key_set("e-stat")
ここにアプリケーションIDを入力してOKをクリックすれば準備完了です。次のようにkey_get()関数を呼び出せば、入力したアプリケーションIDが返ってきます。
keyring::key_get("e-stat")
詳しくはkeyringパッケージで認証情報を管理する - Qiitaも参照してください。
これ以降に示す例では、アプリケーションIDが必要な部分にはkeyring::key_get("e-stat")と記述します。何らかの理由でkeyringを使いたくない場合は、該当部分に直接アプリケーションIDを文字列として記述してください。
7つのe-Stat API
e-StatのAPIは1.0、2.0、2.1の3つのバージョンが公開されており、最新のバージョン2.1には7つのAPIが含まれています。詳しい仕様は、バージョン2.1なら政府統計の総合窓口(e-Stat)のAPI 仕様 2.1版 | 政府統計の総合窓口(e-Stat)−API機能から確認できます。APIを利用する際には適宜仕様を確認することになると思いますが、7つのAPIの機能と役割をざっくり説明すると次のようになります。
- 統計情報取得API ... 統計表の情報をキーワードなどで検索し、取得します。このAPIで取得できる統計表IDを使ってそれぞれの統計表に含まれるデータの取得が可能です。
- メタ情報取得API ...統計表のメタ情報を取得します。メタ情報には、統計表のタイトルや分類などの情報や、カテゴリカルな項目にどのような水準があるか、といった情報が含まれています。カテゴリカル項目の詳しい情報が必要な場合は使用したくなるかもしれません。
- 統計データ取得API ... 統計表IDを指定することで、データを取得できます。おそらくこのAPIを使う機会が最も多いと思います。
- 統計データ一括取得API ... 複数の統計表IDを指定することで、複数の統計表データを一括取得できます。便利なようですが少し癖があり、有効に活用できる場面はあまり多くないかもしれません。
- データセット登録API ... 統計データ取得時の絞り込み条件を登録するAPIです。登録した条件を他のユーザーに公開することもできるようです。私は使用したことがありません。
- データセット参照API ... データセット登録APIで登録した絞り込み条件を参照するAPIです。こちらも私は使用したことがありません。
- データカタログ情報取得API ...ExcelやPDFしか提供されていないデータセットは上記6つのAPIでは対応ができませんが、データカタログ情報取得APIを使用すれば、このようなデータセットを検索することができます。API出力にはExcelファイル等のデータリソースをダウンロードするためのURLが含まれているので、ファイルを一括ダウンロードするようなこともできます。
それぞれのAPIは出力形式に応じてさらに何種類かに分かれます。バージョン2.1ではいずれのAPIもJSONでの出力に対応しており、統計データ取得APIについてはCSV形式での出力に対応しているので、必要に応じてJSONかCSVのどちらかを利用すれば良いでしょう。
e-Stat API利用の一般的な流れ
APIは概ね以下のような流れで利用するものと心得ておきましょう。
- 取得対象のデータはDB形式で提供されているか?
- Yes.
- 統計情報取得APIで統計表IDを取得する。統計表IDは統計表のURLの一部にもなっているので、取得対象の統計表が少数でURLも分かっているならURLを確認して利用しても良いでしょう。
- 統計データ取得APIでデータを取得する。場合によっては統計データ一括取得APIが活用できるかもしれません
- No.
- データカタログ情報取得APIでデータリソースのURLを取得する。
- データリソースをダウンロードする。
- Yes.
取得そのものはそれほど難しくありません。
地獄は、入り口をくぐるだけなら簡単なのです。
RからAPIを使う
では、RからAPIを叩いていきましょう。例としてまずは犯罪統計の取得を目指してみます。
httrパッケージでAPIを叩く
今回はhttrパッケージを使用します。httrには各種リクエストに対応したGET()やPOST()といった関数が用意されています。e-Stat APIのHTTPメソッドは大半がGETですが、データセット登録APIと統計データ一括取得APIはPOSTです。注意しましょう。
まずは統計情報取得APIを使って統計表IDを取得するところをやってみましょう。GET()関数を用い、リクエストURLをurl=に、パラメータをquery=にリストで渡します。
library(httr)
response <- GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/json/getStatsList",
query = list(
appId = keyring::key_get("e-stat"),
searchWord = "犯罪統計 AND 刑法犯"
)
)
response
Response [https://api.e-stat.go.jp/rest/2.1/app/json/getStatsList?appId=...]
Date: 2019-01-17 22:30
Status: 200
Content-Type: application/json; charset=utf-8
Size: 4.07 kB
はい。無事に取得できました。次はレスポンスの中身を取り出します。
レスポンスの中身を確認する
レスポンスボディにはcontents()関数でアクセスできます。この関数は賢いので、Content-Typeに応じてコンテンツを適当にパースしてRのオブジェクトに変換してくれます。今回の例ではJSONが返ってきていますが、これはネストしたリストに変換されます。
が、ネストしたリストをそのままRで表示したり構造を確認したりするのは割と辛い作業です。ここはlistviewerパッケージの力を借りることにします。listviwerのjsonedit()関数やreactjson()関数を使うと、深くネストしたリストでもあまり苦痛を伴わずに中身を探索できます。では中身を見てみましょう。
library(listviewer)
res_content <- content(response)
jsonedit(res_content)
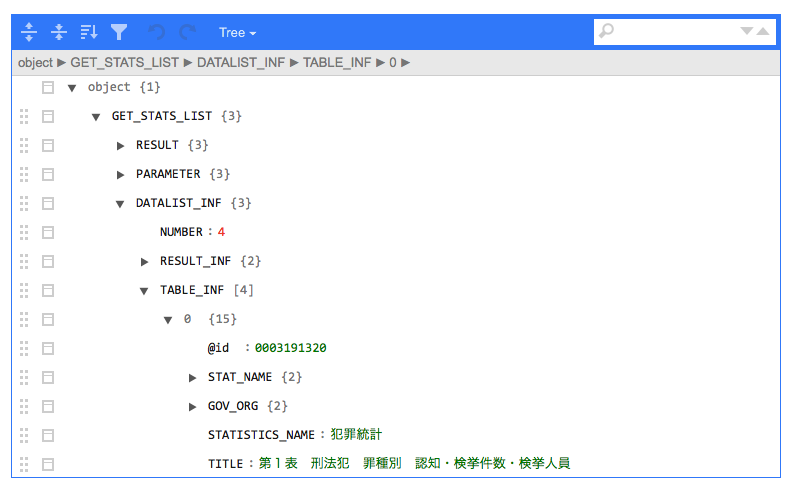
どうやら$GET_STATS_LIST$DATALIST_INF$TABLE_INF以下に統計表の情報がはいっているようです(ちなみにこれはAPIの仕様をよく確認すれば分かることではあります)。この中には各統計表毎に類似した構造を持ったリストが入っています。次の仕事はこのリストの要素を効率的に取り出して構造化することです。特に重要なのは統計表IDで、これは@idに格納されています。@がついているので、要素を指定する際にはバッククォートで括るのを忘れないようにしましょう。
rlistでリストを操作する
リストを扱う方法はいろいろありますが、今回はrlistパッケージを利用します(他には自分で関数を書いたり、purrrを使うといった手があります)。rlistはリストの操作を容易にしてくれるパッケージです。パイプ演算子と親和性が高く、組み合わせることでより洗練された記述が可能となります。ただし、magrittrに由来するパイプ演算子%>%だと時々シンボルが衝突して問題が起こることがあります。rlistを使う場合はpipeRパッケージによるパイプ演算子%>>%を使う方が安全です。%>>%の使い方は%>%とほとんど変わらないので、特に混乱することは無いでしょう。
rlistの機能を細かく説明すると長くなるので(細かい説明を知りたければrlistの短めチュートリアル - Qiitaを参照してください)、今回の目的のために必要な操作を簡単に説明します。
まず、要素の取り出しはlist.map()で行います。この関数はリストの階層を一つ降りた文脈で与えられた式を評価します。つまり、リスト内のサブリストそれぞれで式が評価されることになります。そして、評価結果を要素として持つリストを生成します。次の例では、$TABLE_INF以下に含まれる4つのサブリストそれぞれで@idを評価することで、統計表IDを抽出しています。
library(rlist)
library(pipeR)
res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.map(`@id`)
[[1]]
[1] "0003191320"
[[2]]
[1] "0003191340"
[[3]]
[1] "0003194968"
[[4]]
[1] "0003195002"
rlistの関数には末尾にvのついたバージョンが用意されているものがあり、これを使うとベクトルで返り値を得ることもできます。
res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.mapv(`@id`)
[1] "0003191320" "0003191340" "0003194968" "0003195002"
統計表IDだけを抽出してもどのIDがどの統計表に対応するかがわかりません。統計表の名前も一緒に抽出してみましょう。統計表の名前は各統計表情報のリスト内、$TITLE_SPEC$TABLE_NAME内に入っています。
このような場合はlist.select()を利用します。この関数はサブリスト内の文脈で式を評価し、評価結果を組み合わせた新しいリストを生成します。dplyrに馴染みがある方は、transmute()のようなものと考えると良いでしょう。
res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.select(
id = `@id`,
table_name = TITLE_SPEC$TABLE_NAME
)
[[1]]
[[1]]$id
[1] "0003191320"
[[1]]$table_name
[1] "第1表 刑法犯 罪種別 認知・検挙件数・検挙人員"
[[2]]
[[2]]$id
[1] "0003191340"
[[2]]$table_name
[1] "第1表 刑法犯 罪種別 認知・検挙件数・検挙人員 対前年比較"
[[3]]
[[3]]$id
[1] "0003194968"
[[3]]$table_name
[1] "第3表 刑法犯総数 都道府県別 認知・検挙件数・検挙人員 対前年比較"
[[4]]
[[4]]$id
[1] "0003195002"
[[4]]$table_name
[1] "第3表 刑法犯総数 都道府県別 認知・検挙件数・検挙人員"
ここまで来たらデータフレームにしたいところですね。これは、list.stack()で実現できます。この関数は、要素数と要素毎の型が等しいリストを結合してデータフレームにしてくれます。
res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.select(
id = `@id`,
table_name = TITLE_SPEC$TABLE_NAME
) %>>%
list.stack()
| id | table_name |
|---|---|
| 0003191320 | 第1表 刑法犯 罪種別 認知・検挙件数・検挙人員 |
| 0003191340 | 第1表 刑法犯 罪種別 認知・検挙件数・検挙人員 対前年比較 |
| 0003194968 | 第3表 刑法犯総数 都道府県別 認知・検挙件数・検挙人員 対前年比較 |
| 0003195002 | 第3表 刑法犯総数 都道府県別 認知・検挙件数・検挙人員 |
結果の絞り込み
今回の例は4件しか結果がありませんでしたが、もっと多数の結果から絞り込みを行いたい場合もあるかと思います。例えば今回の例で「対前年比較の表は要らない」と考えた場合、どうすべきでしょうか。
これにはいくつかやり方が考えられます。
- リストをデータフレームにしてから
dplyr::filter()で絞り込む - レスポンスのリストを
rlist::list.filter()で絞り込む - APIを叩く段階で絞り込む
順に見ていきましょう。
1. リストをデータフレームにしてから絞り込む
dplyrでの操作に慣れていればこれが簡単だと思います。先程の結果をfilter()で絞り込むだけです。
library(dplyr)
res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.select(
id = `@id`,
table_name = TITLE_SPEC$TABLE_NAME
) %>>%
list.stack() %>%
filter(!grepl("対前年比較", table_name))
| id | table_name |
|---|---|
| 0003191320 | 第1表 刑法犯 罪種別 認知・検挙件数・検挙人員 |
| 0003195002 | 第3表 刑法犯総数 都道府県別 認知・検挙件数・検挙人員 |
リストの段階で絞り込む
rlistの関数であるlist.filter()を使います。この関数は、与えられた式をサブリストの文脈で評価し、結果が真となるサブリストのみを返却します。統計表IDだけを抽出する場合など、データフレームにする必要がない場合には処理がコンパクトにできて有効です。
res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.filter(!grepl("対前年比較", TITLE_SPEC$TABLE_NAME)) %>>%
list.mapv(`@id`)
[1] "0003191320" "0003195002"
APIを叩く段階で絞り込む
統計情報取得APIには様々なパラメータが指定できます。慣れてきたらAPIの仕様を確認して何ができるのか把握していくと良いでしょう。
検索ワードの指定だけを見てもなかなか柔軟で、AND、OR、()を使った条件の組み合わせやNOTの指定も可能です。
response2 <- GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/json/getStatsList",
query = list(
appId = keyring::key_get("e-stat"),
searchWord = "犯罪統計 AND 刑法犯 NOT 対前年比較"
)
)
content(response2)$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.select(
id = `@id`,
table_name = TITLE_SPEC$TABLE_NAME
) %>>%
list.stack()
| id | table_name |
|---|---|
| 0003191320 | 第1表 刑法犯 罪種別 認知・検挙件数・検挙人員 |
| 0003195002 | 第3表 刑法犯総数 都道府県別 認知・検挙件数・検挙人員 |
この段階で絞り込みができれば受信するデータ量も削減できるので、ある程度絞り込み方法の目処がついたらリファクタリングとしてAPI段階での絞り込みに切り替えてもいいかもしれません。
RからAPIを使ってデータを取得する
ではいよいよデータの取得です。e-Statには様々なデータがあります。見やすく整理されたデータから理解に苦しむデータまでバラエティに富んでいます。分野というか、担当省庁ごとの特色がよく現れていると思います(もう農林水産業のデータをe-Statから取得するのは勘b...)。
いきなり高難易度に挑戦すると命に関わりかねないので、簡単なやつから慣れていきましょう。ここまで例として扱ってきた犯罪統計は構造が複雑でなく、サイズも手頃です。トリッキーな操作は必要なく、練習にうってつけと言えます。
統計データ取得APIを叩く
では、犯罪統計のなかの第1表を、統計表IDを直接指定する形で、CSV形式で取得するAPIを利用して取得してみます。
response <- GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/getSimpleStatsData",
query = list(
appId = keyring::key_get("e-stat"),
statsDataId = "0003191320"
)
)
response
Response [https://api.e-stat.go.jp/rest/2.1/app/getSimpleStatsData?...]
Date: 2019-01-23 12:31
Status: 200
Content-Type: text/plain; charset=utf-8
Size: 211 kB
"RESULT"
"STATUS","0"
"ERROR_MSG","正常に終了しました。"
"DATE","2019-01-23T21:31:11.527+09:00"
"RESULT_INF"
"TOTAL_NUMBER","2310"
"FROM_NUMBER","1"
"TO_NUMBER","2310"
"TABLE_INF","0003191320"
"STAT_NAME","00130001","犯罪統計"
...
はい。無事に取得できました。
しかし何やら不穏な感じです。このチラッと見えているものは我々の知っているCSVなのでしょうか…?なんで行ごとにフィールド数が違うんでしょうか…?
きちんとしたCSVにする
仕様を確認すると、どうも"VALUE"と書かれた行の後からデータ部分が始まるらしいということが分かります。
"VALUE"より前の部分はセクションヘッダと呼ばれており、統計表自体に関するいろいろな情報が入っています。これはsectionHeaderFlgに2を指定すると出力を抑制できるのですが、"VALUE"は残ります。いずれにせよ"VALUE"以前の部分を切り捨てないとCSVとして読み込めないわけです。
というわけでそのようにしましょう。
方法はいくつかありますが、例えばRの標準の関数であるread.csv()とsub()を使うなら次のようになります。
res_content <- content(response)
read.csv(text = sub('(?s).*"VALUE"\n', "", res_content, perl = TRUE))
cat01_code 認知.検挙件数.検挙人員 cat02_code 罪種 time_code 時間軸.年次. unit value
1 100 認知件数 100 刑法犯総数 2016000000 2016年 件 996120
2 100 認知件数 100 刑法犯総数 2015000000 2015年 件 1098969
3 100 認知件数 100 刑法犯総数 2014000000 2014年 件 1212163
4 100 認知件数 100 刑法犯総数 2013000000 2013年 件 1314140
5 100 認知件数 100 刑法犯総数 2012000000 2012年 件 1403167
6 100 認知件数 100 刑法犯総数 2011000000 2011年 件 1502951
...
コンテンツにセクションヘッダが含まれている場合は改行も含めて置換する必要があるので、正規表現の書き方に少し工夫が必要です。例示したsub()では、Perl互換モードを有効にした上で、パターンの頭に(?s)を付加しています。これは正規表現のパターン修飾子/sを指定したのと同じで、いわゆるシングルラインモードにする効果があります。すなわち、.が改行も含めた全ての文字にマッチするようになります。
なお、sectionHeaderFlgに2を指定してセクションヘッダの出力を抑制してしまえば、次のような単純な置換で事が済みます。セクションヘッダに含まれる情報が不要であればこちらのほうが良いでしょう。
read.csv(text = sub('"VALUE"\n', "", res_content))
あるいはreadr::read_csv()とstringr::str_replace()を使って今風にやるならこんな感じになるでしょう。これなら列名に含まれる・や()が.に置換されてしまうこともありません。
stringr::str_replace(res_content, '(?s).*"VALUE"\n', '') %>% readr::read_csv()
# A tibble: 2,310 x 8
cat01_code `認知・検挙件数・検挙人員` cat02_code 罪種 time_code `時間軸(年次)` unit value
<dbl> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
1 100 認知件数 100 刑法犯総数 2016000000 2016年 件 996120
2 100 認知件数 100 刑法犯総数 2015000000 2015年 件 1098969
3 100 認知件数 100 刑法犯総数 2014000000 2014年 件 1212163
4 100 認知件数 100 刑法犯総数 2013000000 2013年 件 1314140
5 100 認知件数 100 刑法犯総数 2012000000 2012年 件 1403167
6 100 認知件数 100 刑法犯総数 2011000000 2011年 件 1502951
7 100 認知件数 100 刑法犯総数 2010000000 2010年 件 1604019
8 100 認知件数 100 刑法犯総数 2009000000 2009年 件 1713832
9 100 認知件数 100 刑法犯総数 2008000000 2008年 件 1826500
10 100 認知件数 100 刑法犯総数 2007000000 2007年 件 1908836
# ... with 2,300 more rows
カテゴリコードとメタ情報取得APIの活用
取得されたデータを見ると分かるように、それぞれのカテゴリカルな項目にはコードが付与されています。先にも説明したように、統計データ取得APIでデータを取得する段階で、取得するデータの絞り込みが可能です。そして、そのためにこのカテゴリコードが利用できます。例えばcat01_codもcat02_codeも100のデータだけで良いという場合は、次のようにやります。
GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/getSimpleStatsData",
query = list(
appId = keyring::key_get("e-stat"),
statsDataId = "0003191320",
sectionHeaderFlg = 2,
cdCat01 = "100",
cdCat02 = "100"
)
) %>% # ついでにデータフレームにしてしまいます
content %>%
stringr::str_replace('"VALUE"\n', '') %>%
readr::read_csv()
# A tibble: 11 x 8
cat01_code `認知・検挙件数・検挙人員` cat02_code 罪種 time_code `時間軸(年次)` unit value
<dbl> <chr> <dbl> <chr> <dbl> <chr> <chr> <dbl>
1 100 認知件数 100 刑法犯総数 2016000000 2016年 件 996120
2 100 認知件数 100 刑法犯総数 2015000000 2015年 件 1098969
3 100 認知件数 100 刑法犯総数 2014000000 2014年 件 1212163
4 100 認知件数 100 刑法犯総数 2013000000 2013年 件 1314140
5 100 認知件数 100 刑法犯総数 2012000000 2012年 件 1403167
6 100 認知件数 100 刑法犯総数 2011000000 2011年 件 1502951
7 100 認知件数 100 刑法犯総数 2010000000 2010年 件 1604019
8 100 認知件数 100 刑法犯総数 2009000000 2009年 件 1713832
9 100 認知件数 100 刑法犯総数 2008000000 2008年 件 1826500
10 100 認知件数 100 刑法犯総数 2007000000 2007年 件 1908836
11 100 認知件数 100 刑法犯総数 2006000000 2006年 件 2050850
列名とパラメータ名が違ってややこしいですね。慣れないうちは都度都度仕様を確認するようにしましょう。
このカテゴリコードの情報をもう少し詳しく知りたい場合にメタ情報取得APIが使えます。
まず、カテゴリは複雑な階層構造を構成している場合が少なくない、ということを把握しておきましょう。例えば今回の例なら「刑法犯総数」には「凶悪犯」の数が含まれていますし、「凶悪犯」には「凶悪犯_強盗」が含まれていたりします。上手く集計をするには、この分類レベルの階層を揃えることが重要です。
例として「罪種」について、「凶悪犯」「粗暴犯」といった少し粗いカテゴリでのデータが欲しい、合計は要らない、という状況を考えてみましょう。このときはまずメタ情報取得APIでメタ情報を取得し、次に「特定の分類レベル」に対応するカテゴリのを抽出し、そのカテゴリのコードでデータをフィルタリングする、といった作業を行います。
まずはjsonedit()でレスポンスの構造を確認してみましょう。
GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/json/getMetaInfo",
query = list(
appId = keyring::key_get("e-stat"),
statsDataId = "0003191320"
)
) %>% content -> meta_content
jsonedit(meta_content)
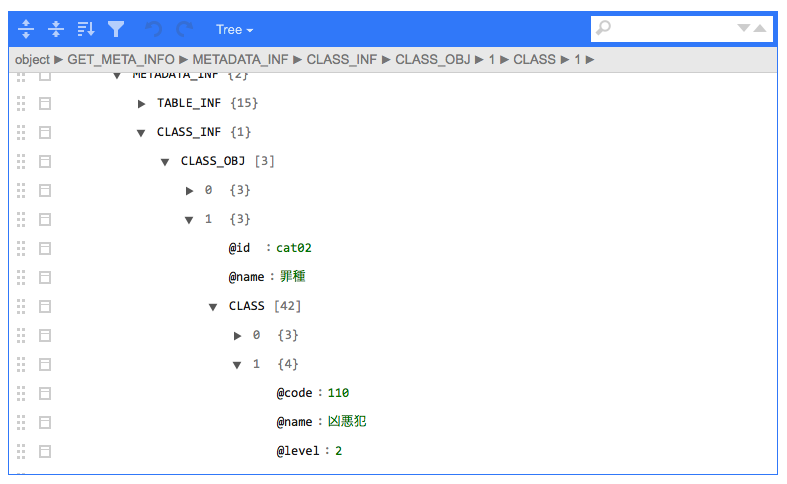
どうやら$GET_META_INFO$METADATA_INF$CLASS_INF$CLASS_OBJ以下にカテゴリの情報が入っているらしいことがわかります。このリストの中で「罪種」に関する部分を抽出し、さらにCALSSを@levelが2のものだけをフィルタリングすれば目的のカテゴリが取得できそうです。
ではrlistでやっていきましょう。
meta_content$GET_META_INFO$METADATA_INF$CLASS_INF$CLASS_OBJ %>>%
list.filter(`@name` == "罪種") %>>%
list.map(CLASS) %>>%
list.ungroup() %>>%
list.filter(`@level` == 2) %>>%
list.stack() -> lv2cat
lv2cat
@code @name @level @parentCode
1 110 凶悪犯 2 100
2 160 粗暴犯 2 100
3 230 窃盗犯 2 100
4 270 知能犯 2 100
5 390 風俗犯 2 100
6 440 その他の刑法犯 2 100
できました。このようにして取得、加工したメタ情報を利用すれば、データのフィルタリングが容易になります。
最後に、せっかくなので取得したデータをプロットして終わりたいと思います。
library(ggplot2)
stringr::str_replace(res_content, '(?s).*"VALUE"\n', '') %>%
readr::read_csv() %>%
filter(cat01_code == "100", cat02_code %in% lv2cat$`@code`) %>%
ggplot(aes(x = `時間軸(年次)`, y = as.numeric(value), group = 罪種)) +
geom_line() +
scale_color_discrete(name = "罪種") +
scale_y_continuous(labels = scales::comma) +
facet_grid(罪種 ~ ., scales = "free_y") +
labs(x = "年次", y = "認知件数") +
theme_bw(base_family = "IPAexGothic")
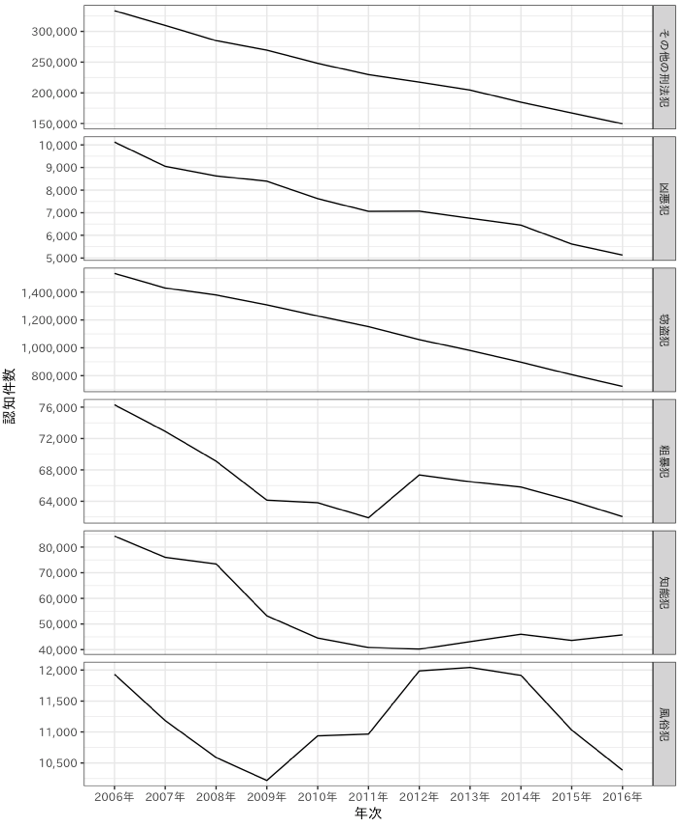
気力があれば次回もっと辛いデータを取得していきたいと思います。
→しました: Rからe-Stat APIを使う(一括取得API) - Qiita